







 本文探讨了深度网络模型压缩的重要性和方法,包括经典论文Deep Compression的Pruning、Quantization和Huffman编码,以及迭代Pruning、直接稀疏卷积等进一步改进策略,旨在实现资源高效的推理。
本文探讨了深度网络模型压缩的重要性和方法,包括经典论文Deep Compression的Pruning、Quantization和Huffman编码,以及迭代Pruning、直接稀疏卷积等进一步改进策略,旨在实现资源高效的推理。
一. 技术背景
一般情况下,CNN网络的深度和效果成正比,网络参数越多,准确度越高,基于这个假设,ResNet50(152)极大提升了CNN的效果,但inference的计算量也变得很大。这种网络很难跑在前端移动设备上,除非网络变得简洁高效。
基于这个假设,有很多处理方法,设计层数更少的网络、更少的卷积和、每个参数占更少的字节,等等。
前面讲过的 PVANet、MobileNet、ShuffleNet 是网络设计层面的思路,这里我们不展开,本节主要讲的是基于 已训练网络的简化方法。
首先来看网络压缩的经典文献,ICLR 2016 的Best Paper,来自 Song Han 大神的 Deep Compression:
这篇文章必须要读一遍,先看示意图:
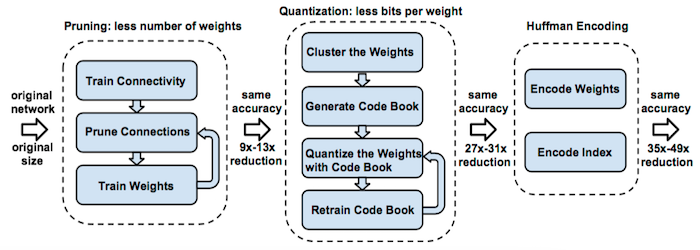
作者提出从三个方面进行网络压缩:
1)Pruning
最常用的剪枝方法,即剔除对于网络贡献比较低的权值连接,这个比较好理解,通过Pruning使得网络变得稀疏,带来更少的计算量。
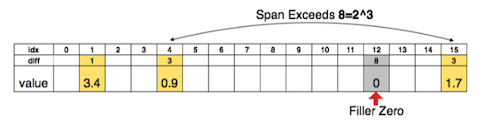
上图是基于稀疏矩阵的索引表示,用3bits 来表示索引的相对位置,其中黄色部分为有效权值区域,当相对位置的diff 超过8(3bits)的时候,中间插入了一个0权值来防止溢出。
事实上,稀疏矩阵对于计算量来讲并没有太多的效率优化,远不如将整个的卷积和剔除来得更实在,这也是 Pruning 接下来聚焦的方向。
2)Quantization
量化,包括两个方向:
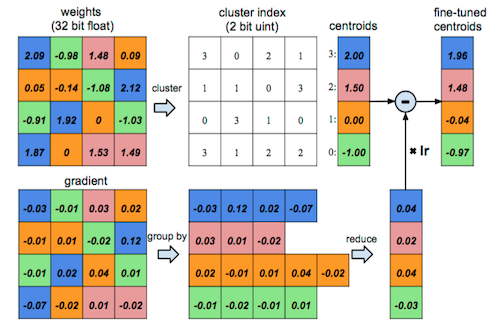
a)通过聚类的方式实现权值共享;
这种方法误差很大,后续研究的也并不是很多,知道下就好了。
b)采用更少的字节表示权值,比如 16bit、8bit;
这里面还有 著名的 BinaryNet,XNOR-Net,不过对于效果影响比较大,我最多能接受 int8 所以没怎么看,当然大家有兴趣可以看一下。
3)Huffman 编码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5498
5498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









