






from time import sleep # 从time模块中导入sleep函数,可以让程序暂停指定的秒数。
from scipy.io import loadmat # 导入scipy库中的loadmat模块,用于加载.mat格式的文件
import numpy as np # 导入numpy库,用于进行数值计算和数组操作
import os # 导入os库,用于处理文件和目录操作
from sklearn import preprocessing # 0-1编码
from sklearn.model_selection import StratifiedShuffleSplit # 随机划分,保证每一类比例相同
def prepro(d_path, length=0, number=0, normal=True, rate=[0, 0, 0], enc=False, enc_step=28):
"""
预处理函数,对输入的数据进行预处理,包括截取、采样、归一化和编码等操作。
参数:
d_path: str,数据文件夹路径
length: int,每个样本的长度,默认为0
number: int,每类样本的数量,默认为0
normal: bool,是否进行标准化,默认为True
rate: list,采样率,默认值为[0, 0, 0]
enc: bool,是否进行编码,默认为False
enc_step: int,编码步长,默认为28
"""
# 获得该文件夹下所有.mat文件名
filenames = os.listdir(d_path)
# 定义一个函数,名为capture,输入参数是original_path,返回值是一个字典类型的变量files
def capture(original_path):
# 创建一个空字典,用于存储文件名及其对应的数据
files = {}
# 遍历原始路径下的所有文件名
for i in filenames:
# 使用os.path.join()函数将目录路径和文件名拼接成完整的文件路径
file_path = os.path.join(d_path, i)
# 使用loadmat()函数加载.mat文件,并将其内容存储在变量file中
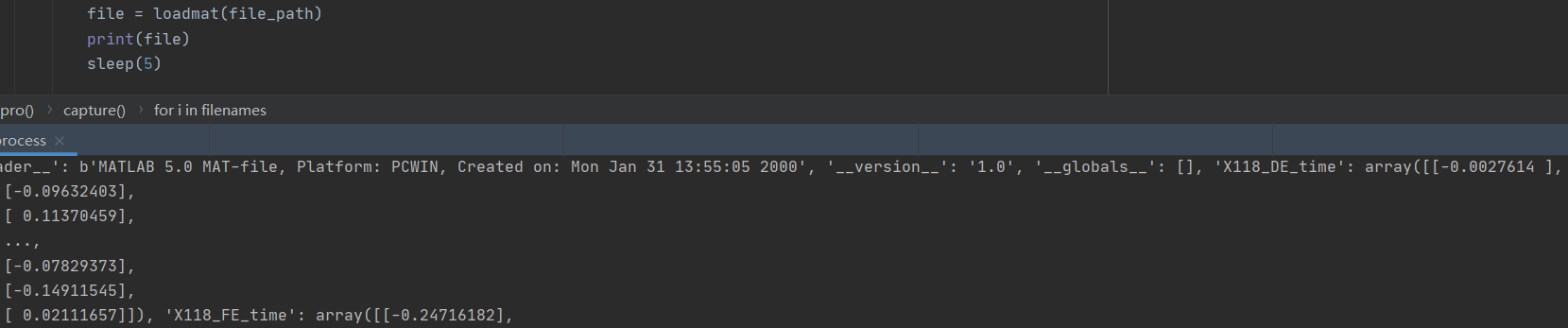
file = loadmat(file_path)
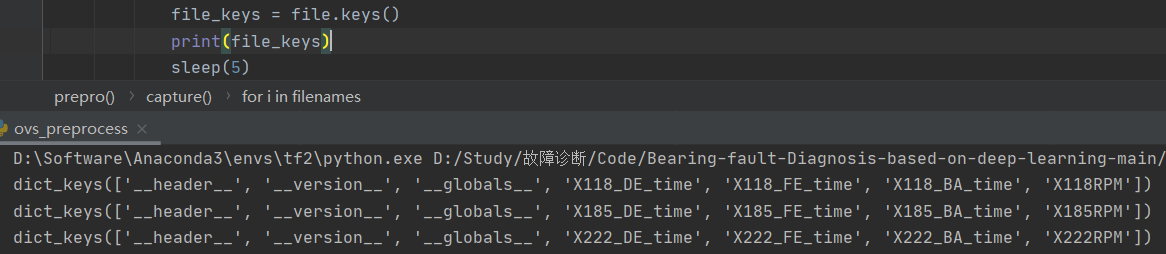
# 获取file中所有的键(即变量名)
file_keys = file.keys()
# 遍历file中的所有键
for key in file_keys:
# 如果键中包含'DE',则将该键和对应的值存储在files字典中,键为文件名,值为一维数组
if 'DE' in key:
files[i] = file[key].ravel()
# 返回存储了文件名及其对应数据的字典
return files
def slice_enc(data, slice_rate=rate[1] + rate[2]): # slice_rate = 0.5 = 0.25 + 0.25
# 函数定义,接受一个名为data的字典参数和一个名为slice_rate的可选参数,默认值是rate[1] + rate[2]
keys = data.keys()
# 从字典data中获取所有键,保存到keys中
Train_Samples = {}
# 创建一个空字典Train_Samples用于存储训练样本
Test_Samples = {}
# 创建一个空字典Test_Samples用于存储测试样本
for i in keys:
# 遍历字典data的键
slice_data = data[i]
# 获取当前键i对应的值,即数据切片
all_length = len(slice_data)
# 获取切片数据的总长度
# end_index = int(all_lenght * (1 - slice_rate))
samp_train = int(number * (1 - slice_rate)) # 300(1-0.5)
# 计算用于训练的样本数
Train_sample = []
# 创建一个空列表Train_sample用于存储训练样本
Test_Sample = []
# 创建一个空列表Test_Sample用于存储测试样本
for j in range(samp_train):
# 遍历训练样本数的次数
sample = slice_data[j*150: j*150 + length]
# 从slice_data中获取一个样本,每个样本从j*150到(j*150 + length)的范围
# [0:0*150+784],[1*150:1*150+784]...
Train_sample.append(sample)
# 将样本添加到训练样本列表Train_sample中
# 抓取测试数据
for h in range(number - samp_train): # 样本数量-训练样本
# 计算 sample 变量,从 slice_data 中切片一个子序列
# 切片的位置是基于 samp_train、length 和 h 的值计算的
sample = slice_data[samp_train*150 + length + h*150: samp_train*150 + length + h*150 + length]
# 将 sample 添加到 Test_Sample 列表中
Test_Sample.append(sample)
# 将 Train_Sample 存储在 Train_Samples 列表的索引 i 处
Train_Samples[i] = Train_sample
# 将 Test_Sample 存储在 Test_Samples 列表的索引 i 处
Test_Samples[i] = Test_Sample
# 最终返回 Train_Samples 和 Test_Samples 列表
return Train_Samples, Test_Samples
# 仅抽样完成,打标签
# 创建一个函数 add_labels,用于为每个数据子集添加标签
def add_labels(train_test):
# 初始化两空列表 X 和 Y,用于存储特征数据和标签数据
X = []
Y = []
# 初始化标签(label),起始值为0
label = 0
# 遍历数据子集标识符列表 filenames
for i in filenames:
# 从传递给函数的 train_test 字典中获取当前数据子集 i 的特征数据,存储在变量 x 中
x = train_test[i]
# 将当前数据子集的特征数据 x 添加到 X 列表中,合并成一个大的特征数据集
X += x
# 计算当前数据子集特征数据 x 的长度,以确定该子数据集中的样本数量
lenx = len(x)
# 将长度为 lenx 的标签列表 [label] 添加到 Y 列表中,将每个样本与相应的标签 label 关联起来
Y += [label] * lenx
# 增加标签 label 的值,以便为下一个数据子集分配不同的标签
label += 1
# 最后,函数返回两个列表 X 和 Y,X 包含特征数据,Y 包含相应的标签数据
return X, Y
def scalar_stand(Train_X, Test_X):
"""
用训练集标准差标准化训练集以及测试集
参数:
Train_X, Test_X: list,训练集和测试集的特征列表
返回值:
Train_X, Test_X,分别为标准化后的训练集和测试集的特征列表
"""
# 用训练集标准差标准化训练集以及测试集
data_all = np.vstack((Train_X, Test_X))
scalar = preprocessing.StandardScaler().fit(data_all)
Train_X = scalar.transform(Train_X)
Test_X = scalar.transform(Test_X)
return Train_X, Test_X
def valid_test_slice(Test_X, Test_Y):
"""
将测试集切分为验证集和测试集
参数:
Test_X, Test_Y: list,测试集的特征列表和标签列表
返回值:
X_valid, Y_valid, X_test, Y_test,分别为验证集和测试集的特征列表和标签列表
"""
test_size = rate[2] / (rate[1] + rate[2])
ss = StratifiedShuffleSplit(n_splits=1, test_size=test_size)
Test_Y = np.asarray(Test_Y, dtype=np.int32)
for train_index, test_index in ss.split(Test_X, Test_Y):
X_valid, X_test = Test_X[train_index], Test_X[test_index]
Y_valid, Y_test = Test_Y[train_index], Test_Y[test_index]
return X_valid, Y_valid, X_test, Y_test
# 从所有.mat文件中读取出数据的字典
data = capture(original_path=d_path)
# 将数据切分为训练集、测试集
train, test = slice_enc(data)
# 为训练集制作标签,返回X,Y
Train_X, Train_Y = add_labels(train)
# 为测试集制作标签,返回X,Y
Test_X, Test_Y = add_labels(test)
# 训练数据/测试数据 是否标准化。
if normal:
Train_X, Test_X = scalar_stand(Train_X, Test_X)
Train_X = np.asarray(Train_X)
Test_X = np.asarray(Test_X)
# 将测试集切分为验证集和测试集。
Valid_X, Valid_Y, Test_X, Test_Y = valid_test_slice(Test_X, Test_Y)
return Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
num_classes = 10 # 样本类别,10分类
length = 784 # 样本长度,轴承旋转一周采样点约480
number = 300 # 每类样本的数量,总数=300*10=3000
normal = True # 是否标准化
rate = [0.5, 0.25, 0.25] # 训练集测试集验证集划分比例
path = r'data/0HP'
x_train, y_train, x_valid, y_valid, x_test, y_test = prepro(
d_path=path,
length=length,
number=number,
normal=normal,
rate=rate,
enc=False, enc_step=28)
x_train = np.array(x_train)
y_train = np.array(y_train)
x_valid = np.array(x_valid)
y_valid = np.array(y_valid)
x_test = np.array(x_test)
y_test = np.array(y_test)
print(x_train.shape) # (1500, 784),3000*0.5=1500
```
关于sample = slice_data[samp_train*150 + length + h*150: samp_train*150 + length + h*150 + length]
`sample` 的计算方式是为了从 `slice_data` 中提取特定范围的子序列(或子样本)。让我们分解这个计算方式:
- `samp_train` 控制了训练样本的数量,这个数量已经在之前的计算中确定。
- `150` 和 `length` 是常数,用于计算切片位置的偏移量。 `150` 似乎是一个步长,而 `length` 是子样本的长度。
- `h` 是一个循环变量,用于迭代从 `0` 到 `number - samp_train - 1`,以生成多个测试样本。
现在,让我们将 `sample` 的计算方式拆分为几个步骤:
1. `samp_train * 150`: 这部分用于计算训练样本的长度。因为 `samp_train` 控制了训练样本的数量,而 `150` 是步长,所以这部分计算得到了训练样本所占的总长度。
2. `length`: 这是子样本的长度。这部分用于确定每个子样本的长度。
3. `h * 150`: 这部分用于计算测试样本的偏移量。随着 `h` 的增加,偏移量也会增加,以便生成不同位置的测试样本。
综合起来,上述计算方式使用 `samp_train` 控制训练样本的长度,`length` 控制子样本的长度,并且使用 `h` 控制测试样本的偏移量,从 `slice_data` 中切片出测试样本。每次迭代时,`sample` 会移动到不同位置,从而生成一系列不同的测试样本。这种方法使得可以在不同的位置截取测试样本,用于模型训练和评估。















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









