







Deep Cross Network (深度交叉网络, DCN) 介绍与代码分析
文章目录
发现看完 Paper 和源码后如果不做点笔记, 一段时间过后, 甚至记不起曾经看过相应的 Paper, 年纪大了啊 😂😂😂, 所以得养成好习惯. 限于水平, 笔记记录下 Paper 的要点即可. 说回正题, 这是 Stanford & Google 于 2017 年发表于 KDD 的工作.
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Networkfor Ad Click Predictions. In Proceedings of the ADKDD’17. ACM, 12.
后面的代码分析采用 DeepCTR-Torch 的 PyTorch 实现.
广而告之
可以在微信中搜索 “珍妮的算法之路” 或者 “world4458” 关注我的微信公众号;另外可以看看知乎专栏 PoorMemory-机器学习, 以后文章也会发在知乎专栏中;
文章信息
文章地址: Deep & Cross Networkfor Ad Click Predictions
发表时间: KDD, 2017
代码实现: https://github.com/shenweichen/DeepCTR-Torch/blob/master/deepctr_torch/models/dcn.py
主要内容
传统的 CTR 模型为了增强非线性表达能力, 需要构造特征组合, 虽然这些特征含义明确、可解释性强, 但通常需要大量的特征工程, 耗时耗力. 另一方面, DNN 模型具有强大的学习能力, 可以自动获取高阶的非线性特征组合, 然而这些特征通常是隐式的, 含义难以解释. 本文的亮点在于提出了一个 Cross Network, 可以显式并且自动地获取交叉特征; 此外, Cross Network 相比 DNN 显得更为轻量级,因此在表达能力上比 DNN 会逊色一些, 本文通过联合训练 Cross Network 与 DNN 来同时发挥二者的优势.
Deep Cross Network
下图即为本文提出的 DCN 完整模型:
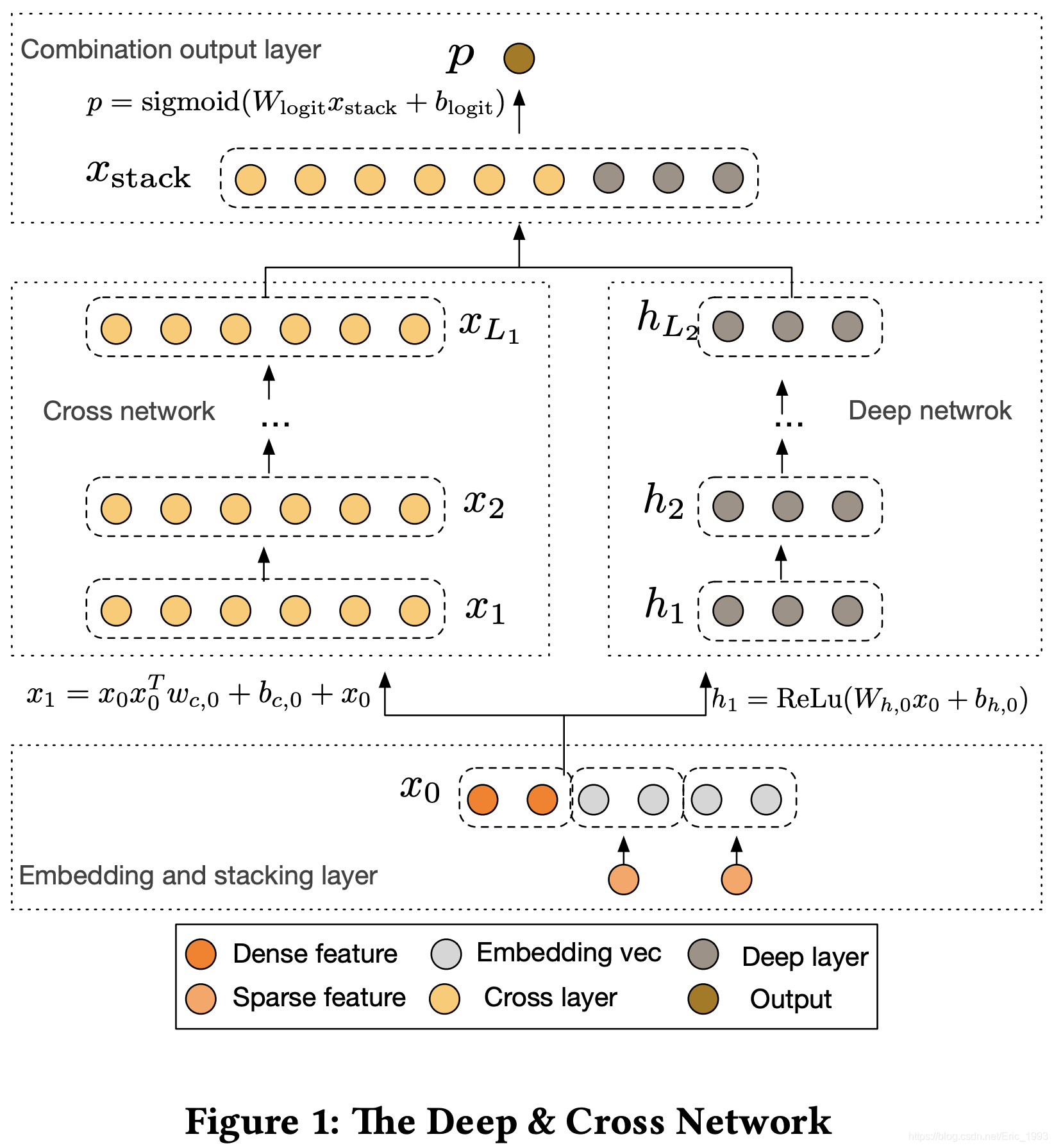
主要由三部分构成:
- 底层的 Embedding and Stacking Layer
- 中间层并行的 Cross Network 以及 Deep Network
- 输出层的 Combination output Layer
特征输入
对于原始的输入特征, 可能包括离散的类别特征 (Categorical Features) 和连续的稠密特征 (Dense Features). 通常我们会将类别特征编码为 OneHot 的形式, 但会导致对应的特征维度较高且稀疏, 因此我们还会引入一个 Embedding 层将类别特征映射为低维的稠密特征:
x e m b , i = W e m b , i x i x_{emb, i} = W_{emb, i} x_i xemb,i=Wemb,ixi
之后和规范化的连续特征进行 Concatenation 后, 再喂入到下一层网络中:
x 0 = [ x e m b , 1 T , x e m b , 2 T , … , x e m b , k T , x d e n s e T ] x_0 = [x^T_{emb, 1}, x^T_{emb, 2}, \ldots, x^T_{emb, k}, x^T_{\bm{dense}}] x0=[xemb,1T,xemb,2T,…,xemb,kT,xdenseT]
Cross Network
先看图, 再看公式化表达:

Cross Network 是本文的核心 idea, 它被用来显式并且高效地对交叉特征进行学习. 它由多个 Crossing Layer 构成, 每一层使用下式表示:
x l + 1 = x 0 x l T w l + b l + x l = f ( x l , w l , b l ) + x l x_{l + 1} = x_0 x^T_l w_l + b_l + x_l = f(x_l, w_l, b_l) + x_l xl+1=x0xlTwl+bl+xl=f(xl,wl,bl)+xl
其中 x l , x l + 1 ∈ R n x_{l}, x_{l + 1}\in\mathbb{R}^n xl,xl+1∈Rn 分别为第 l l l 层以及第 l + 1 l + 1 l+1 层的输出特征; w l , b l ∈ R n w_l, b_l\in\mathbb{R}^n wl,bl∈Rn 为第 l l l 层的权重和偏置; 注意到权重 w \bm{w} w 为向量而非矩阵. 此外, Residual Learning 的思路也被引入, 可以有效避免梯度消失的问题, 并可以帮助构建更深的网络, 增强网络的表达能力. Cross Network 特殊的结构可以让特征的阶数(degree)随着网络的深度增加而增长. 比如一个层数为 l l l 的 Cross Network, 其 highest polynomial degree 为 l + 1 l + 1 l+1.
由于每一层 cross layer 的权重 w w w 和偏置 b b b 都是向量, 假设维度均为 d d d, 那么层数为 L c L_c Lc 的 Cross Network 的参数总量为 d × L c × 2 d\times L_c\times 2 d×Lc×2. 由于 Cross Network 的参数数量相对较少, 这限制了模型的表达能力, 因此需要配合 Deep Network 一起使用.
下面看看 DeepCTR-Torch 对 CrossNet 的 PyTorch 实现:
class CrossNet(nn.Module):
"""The Cross Network part of Deep&Cross Network model,
which leans both low and high degree cross feature.
Input shape
- 2D tensor with shape: ``(batch_size, units)``.
Output shape
- 2D tensor with shape: ``(batch_size, units)``.
Arguments
- **in_features** : Positive integer, dimensionality of input features.
- **input_feature_num**: Positive integer, shape(Input tensor)[-1]
- **layer_num**: Positive integer, the cross layer number
- **l2_reg**: float between 0 and 1. L2 regularizer strength applied to the kernel weights matrix
- **seed**: A Python integer to use as random seed.
References
- [Wang R, Fu B, Fu G, et al. Deep & cross network for ad click predictions[C]//Proceedings of the ADKDD'17. ACM, 2017: 12.](https://arxiv.org/abs/1708.05123)
"""
def __init__(self, in_features, layer_num=2, seed=1024, device='cpu'):
super(CrossNet, self).__init__()
self.layer_num = layer_num
self.kernels = torch.nn.ParameterList(
[nn.Parameter(nn.init.xavier_normal_(torch.empty(in_features, 1))) for i in range(self.layer_num)])
self.bias = torch.nn.ParameterList(
[nn.Parameter(nn.init.zeros_(torch.empty(in_features, 1))) for i in range(self.layer_num)])
self.to(device)
def forward(self, inputs):
x_0 = inputs.unsqueeze(2)
x_l = x_0
for i in range(self.layer_num):
xl_w = torch.tensordot(x_l, self.kernels[i], dims=([1], [0]))
dot_ = torch.matmul(x_0, xl_w)
x_l = dot_ + self.bias[i] + x_l
x_l = torch.squeeze(x_l, dim=2)
return x_l
其中 layer_num 表示 Cross Network 的层数, 由于权重和 Bias 均为向量, 代码中使用 PyTorch 中的 Parameter 来表示, 每一层权重/Bias 的大小为 [in_features, 1], 为了方便我们设 in_channels = d.
在 forward 方法中实现 Cross Network 的前向传播逻辑. 其中 inputs 的大小为 [B, d], 其中 B 表示一个 Batch 的大小, d 表示每个样本的维度, 即输入特征的维度.
x_0 = inputs.unsqueeze(2)
这一步对 inputs 的 dim=2 进行扩展, 此时 x0 的 Shape 为 [B, d, 1]. 之后在 for 循环中, 实现公式
x l + 1 = x 0 x l T w l + b l + x l x_{l + 1} = x_0 x^T_l w_l + b_l + x_l xl+1=x0xlTwl+bl+xl
的效果. 第一步先完成 x l T w l x^T_l w_l xlTwl, 即:
xl_w = torch.tensordot(x_l, self.kernels[i], dims=([1], [0]))
这里需要了解下 torch.tensordot, 它将 x_l : [B, d, 1] 的 dim=1 这个维度的数据, 即 d 这个维度的数据, 也即特征, 和第
l
l
l 层的权重 kernels[i] : [d, 1] 的 dim=0 这个维度的数据, 也就是权重, 进行 element-wise 相乘并求和. 最终的效果就是 Shape 为 [B, d, 1] 的特征和 Shape 为 [d, 1] 的权重进行 tensordot 后得到 Shape 为 [B, 1, 1] 的结果.
第二步进行
x
0
x
l
T
w
l
x_0 x^T_l w_l
x0xlTwl, 由于前一步得到了
x
l
T
w
l
x^T_l w_l
xlTwl, 代码中表示为 xl_w, 那么这一步的结果为:
dot_ = torch.matmul(x_0, xl_w)
这时候得到的 dot_ Shape 和 x_0 相同, 均为 [B, d, 1]
最后一步是加上偏置以及输入自身:
x_l = dot_ + self.bias[i] + x_l
经过 layer_num 次循环后, 也即特征经过了
l
l
l 层后, 代码中的 x_l Shape 为 [B, d, 1], 因此还需进行最后一步:
x_l = torch.squeeze(x_l, dim=2)
得到大小为 [B, d] 的输入结果.
Deep Network
这个不多说, 里面可能会用到 Dropout, BN 之类的, 但作者在论文 4.2 节的实现细节中说没有发现 Dropout 或者 L2 正则化有效.
Deep Network 的公式化为:
h l + 1 = f ( W l h l + b l ) h_{l + 1} = f(W_l h_l + b_l) hl+1=f(Wlhl+bl)
Combination Layer
最后的输出层, 需要先将 Cross Network 与 Deep Network 的结果进行 Concatenation, 输入到 LR 模型 (对于 LR 模型, 可以详见文章 逻辑回归模型 Logistic Regression , 推导特别详细, 我都很感动 😂😂😂), 从而得到预测概率.
p = σ ( [ x L 1 T , h L 2 T ] w l o g i t s ) , σ ( x ) = 1 1 + e − x p = \sigma\left([x^T_{L_1}, h^T_{L_2}]w_{logits}\right), \quad \sigma(x) = \frac{1}{1 + e^{-x}} p=σ([xL1T,hL2T]wlogits),σ(x)=1+e−x1
损失函数为 LR 模型的 Negative Log Likelihood, 再加上 L2 正则项:
loss = − 1 N ∑ i = 1 N y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) + λ ∑ l ∥ w l ∥ 2 \text{loss} = -\frac{1}{N}\sum_{i=1}^{N}y_i\log(p_i) + (1 - y_i)\log(1 - p_i) + \lambda\sum_{l}\Vert \bm{w}_l\Vert^2 loss=−N1i=1∑Nyilog(pi)+(1−yi)log(1−pi)+λl∑∥wl∥2
使用 Adam 算法进行优化.
总结
文章介绍的 Cross Network 可以用于高效地对高阶组合特征进行显式学习, 组合特征的多项式阶数会随着网络深度的增加而增加. Cross Network 每一层的权重均为向量, 结构相对较简单, 参数相比 DNN 显著减少, 这也限制了模型的表达能力, 因此需要联合 DNN 训练, 两者优势互补.
参考资料
- Deep & Cross Networkfor Ad Click Predictions 论文资料
- DeepCTR-Torch 实现了经典的各种 CTR 模型, 非常推荐看源码学习.
- (读论文) 推荐系统之ctr预估-DCN模型解析 深入读论文系列

















 3254
3254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









