









 文章围绕《Improved Techniques for Training GANs》展开,总结了提升标准GAN训练的技术,包括特征匹配、小批量判别、历史平均、单边标签平滑、虚拟批量归一化等,还介绍了新评估标准Inception score及半监督学习在无监督学习中的应用。
文章围绕《Improved Techniques for Training GANs》展开,总结了提升标准GAN训练的技术,包括特征匹配、小批量判别、历史平均、单边标签平滑、虚拟批量归一化等,还介绍了新评估标准Inception score及半监督学习在无监督学习中的应用。
《Improved Techniques for Training GANs》

昨天晚上在看同样是openai一个人写的一篇介绍性的文章《From GAN to WGAN》时,其中写到了一些关于提升标准GAN训练方面的技术,如feature matching、minibatch discrimination……,就想到这篇放在文件夹中很久但一直忘记看的文章。
在文章的开篇,作者提出了所关注的两个重点:半监督学习和生成接近于真实的图像。关于GAN的基础理论方面这里就不再赘述,假设大家都已经看过lan Goodfellow的《Generative Adversarial Nets》了。下面主要总结一下文中提出的几种帮助训练GAN的技术:feature matching、minibatch discrimination、historical averaging、one-side label smoothing和virtual batch normalization,一个新提出的评估标准Inception score和在无监督学习中的使用。
Feature matching
GAN中的判别器(Discriminator,D)是用来判断输入到D中的样本是来自于真实数据还是生成器,然后给出一个标量表示判别的结果。那么,如果将其作为一个分类器的话,类比于通常用卷积网络来分类的模型,我们就可以知道:D同样是从输入的真、假样本中进行特征提取的工作,然后通过比较真实样本中的特征和生成样本中的特征的差异来判断样本的来源。
所以我们可以通过比较不同来源的样本在D的中间层所表示的特征的差异来进一步的提高D判别的准确率,同时逼迫生成器(Generator,G)生成更接近于真实的样本。原文中是这样描述的:
Instead of directly maximizing the output of the discriminator, the new objective requires the generator to generate data that matches the statistics of the real data, where we use the discriminator only to specify the statistics that we think are worth matching.
即可以不按照最初的方法(最大化D正确判别的概率)优化D,而是希望G生成的样本所表达的某些数据的统计值接近于D关注的真实样本中某些统计值。这样的话,如果它们足够接近的话,我们就可以认为生成样本所满足的分布
p
g
p_{g}
pg接近真实数据分布
p
d
a
t
a
p_{data}
pdata。假设
f
(
x
)
f(x)
f(x)为D中间层输出的特征图,G的目标函数就变成了如下的形式:
∥
E
x
∼
p
data
f
(
x
)
−
E
z
∼
p
z
(
z
)
f
(
G
(
z
)
)
∥
2
2
\| \mathbb{E}_{\boldsymbol{x} \sim p_{\text { data }}} \mathbf{f}(\boldsymbol{x})-\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})} \mathbf{f}(G(\boldsymbol{z}))\left\|_{2}^{2}\right.
∥Ex∼p data f(x)−Ez∼pz(z)f(G(z))∥∥22
但是作者也指出,这样的方式并不能保证G到达那个最优值点,但是可以帮助稳定训练过程。
Minibatch discrimination
在GAN的训练过程中,经常会发生模式坍缩(mode collapse)的问题,此时G只会生成某些固定类别的样本,不能很好的接近真实数据所满足的分布。作者认为这个问题的出现是因为D每一次只单独的处理一个样本,它无法指出前后的生成样本之间的相似性,所以就无法给G提供有用的信息来使得G生成更多类型的样本。因此,我们可以每次给D一个小批次的样本,这样D就可以知道样本之间的差异性,从而使得G避免陷入模式坍缩的牢笼。假设输入为
x
i
x_{i}
xi,它在D的某一层的特征向量为
f
(
x
i
)
f(x_{i})
f(xi),我们将其乘以张量
T
∈
R
A
×
B
×
C
T \in \mathbb{R}^{A \times B \times C}
T∈RA×B×C得到矩阵
M
i
∈
R
B
×
C
M_{i} \in \mathbb{R}^{B \times C}
Mi∈RB×C,然后对每个样本之间的M的行向量计算
L
1
L_{1}
L1距离,得到
c
b
(
x
i
,
x
j
)
=
exp
(
−
∥
M
i
,
b
−
M
j
,
b
∥
L
1
)
∈
R
c_{b}\left(x_{i}, x_{j}\right)=\exp \left(-\left\|M_{i, b}-M_{j, b}\right\|_{L 1}\right) \in \mathbb{R}
cb(xi,xj)=exp(−∥Mi,b−Mj,b∥L1)∈R
然后将所有的
c
b
(
x
i
,
x
j
)
c_{b}\left(x_{i}, x_{j}\right)
cb(xi,xj) 相加得到
o
(
x
i
)
b
o(x_{i})_{b}
o(xi)b,最后所有的
o
(
x
i
)
b
o(x_{i})_{b}
o(xi)b合并起来得到
o
(
X
)
o(X)
o(X),如下所示:
o
(
x
i
)
b
=
∑
j
=
1
n
c
b
(
x
i
,
x
j
)
∈
R
o
(
x
i
)
=
[
o
(
x
i
)
1
,
o
(
x
i
)
2
,
…
,
o
(
x
i
)
B
]
∈
R
B
O
(
X
)
∈
R
n
×
B
o\left(\boldsymbol{x}_{i}\right)_{b}=\sum_{j=1}^{n} c_{b}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right) \in \mathbb{R} \\ o\left(\boldsymbol{x}_{i}\right)=\left[o\left(\boldsymbol{x}_{i}\right)_{1}, o\left(\boldsymbol{x}_{i}\right)_{2}, \ldots, o\left(\boldsymbol{x}_{i}\right)_{B}\right] \in \mathbb{R}^{B} \\ O(\mathbf{X}) \in \mathbb{R}^{n \times B}
o(xi)b=j=1∑ncb(xi,xj)∈Ro(xi)=[o(xi)1,o(xi)2,…,o(xi)B]∈RBO(X)∈Rn×B
图示化:
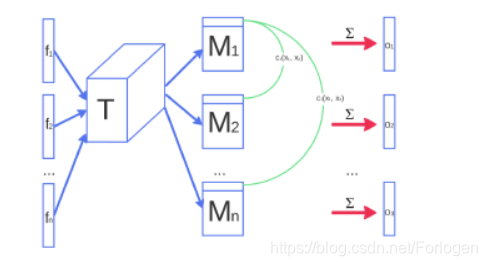
接着,将 o ( x i ) o(x_{i}) o(xi)和 f ( x i ) f(x_{i}) f(xi)合并成一个向量作为D网络下一层的输入。D的训练方式并不改变,但是可以将minibatch中其他样本的特征作为辅助信息,告诉G下一次生成的样本尽量不要太相近。
Historical averaging
做historical averaging是防止模型的参数
θ
\theta
θ变化的太过于剧烈而不符合真实的情况,而参数的历史平均值可以在线更新,因此该学习规则可以很好地扩展到长时间序列。
∥
θ
−
1
t
∑
i
=
1
t
θ
[
i
]
∥
2
\left\|\theta-\frac{1}{t} \sum_{i=1}^{t} \theta[i]\right\|^{2}
∥∥∥∥∥θ−t1i=1∑tθ[i]∥∥∥∥∥2
其中
θ
\theta
θ 是当前时刻的模型参数,
θ
i
\theta_{i}
θi为之前各个时刻的模型参数。
One-side label smoothing
这个方法是将分类器的判别结果0和1替换为平滑值:如0.9和0.1,这样做被证明可以降低神经网络对对抗样本的脆弱性。
因此最优的D就表示为
D
(
x
)
=
α
p
d
a
t
a
(
x
)
+
β
p
m
o
d
e
l
(
x
)
p
d
a
t
a
(
x
)
+
p
r
m
o
d
e
l
(
x
)
D(\boldsymbol{x})=\frac{\alpha p_{\mathrm{data}}(\boldsymbol{x})+\beta p_{\mathrm{model}}(\boldsymbol{x})}{p_{\mathrm{data}}(\boldsymbol{x})+p_{\mathrm{rmodel}}(\boldsymbol{x})}
D(x)=pdata(x)+prmodel(x)αpdata(x)+βpmodel(x)
其中
α
\alpha
α是控制正样本的参数,
β
\beta
β是控制负样本的参数。但是为了避免当
p
d
a
t
a
p_{data}
pdata趋近于0时无意义的情况,作者指出我们只平滑正向标签,将负标签设置为0。
Virtual batch normalization
DCGAN中使用了batch Normalization取得了不错的效果,那能否将其应用到GAN的训练中呢?首先,我们需要明白BN所存在的一个问题:它会使得对于输入 x x x的输出高度依赖于其他的输入 x ′ x' x′。因此作者提出,在每一个minibatch中的输入进行归一化时,只根据提前选出且在训练过程中不在改变的参考批次样本(reference batch)的统计信息进行操作,这样就避免了对于同一minibatch中其他输入样本的依赖。因为它的计算开销很大,因此一般只用在G中。
Inception score
它以生成图片 x x x为输入,以 x x x的判别类标签概率为输出。作者认为好的样本(图像看起来像来自真实数据分布的图像)预计会产生:
-
低熵 P ( y ∣ x ) P(y|x) P(y∣x):生成样本看起来很像从真实数据中采样得到
-
高熵 ∫ p ( y ∣ x = G ( z ) ) d z \int p(y | \boldsymbol{x}=G(z)) d z ∫p(y∣x=G(z))dz:生成样本的多样性应该很好
因此,inception score定义为 exp ( E x K L ( p ( y ∣ x ) ∥ p ( y ) ) ) \exp \left(\mathbb{E}_{\boldsymbol{x}} \mathrm{KL}(p(y | \boldsymbol{x}) \| p(y))\right) exp(ExKL(p(y∣x)∥p(y))) ,即衡量已有类别的分布和生成样本类别的分布之间的KL散度,当然希望值越大越好(生成样本的多样性更好)。
Semi-supervised learning
在标准的用于分类的网络中,经过softmax将输入
x
x
x分为
K
K
K个类别,得到类别向量
{
l
1
,
.
.
.
,
l
k
}
\{l_{1},...,l_{k}\}
{l1,...,lk}
p
model
(
y
=
j
∣
x
)
=
exp
(
l
j
)
∑
k
=
1
K
exp
(
l
k
)
)
p_{\text {model}}(y=j | x)=\frac{\exp \left(l_{j}\right)}{\sum_{k=1}^{K} \exp \left(l_{k}\right) )}
pmodel(y=j∣x)=∑k=1Kexp(lk))exp(lj)
如果将D看作时上述类型的分类网络模型,就可以将生成样本看作第
K
+
1
K+1
K+1类,用
p
m
o
d
e
l
(
y
=
K
+
1
∣
x
)
p_{model}(y=K+1|x)
pmodel(y=K+1∣x)表示生成网络的图片为假,用来代替标准GAN的
1
−
D
(
x
)
1-D(x)
1−D(x)。对于D来说,只需要知道某输入样本属于哪一类,而不必知道具体的类别信息,通过
p
m
o
d
e
l
(
y
∈
{
1
,
.
.
.
,
K
}
∣
x
)
p_{model}(y\in \left \{1,...,K \right \}|x)
pmodel(y∈{1,...,K}∣x)就可以训练。 所以损失函数就变为了:
L
=
−
E
x
,
y
∼
p
d
a
t
a
(
x
,
y
)
[
log
p
model
(
y
∣
x
)
]
−
E
x
∼
G
[
log
p
model
(
y
=
K
+
1
∣
x
)
]
=
L
supervised
+
L
unsupervised
,
where
L
supervied
=
−
E
x
,
y
∼
p
data
(
x
,
y
)
log
p
model
(
y
∣
x
,
y
<
K
+
1
)
L
unsuperised
=
−
{
E
x
∼
p
data
(
x
)
log
[
1
−
p
model
(
y
=
K
+
1
∣
x
)
]
+
E
x
∼
G
log
[
p
model
(
y
=
K
+
1
∣
x
)
]
}
\begin{aligned} L &=-\mathbb{E}_{\boldsymbol{x}, y \sim p_{\mathrm{data}}(\boldsymbol{x}, y)}\left[\log p_{\operatorname{model}}(y | \boldsymbol{x})\right]-\mathbb{E}_{\boldsymbol{x} \sim G}\left[\log p_{\text { model }}(y=K+1 | \boldsymbol{x})\right] \\ &=L_{\text { supervised }}+L_{\text { unsupervised }}, \text { where } \end{aligned} \\ \begin{aligned} L_{\text { supervied }} &=-\mathbb{E}_{\boldsymbol{x}, y \sim p_{\text { data }}(\boldsymbol{x}, y)} \log p_{\text { model }}(y | \boldsymbol{x}, y<K+1) \\ L_{\text { unsuperised }} &=-\left\{\mathbb{E}_{\boldsymbol{x} \sim p_{\text { data }}(\boldsymbol{x})} \log \left[1-p_{\text { model }}(y=K+1 | \boldsymbol{x})\right]+\mathbb{E}_{\boldsymbol{x} \sim G} \log \left[p_{\text { model }}(y=K+1 | \boldsymbol{x})\right]\right\} \end{aligned}
L=−Ex,y∼pdata(x,y)[logpmodel(y∣x)]−Ex∼G[logp model (y=K+1∣x)]=L supervised +L unsupervised , where L supervied L unsuperised =−Ex,y∼p data (x,y)logp model (y∣x,y<K+1)=−{Ex∼p data (x)log[1−p model (y=K+1∣x)]+Ex∼Glog[p model (y=K+1∣x)]}
如果令
D
(
x
)
=
1
−
p
m
o
d
e
l
(
y
=
K
+
1
∣
x
)
D(x)=1-p_{model}(y=K+1|x)
D(x)=1−pmodel(y=K+1∣x),上述无监督的表达式就是GAN的形式:
L
unsuperised
=
−
{
E
x
∼
p
data
(
x
)
log
D
(
x
)
+
E
z
∼
noise
log
(
1
−
D
(
G
(
z
)
)
)
}
L_{\text { unsuperised }}=-\left\{\mathbb{E}_{\boldsymbol{x} \sim p_{\text { data }}(\boldsymbol{x})} \log D(\boldsymbol{x})+\mathbb{E}_{z \sim \text { noise }} \log (1-D(G(\boldsymbol{z})))\right\}
L unsuperised =−{Ex∼p data (x)logD(x)+Ez∼ noise log(1−D(G(z)))}
参考
https://blog.csdn.net/shenxiaolu1984/article/details/75736407
https://blog.csdn.net/u013972559/article/details/85545339
openai Lilian Weng《From GAN to WGAN》 https://arxiv.org/abs/1904.08994

















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









