






1.贝叶斯的基本思想:
已知公式:p(y|x)=p(x|y)*p(y)/p(x)
可以将x看做特征向量,y为结果,那么p(y|x)就是在x特征出现的情况下,结果为y的概率。
在机器学习中,p(y|x)就是我们预测一个新样本要计算样本属于哪一类的公式,同时我们掌握着大量的数据集,因为p(y|x)不好求解,那么可以对p(x|y)*p(y)进行计算,偷天换日,效果是一样的。
由于p(x)属于全概率公式,每个判断过程的p(x)都是相同的,因此忽略掉也不影响各类概率大小的比较。
接下来上代码讲解全过程:
1.获取到邮件数据集.csv,要对每一封邮件进行真实值(label)的存储,和邮件内容(feature)的存储
注意的是:邮件内容存储的同时,要对内容进行切词,可以利用jieba库
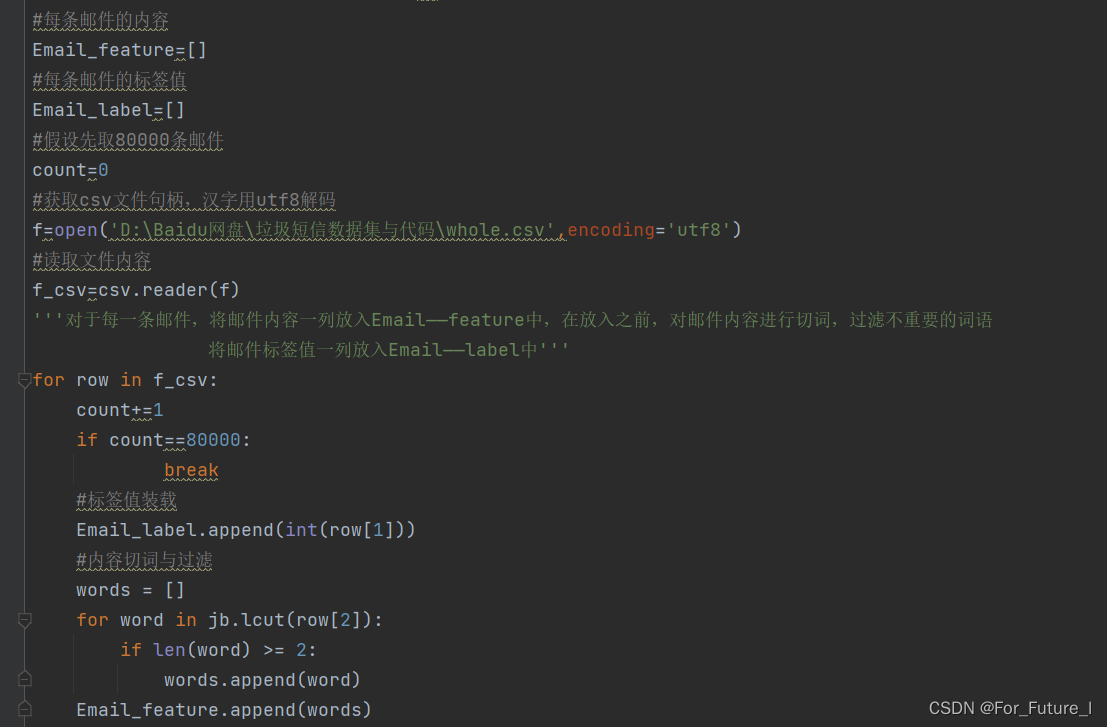
2.先手动将垃圾邮件和正常邮件分开;然后分别对垃圾邮件和正常邮件进行词袋的建立。
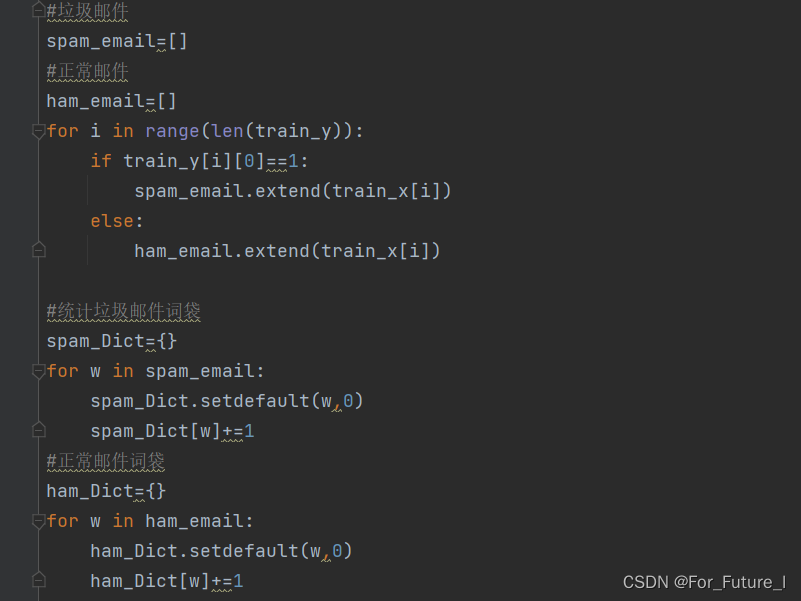
3. 去除词袋中没有意义的词汇统计量,免得影响进行朴素贝叶斯计算时,分母过大,导致词袋词频数少的邮件词袋概率总是偏大

4.开始对测试集中每一封邮件继续预测
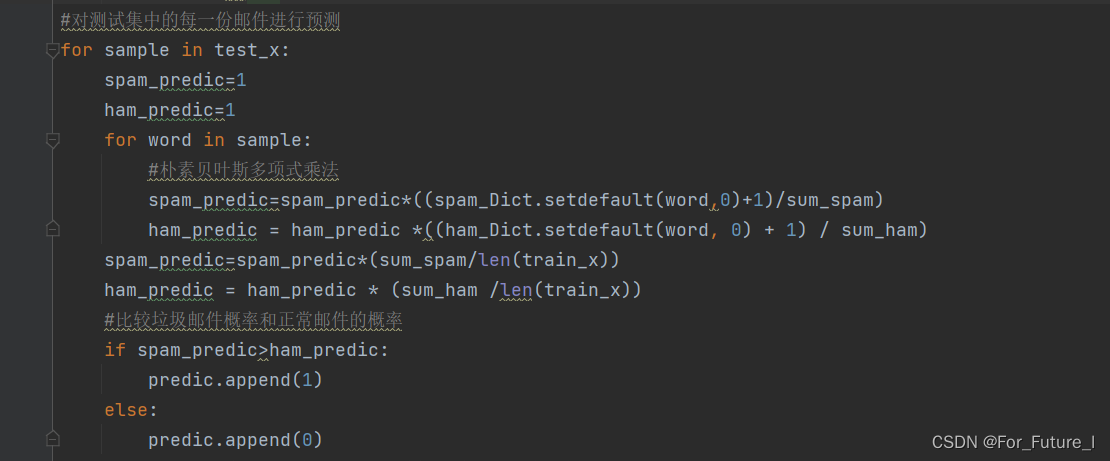
5.计算模型正确率
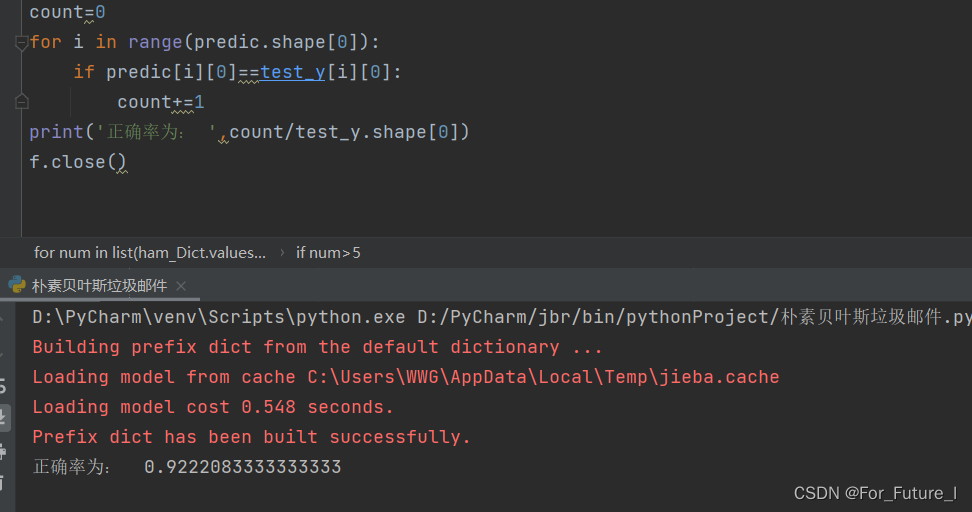
这是自己学习朴素贝叶斯之后,没有进行sklearn库掉包的一次手动计算的实验,过程中许多不同数值处理都会有所影响,这只是按照自己理解的朴素贝叶斯写的偏方,不一定正确。不过效果针得很不戳,















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









