







一、前言
模型针对W&D的wide部分进行了改进, 因为Wide部分有一个不足就是需要人工进行特征的组合筛选, 过程繁琐且需要经验, 2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。于是乎,作者用一个Cross Network替换掉了Wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。
二、Deep&Cross模型
下面就来看一下DCN的结构:模型的结构非常简洁,从下往上依次为:Embedding和Stacking层、Cross网络层与Deep网络层并列、输出合并层,得到最终的预测结果。
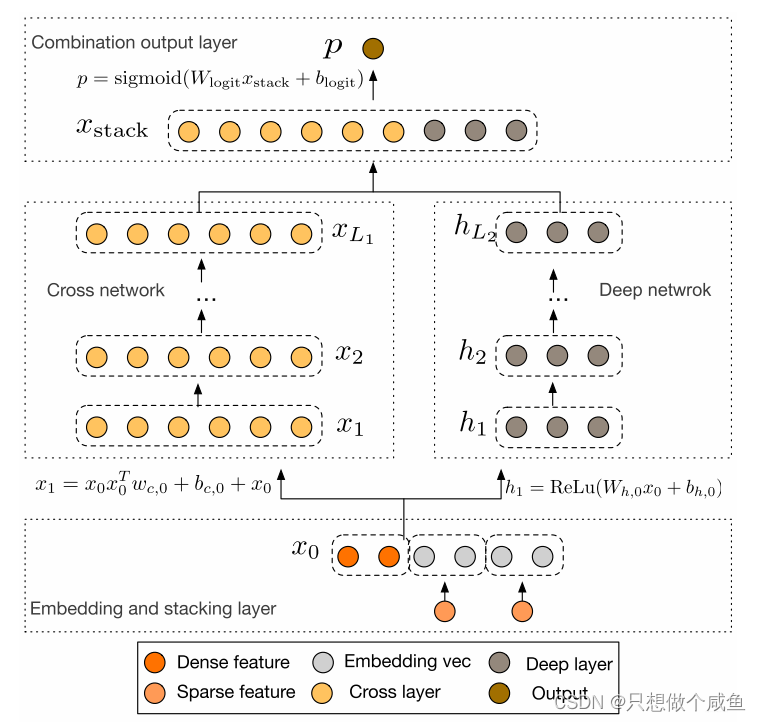
(1)Embedding and stacking layer
这里的作用依然是把稀疏离散的类别型特征变成低维密集型。
运用起来就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的Embedding向量
最后,该层需要将所有的密集型特征与通过embedding转换后的特征进行联合(Stacking)
(2) Cross Network
设计该网络的目的是增加特征之间的交互力度。 交叉网络由多个交叉层组成
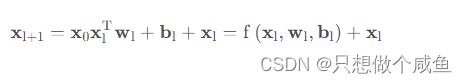
交叉层的操作的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量, 以及原输入向量
和偏置向量
。 交叉层的可视化如下:
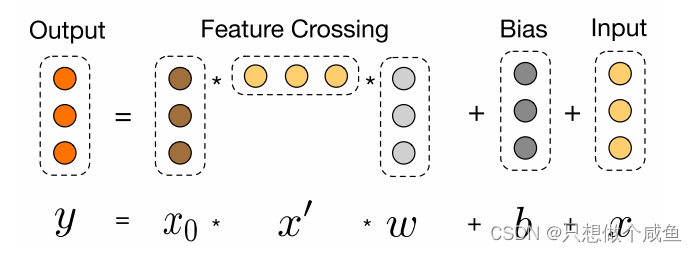
代码实现部分对应
# x是(None, dim)的形状, 先扩展一个维度到(None, dim, 1)
x_0 = torch.unsqueeze(x, dim=2)
x = x_0.clone() #32*221*1
xT = x_0.clone().permute((0, 2, 1)) # (None, 1, dim) 32*1*221
for i in range(self.layer_num):
x = torch.matmul(torch.bmm(x_0, xT), self.cross_weights[i]) + self.cross_bias[i] + x # (None, dim, 1)32*221*1 bmm(32*221*1,32*1*221), W=221*1, b=221*1
xT = x.clone().permute((0, 2, 1)) # (None, 1, dim) 是最开始的输入,一直保持不变,
是不断更新的,与权重+偏差 做内积
并且在每一层均保留了输入向量, 因此输入和输出之间的变化不会特别明显。
(3)Deep work
全连接层原理一样。

(4)组合层
负责将两个网络的输出进行拼接, 并且通过简单的Logistics回归完成最后的预测:
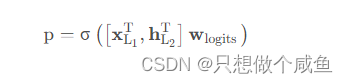
最后二分类的损失函数依然是交叉熵损失:
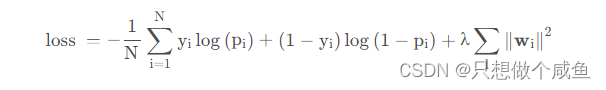
其核心部分就是Cross Network, 这个可以进行特征的自动交叉, 避免了更多基于业务理解的人工特征组合。 该模型相比于W&D,Cross部分表达能力更强, 使得模型具备了更强的非线性学习能力。
三、Deep&Cross模型的pytorch实现
(1)DNN网络
class Dnn(nn.Module):
"""
Dnn part
"""
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout: 失活率
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList(
[nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))]) #221*128*64
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x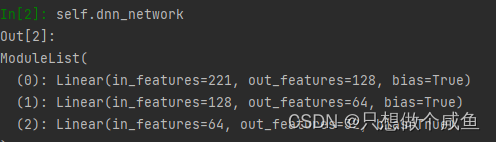
(2)cross_network
class CrossNetwork(nn.Module):
"""
Cross Network
"""
def __init__(self, layer_num, input_dim):
super(CrossNetwork, self).__init__()
self.layer_num = layer_num
# 定义网络层的参数 221*3 三个
self.cross_weights = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
self.cross_bias = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
def forward(self, x):
# x是(None, dim)的形状, 先扩展一个维度到(None, dim, 1)
x_0 = torch.unsqueeze(x, dim=2)
x = x_0.clone() #32*221*1
xT = x_0.clone().permute((0, 2, 1)) # (None, 1, dim) 32*1*221
for i in range(self.layer_num):
x = torch.matmul(torch.bmm(x_0, xT), self.cross_weights[i]) + self.cross_bias[i] + x # (None, dim, 1)32*221*1 bmm(32*221*1,32*1*221), W=221*1, b=221*1
xT = x.clone().permute((0, 2, 1)) # (None, 1, dim)
x = torch.squeeze(x) # (None, dim) 32*221 再降维
return x

(3)DCN网络
class DCN(nn.Module):
def __init__(self, feature_columns, hidden_units, layer_num, dnn_dropout=0.):
super(DCN, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
hidden_units.insert(0,
len(self.dense_feature_cols) + len(self.sparse_feature_cols) * self.sparse_feature_cols[0][
'embed_dim'])
self.dnn_network = Dnn(hidden_units)
self.cross_network = CrossNetwork(layer_num, hidden_units[0]) # layer_num是交叉网络的层数, hidden_units[0]表示输入的整体维度大小
self.final_linear = nn.Linear(hidden_units[-1] + hidden_units[0], 1)
def forward(self, x):
dense_input, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):] #32*13 32*26
sparse_inputs = sparse_inputs.long()
sparse_embeds = [self.embed_layers['embed_' + str(i)](sparse_inputs[:, i]) for i in
range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, axis=-1) #32*208 208=(26*8)
x = torch.cat([sparse_embeds, dense_input], axis=-1) #32*221
# cross Network
cross_out = self.cross_network(x) #32*221
# Deep Network
deep_out = self.dnn_network(x) #32*32
# Concatenate
total_x = torch.cat([cross_out, deep_out], axis=-1) #32*253
# out
outputs = F.sigmoid(self.final_linear(total_x))
return outputs
模型训练
# 模型的相关设置
def auc(y_pred, y_true):
pred = y_pred.data
y = y_true.data
return roc_auc_score(y, pred)
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
metric_func = auc
metric_name = 'auc'
# 脚本训练风格
epochs = 10
log_step_freq = 10
dfhistory = pd.DataFrame(columns=['epoch', 'loss', metric_name, 'val_loss', 'val_' + metric_name])
print('start_training.........')
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('========' * 8 + '%s' % nowtime)
for epoch in range(1, epochs + 1):
# 训练阶段
model.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features, labels) in enumerate(dl_train, 1):
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = model(features).squeeze()
loss = loss_func(predictions, labels)
try:
metric = metric_func(predictions, labels)
except ValueError:
pass
# 反向传播
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
print(("[step=%d] loss: %.3f, " + metric_name + ": %.3f") % (step, loss_sum / step, metric_sum / step));
# 验证阶段
model.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features, labels) in enumerate(dl_val, 1):
with torch.no_grad():
predictions = model(features).squeeze()
val_loss = loss_func(predictions, labels)
try:
val_metric = metric_func(predictions, labels)
except ValueError:
pass
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 记录日志
info = (epoch, loss_sum / step, metric_sum / step, val_loss_sum / val_step, val_metric_sum / val_step)
dfhistory.loc[epoch - 1] = info
# 打印日志
print((
"\nEPOCH=%d, loss=%.3f, " + metric_name + " = %.3f, val_loss=%.3f, " + "val_" + metric_name + " = %.3f") % info)
nowtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print('\n' + '==========' * 8 + '%s' % nowtime)
print('Finished Training')
测试集的预测
y_pred_probs = model(torch.tensor(test_x).float())
y_pred = torch.where(y_pred_probs>0.5, torch.ones_like(y_pred_probs), torch.zeros_like(y_pred_probs))
print(y_pred.data)
总结
W&D开启了组合模型的探索之后,DCN也是替换掉了wide部分, 后面又出现了几个FM的演化版本模型, 比如FNN, DeepFM和NFM, 后面也会陆续整理!!















 1356
1356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









