







一、定义
on-policy:要learn的agent和与环境互动的agent是同一个agent(一边学一边互动)。
off-policy:要learn的agent和与环境互动的agent不是同一个agent(在旁边看着别人互动)。
二、过程


![]() 和
和![]() 是不能相差太多的,否则训练结果就不好,所以该怎么选择?PPO/TRPO
是不能相差太多的,否则训练结果就不好,所以该怎么选择?PPO/TRPO
在实际使用中,虽然PPO和TRPO(PPO的前身)效果相差不大,但PPO使用起来更为简易,一般推荐使用PPO算法。KL divergence 当作一个function,表示的不是![]() 和
和![]() 的参数距离,而是它们behavior上的距离。假设现在有两个actor,一个参数是
的参数距离,而是它们behavior上的距离。假设现在有两个actor,一个参数是![]() ,一个参数是
,一个参数是![]() 。所谓参数上的距离是指算这两个参数有多像;而behavior上的距离是指给同样state的时候,output的action distribution之间的差距。之所以不考虑参数的距离而是考虑行为上的距离,是很有可能对actor来说,参数的变化和action的变化不一定是完全一致的,可能参数变很多,action变化不大。
。所谓参数上的距离是指算这两个参数有多像;而behavior上的距离是指给同样state的时候,output的action distribution之间的差距。之所以不考虑参数的距离而是考虑行为上的距离,是很有可能对actor来说,参数的变化和action的变化不一定是完全一致的,可能参数变很多,action变化不大。

PPO算法:

如果觉得计算KL很麻烦,那还有简易版本的PPO算法:

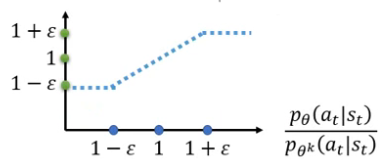
PPO2算法是选择括号里两项中小的一项。
第二项中有个clip function,我的理解是做边界处理的,假设![]() 为0.2,则当
为0.2,则当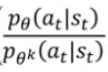 的计算结果小于0.8时,就当作0.8,当的计算结果大于1.2时,就当作1.2。
的计算结果小于0.8时,就当作0.8,当的计算结果大于1.2时,就当作1.2。
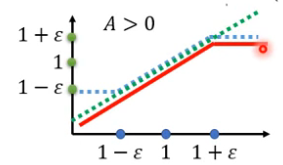
第一项就是绿色那条线 。如果A>0,那么取两条线的较小的那条线为下面红色那条线。
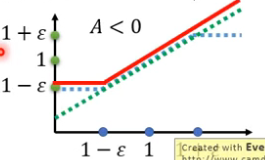
反正,如果A<0的话,那么取两条线的较小的那条线为下面红色那条线。
对这个PPO2算法的解释:使 ![]() 和
和![]() 不要相差太大。横轴就是
不要相差太大。横轴就是![]() 。如果A>0,也就是某一pair的St和At是比较好的,所以要做的事情是增大这一pair的机率,也就是
。如果A>0,也就是某一pair的St和At是比较好的,所以要做的事情是增大这一pair的机率,也就是![]() 越大越好,但
越大越好,但![]() 与
与![]() 的比值不能超过
的比值不能超过![]() 。同理A<0的时候也是一样。
。同理A<0的时候也是一样。















 6795
6795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









