







 本文深入探讨word2vec的原理,包括CBOW和skip-gram模型,以及优化策略如分层softmax和负采样。同时介绍了word2vec在TensorFlow中的实现。
本文深入探讨word2vec的原理,包括CBOW和skip-gram模型,以及优化策略如分层softmax和负采样。同时介绍了word2vec在TensorFlow中的实现。
word2vec
内容源自对论文的理解。
Introduction
字词的向量空间模型依靠将语意相近的词语聚在一起来提高自然语言处理的表现。比如训练集中可能会有句子1.the dog is walking和句子2.the cat is walking。很明显因为dog和cat的 上下文(context) 的概率分布很相似,出现dog的句子中,将dog换成cat也很有可能得到一个合法的句子,而将dog换成一个其他一些和dog上下文概率分布不相似的词,就很有可能得到一个不太可能合法的词,比如beautiful。
因此自然有了将相似词(指上下文相似,下同)聚集到一起,将不相似词远离的处理思想。这样也会缩减后续处理中预测误差对最终结果的影响。如果未做上述处理,最终一点
利用人工神经网络训练的字词向量非常有趣,因为它可以用来编码许多线性翻译的模式。比如:利用向量关系表示:Madrid 之于 Spain = Paris 之于 France :
vec(“Madrid”) - vec(“spain”) = vec(“Paris”) - vec(“France”).因此对于一个好的训练结果往往可以通过计算 与vec(“Paris”) + vec(“Spain”) - vec(“Marid”)向量最近的词来求出 France.
这叫作类别推理,这也是目前检测一个词向量系统质量的常用方法。
The Model
cbow(连续词袋模型)利用词语的上下文来预测词语。与之相反,skip-gram利用词语来预测它的上下文。
具体来说,给定一个训练的句子:w1,w2,w3,…,wt.skip-gram模型的目标是最大化以下极大似然估计:
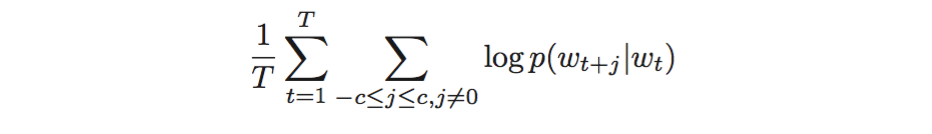
其中t表示单词表中的词数。j表示上下文窗口的大小。
一种比较直观的模型构建方式如下(skip-gram model):
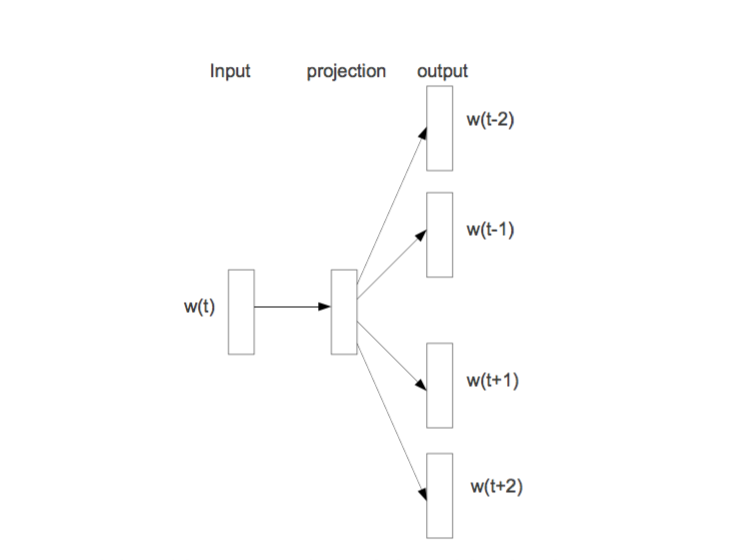
输入一个词的向量表示,利用一个隐含层进行抽象,输出层节点数目等于单词表中词的数目。表示预测各词组成输入词上下文的概率,通常选用softmax来表示输出。
损失函数常选以上极大似然估计的相反数。可以选用一些常见的,如随机梯度下降(SGD)来训练模型。
以上都是skip-gram model的模型表示和训练方法。
cbow model与之大同小异。只是输入由一个单词变成了一个词袋(若干个单词)。
Optimize
以上模型表示的一大缺点是,训练数据量较大时,往往导致单词表中的单词数目很大,在每次前后向传播时,计算softmax将时一个很大的开销。
因此有人提出了使用分层softmax的方法来替代普通的softmax,它在几乎不太影响模型效果的前提下,大大提高了模型的训练速度,真正使模型变得实用。
主要思想是,构造一颗二叉树,使得单词表中的单词均为二叉树的叶子节点。该叶子节点的概率为:从二叉树的根节点到该叶子节点的路径上各个节点与输入单词的向量点乘的连乘:
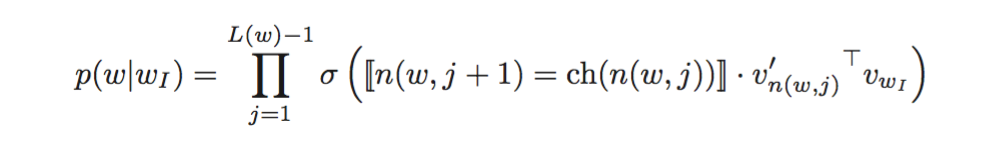
并选择任意方向,如向左为正方向,向右为负方向,利用sigmoid作为概率激活函数。
这样计算每个输入时softmax的计算复杂度由原来的O(n)变成了log(n)。
其实上述分层softmax利用了二分类的思想。每次为一个单词从两个抽象分类中选择其中一种,利用sigmoid函数为两个类分配概率。一直对单词分类直到标定清楚一个单词的具体表示。
就像这样:只不过,下图每个决策点不全是二分类。
因此训练结果中的二叉树的非叶子节点都表示某一抽象类。
构造二叉树的方法有很多,不同构造方法会对计算效率和准确率有略微的影响。
一种常见方法是根据单词的词频构建huffman编码树。可以利用编码01标记每次的正负概率。更重要的思想是,是高频词汇路径短,提高上式连乘速度。
More
其他优化还有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









