






什么是决策树
基本结构:
决策树是一种树状模型,其中每个节点表示一个特征,每个分支表示该特征的一个可能值,而每个叶节点表示一个类标签(分类)或一个连续值(回归)
单模型:
决策树是一个单一的模型,它通过递归地对数据进行分割,直到满足某些停止条件(如最大深度或最小样本数)为止
什么是随机森林
基本结构:
随机森林是一种集成学习方法,它通过构建多个决策树(通常称为“森林”)并结合它们的预测结果来进行决策,每棵树是在一个不同的子集(通过Bootstrap抽样)上训练的,并且在每个节点分裂时,只考虑特征的一个随机子集
集成模型:
随机森林由多棵决策树组成,通过对所有树的预测结果进行投票(分类)或平均(回归)来生成最终的预测结果
通过了解决策树和随机森林的关系,接下来利用这种关系进行决策树到随机森林的可视化,决策树详细原理可参考早期文章决策树算法-CART分类树算法实现及其可解释性绘图
代码实现
数据读取预处理
import pandas as pd
df = pd.read_excel('iris.xlsx')
# 使用 pandas 的 factorize 方法进行编码
encoded_values, unique_classes = pd.factorize(df['class'])
# 将编码值加入到 DataFrame 中
df['Class_encoded'] = encoded_values
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
train_X, test_X, train_y, test_y = train_test_split(df.iloc[:, 0:4], df['Class_encoded'],
test_size=0.2, random_state=42, stratify=df['Class_encoded'])
# 初始化 MinMaxScaler
scaler = MinMaxScaler()
# 对 train_X 进行归一化处理
train_X = scaler.fit_transform(train_X)
# 使用 train_X 的归一化统计量对 test_X 进行归一化
test_X = scaler.transform(test_X)加载Iris数据集,对类别标签进行编码,划分训练集和测试集,并对特征进行归一化处理,为接下来构建模型做准备
决策树模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
# 初始化并训练决策树模型
clf = DecisionTreeClassifier(random_state=42)
clf.fit(train_X, train_y)
# 预测
predictions = clf.predict(test_X)
# 输出分类报告
report = classification_report(test_y, predictions, target_names=unique_classes)
print(report)
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 可视化决策树
plt.figure(figsize=(20, 20), dpi=200)
plot_tree(
clf,
feature_names=df.columns[0:4], # 使用 df 的列名作为特征名称
class_names=unique_classes,
filled=True
)
plt.savefig('决策树.png')
plt.show()

这里针对鸢尾花分类任务训练得到的决策树,可视化展示了决策树的“玻璃箱”结构,按照惯例,在一个节点中满足条件的子节点位于左侧分支
解释:树的根节点是通过对"sepal length "特征进行条件判定,如果其值小于等于0.233,则进入左子树,否则进入右子树,其它节点类似,最后的叶节点表示决策树的最终分类结果,每个叶节点包含样本的基尼不纯度(gini)和样本数量(samples),以及每个类别的样本数量和类别(class)
随机森林模型
from sklearn.ensemble import RandomForestClassifier
# 初始化并训练随机森林模型
rf_clf = RandomForestClassifier(random_state=42, n_estimators=20)
rf_clf.fit(train_X, train_y)
# 从随机森林中提取一棵决策树
estimator = rf_clf.estimators_[0] # 提取第一棵树
# 预测
predictions = rf_clf.predict(test_X)
# 输出分类报告
report = classification_report(test_y, predictions, target_names=unique_classes)
print(report)
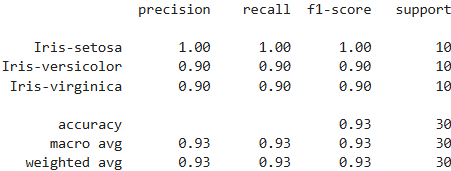
在随机森林中,n_estimators参数表示随机森林中包含的决策树的数量,这里为10表示存在10棵决策树,增加其值通常可以提高模型的预测性能,因为更多的树可以更好地捕捉数据的复杂模式,性能提升会逐渐减小,但是请提防模型过拟合
plt.figure(figsize=(20, 20), dpi=200)
plot_tree(
estimator,
feature_names=df.columns[0:4], # 使用 df 的列名作为特征名称
class_names=unique_classes,
filled=True
)
plt.show()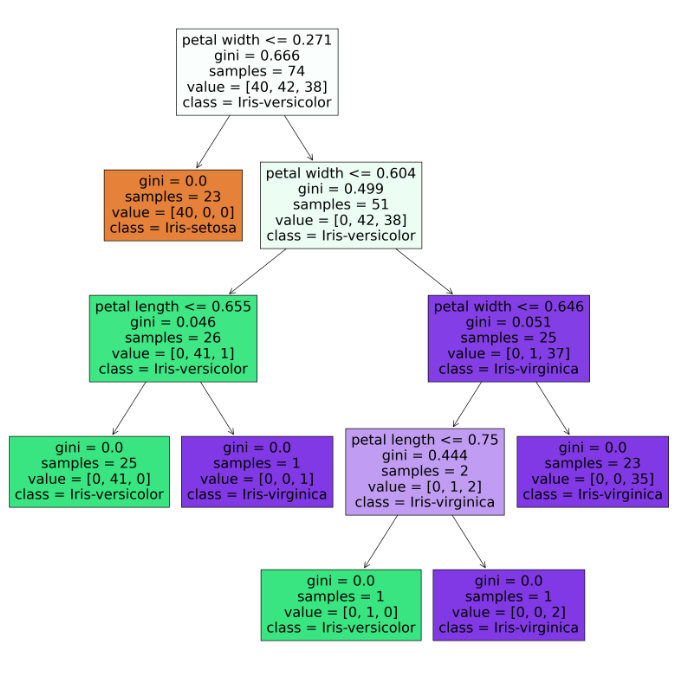
这里的可视化为第一棵决策树,接下来绘制随机森林里面的所有决策树
# 可视化所有提取的决策树
fig, axes = plt.subplots(nrows=5, ncols=4, figsize=(40, 50), dpi=200)
for i in range(20):
ax = axes[i // 4, i % 4]
plot_tree(
rf_clf.estimators_[i],
feature_names=df.columns[0:7], # 使用 df 的列名作为特征名称
class_names=unique_classes,
filled=True,
ax=ax
)
ax.set_title(f'Tree {i+1}')
plt.savefig('随机森林.png')
plt.tight_layout()
plt.show()
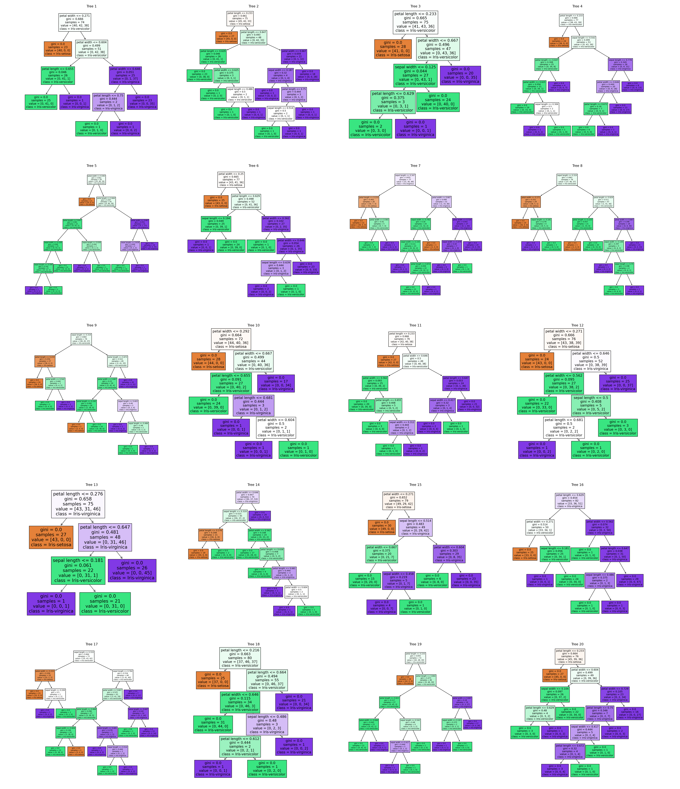
这就是这个随机森林存在的20棵决策树的决策过程,每棵树都会对输入样本进行预测,并根据多数投票的结果来确定最终样本的分类
如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











