







目录
2. pruning_structured_l1_diltilgpt2
(1)Function to compute importance scores (L1 norm)
(2)Function to prune neurons and create new Conv1D layers
(3)Function to copy weights and biases to new pruned layers
(4)Function to iterate through the model and prune each block
本文学习重点:结构化宽度剪枝,计算L1范数,淘汰20%重要性低的神经元。
1. 剪枝 Pruning
1.1 什么是 pruning
通过移除神经网络中冗余参数(如权重、神经元或层)来压缩模型规模。
(1)方法分类
非结构化剪枝(Unstructured Pruning):
随机移除单个权重(如接近零的权重),生成稀疏矩阵结构化剪枝(Structured Pruning):
移除整组结构(如神经元、通道或层),保持规整矩阵便于硬件加速
(2)基本实施流程
预训练模型:获得过参数化的基础模型。
过参数化:可训练参数数量显著超过任务所需的最小参数量
基础模型:在大规模数据集(如The Pile、Common Crawl)上预训练好的大型语言模型(如LLaMA、GPT系列)重要性评估:通过指标(如权重绝对值、梯度信息)识别冗余参数。
剪枝操作:按阈值移除低重要性部分。
微调恢复:用少量数据(如Few-Shot)微调剪枝后模型,补偿性能损失。
Few-Shot:指极少量标注数据(通常 5~100条样本),用于快速适配模型到特定任务
1.2 剪枝 vs 量化 vs 蒸馏
(1)剪枝 (pruning):移除模型中冗余的权重、神经元或层
操作的是权重矩阵、通道、注意力头、网络层。
(2)量化 (Quantization):将高精度数值(如FP32)转换为低精度表示(如INT8)
操作的是权重、激活值(数据精度)。
(3)蒸馏 (Distillation):教师模型指导学生模型学习输出概率分布或中间特征
操作的是模型架构(教师→学生)。

2. pruning_structured_l1_diltilgpt2
2.1 Get the original model
prune_percent = 0.2 # Prune 20% of neurons
model_name = 'distilgpt2'
# Support function to check the size reduction.
def count_parameters(model):
return sum(p.numel() for p in model.parameters())
# Download the model and tokenizer
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
print("original model:")
print(model)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
original_param_count = count_parameters(model)
print(f"Original model parameters: {original_param_count}")original model:
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-5): 6 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D(nf=2304, nx=768)
(c_proj): Conv1D(nf=768, nx=768)
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D(nf=3072, nx=768)
(c_proj): Conv1D(nf=768, nx=3072)
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
)可以看到模型的 mlp 部分由两层 Conv1D 组成:c_fc 和 c_proj ,剪枝就是在这两层实现的:
-
c_fc:保留重要的列(即输出神经元),进行列裁剪得到 [hidden_size, intermediate_size]
-
c_proj:由于它的输入就是 c_fc 层的输出(即中间表示),所以需要相应地裁剪其输入维度,即留下与保留的神经元对应的行,进行行裁剪得到 [intermediate_size, hidden_size]
2.2 Pruning
(1)Function to compute importance scores (L1 norm)
def compute_importance_scores(c_fc_weight):
return torch.sum(torch.abs(c_fc_weight), dim=0) # Shape: [intermediate_size]使用 L1 范数(权重绝对值之和)计算每个神经元的重要性得分。
通俗理解:想象神经元是一个水管,权重是水管的粗细。L1 范数(权重绝对值之和)相当于测量从该神经元流出的"总水流"。水流小的水管(L1值小)说明它传递的信息少,可以关闭而不影响系统。
(2)Function to prune neurons and create new Conv1D layers
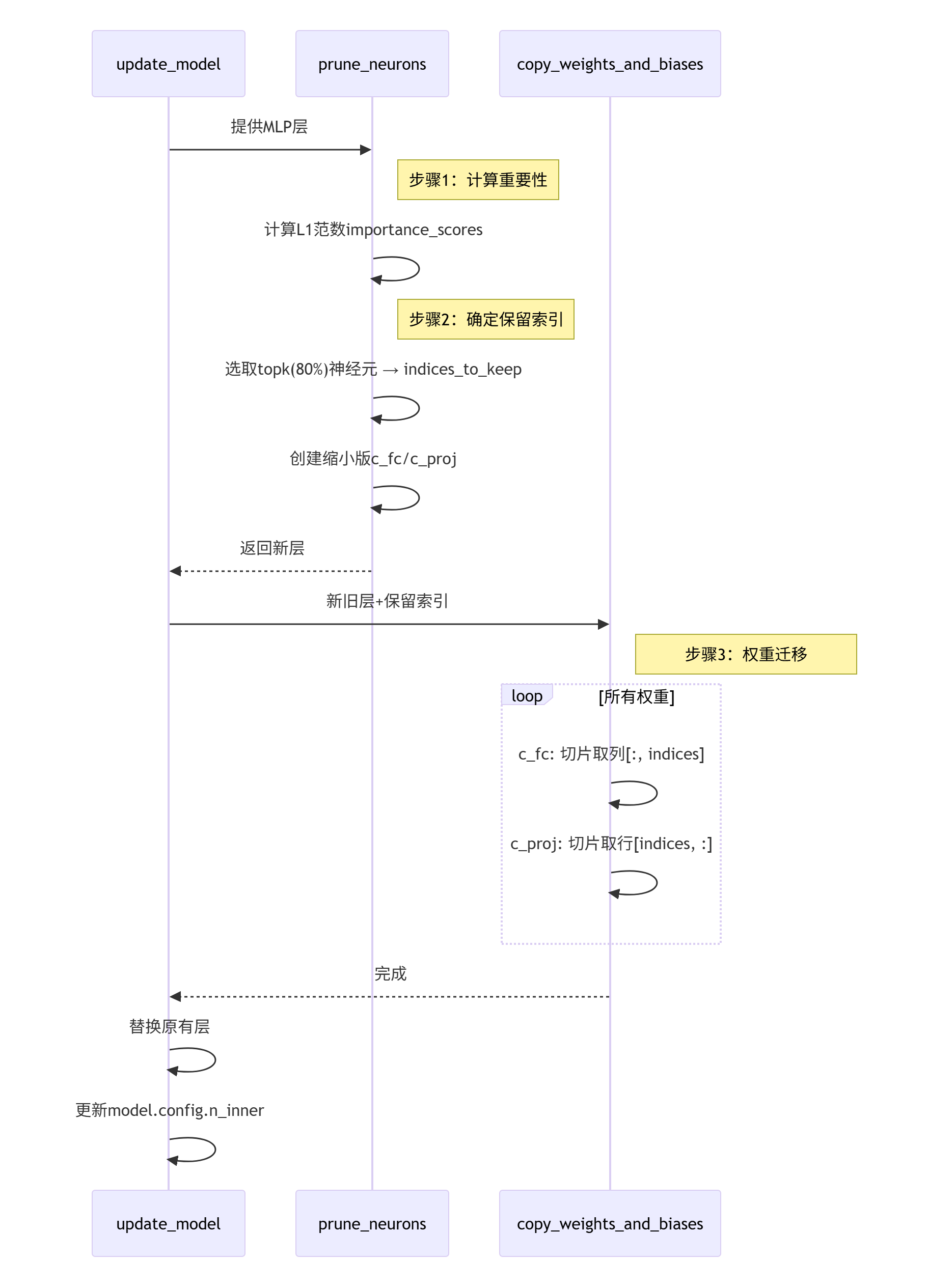
def prune_neurons(mlp, prune_percent, device):
# 获取MLP中c_fc层的权重数据(Conv1D实现的线性变换)
c_fc_weight = mlp.c_fc.weight.data
# 计算每个神经元的重要性得分(L1范数)
importance_scores = compute_importance_scores(c_fc_weight)
# 获取原始中间层维度大小
original_intermediate_size = c_fc_weight.size(1) # 即神经元数量
# 计算需要剪枝的神经元数量
num_neurons_to_prune = int(prune_percent * original_intermediate_size)
# 选择重要性最高的神经元保留(反选要剪枝的神经元)
_, indices_to_keep = torch.topk(importance_scores, original_intermediate_size - num_neurons_to_prune)
# 对保留的神经元索引排序(保持维度顺序一致性)
indices_to_keep, _ = torch.sort(indices_to_keep)
# 创建新的Conv1D层(已缩减尺寸):
# new_c_fc:输入维度不变(mlp.c_fc.weight.size(0)),输出维度缩减为保留的神经元数
new_c_fc = Conv1D(len(indices_to_keep), mlp.c_fc.weight.size(0)).to(device)
# new_c_proj:输入维度缩减为保留的神经元数,输出维度不变(mlp.c_proj.weight.size(1))
new_c_proj = Conv1D(mlp.c_proj.weight.size(1), len(indices_to_keep)).to(device)
return new_c_fc, new_c_proj, len(indices_to_keep), indices_to_keepprune_neurons 函数作用:创建了新的Conv1D层(尺寸缩减20%)。
相当于创建了一个空的容器,并确定了保留索引(indices_to_keep:表示原始权重矩阵中哪些神经元(列/行)应该保留)。
但值得注意的是,创建的新层的 weight 和 bias 都是随机初始化的(也就是我们所说的“空”),因此就需要后续的 copy 函数帮助我们获得原始的 weight 和 bias。
假设初始有100个神经元:
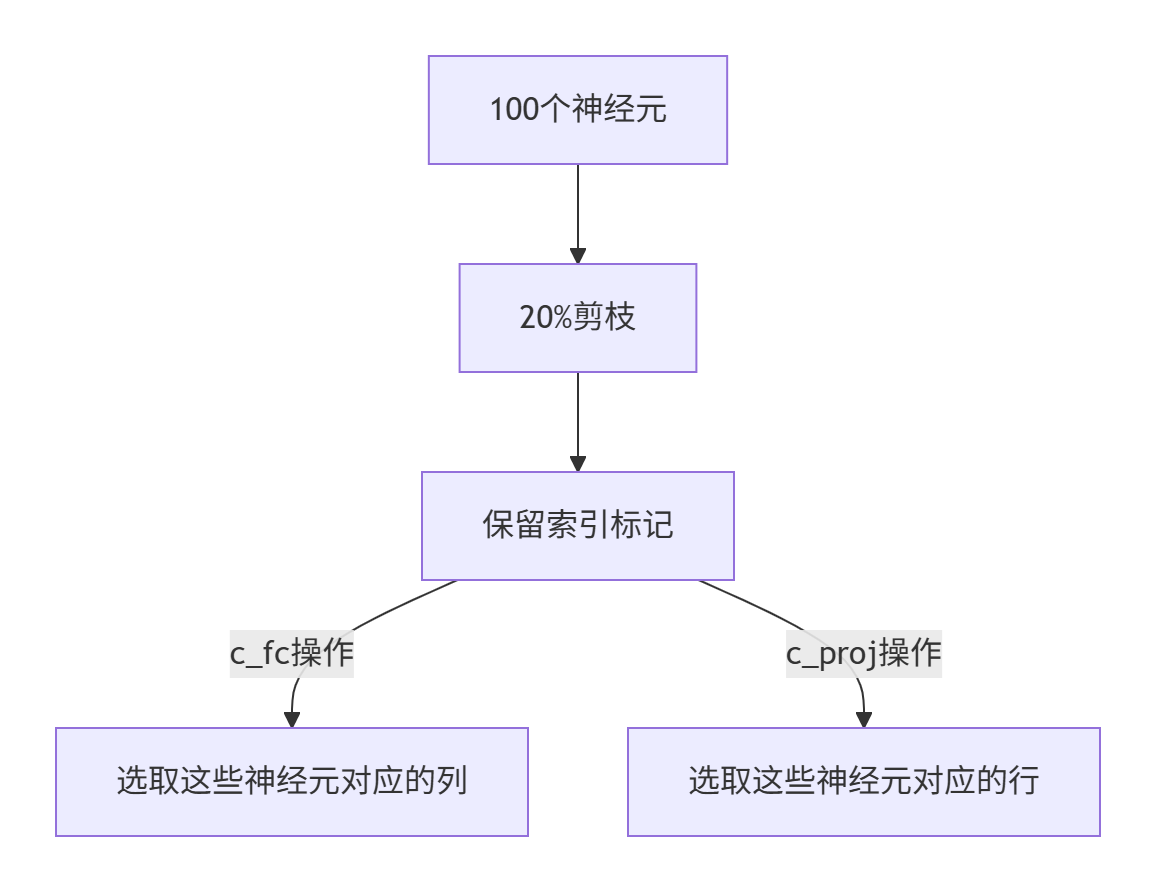
(3)Function to copy weights and biases to new pruned layers
def copy_weights_and_biases(mlp, new_c_fc, new_c_proj, indices_to_keep):
# 复制c_fc层权重:选择所有输入通道(:, ...),只保留指定的输出通道
new_c_fc.weight.data = mlp.c_fc.weight.data[:, indices_to_keep]
# 复制c_fc层偏置:只保留指定的神经元偏置
new_c_fc.bias.data = mlp.c_fc.bias.data[indices_to_keep]
# 复制c_proj层权重:只保留指定的输入通道(... indices_to_keep, :),所有输出通道
new_c_proj.weight.data = mlp.c_proj.weight.data[indices_to_keep, :]
# 复制c_proj层偏置(不受剪枝影响,可直接复制)
new_c_proj.bias.data = mlp.c_proj.bias.datacopy_weights_and_biases 函数作用:只处理传递给它的 MLP 层中的 c_fc 和 c_proj 这两层,只保留指定行/列的数据。
另外地,“复制”并不是很严谨的讲法,实际上应该是引用替换,层引用被替换指向被剪枝后的新矩阵。"层引用"指的是对象内部指向另一个对象的指针或地址标签,举例说明:
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.c_fc = Conv1D(...) # 这是层引用
self.c_proj = Conv1D(...) # 这也是层引用
def forward(self, x):
x = self.c_fc(x) # 通过引用访问实际层
return self.c_proj(x)
层引用不是层本身,而是指向层对象的内存地址(可以理解为你家的门牌号)
层对象是包含weight、bias的数据容器,有自己的存储空间(也就是住在上述门牌号)
(4)Function to iterate through the model and prune each block
def update_model(model, prune_percent, device):
# 初始化新中间层尺寸变量
new_intermediate_size = None
# 遍历模型中的每个Transformer块
for idx, block in enumerate(model.transformer.h):
# 获取当前块的MLP层
mlp = block.mlp
# 创建剪枝后的新层并获取保留的神经元索引
new_c_fc, new_c_proj, new_size, indices_to_keep = prune_neurons(mlp, prune_percent, device)
# 复制权重到新创建的小尺寸层
copy_weights_and_biases(mlp, new_c_fc, new_c_proj, indices_to_keep)
# 用剪枝后的层替换原始层
mlp.c_fc = new_c_fc
mlp.c_proj = new_c_proj
# 只在第一次循环时记录新尺寸(假设所有层尺寸相同)
if new_intermediate_size is None:
new_intermediate_size = new_size
# 更新模型配置中的中间层尺寸
model.config.n_inner = new_intermediate_size
return modelupdate_model 函数作用:循环执行6次(针对distilgpt2的6个Transformer块)
(5)整体流程
2.3 Get the pruned Model
model = update_model(model, prune_percent, device)
pruned_param_count = count_parameters(model)
print(f"Pruned model parameters: {pruned_param_count}")
print(f"Reduction in parameters: {original_param_count - pruned_param_count}")
print("pruned model:")
print(model)pruned model:
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-5): 6 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D(nf=2304, nx=768)
(c_proj): Conv1D(nf=768, nx=768)
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D(nf=2458, nx=768)
(c_proj): Conv1D(nf=768, nx=2458)
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
)(1)维度变化: 3072*0.8 = 2457.6 ≈ 2458
(c_fc): Conv1D(nf=3072, nx=768)
(c_proj): Conv1D(nf=768, nx=3072)
↓ ↓ ↓
(c_fc): Conv1D(nf=2458, nx=768)
(c_proj): Conv1D(nf=768, nx=2458)-
nf (number of features):输出特征维度(即神经元数量)
-
nx (input dimension):输入特征维度
(2)参数量变化:
Original model parameters: 81912576
Pruned model parameters: 76250268
Reduction in parameters: 56623083. 剪枝效果评估
## 输入
prompt = "Paris is the capital of"
## 输出
Generated text: Paris is the capital of the United States.
Generated text after pruning: Paris is the capital of the United States, and输出的情况和原课程中是一致的,虽然很明显输出是不正确的,但 pruned-model 的响应与 base-model 的响应不同,这说明剪枝过程确实影响到了模型的输出生成。

















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









