







我自己的原文哦~ https://blog.51cto.com/whaosoft/11566677
# 大语言模型部署方案
随着AI的不断发展,LLM逐渐从单一的自然语言处理任务扩展到处理多种媒体数据的多模态模型,同时模型参数量越来越大。像 GPT-4 和 LLaMA 这样的大型语言模型(LLM)已成为在各个层面为各种注入人工智能的应用提供服务的主要工作负载。从一般聊天模型到文档摘要,从自动驾驶到软件栈各层的协同机器人,大规模部署和服务这些模型的需求急剧上升。此外,模型规模越大,在实际应用中模型推理速度更更慢。因此研究LLM推理过程并提出优化方法以降低所需显存、降低功耗和提高模型推理速度,具有重要的意义。
关于LLM推理优化及加速,我们计划分几部分展开。首先,我们带大家了解LLM模型推理过程中存在的瓶颈及常见优化方法。
1 LLM推理
LLM推理主要分为两步骤:
1)encoding/prefill:预填充,并行处理输入的所有 tokens
2)decoding:解码,逐个生成下一个 token
重复这两个步骤直到生成 EOS token 或达到用户设定的停止条件(stop token 或最大 token 数)。
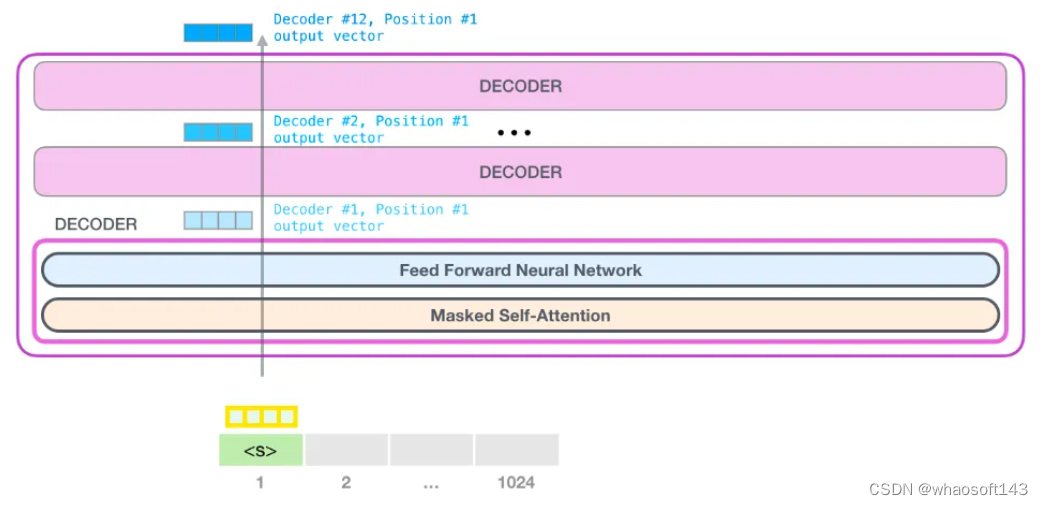
图1 LLM推理过程
以 Llama2-7B(序列长度4096,精度float16,输入prompt长度350token)在A10GPU上推理为例,计算 batch_size = 1的理想推理速度。
prefill:
预填充所需要的时间 = token数量*(模型总参数所占字节数 / 计算带宽)= 350 * (2 * 7B) FLOP / 125 TFLOP/s = 39 ms。这个阶段性能瓶颈主要是算力
decoding:
解码阶段每个token所需的生成时间 time/token = 模型总参数所占字节数 / 内存带宽 = (2 * 7B) bytes / (600 GB/s) = 23 ms/token,即每生成一个token理想情况下需要23ms。在此阶段,主要性能瓶颈是带宽。然而实际上由于带宽利用率较低,推理速度与理想时间相差较大。
2 LLM推理评价指标
主要有以下四个核心评价指标:
- Time To First Token (TTFT): 首Token 延迟,即从输入到输出第一个 token的延迟。在线的流式应用中,TTFT 是最重要的指标,它决定了用户体验。
- Time Per Output Token (TPOT):每个输出token 的延迟(不含首个Token)。在离线的批处理应用中,TPOT 是最重要的指标,它决定了整个推理的时间。
- Latency:延迟,即从输入到输出最后一个 token 的延迟。Latency = (TTFT) + (TPOT) * (the number of tokens to be generated). Latency 可以转换为 Tokens Per Second (TPS):TPS = (the number of tokens to be generated) / Latency。
- Throughput:吞吐量,即每秒针对所有请求生成的 token 数。以上三个指标都针对单个请求,而吞吐量是针对所有并发请求的。
其中在线的流式应用可以理解为存在多客户同时向LLM发出多请求的场景,离线的批处理应用可以理解为LLM部署在私域或本地服务器,这样不存在高并发请求的现象。对于线流式应用,为了给用户提供更好的使用体验,因此对 TTFT、TPOT、Latency 非常敏感,需要尽可能快的生成 token。对于离线批量应用,对 Throughput 敏感,需要在单位时间内尽可能多的生成 token。
3 LLM推理性能卡点分析
3.1 KV-Cache
由于LLM推理是一个自回归的过程,即在生成第i+1次token时,会将前i次生成的token送入模型,经过推理拿到第i+1次的输出token。
在这个过程中Transformer会执行自注意力操作,为此需要给当前序列中的每个token提取键值(kv)向量。这些向量存储在一个矩阵中,通常被称为kv cache。kv cache是为了避免每次采样token时重新计算键值向量。
举例:
对最大长度是 4096 的 LLaMa2-7B fp16 模型,服务端每创建 1 个并发,都需要大约 2GB 显存保存 kv_cache,即便是 A100 80G,能并发服务的用户非常有限。
所以KV-Cache 的减少以及优化是提高 LLM 推理性能的关键。
3.2 带宽瓶颈导致 TPOT 受限
随着GPU的发展迭代,计算能力一般不是推理瓶颈,而带宽才是瓶颈。衡量指标主要是模型带宽利用率 MBU。
MBU 计算方式:
MBU = 实际内存带宽 / 峰值内存带宽,
实际内存带宽 = (总模型参数大小 + KV 缓存大小) / TPOT
例子:
假如 7B fp16 模型的 TPOT 是 14ms,那么它就需要在 14ms 内把 14GB 参数从显存加载到计算单元,也就是 1TB/s 的带宽使用量。假设显卡的峰值带宽为 2TB/s,那么 MBU = 0.5,即显存带宽利用率是 50%。注:这里忽略了KV 缓存。
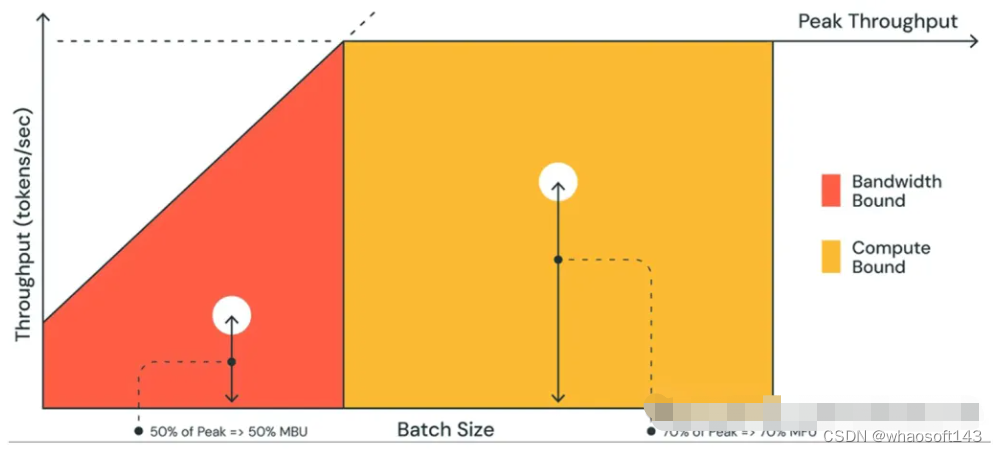
图2 LLM推理过程不同阶段的性能瓶颈分析
4 LLM推理优化方法
下面介绍目前业界在生产环境下常用的优化技术
4.1 Operator Fusion 算子融合
通过转换工具,将神经网络中的部分层进行融合,从而降低计算量和数据量,提高推理性能。
常见的两个框架是 FasterTransformer(TensorRT) 和 Deepseed Inference,都可以通过转换的方式,融合 Transformer 的特定层。
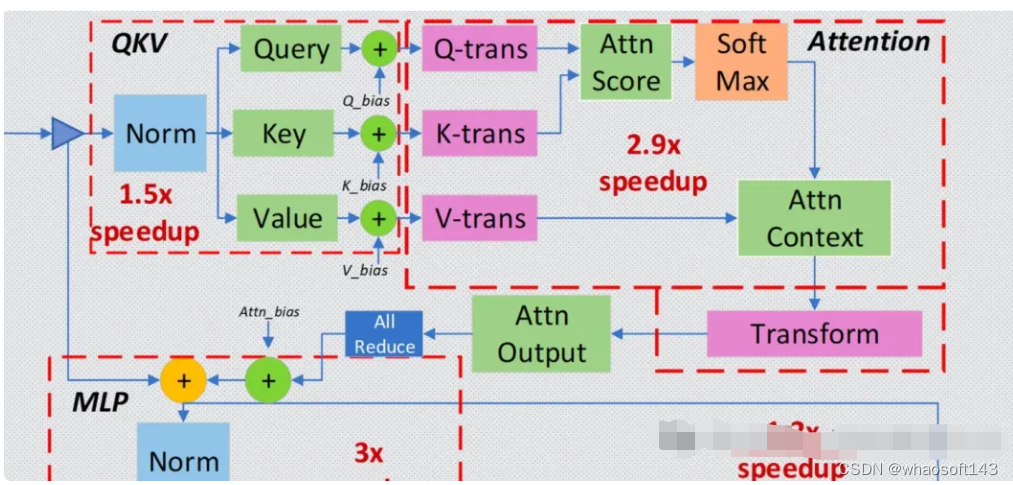
图3 Deepspeed 层融合示意图
4.2 Quatization 量化
量化除了降低模型需要的显存外,最直接的收益就是降低了带宽使用率,所以从理论上来说,量化后的模型性能应该是成比例提升的,这个提升不仅体现在吞吐量上,也会体现在 Latency 上。量化分类:
- 量化感知训练(QAT):在训练(一般是 sft 中)过程中,通过量化感知训练,让模型适应低精度的计算,从而保护模型的效果不受量化影响。少数模型提供了相关权重。
- 动态离线量化(PTQ Dynamic):缩放因子(Scale)和零点(Zero Point)是在推理时计算的,特定用于每次激活。不需要样本数据训练,但是性能和效果都略低。
- 静态离线量化(PTQ Static):需要少量无标签样本进行校准,计算出缩放因子和零点,然后在推理时使用。性能和效果都比动态离线量化好。目前一般使用这种量化方式。
4.3 FlashAttention
FlashAttention 就是通过利用 GPU 硬件中的特殊设计,针对全局内存和共享存储的 I/O 速 度的不同,尽可能的避免 HBM(全局内存)中读取或写入注意力矩阵。FlashAttention 目标是尽可能高效地使 用 SRAM (共享内存)来加快计算速度,避免从全局内存中读取和写入注意力矩阵。
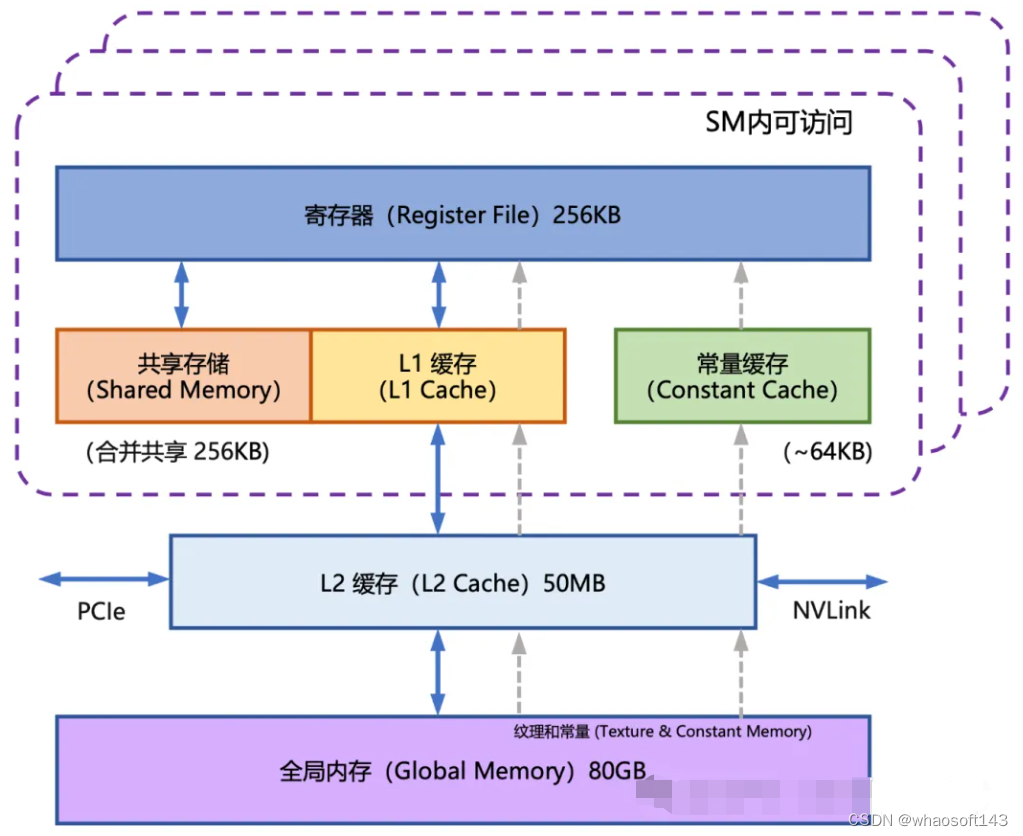
图4 GPU内存架构图
4.4 PageAttention
随着序列长度和并发数的增加,KV-Cache 的大小等比例提升,成为核心瓶颈。目前主要采用PageAttention优化方法:
KV Cache 的大小取决于序列长度,这是高度可变和不可预测的。实际上因为显存碎片和过度预留,浪费了 60% - 80% 的显存。PageAttention 参考虚拟内存和内存分页的思想,解决显存碎片化的问题,提高显存利用率,从而提升推理性能。同时 PageAttention 具备 Copy-on-Write 的特性,可以对相同的 Prompt 共享 KV Cache,从而节省显存。
PagedAttention 是 vLLM 的核心技术,在生产环境中一般都有 4x 以上的性能提升。
与传统的注意力算法不同,PagedAttention 允许在不连续的内存空间中存储连续的键和值。具体来说,PagedAttention 将每个序列的 KV 缓存划分为多个块,每个块包含固定数量的令牌的键和值。在注意力计算过程中,PagedAttention 内核会有效地识别和获取这些块。由于块不需要在内存中是连续的,因此我们可以像在操作系统的虚拟内存中一样以更灵活的方式管理键和值:可以将块视为页面,将 token 视为字节,将序列视为进程。序列的连续逻辑块通过块表映射到非连续的物理块。随着新 token 的生成,物理区块会按需分配。
4.5 并行化
并行化可以有效利用多个设备进行推理,从而提升吞吐,降低延迟。

表1 多设备并行推理性能比较
4.6 批处理
- 静态批处理 (Static Batching):在推理前,将多个请求合并为一个大的请求,然后一次性推理。这种方式可以提高吞吐量,但是需要所有请求都完成后才能返回结果,所以一般不会应用。
- 动态/持续批处理(Continuous Batching):持续批处理是一种特殊的动态批处理,它可以在序列结束后,继续接受新的序列。从而在保证延迟的情况下,提高吞吐量。
# 大模型微调项目 / 数据集调研汇总
总结了一些热门的大模微调项目的亮点以及数据集
前言
本文主要总结本人最近跑过的大模型微调项目。
相信大家这几个月都会不断新出的微调大模型项目刷屏,频率基本每天都有高星的项目诞生,部分还宣称自己达到GPT的百分之多少,一方面弄得大家过度乐观,一方面弄得大家焦虑浮躁。
面对这种情况,我的建议是「多动手」。把这些项目 clone 下来,跑跑代码,把项目用到的数据集下载下来做做EDA,把项目训练完的checkpoint下载下来,用自己的例子跑跑。多接触反而心态平定了许多。
回归正题,这篇博文聊聊一些热门的大模型微调项目。首先我觉得大量这些项目的诞生是源于以下三个节点:
- 节点1 ChatGPT:由于 ChatGPT 惊人的效果,让大家意识到AGI的可能性,并重视起了大模型+开放指令微调+强化学习这种三阶段范式
- 节点2 LLaMA:LLaMA 是 Meta 在今年2月份推出的基座模型,宣称 LLaMA-13B 在大多数基准测试中超过了 GPT-3 (175B),而 LLaMA-65B 与最好的模型 Chinchilla70B 和 PaLM-540B 相比非常有竞争力。此外,该项目还开源了7B、13B、30B和65B版本。
- 节点3 Stanford Alpaca:在 LLaMA 的基础上,用 Self-Instruct 去制造了52K的指令微调数据集,最后发现训练出来的模型确实是能听懂指令的,能看出ChatGPT的雏形
这三个节点加起来相当于证明了一条可以低成本复现的道路,然后大量的人沿着这条道路去进行时间。
再来说说这些项目的,本质都是:底座模型(ChatGLM/LLaMA/BLOOM)+ 微调数据(主要是指令微调数据集) + 高效微调方案(Fulltuning/Lora/Freeze/Ptuning)。
项目
这些介绍几个我认为比较好的,好的定义是:Github star 比较高的,持续在维护更新的,同时作者对自己的项目做了详细解析和深入研究的。
ChatGLM-6B
清华唐杰老师团队
项目: https://github.com/THUDM/ChatGLM-6B
Blog: https://chatglm.cn/blog
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于GLM架构,具有62亿参数。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约1T个标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持。为了方便下游开发者针对自己的应用场景定制模型,项目还开源了基于 P-Tuning v2(https://github.com/THUDM/P-tuning-v2) 的高效参数微调代码。
亮点:
- GLM 是一种 Prefix decoder 的结构,而目前大模型采用的主流结构是 Casual decoder,可以说GLM走出了自己的道路,但究竟那种结构更优,需要更科学的评定
- 1T 个token的中英文预训练,对比 175B 的 GPT3 训练了300B个 token,540B的 PaLM 训练了780B个 token,而 ChatGLM-6B 的底座只是6B的模型,却训练了1T个 token,让人有种憧憬,用大数据训练小模型,是否能达到小数据训练大模型的效果
- 项目号称经过监督微调、反馈自助、人类反馈强化学习
但是 ChatGLM-6B 没有公布它的训练细节和语料是怎么做的,有人说 ChatGLM-6B 的 IFT 也是通过 self-Instruct 得到的,这也不是空穴来风,相信用过 ChatGLM-6B 的人都会觉得,ChatGLM-6B的回复风格跟ChatGPT十分相似。
Alpaca-CoT
中科院的学生做的项目
项目:https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
多接口统一的大模型指令微调平台。该项目做了一个框架,利用这个框架,可以方便地用不同的底座模型+不同的指令数据集进行大模型的微调,不足的地方是,只提供了使用Lora的训练方式。除此之外,该项目主打一个思维链 (CoT),把CoT数据集加入到指令微调中,在项目中还举了很多案例,证明加入了CoT数据集后对模型的提升作用。
亮点:
- 统一了多个底座模型,包括有 LLaMA、ChatGLM、BLOOM
- 整理统一了其他公开项目的数据集,如果大家想梳理下现在市面上开源的IFT数据集,建议可以通过这个项目了解
- 项目集成了 Int8-bitsandbytes、Fp16-mixed precision、LoRA(hugging peft库)等高效训练的方法
- 首个加入了 CoT 训练后的效果研究
BELLE
贝壳团队开源的项目
项目:https://github.com/LianjiaTech/BELLE
项目基于 Deepspeed-Chat 项目,包括全量参数微调(fine-tuning)和基于LoRA的参数高效微调。
亮点:
- 开源了一个规模巨大的中文IFT数据集,现在加起来有300万以上,基本都是通过Self-Instructi得到
- 做了一系列的实验,截止日前已发了4篇技术报告
- 《Exploring ChatGPT's Ability to Rank Content: A Preliminary Study on Consistency with Human Preferences》
- 《Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases》
- 《Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation》
- 《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model》
建议大家把它们的数据集下载下来看看,并把这4篇实验报告都看一次。虽然这些实验并不是很客观,例如最后的test集也是用的belle自己的,然后用的是GPT3.5打分。不过整体的实验思路和实验结果还是可以大致参考的。
Chinese-LLaMA-Alpaca
科大讯飞&哈工大团队,很出名的团队,很多耳熟能详的中文预训练模型,如RoBERTa、MacBERT、PERT都出自它们团队
项目:https://github.com/ymcui/Chinese-LLaMA-Alpaca
该项目包括词表扩充、继续预训练和指令精调三部分,其中词表扩充的代码参见 merge_tokenizers.py ;预训练和指令精调代码参考了 transformers中的 run_clm.py 和 Stanford Alpaca 项目中数据集处理的相关部分。
亮点:
- 相对完整的流程,不紧紧是指令微调这一步,还包括词表扩充、继续预训练
- 针对LLaMA模型扩充了中文词表,提升了中文编解码效率。这一步是我觉得假如想用LLaMA去做中文必须要做的一个事情,因为原生LLaMA对中文支持不好,很多中文词不在它们的词表中,会被切成两个token,极大影响了效果
- 对中文继续做了20G语料的预训练,这个预料规模一看就很熟,它们开源的RoBERTa、MacBERT也是在这个规模的预料上训练得到的
- 在预训练介绍,分成两部分,第一阶段:冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量,第二阶段:使用LoRA技术,为模型添加LoRA权重(adapter),训练embedding的同时也更新LoRA参数。这给大家做高效继续预训练的提供了一个方向。
StackLLaMA
项目:https://huggingface.co/spaces/trl-lib/stack-llama
Blog: https://huggingface.co/blog/stackllama
Hugging Face的研究人员发布的一个70亿参数的模型——StackLLaMA。这是一个通过人类反馈强化学习在LLaMA-7B微调而来的模型。
个人感觉有价值的是Hugging Face研究人员发布的一篇Blog:用RLHF训练LLaMA的实践指南。
亮点:
- 博客更像是一个教程和指南,介绍如何使用RLHF来训练模型,而不是主要关注模型的性能表现
- 重点介绍了指令微调和强化学习部分,其中强化学习部分利用的是StackOverflow构建的数据集,利用网民们的upvotes去进行评分,给我们构造强化学习数据集部分提供了一个思路,能否利用微博点赞、知乎点赞等数据去构造一个中文的强化学习数据集呢?
数据集
介绍几个比较有特色的中文数据集
Alpaca-CoT
对大部份中英文的开源IFT数据集进行了整理和汇总,包括有 Guanaco、belle、firefly、COIG,加上项目自己开源的CoT数据集。假如不想自己去疏离数据集的话,就看这个它们整理好的就行了。
Alpaca_GPT4
https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
微软论文《INSTRUCTION TUNING WITH GPT-4》开源的数据集。亮点是利用 GPT-4 生成的 Alpaca 数据,并做了中文的翻译。由于GPT4比GPT3.5强大很多的,因此质量自然会更高。
belle_data
https://github.com/LianjiaTech/BELLE/tree/main/data/10M
规模很大、类型也较多的数据集
- School Math:包含约25万条中文数学题数据,包含解题过程。
- Multiturn Chat:包含约80万条用户与助手的多轮对话。
- Generated Chat:包含约40万条给定角色的多轮对话。
- train_2M_CN:包含约200万条与Alpaca类似生成的多样化指令任务数据。
这些数据都是由ChatGPT生成,部分质量是不过关的,需要自己好好筛选一下。
COIG
https://huggingface.co/datasets/BAAI/COIG
规模很大,类型很全的数据集
- 翻译指令数据集:基于开源数据集精选得到,并通过DeepL高质量翻译、并进行人工验证+人工修正
- 考试指令数据集:中国高考、中考、公务员考试得到,可用作思维链 (CoT) 语料库
- 价值对齐数据集:「中文世界的价值观念不同于英语世界的价值观」,作者构建了与普世华人价值观match的数据集,也是通过 self-instruct 生成的
- 反事实校正数据集:构建了反事实校正多轮聊天数据集(CCMC)。CCMC 数据集包括学生和老师之间的 5 轮角色扮演聊天,以及他们所参考的相应知识。教师根据基本事实知识生成响应,并在每一轮中纠正学生问题或陈述中的事实错误或不一致之处
- 代码指令数据集:Leetcode 数据集,包含有代码到文本和文本到代码
总体来说,这份数据集质量非常高,需要我们好好根据任务进行挑选。
个人感悟
数据清洗方案如何更好?
- 多样性:例如在 Self-Instruct 论文中,会使用 ROUGE 指标,过滤掉生成的指令与已有指令重合的指令。
- 高质量:使用 ChatGPT 生成数据,自然训练出来的模型就是模仿 ChatGPT 的回复风格。然而,ChatGPT(指 GPT3.5)自身的缺点包括浓浓的机翻味道、文绉绉的、不够活泼可爱,其次中文生成不够流畅。一种思路是使用 PPL 等指标筛选出生成的指令和回复,计算困惑度 Perplexity。Perplexity 低的通常是不流畅的,可以将低于一定阈值的去掉。
- 启发式:例如过滤掉问题是中文但回答是英文的,过滤掉生成的指令包含需要外部知识库的情况。
更多的清洗方案,可以多看看开源数据集中它们是如何处理的,留意里面的数据清洗方式。
哪种微调方案比较好?
从 BELLE 的技术报告《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model》中可以看出,Full-Tuning 效果应该是最好的,但 Full-Tuning 需要机器资源多,训练时间长。其次是 P-TuningV2/Lora/Freezing 的话,貌似是 P-TuningV2 效果最佳,具体可以看这个https://github.com/liucongg/ChatGLM-Finetuning。然而,这些比较并不严谨,例如每个方案都有自己的超参,是否每个方法都做了超参搜索。
强化学习部分重要吗?
非常重要。现在发现 ChatGLM-6B 的回复虽然一看过去感觉像模像样,但仔细看会发现胡言乱语的情况很严重,也即幻觉问题。也有人会另辟蹊径,例如 COIG 中的 CCMC 数据集,通过将这些数据集加入到 IFT 训练中,让模型学习纠正不正确回复的能力。还有在 prompt 中加入“请不要生成虚假的、自我捏造的回复”等字眼,目的是让模型在生成更加谨慎。然而,这些都是折中的办法。个人认为减少幻觉问题这一步,还得靠强化学习。希望未来能看到更多构建强化学习数据和开源强化学习数据集、训练的方案。
# 模型被投毒攻击,如今有了新的安全手段,还被AI顶刊接收
在深度学习时代,联邦学习(FL)提供了一种分布式的协作学习的方法,允许多机构数据所有者或客户在不泄漏数据隐私的情况下协作训练机器学习模型。然而,大多数现有的 FL 方法依赖于集中式服务器进行全局模型聚合,从而导致单点故障。这使得系统在与不诚实的客户打交道时容易受到恶意攻击。本文中,FLock 系统采用了点对点投票机制和奖励与削减机制,这些机制由链上智能合约提供支持,以检测和阻止恶意行为。FLock 理论和实证分析都证明了所提出方法的有效性,表明该框架对于恶意客户端行为具有鲁棒性。
现今,机器学习(ML),更具体地说,深度学习已经改变了从金融到医疗等广泛的行业。在当前的 ML 范式中,训练数据首先被收集和策划,然后通过最小化训练数据上的某些损失标准来优化 ML 模型。学习环境中的一个共同基本假设是训练数据可以立即访问或轻松地跨计算节点分发,即数据是「集中式」的。
然而,在一个拥有多个「客户端」(即数据持有者)的系统中,为了确保数据集中化,客户端必须将本地数据上传到一个集中设备(例如中心服务器)以进行上述的集中式训练。尽管集中式训练在各种深度学习应用中取得了成功,但对数据隐私和安全的担忧日益增长,特别是当客户端持有的本地数据是私有的或包含敏感信息时。
联邦学习(FL)可以解决训练数据隐私的问题。在一个典型的 FL 系统中,一个中心服务器负责聚合和同步模型权重,而一组客户端操纵多站点数据。这促进了数据治理,因为客户端仅与中心服务器交换模型权重或梯度,而不是将本地数据上传到中心服务器,并且已经使 FL 成为利用多站点数据同时保护隐私的标准化解决方案。
然而,现有的 FL 大多不能保证来自客户端的上传模型更新的质量。例如,我们可以将恶意行为定义为通过投毒攻击故意降低全局模型学习性能(例如准确性和收敛性)的行为。攻击者可以通过操纵客户端破坏 FL 系统,而不是黑进中心服务器。这项工作专注于防御客户端投毒攻击。
一种解决方案是将 FL 与如全同态加密(FHE)和安全多方计算(SMPC)等复杂的密码协议相结合,以减轻客户端的恶意行为。然而,采用这些复杂的密码协议为 FL 参与者引入了显著的计算开销,从而损害了系统性能。
FLock.io 公司及其合作研究者们(上海人工智能实验室 Nanqing Dong 教授、帝国理工大学 zhipeng Wang 博士、帝国理工大学 William Knoettenbelt 教授及卡内基梅隆大学 Eric Xing 教授)通过提出一种基于区块链和分布式账本技术的安全可靠的 FL 系统框架来解决传统联邦学习(FL)依赖于集中式服务器进行全局模型聚合,从而导致单点故障这个问题,并将此系统设计命名为 FLock。
在该研究中,团队借助区块链、智能合约和代币经济学设计一种可以抵抗恶意节点攻击(尤其是投毒攻击)的 FL 框架。该工作的成果近期被 IEEE Transactions on Artificial Intelligence (TAI) 接收。
- 论文链接:https://ieeexplore.ieee.org/document/10471193
- 论文标题:Defending Against Poisoning Attacks in Federated Learning with Blockchain
方法介绍
灵感来源
FLock 的机制设计受到了证明权益(PoS)区块链共识机制和桌面游戏《The Resistance》(一种角色扮演类游戏,该游戏的一个变种叫阿瓦隆)的启发。
《The Resistance》游戏则通过投票机制,每轮游戏中玩家独立推理并投票,从而实现全局共识。《The Resistance》有两个不匹配的竞争方,其中较大的一方被称为抵抗力量,另一方被称为间谍。在《The Resistance》中,有一个投票机制,在每一轮中,每个玩家进行独立推理并为一个玩家投票,得票最多的玩家将被视为「间谍」并被踢出游戏。抵抗力量的目标是投票淘汰所有间谍,而间谍的目标是冒充抵抗力量并生存到最后。
整体设计
基于 PoS 和《The Resistance》的启发,FLock 提出了一个新颖的基于区块链的 FL 全局聚合的多数投票机制,其中每个 FL 参与客户端独立验证聚合本地更新的质量,并为全局更新的接受度投票。参与者需要抵押资产或代币。
每一轮 FL 训练中,参与者将被随机选中参与两种类型的行动,提议(上传本地更新)和投票。聚合者(可以是区块链矿工或者其他 FL 链下聚合者)将对收到的本地更新进行聚合从而得到全局聚合。如果大多数投票接受全局聚合,提议者将退还其抵押的代币,而投票接受的投票者不仅会退还,而且还会获得投票拒绝的投票者的抵押代币的奖励,反之亦然。
基于股权基础聚合机制的整体设计如下图所示。

算法细节如下所示:
- 在每一轮中,从参与的客户端中随机选择提议者来进行本地训练并将本地更新上传到区块链。
- 随机选择的投票者将下载聚合的本地更新,执行本地验证,并投票接受或拒绝。
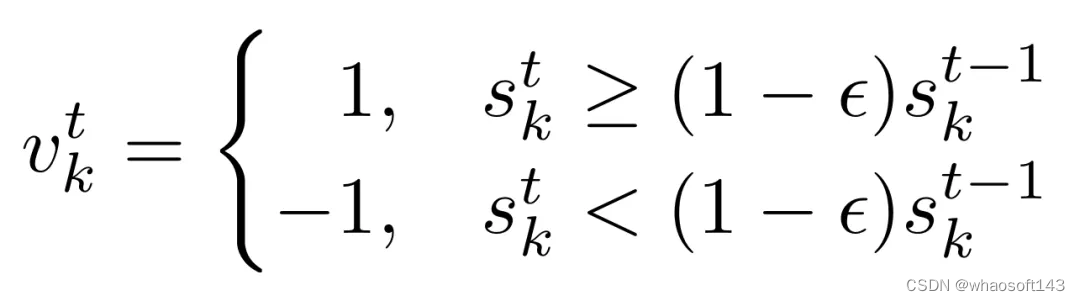
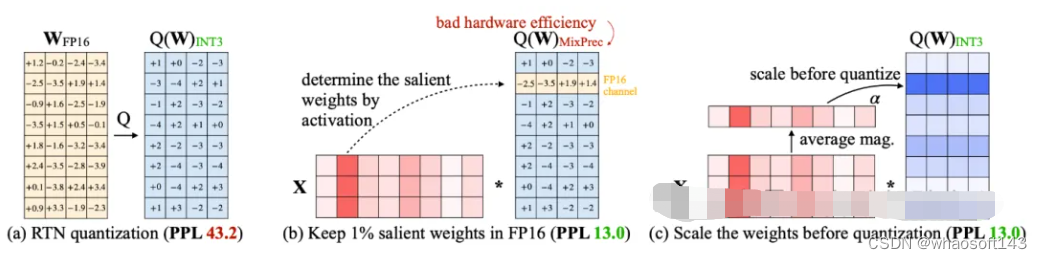
- 如果大多数投票者投票「接受」,那么全局模型将被更新,提案者和投票「接受」的投票者将获得奖励。
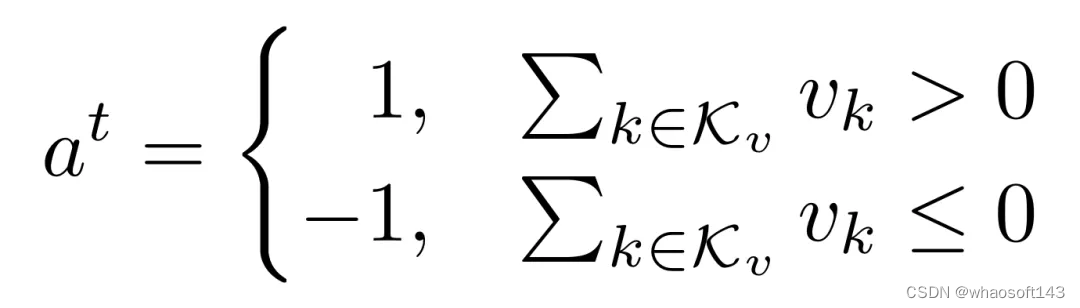
- 相反,如果大多数投票者投票「拒绝」,则全局模型将不会更新,提案者和投票「接受」的投票者的抵押代币将被削减。
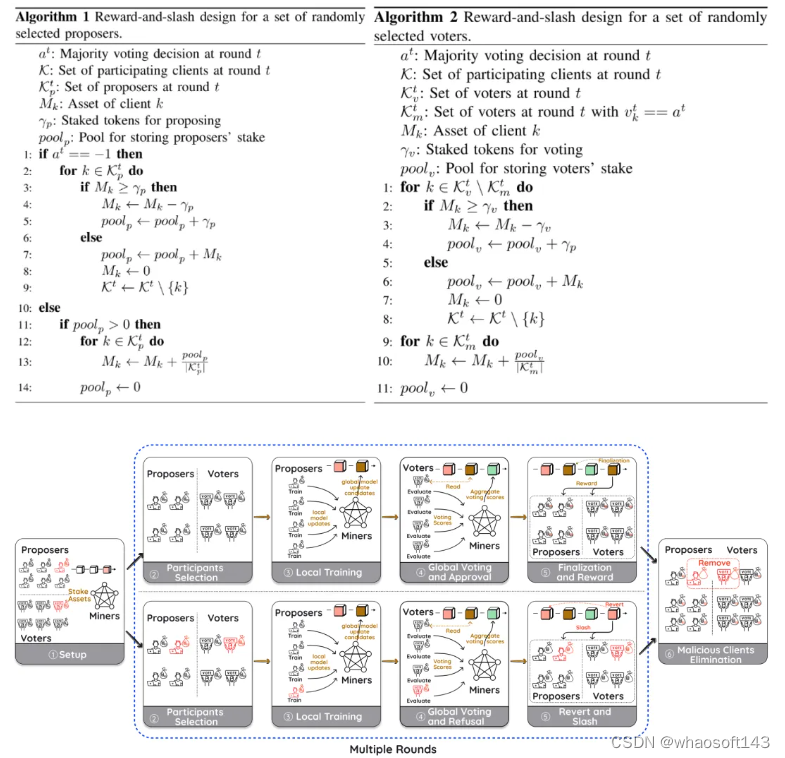
该算法的最终目标是让恶意参与者的长期平均收益为负值,进而使其抵押代币削减到低于某个允许阈值,从而被提出 FL 系统。
实验结果
FLock 的实验在 Kaggle Lending Club 数据集和 ChestX-ray14 数据集上显示分析了该方案的可行性和鲁棒性,包括:
与传统 FL 相比,FLock 抵抗恶意节点的能力:如下图所示,FLock (即 FedAVG w/block)在有恶意节点的情况下仍然保持了稳健的性能。
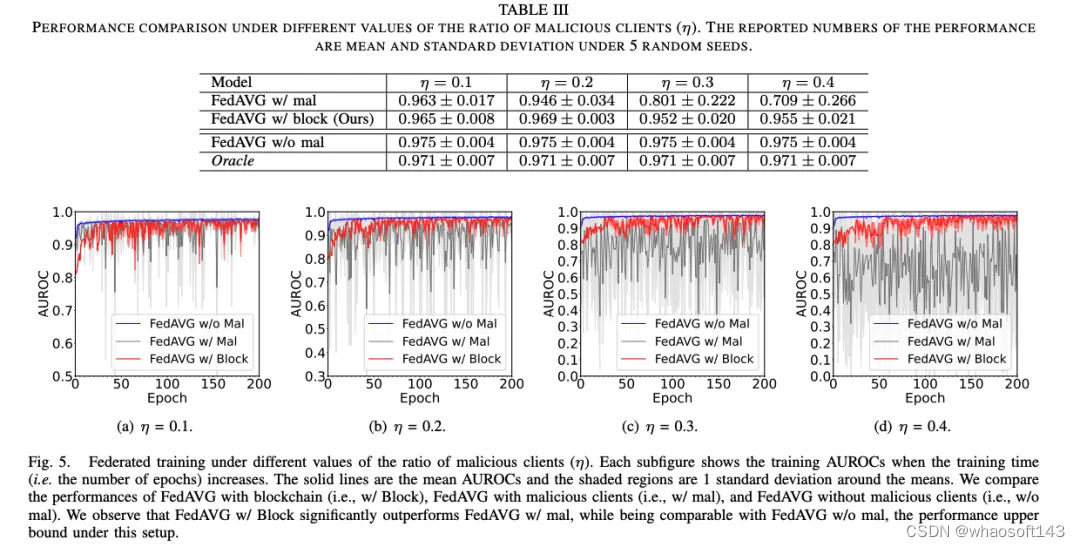
恶意参与者的抵押代币变化:同理论分析一致,恶意参与者的平均代币随着训练轮数 / 时间的增加而减少。并且,如果惩罚力度增大(即 \gamma 增大),则恶意参与者的平均代币的减少速度将会增大。
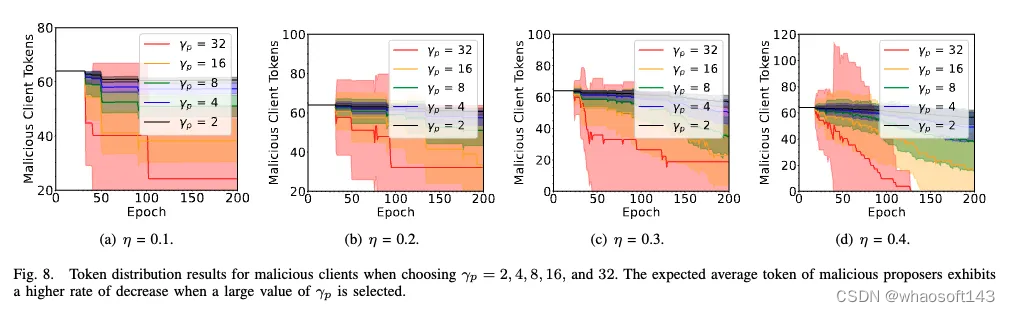
诚实参与者的抵押代币变化:相对应的,诚实参与者的平均代币随着训练轮数 / 时间的增加而增加。并且,如果惩罚力度增大大(即 \gamma 增大),则诚实参与者的平均代币的增加速度将会增大。
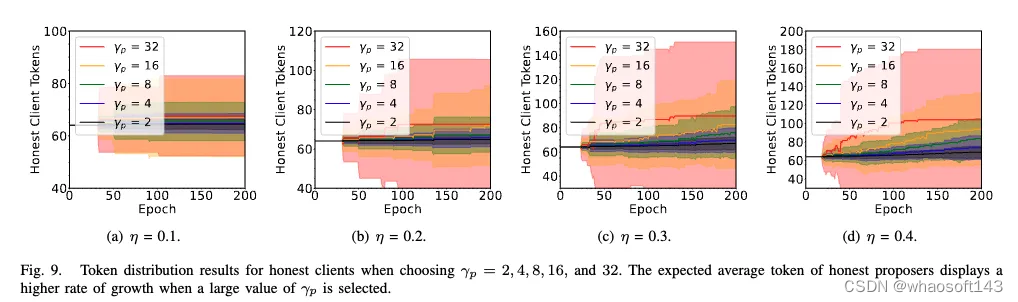
恶意参与者的存活时间:恶意参与者的存活时间将会随着惩罚力度增大而缩短。
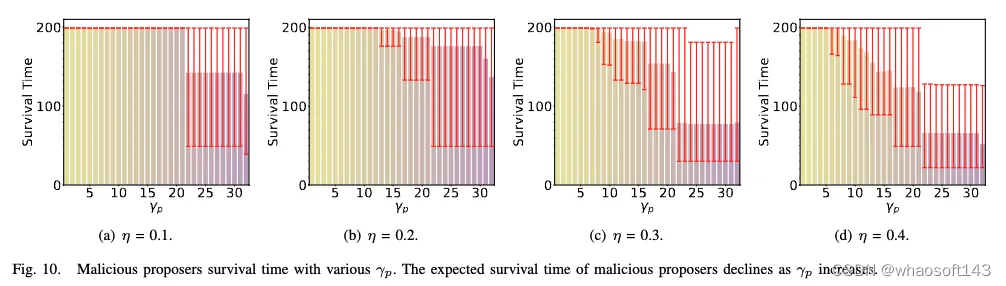
诚实参与者的存活时间:FLock 的实验结果也指出,在恶意节点占比较多的时候(即 \eta 增大时),较大的惩罚力度也会造成部分诚实节点的存活时间缩短(因为每一轮的提议者和投票者是随机选取的)。因此,在实际应用中,要结合考虑恶意节点占比(即 \eta)设置惩罚力度(即 \gamma)。

总结与展望
FLock 提出了一种基于区块链、智能合约和代币经济学的可以抵恶意节点攻击的 FL 框架。该方案论证了区块链和 FL 结合的可行性,证明了区块链不仅可以在去中心化和激励参与者在金融和医学等领域的现实世界中的 FL 应用中发挥重要作用,而且还可以用来防御投毒攻击。
FLock 的方案已被进一步落地实现:https://www.flock.io/
团队将于近期推出首个版本的去中心化 AI 模型训练平台,基建包括了激励体系,联邦学习和一键微调脚本。平台将主要面向两类人群:Developer:欢迎各位 Kaggle 及 Huggingface 玩家早期入驻,完成模型训练与验证以获得激励;Task Creator:有模型训练或者微调需求的公司或者团队可以在FLock平台上发布任务,FLock提供基建组织开发者,从而省去组建AI团队,寻找用户基础与数据的复杂过程,并简化工作流。有兴趣请邮件 FLock 团队:hello@flock.io
研究方面,FLock 也正在探索更加多维度的 decentralized AI 安全解决方案,如借助零知识证明解决 FL 中心节点作恶的问题。
研究地址:https://arxiv.org/pdf/2310.02554.pdf
# DeepMind升级Transformer,前向通过FLOPs最多可降一半
引入混合深度,DeepMind 新设计可大幅提升 Transformer 效率。
Transformer 的重要性无需多言,目前也有很多研究团队致力于改进这种变革性技术,其中一个重要的改进方向是提升 Transformer 的效率,比如让其具备自适应计算能力,从而可以节省下不必要的计算。
正如不久前 Transformer 架构的提出之一、NEAR Protocol 联合创始人 Illiya Polosukhin 在与黄仁勋的对话中说到的那样:「自适应计算是接下来必须出现的。我们要关注,在特定问题上具体要花费多少计算资源。」
其实人类就天生具备自适应计算的能力 —— 人在解决各种不同的问题时,会自然地分配不同的时间和精力。
语言建模也应如此,为了得到准确的预测结果,并不需要为所有 token 和序列都投入同样的时间或资源。但是,Transformer 模型在一次前向传播中却会为每个 token 花费同等的计算量。这不禁让人哀叹:大部分计算都被浪费了!
理想情况下,如果可以不执行非必要的计算,就可以降低 Transformer 的计算预算。
条件式计算这种技术可在需要执行计算时才执行计算,由此可以减少总计算量。之前许多研究者已经提出了多种可以评估何时执行计算以及使用多少计算量的算法。
但是,对于这个颇具挑战性的问题,普遍使用的解决形式可能无法很好地应对现有的硬件限制,因为它们往往会引入动态计算图。最有潜力的条件式计算方法反而可能是那些能协调使用当前硬件栈的方法,其会优先使用静态计算图和已知的张量大小(基于对硬件的最大利用而选取这个张量大小)。
近日,Google DeepMind 研究了这个问题,他们希望使用更低的计算预算来缩减 Transformer 使用的计算量。
- 论文标题:Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
- 论文地址:https://arxiv.org/pdf/2404.02258.pdf
他们设想:在每一层中,网络必须学会为每个 token 做决策,从而动态地分配可用计算预算。在他们的具体实现中,总计算量由用户在训练之前设定并且不再更改,而非网络工作时执行决策的函数。这样一来,便可以提前预知并利用硬件效率收益(比如内存足迹减少量或每次前向传播的 FLOPs 减少量)。该团队的实验表明:可以在不损害网络整体性能的前提下获得这些收益。
DeepMind 的这个团队采用了类似于混合专家(MoE) Transformer 的方法,其中会在整个网络深度上执行动态 token 层面的路由决策。
而与 MoE 不同的是,这里他们的选择是:要么是将计算应用于 token(和标准 Transformer 一样),要么就是通过一个残差连接绕过它(保持不变,节省计算)。另一个与 MoE 的不同之处是:这里是将这种路由机制同时用在 MLP 和多头注意力上。因此,这也会影响网络处理的键值和查询,因此该路由不仅要决定更新哪些 token,还要决定哪些 token 可供关注。
DeepMind 将这一策略命名为 Mixture-of-Depths(MoD),以突显这一事实:各个 token 在 Transformer 深度上通过不同数量的层或模块。我们这里将其翻译成「混合深度」,见图 1。
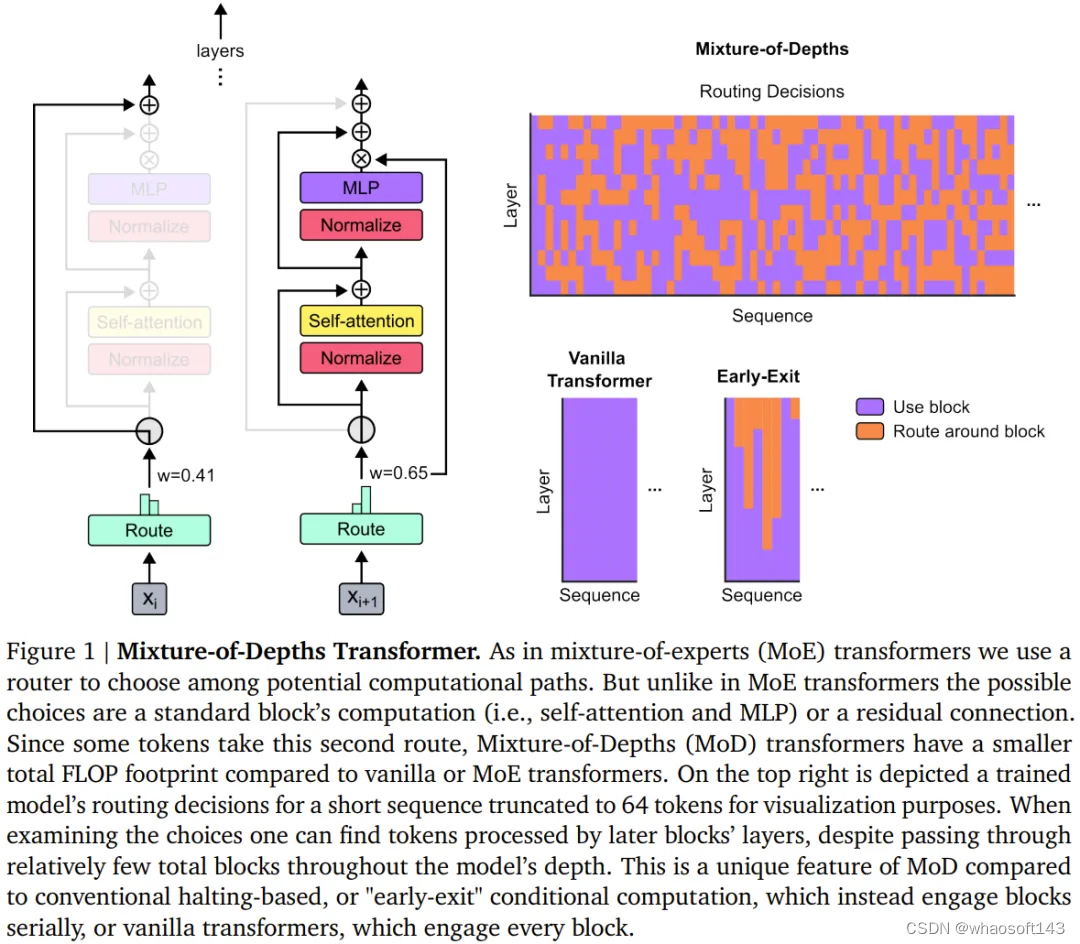
MoD 支持使用者权衡考量性能与速度。一方面,使用者可以使用与常规 Transformer 同等的训练 FLOPs 来训练 MoD Transformer,这可为最终的对数概率训练目标带来多达 1.5% 的提升。另一方面,MoD Transformer 使用更少的计算量就能达到与常规 Transformer 同样的训练损失 —— 每一次前向传播的 FLOPs 可少最多 50%。
这些结果表明,MoD Transformer 可以学习智能地路由(即跳过不必要的计算)。
实现混合深度(MoD)Transformer
概况来说,其策略如下:
- 设定一个静态的计算预算,该预算低于等价的常规 Transformer 所需的计算量;做法是限制序列中可参与模块计算(即自注意力模块和后续的 MLP)的 token 数量。举个例子,常规 Transformer 可能允许序列中的所有 token 都参与自注意力计算,但 MoD Transformer 可限定仅使用序列中 50% 的 token。
- 针对每个 token,每个模块中都有一个路由算法给出一个标量权重;该权重表示路由对各个 token 的偏好 —— 是参与模块的计算还是绕过去。
- 在每个模块中,找到最大的前 k 个标量权重,它们对应的 token 会参与到该模块的计算中。由于必定只有 k 个 token 参与到该模块的计算中,因此其计算图和张量大小在训练过程中是静态的;这些 token 都是路由算法认定的动态且与上下文有关的 token。
路由方案
该团队考虑了两种学习到的路由方案(见图 2):token 选择型和专家选择型。
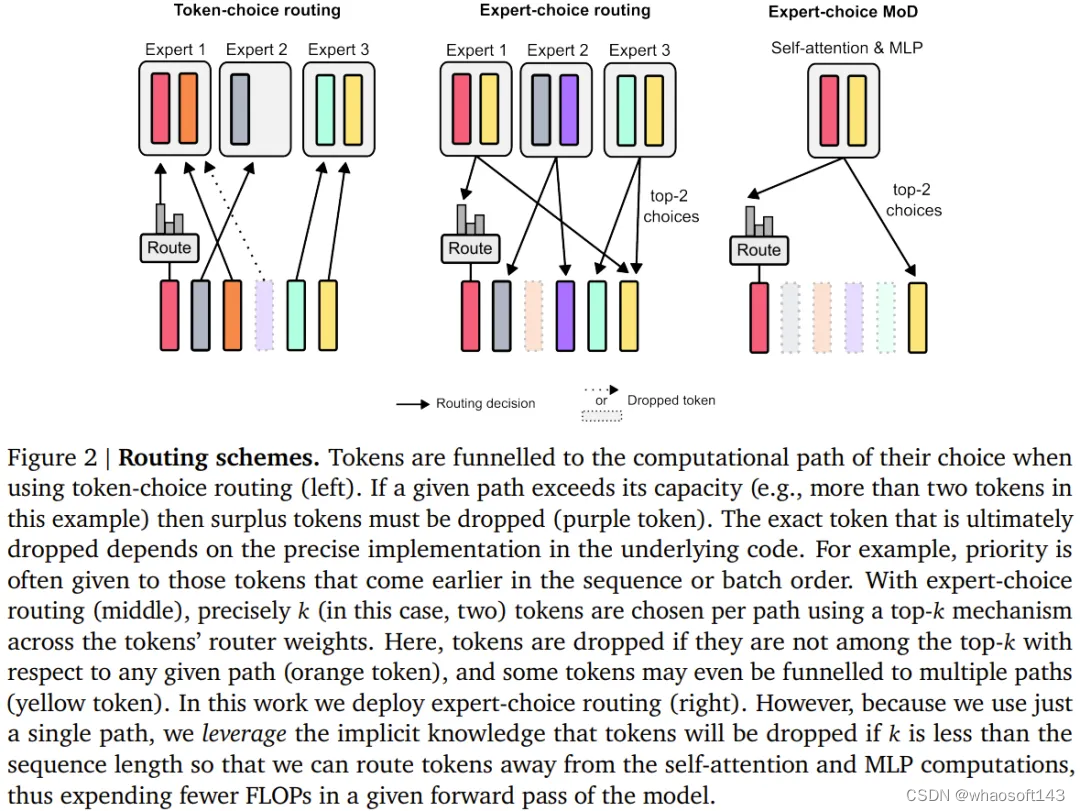
在 token 选择型路由方案中,路由算法会跨计算路径(比如跨 MoE Transformer 中的专家身份)生成针对每个 token 的概率分布。然后 token 会被传送到它们偏好的路径(即概率最高的路径),而辅助损失可以确保所有 token 不会收敛到同一路径。token 选择型路由可能会有负载平衡问题,因为不能确保 token 在可能的路径之间划分适当。
专家选择型路由则是将上述方案反过来:不是让 token 选择它们偏好的路径,而是让每条路径基于 token 偏好选择前 k 个 token(top-k)。这能确保负载完美平衡,因为每条路径总是保证 k 个 token。但是,这也可能导致某些 token 被过处理或欠处理,因为某些 token 可能是多条路径的前 k 名,另一些 token 则可能没有相应路径。
DeepMind 的选择是使用专家选择型路由,原因有三。
第一,它无需辅助性的平衡损失。
第二,由于选取前 k 名这一操作取决于路由权重的幅度,因此该路由方案允许使用相对路由权重,这有助于确定当前模块计算最需要哪些 token;路由算法可以通过适当地设定权重来尽力确保最关键的 token 是在前 k 名之中 —— 这是 token 选择型路由方案无法做到的。在具体的用例中,有一条计算路径本质上是 null 操作,因此应该避免将重要 token 路由到 null。
第三,由于路由只会经由两条路径,因此单次 top-k 操作就能高效地将 token 分成两个互斥的集合(每条计算路径一个集合),这能应对上面提及的过处理或欠处理问题。
该路由方案的具体实现请参看原论文。
采样
尽管专家选择型路由有很多优点,但它也有一个很明显的问题:top-k 操作是非因果式的。也就是说,一个给定 token 的路由权重是否在前 k 名取决于其之后的路由权重的值,但在执行自回归采样时,我们无法获得这些权重。
为了解决这个问题,该团队测试了两种方法。
第一种是引入一个简单的辅助损失;实践证明,其对语言建模主目标的影响程度为 0.2%− 0.3%,但却能够让模型自回归地采样。他们使用了一个二元交叉熵损失,其中路由算法的输出提供 logit,通过选取这些 logit 中的 top-k,就能提供目标(即,如果一个 token 在 top-k 中,就为 1,否则为 0)。
第二种方法是引入一个小的辅助 MLP 预测器(就像是又一个路由算法),其输入与路由算法的一样(具有 stop gradient),但其输出是一个预测结果:token 是否在序列的 top-k 中。该方法不会影响语言建模目标,实验表明也不会显著影响该步骤的速度。
有了这些新方法,就可以通过选择路由到的 token 来执行自回归采样,也可以根据路由算法的输出绕过一个模块,这无需依赖任何未来 token 的信息。实验结果表明,这是一种相对简单辅助任务,可以很快实现 99% 的准确度。
结果
训练,isoFLOP 比较
首先,该团队训练了一些 FLOP 预算相对较小(6e18)的模型,以确定最优的超参数(见下图 3)。
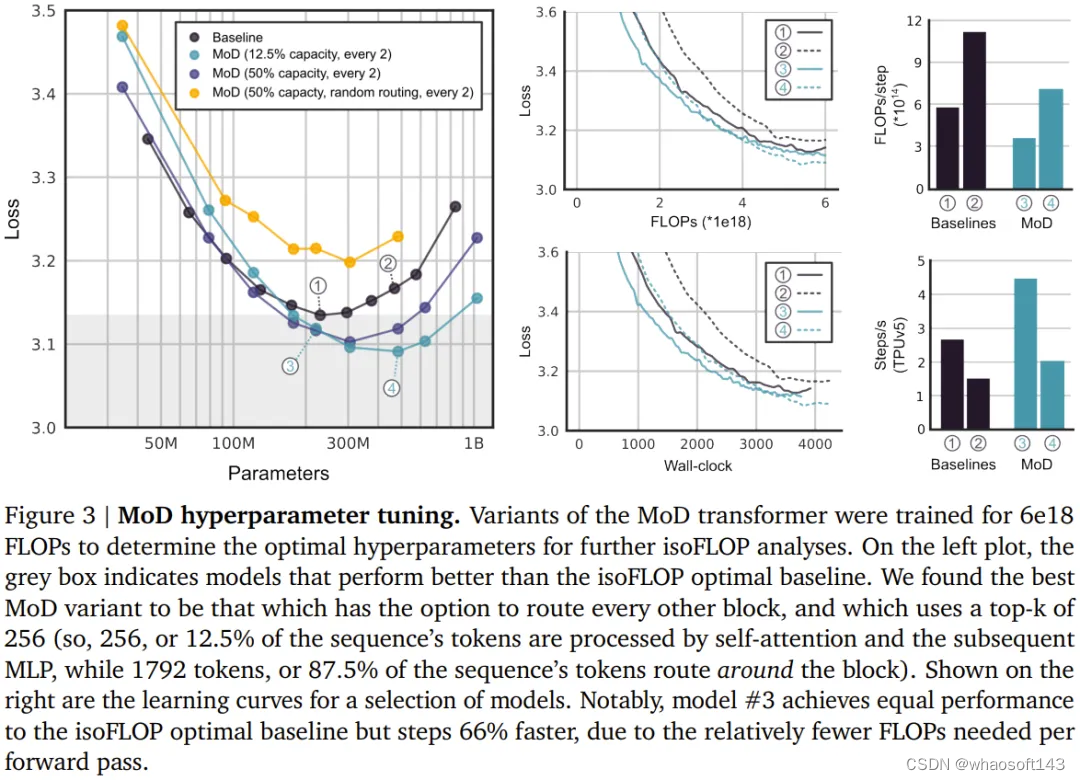
总体而言,可以看到 MoD Transformer 会将基准 isoFLOP 曲线向右下方拖动。也就是说,最优的 MoD Transformer 的损失比最优的基准模型更低,同时参数也更多。这种效应带来了一个幸运的结果:存在一些和最优基准模型表现一样好甚至更好的 MoD 模型(同时步骤速度更快),尽管它们本身在其超参数设置下并不是 isoFLOP 最优的。举个例子,一个 220M 参数量的 MoD 变体(图 3 中的 3 号模型)稍优于 isoFLOP 最优基准模型(参数量也是 220M,图 3 中的 1 号模型),但这个 MoD 变体在训练期间的步骤速度快了 60% 以上。
下图 4 给出了总 FLOPs 为 6e18、2e19 和 1e20 时的 isoFLOP 分析。可以看到,当 FLOP 预算更大时,趋势依然继续。
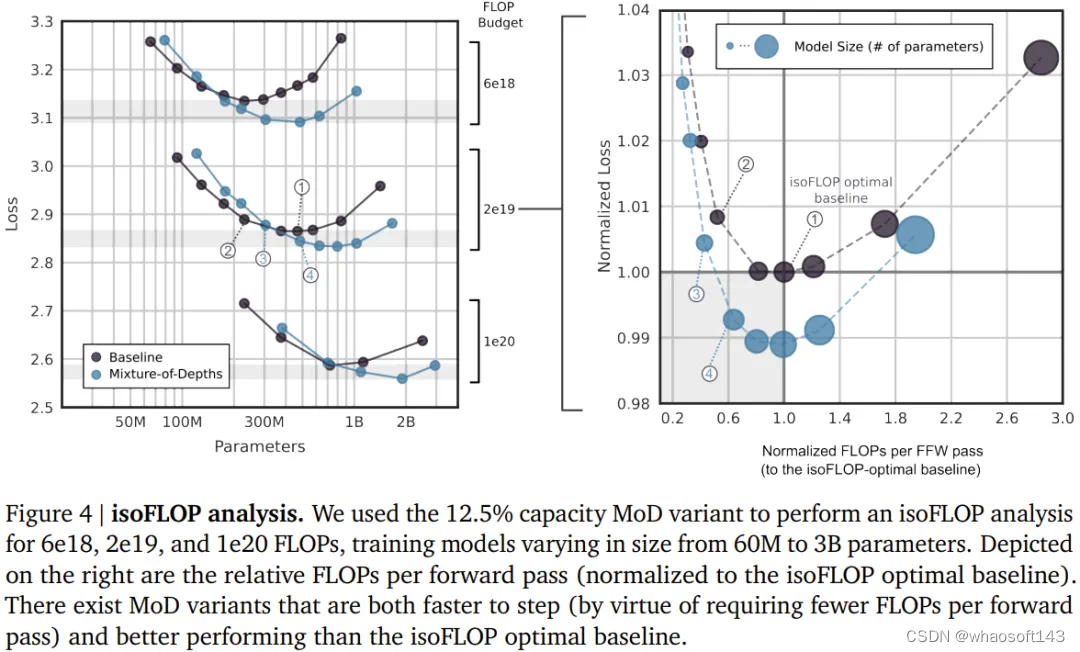
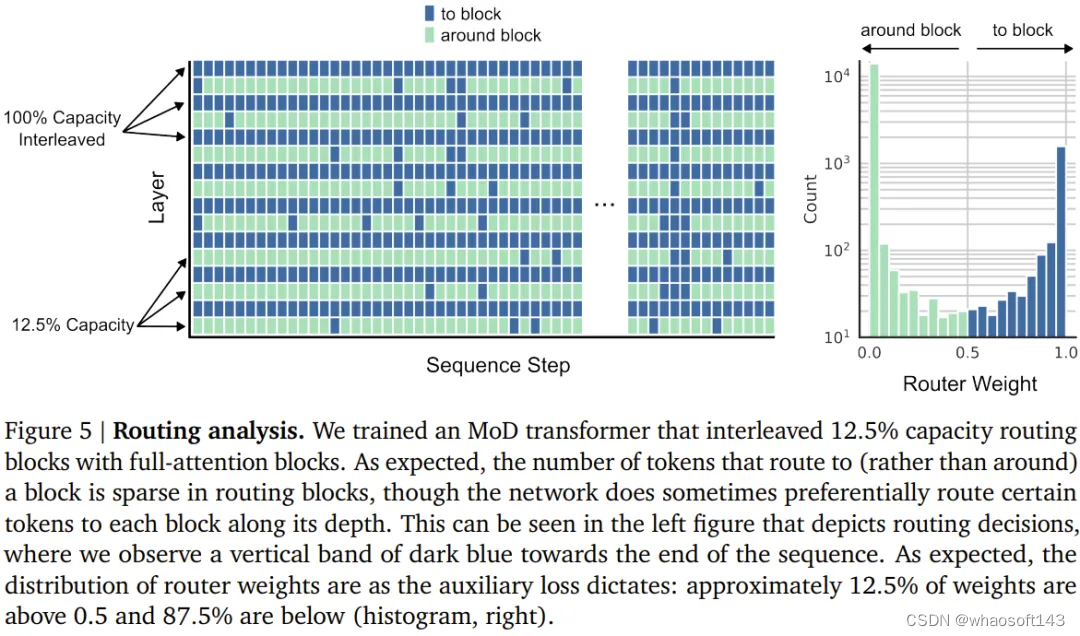
下图 5 给出了一个使用交织的路由模块训练的 MoD Transformer 的路由决策。尽管其中存在大量绕过模块的情况,但这个 MoD Transformer 依然能实现优于常规 Transformer 的性能。
自回归评估
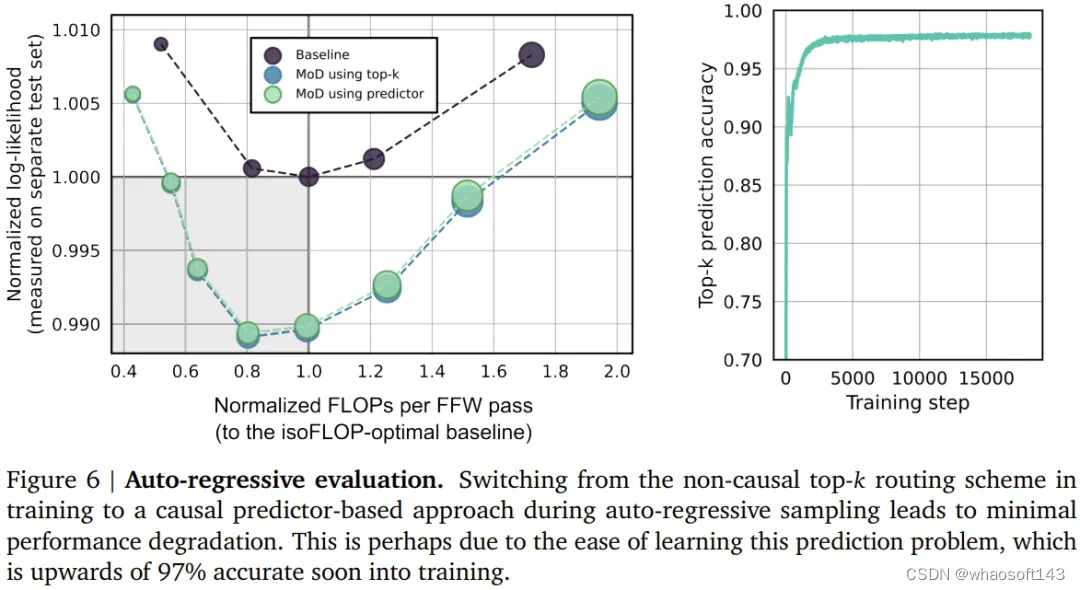
他们也评估了 MoD 变体的自回归采样表现,结果见下图 6。这些结果表明 MoD Transformer 所带来的计算节省不仅仅局限于训练设置。
混合深度与专家(MoDE)
MoD 技术可以自然地与 MoE 模型整合起来,组成所谓的 MoDE 模型。下图 7 展示了 MoDE 及其带来的提升。
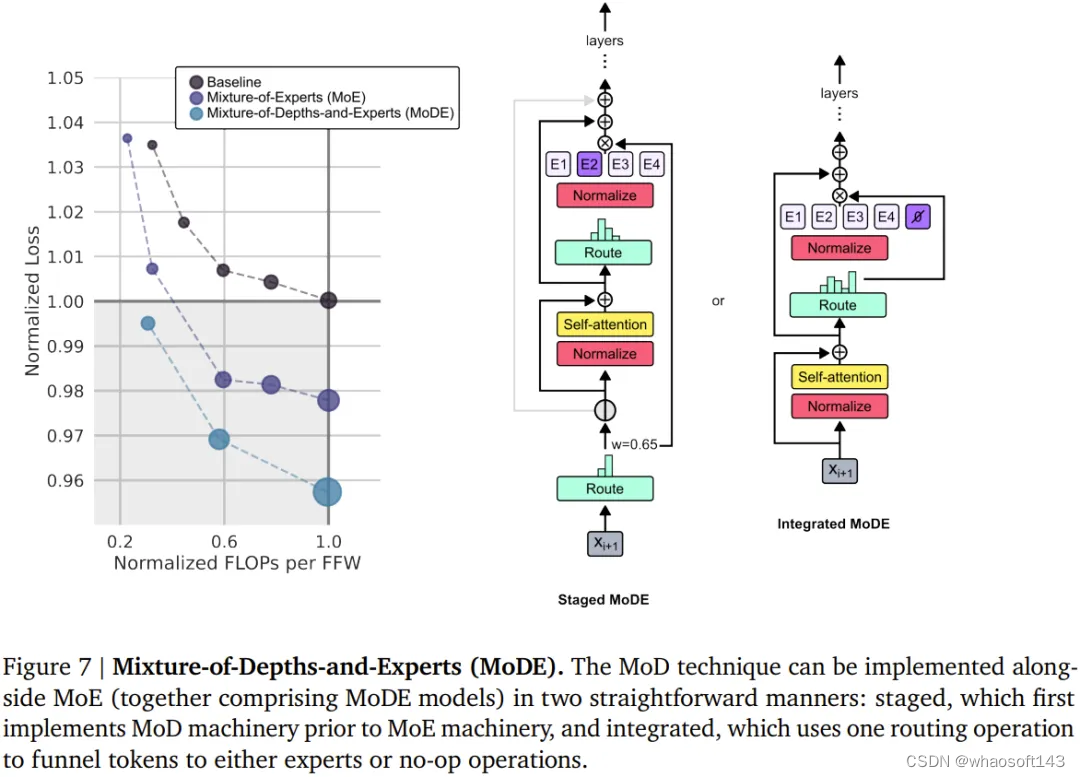
MoDE 有两种变体:分阶段 MoDE 和集成式 MoDE。
其中分阶段 MoDE 是在自注意力步骤之前进行路由绕过或到达 token 的操作;而集成式 MoDE 则是通过在常规 MLP 专家之间集成「无操作」专家来实现 MoD 路由。前者的优势是允许 token 跳过自注意力步骤,而后者的好处在于其路由机制很简单。
该团队注意到,以集成方式实现 MoDE 明显优于直接降低专家的能力、依靠丢弃 token 来实现残差路由的设计。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









