







二叉搜索树
概念
二叉搜索树又称二叉排序树,它或者是空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有结点的值都小于根结点的值
- 若它的右子树不为空,则右子树上所有结点的值都大于根结点的值
- 它的左右子树也分别为二叉搜索树
如下图即为一颗二叉搜索树:
**值得注意的是:**二叉搜索树通过中序遍历得到的序列是升序的。如上得到序列:1 3 4 6 7 8 10 13 14
性能分析
二叉树有多高,搜索的最大次数就是多少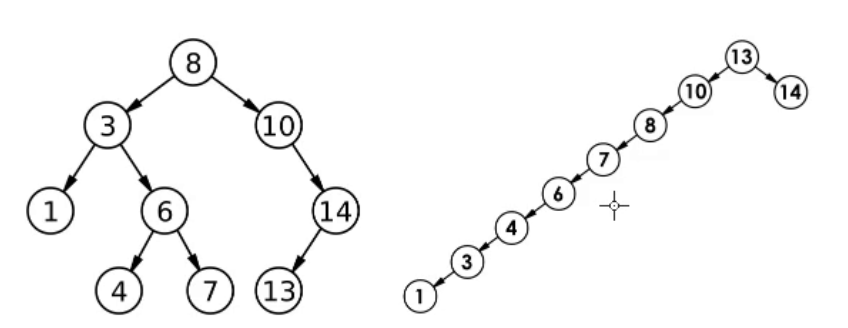
普通的二叉搜索树搜索的最坏时间复杂度是O(N),如上面的右图;最好时间复杂度是O(logN),如上面的左图
二叉搜索树的实现
框架设计
template<class K>
struct BSTreeNode
{
BSTreeNode(const K& key)
:_left(nullptr)
, _right(nullptr)
, _key(key)
{}
BSTreeNode* _left;
BSTreeNode* _right;
K _key;
};
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
…………
private:
Node* _root;
};
中序遍历
给出中序遍历,方便对二叉搜索树进行打印
public:
//中序遍历
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
之前的中序遍历是只有下面的void _InOrder(Node* root)这一个函数的。但由于_root是私有成员,我们无法在外部获取_root并将其作为参数传入_InOrder中。因此采取了上述再套一层函数的方法。
这种方法在后面实现二叉搜索树递归实现时会频繁使用。
其实也可以用
GetRoot函数在外部获取_root,但没有上述好。上述既不暴露根结点,也能实现中序遍历
二叉搜索树的非递归实现
插入
bool Insert(const K& key)
{
//如果树为空,直接新增结点赋值给_root
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
//插入的值比根值大则插入右边
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if (key < cur->_key)//插入的值比根值小则插入左边
{
parent = cur;
cur = cur->_left;
}
else//和根值一样大,说明不需要再插入
{
return false;
}
}
cur = new Node(key);
//虽然cur已经到达正确的位置,但我是不知道是在parent左边还是右边的,所以还需要判断一下
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
查找
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
//比根值大
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)//比根值小
{
cur = cur->_left;
}
else//和根值一样大,说明不需要再插入
{
cout << "找到了" << endl;
return true;
}
}
return false;
}
删除
删除相较于插入和查找复杂很多,也是经常考察的地方
待删除结点有四种情况:
- 要删除的结点无孩子结点
- 要删除的结点只有左孩子结点
- 要删除的结点只有右孩子结点
- 要删除的结点左右孩子结点都有
但实际上第1种情况可以归为第2或3种情况中的任意一种(如果情况2的代码先写,那么情况1就走情况2的代码)
因此真正的删除过程如下:
- 情况2:删除该结点且使被删除结点的父节点指向被删除结点的左孩子结点
- 情况3:删除该结点且使被删除结点的父节点指向被删除结点的右孩子结点
- 情况4:找出被删除结点的左子树的最大结点或者右子树的最小结点,将被删除结点与该结点交换值。至此情况变成了1或2或3中的一种,再处理该结点的删除问题
针对情况2和情况3,为直接删除
针对情况4,为间接删除,又称替换法
情况1和情况2和情况3
//被删除结点的左边为空
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (parent->_right == cur)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
}
else if (cur->_right == nullptr)//被删除结点的右边为空
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (parent->_right == cur)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
}
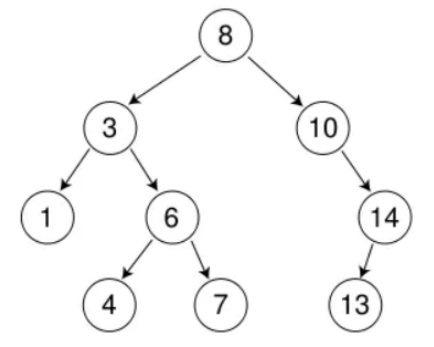
假设要删除4,对应情况1。由于上述代码在删除部分,先写的“被删除结点左边为空”的情况,因此被删除结点左右都为空也是走的这种情况。
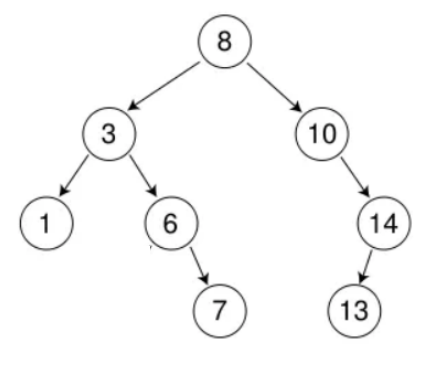
假设要删除6,对应情况2。但这里还有一种特殊情况,即被删除结点是根结点: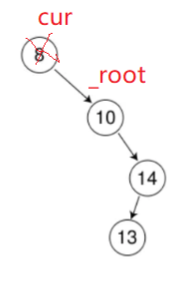
由于被删除的结点是根节点,而根节点没有父结点
情况4
else//左右都不为空,替换法
{
//找替换结点,左边最大或右边最小
Node* parent = cur;
Node* maxleft = cur->_left;
while (maxleft->_right)
{
parent = maxleft;
maxleft = maxleft->_left;
}
//这里找出左边最大并交换
swap(cur->_key, maxleft->_key);
if (parent->_left == maxleft)
{
parent->_left = maxleft->_left;
}
else
{
parent->_right = maxleft->_left;
}
cur = maxleft;
}
假设我找的替换结点是左子树的最大结点。在替换后,被删除结点的情况要么是情况1要么是情况2
这里存在一种特殊情况如下: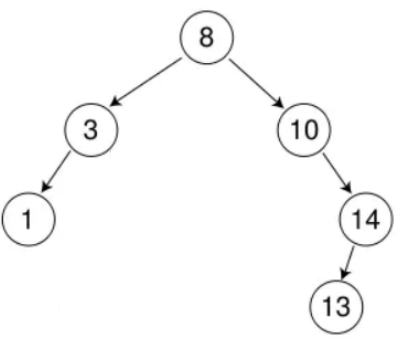
假设我要删除根节点8。那么 Node* parent = cur;这句就很关键,且下面的if和else的判断也很有必要
完整代码
bool Erase(const K& key)
{
Node* cur = _root;
Node* parent = _root;
while (cur)
{
//比根值大
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if (key < cur->_key)//比根值小
{
parent = cur;
cur = cur->_left;
}
else//和根值一样大,开始删除
{
//被删除结点的左边为空
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else
{
if (parent->_right == cur)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
}
else if (cur->_right == nullptr)//被删除结点的右边为空
{
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (parent->_right == cur)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
}
else//左右都不为空,替换法
{
//找替换结点,左边最大或右边最小
Node* parent = cur;
Node* maxleft = cur->_left;
while (maxleft->_right)
{
parent = maxleft;
maxleft = maxleft->_left;
}
//这里找出左边最大并交换
swap(cur->_key, maxleft->_key);
if (parent->_left == maxleft)
{
parent->_left = maxleft->_left;
}
else
{
parent->_right = maxleft->_left;
}
cur = maxleft;
}
delete cur;
return true;
}
}
return false;
}
二叉搜索树的递归实现
由于递归实现需要传根节点,因此一般都会套一层函数,如中序遍历
插入
public:
bool InsertR(const K& key)
{
return _InsertR(_root, key);
}
private:
bool _InsertR(Node*& root, const K& key)
{
if (root == nullptr)
{
root = new Node(key);//正是因为参数的引用,使得这里可以直接完成链接操作
return true;
}
if (root->_key > key)//比根值小就插入到左子树
{
_InsertR(root->_left, key);
}
else if (root->_key < key)//比根值大就插入到右子树
{
_InsertR(root->_right, key);
}
else//和根值一样就没必要插入了
{
return false;
}
}
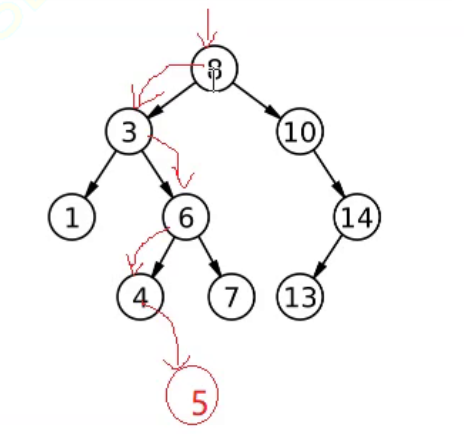
这里的关键点就是函数_InsertR的参数中的那个引用。那这个引用有什么好处呢?
-
假设是空树,那么
_root就是nullptr,root就是_root的别名。然后就会root=new Node(key),直接给根赋值 -
假设插入的是5,如上图。一直递归到了结点4,此时传入结点4的右指针nullptr,root就是结点4右指针的别名,那么直接将结点5赋给结点4的右指针,就自动完成了链接
查找
public:
bool FindR(const K& key)
{
return _FindR(_root, key);
}
private:
bool _FindR(Node* root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key > key)//比根值小就到左子树找
{
_FindR(root->_left, key);
}
else if (root->_key < key)//比根值大就到右子树找
{
_FindR(root->_right, key);
}
else//找到了
{
return true;
}
}
删除
public:
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
private:
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key > key)//比根值小就到左子树中去删除
{
_EraseR(root->_left, key);
}
else if (root->_key < key)//比根值大就到右子树中去删除
{
_EraseR(root->_right, key);
}
else//实施删除
{
//将被删除的root保存下来
Node* del = root;
if (root->_left == nullptr)//root的左孩子为空
{
root = root->_right;
}
else if (root->_right == nullptr)//root的右孩子为空
{
root = root->_left;
}
else//root的左右孩子都不为空
{
//找出最大左孩子
Node* leftmax = root->_left;
while (leftmax->_right)
{
leftmax = leftmax->_right;
}
swap(leftmax->_key, root->_key);
return _EraseR(root->_left, key);//这里我们已经知道需要被删除的数据是在左子树中的,所以直接递归即可。虽然会重复再找一次需要删除的数据,但代价不大
}
delete del;
return true;
}
}
也如插入一样利用引用简化
在非递归中不用引用是因为引用不能改变指向。递归里的引用是在不同的栈帧,所以每次都是新的引用
二叉搜索树的其余函数
析构函数
后序删除
public:
~BSTree()
{
Destroy(_root);
}
private:
void Destroy(Node*& root)
{
//后序销毁
if (root == nullptr)
return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
root = nullptr;
}
加引用是方便将root置空
拷贝构造
前序拷贝。遇到8就拷贝8,遇到3就拷贝3
public:
BSTree(const BSTree<K>& t)
{
_root = Copy(t._root);
}
private:
Node* Copy(Node* root)
{
//前序拷贝
if (root == nullptr)
{
return nullptr;
}
Node* copyroot = new Node(root->_key);
copyroot->_left = Copy(root->_left);
copyroot->_right = Copy(root->_right);
return copyroot;
}
赋值运算符重载
现代写法:
public:
BSTree<K>& operat(BSTree<K> t)
{
swap(_root, t._root);
return *this;
}
二叉搜索树的应用
二叉搜索树的应用有两大场景:
- key的搜索模型:快速判断在不在的场景,如门禁系统
- key-value的搜索模型:通过一个值找另外一个值,如找快递
之前讲的都是key的搜索模型。下面来看看key/value的搜索模型:
其实与key的搜索模型相比没什么,就是在结点中多存一个value。最主要的还是key
比如说字典,假设英文是key,那么中文就是value。可以通过英文得到对应的中文
再比如说,统计水果出现的次数
之所以上述用二叉搜索树实现,一个是因为字符串可以比较大小,第二个是因为二叉搜索树的搜索效率高
在key模型的基础下,修改后代码如下:(没写的函数说明和key模型是一样的)
namespace key_value
{
template<class K,class V>
struct BSTreeNode
{
BSTreeNode(const K& key,const V& value)
:_left(nullptr)
, _right(nullptr)
, _key(key)
,_value(value)
{}
BSTreeNode* _left;
BSTreeNode* _right;
K _key;
V _value;
};
template<class K,class V>
class BSTree
{
typedef BSTreeNode<K, V> Node;
public:
BSTree()
:_root(nullptr)
{}
//中序遍历
void InOrder()
{
_InOrder(_root);
cout << endl;
}
//查找的递归版本
Node* FindR(const K& key)
{
return _FindR(_root, key);
}
//插入的递归版本
bool InsertR(const K& key,const V& value)
{
return _InsertR(_root, key, value);
}
//删除的递归版本
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
private:
void Destroy(Node*& root)
{
//后序销毁
if (root == nullptr)
return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
root = nullptr;
}
Node* Copy(Node* root)
{
//前序拷贝
if (root == nullptr)
{
return nullptr;
}
Node* copyroot = new Node(root->_key);
copyroot->_left = Copy(root->_left);
copyroot->_right = Copy(root->_right);
return copyroot;
}
Node* _FindR(Node* root, const K& key)
{
if (root == nullptr)
return nullptr;
if (root->_key > key)//比根值小就到左子树找
{
_FindR(root->_left, key);
}
else if (root->_key < key)//比根值大就到右子树找
{
_FindR(root->_right, key);
}
else//找到了
{
return root;
}
}
bool _InsertR(Node*& root, const K& key,const V& value)
{
if (root == nullptr)
{
root = new Node(key,value);//正是因为参数的引用,使得这里可以直接完成链接操作
return true;
}
if (root->_key > key)//比根值小就插入到左子树
{
_InsertR(root->_left, key,value);
}
else if (root->_key < key)//比根值大就插入到右子树
{
_InsertR(root->_right, key,value);
}
else//和根值一样就没必要插入了
{
return false;
}
}
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key > key)//比根值小就到左子树中去删除
{
_EraseR(root->_left, key);
}
else if (root->_key < key)//比根值大就到右子树中去删除
{
_EraseR(root->_right, key);
}
else//实施删除
{
//将被删除的root保存下来
Node* del = root;
if (root->_left == nullptr)//root的左孩子为空
{
root = root->_right;
}
else if (root->_right == nullptr)//root的右孩子为空
{
root = root->_left;
}
else//root的左右孩子都不为空
{
//找出最大左孩子
Node* leftmax = root->_left;
while (leftmax->_right)
{
leftmax = leftmax->_right;
}
swap(leftmax->_key, root->_key);
return _EraseR(root->_left,key);
}
delete del;
return true;
}
}
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << ":"<<root->_value<<" ";
_InOrder(root->_right);
}
private:
Node* _root;
};
}














 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









