







一、安装labelme
深度学习算法等基于神经网络的算法都是基于数据驱动的,数据的好坏会影响你最后生成的模型的好坏,在使用Mask-RCNN时,第一件事就是标注数据集,这里我们默认你已经配置好了anaconda的环境,如果你没有配置好可以参考一下其他人的博客,在已经配置好的conda环境下新建一个虚拟环境,在终端中输入以下命令安装标注工具labelme:
pip install labelme
pip install pyqt5
pip install pillow==4.0.0二、标注数据集
下一步开始标注数据,在终端中输入下面的代码会自动打开标注工具:
labelme
接着选择第二项打开文件夹,如下图所示:
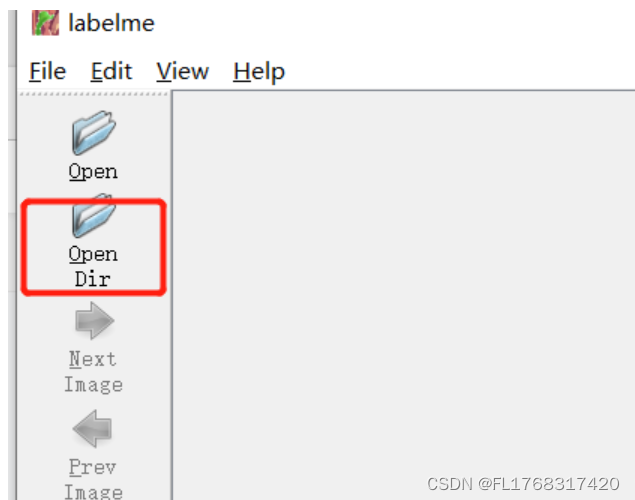
选择数据图片所在文件夹,右键对图片逐个标注。并填写标签信息。标注好后点击D切换到下一张,这里会弹出保存界面,直接保存到我们原图像所在文件夹即可。将图片全部标注好后,得到如下的全部json文件后,关闭终端。

三、批量处理Json文件
现在的.json包含了我们标注的信息,但是还不是可以让代码直接读取的数据格式,对于不同的深度学习代码,数据存放的格式要根据不同代码的写法来定,下面以上述的mask-rcnn为例,将数据修改为我们需要的格式。在保存.json文件的文件夹下新建一个.txt文件,输入以下内容:
@echo off
for %%i in (*.json) do labelme_json_to_dataset "%%i"
pause保存后将文件后缀名改为.bat,将其改为一个更改文件的存放格式的脚本,保存后双击运行即可。运行后等一会,会得到如下文件夹。
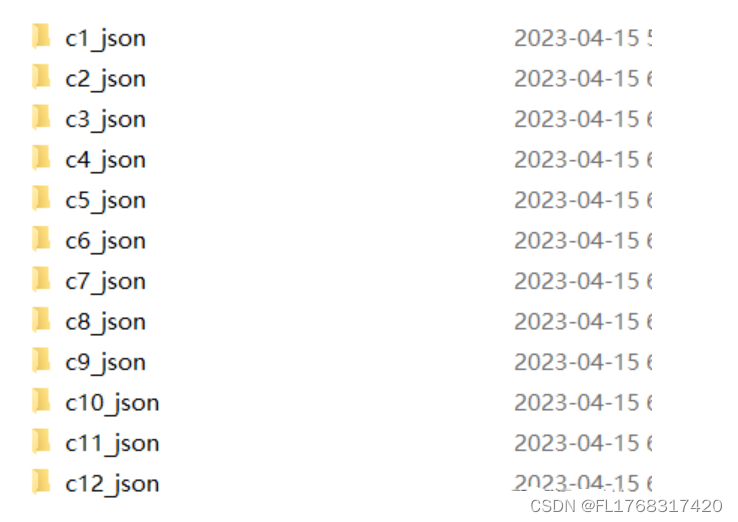
如下图所示建立文件夹:

labelme_json文件夹存放的是上一步中得到的文件夹。
json文件夹存放的是标注得到的.json文件。
pic文件夹存放的是原图。
以上三个文件夹存放的东西直接复制粘贴过来即可,这里有一个小技巧,在电脑上的文件的排序中可以选择按文件类型排序,这样可以方便我们复制粘贴。
cv2_mask存放的是上一步中得到的文件夹中生成的后缀为.png的mask文件,大概内容如下:

将.png文件复制逐个复制进文件夹并重命名比较麻烦,这里我们写一个python脚本copy.py文件进行批量操作:
import os
import shutil
for dir_name in os.listdir('./labelme_json'):
pic_name = dir_name[:-5] + '.png'
from_dir = './labelme_json/'+dir_name+'./label.png'
to_dir = './cv2_mask/'+pic_name
shutil.copyfile(from_dir, to_dir)
print (from_dir)
print (to_dir)将上述文件.py文件保存到如下目录,运行即可:

到此我们的数据集制作完毕。
四、下载Mask-RCNN源码
下载修改过后的代码(想要修改版的代码可以加qq群:817442229或直接加博主的qq:2425113371免费领取),并将我们制作好的数据集改名为mydata放到该文件夹下即可直接使用,也可以下载官方版代码,但是官方版需要对代码有深入的理解才能使用,下面附上官方版源码的github链接,新手建议直接找我拿源码:Release Mask R-CNN 2.0 · matterport/Mask_RCNN · GitHub
五、环境搭建
搞深度学习的对conda这个工具应该不陌生,这里我们假设你已经安装好conda这个管理虚拟环境的工具。直接在base下新建一个虚拟环境,这个源码开发的时间比较久远,python版本太高会导致后续出现很多问题,最好使用python2进行环境搭建,但是我这里使用python3版本进行搭建,你直接跟着我来用python3也没问题,搭建好环境后还需要修改源码(后面再说):
conda create -n MaskRCNN python=3.6创建好后使用如下命令激活环境:
source activate MaskRCNN这里在ubuntu系统下应该是:
conda activate MaskRCNN接下来在该环境下安装tensorflow,注意,这里tensorflow不能过高也不能过低,我使用的是1.5.0版本,千万不要不指定版本,不指定版本默认下载最高版,后面跑程序会有问题:
pip install tensorflow==1.5.0这里也可以下载gpu版本,gpu版跑起来会比cpu快很多,但是gpu版本的tensorflow和cuda和cudnn有版本的对应关系,想用gpu版本很可能需要重装cuda和cudnn:
pip install tensorflow-gpu==1.5.0这里对应的cuda版本是9.0,到pytorch官网查看对应的pytorch版本,然后利用pytorch帮我们安装cuda和cudnn:
conda install pytorch==1.1.0 torchvision==0.3.0 cudatoolkit=9.0 -c pytorch
可以使用如下代码查看是否安装成功:
import torch
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())
print(torch.cuda_version)
print(torch.backends.cudnn.version())运行结果打出两个true就说明配置成功,最后两行可能由于版本原因会报错,但是没关系,忽略即可,接着往下做。
下面再安装keras,注意,keras的版本要和tensorflow对应:
pip install keras==2.1.6如果下载过于缓慢,考虑换源,在上述代码后-i换源,举例如下,安装其他包的时候也可以如法炮制,非常好用:
pip install keras==2.1.6 -i https://pypi.tuna.tsinghua.edu.cn/simple安装好后,用pycharm打开代码文件夹,点击下方的terminal,在这里可以使用下面代码安装requirements.txt中的所有需要的包:
pip install -r requirements.txt如果下载后没有问题且能运行代码,即说明环境以及配置完毕。但是大概率会失败,因为博主就失败了...,如果使用这个方式失败了,就要逐个安装requirements.txt中的包:
pip install numpy
pip install scipy
pip install Pillow
pip install cython
pip install matplotlib
pip install scikit-image
pip install opencv-python
pip install h5py
pip install imgaug
pip install IPython[all]逐行运行上述代码,建议每安装好一个包后都要运行一遍测试代码,以测试tensorflow是否还能正常工作,因为有些包的版本对应不上可能会影响tensorflow,下面是测试代码:
import tensorflow as tf
import keras
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()如果你在未安装requirements.txt下面的包时上述代码报错,大概率是tensorflow和numpy的版本不对应导致出现问题。我使用的numpy版本是1.16.0,这是恰好能运行所有包且和tensorflow1.5.0兼容的最低版本:
pip install numpy==1.16.0如果numpy的版本更改后任然报错,可能是python3的编码格式问题,将topology.py下面的所有的.decode('utf8')前加入如下图所示即可:

在安装opencv-python的时候,大概率会报错,因为默认下载的是最高版本,最高版本的cv与tensorflow==1.5.0不兼容,我使用的是:
pip install opencv-python==4.3.0.38安装完以上的包,运行代码可能还会出现警告:

这个警告出现的原因是scikit-image的版本不兼容,使用如下命令重新安装即可:
pip install -U scikit-image==0.16.2至于其他的警告无关痛痒,忽略即可,但是红红的报错看起来非常不爽,可以在代码的最前面加入以下内容进行屏蔽:
# 版本不兼容报错,直接忽略
import warnings
warnings.filterwarnings("ignore")
六、对下载好的源码进行修改
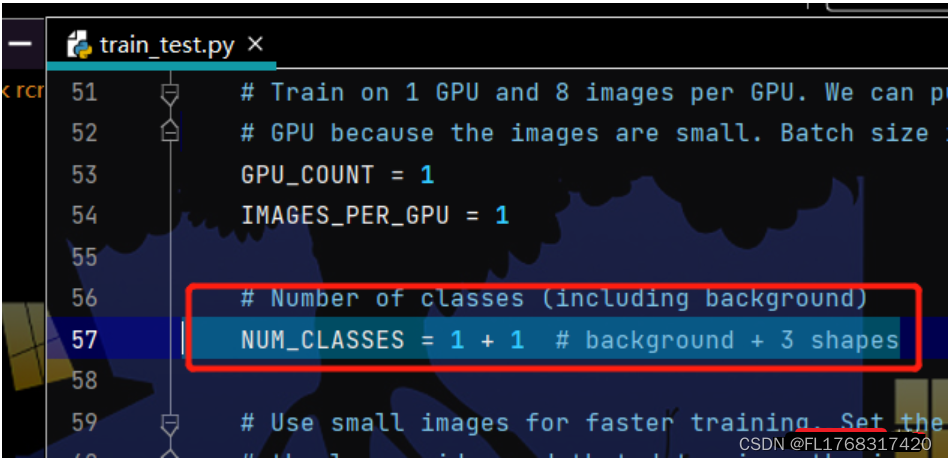
1、修改train_test.py的第57行,改为类别数+1。
2、修改train_test.py的121行,将原有的注释掉,有多少类别就重新写多少行,每行第二个参数是序号,第三个参数是类别名。

3、修改train_test.py的178~182行,修改为自己的路径,这里使用的是相对路径,如果你的dataset是按照我前面所说的方式放置,其实这里也可以不用改。

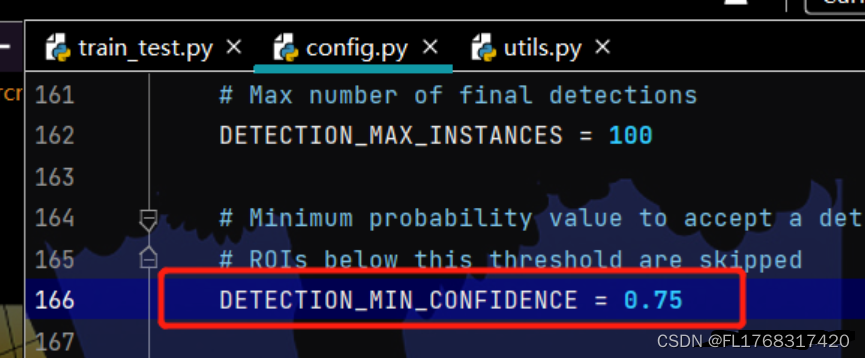
4、修改config.py下的DETECTION_MIN_CONFIDENCE,调小这个值可以获得更多的预测结果。
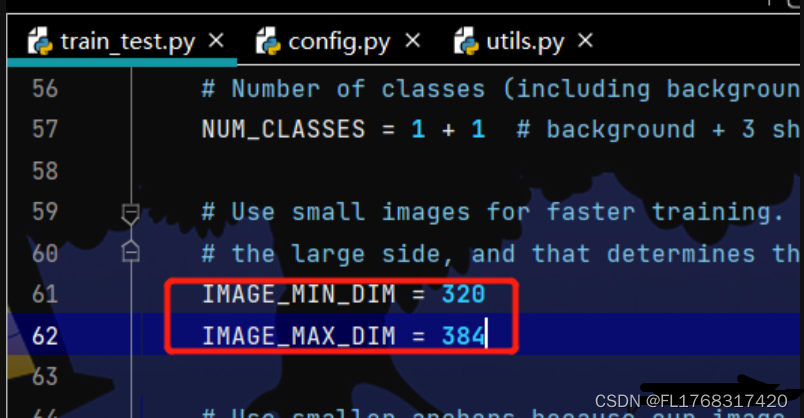
5、修改train_test.py的61~62行可以指定图片大小。
6、修改train_test.py的160~163行。

其余参数无需修改,完成之后运行train_test文件即可开始训练。
七、测试代码
运行测试代码要安装pycocotools,运行:
pip install pycocotools若出现如下报错:

说明缺少Microsoft Visual C++ 14.0这个东西,去以下地址安装即可:
https://my.visualstudio.com/Downloads?q=build%20tools
搜索build tools,下载DVD格式的build tools:
 下载完成后安装。但该方法会占用极大的内存,一种更加直接的方法,在终端运行:
下载完成后安装。但该方法会占用极大的内存,一种更加直接的方法,在终端运行:
conda install libpython m2w64-toolchain -c msys2具体内容可以参考:
Microsoft Visual C++ 14.0 is required.-CSDN博客
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











