






总述:这场ABC难度没有之前的大,而且后面的G是典,成功完成人生首次ak ABC,特写一篇题解留念
A - Past ABCs
可以用字符串的substr函数截取后三位,再用stoi()把字符串转数字,判断这个数字在不在范围内,以及不等于316即可
代码:
#include <bits/stdc++.h>
// #define int long long
#define inf 0x3f3f3f3f
#define ll long long
#define pii pair<int, int>
#define db double
using namespace std;
const int maxn = 1e5 + 10;
const int mod = 998244353;
signed main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
string str;
cin >> str;
string a = str.substr(0, 3);
string b = str.substr(3);
int num = stoi(b);
if (1 <= num && num <= 349 && num != 316) {
cout << "Yes" << endl;
} else
cout << "No" << endl;
// system("pause");
return 0;
}
B - Dentist Aoki
模拟,直接用01数组表示是否存在牙齿,每次操作可以用异或1来表示取反,最后统计数组内有几个1
代码:
#include <bits/stdc++.h>
// #define int long long
#define inf 0x3f3f3f3f
#define ll long long
#define pii pair<int, int>
#define db double
using namespace std;
const int maxn = 1e5 + 10;
const int mod = 998244353;
int arr[maxn];
signed main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int n, q;
cin >> n >> q;
for (int i = 1; i <= n; i++)
arr[i] = 1;
while (q--) {
int x;
cin >> x;
arr[x] ^= 1;
}
int ans = 0;
for (int i = 1; i <= n; i++)
ans += arr[i];
cout << ans << endl;
// system("pause");
return 0;
}
C - Sort
置换环,有两种写法
1.
对于错位的元素,可以将应该在该位置的元素调换过来,这种写法就需要两个数组互相映射,比较绕,不推荐写这种。
2.
对于错位的元素,可以选择将该元素替换至它应该在的地方,每次替换都至少能让一个元素归位,所以最多也是 n − 1 n-1 n−1 次就可以有序。写起来更方便,只需要一个数组维护此时各个元素的位置,然后每次while当前元素错位,交换即可,代码:
#include <bits/stdc++.h>
// #define int long long
#define inf 0x3f3f3f3f
#define ll long long
#define pii pair<int, int>
#define db double
using namespace std;
const int maxn = 2e5 + 10;
const int mod = 998244353;
int arr[maxn], pos[maxn];
signed main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> arr[i];
}
vector<pii> ans;
for (int i = 1; i <= n; i++) {
while (arr[i] != i) {
ans.push_back(pii(i, arr[i]));
swap(arr[i], arr[arr[i]]);
}
}
cout << ans.size() << endl;
for (auto [u, v] : ans)
cout << u << " " << v << endl;
// system("pause");
return 0;
}
D - New Friends
并查集,猜结论
一开始我想去在线维护这种过程,后来看样例发现,这种操作可能有连带性,即操作一次新增一条边后,可能又可以根据新增的这条边去操作其他的元素,所以维护肯定维护不了。
然后看样例里面,3个点的时候,最终连线是一个完全图,就可以去猜一下是不是只要连通块,最终都会变成完全图。可以自己画一个4个点的链,发现连着连着确实变成完全图了,所以思路就有了,直接用并查集维护连通块大小。去统计最终状态的总边数,每个连通块设大小为
s
i
z
[
i
]
siz[i]
siz[i] ,总边数即为
∑
s
i
z
[
i
]
×
(
s
i
z
[
i
]
−
1
)
/
2
\sum siz[i] \times (siz[i] - 1) / 2
∑siz[i]×(siz[i]−1)/2 ,然后因为每次操作等价于连一条边,总边数减去初始的边数
m
m
m 就是最多可以操作的次数。
代码:
#include <bits/stdc++.h>
#define int long long
#define inf 0x3f3f3f3f
#define ll long long
#define pii pair<int, int>
#define db double
using namespace std;
const int maxn = 2e5 + 10;
const int mod = 998244353;
int fa[maxn], siz[maxn];
int Find(int x) {
return fa[x] == x ? fa[x] : fa[x] = Find(fa[x]);
}
signed main() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
fa[i] = i;
siz[i] = 1;
}
for (int i = 1; i <= m; i++) {
int u, v;
cin >> u >> v;
u = Find(u), v = Find(v);
if (u != v) {
fa[u] = v;
siz[v] += siz[u];
}
}
int ans = 0;
for (int i = 1; i <= n; i++) {
if (Find(i) == i) {
ans += siz[i] * (siz[i] - 1) / 2;
}
}
ans -= m;
cout << ans << endl;
// system("pause");
return 0;
}
E - Toward 0
记忆化搜索,期望DP
看到数据范围
1
0
18
10^{18}
1018, 但是每次操作都是除法,因此最多也就
l
o
g
log
log 次就操作完了,这个数据范围启发我们用搜索来求期望。
考虑
d
p
[
i
]
dp[i]
dp[i] 表示当前数字为
i
i
i 时,让它归零的期望代价,初始化
d
p
[
0
]
dp[0]
dp[0] 已经是0了,所以等0。
那么显然对于操作1,可以这样转移:
d
p
[
i
]
=
d
p
[
i
/
A
]
+
X
dp[i] = dp[i/A] + X
dp[i]=dp[i/A]+X, 即花费
X
X
X 的代价让它变成
i
/
A
i/A
i/A 的期望。
对于操作2,因为是投骰子,所以期望就是投六个数的期望均分6份合起来。即
d
p
[
i
]
=
1
6
∑
j
=
1
6
d
p
[
i
/
j
]
+
Y
dp[i]= \frac{1}{6}\sum_{j=1}^{6} dp[i/j]+Y
dp[i]=61∑j=16dp[i/j]+Y 。
由于是最佳操作,所以每次对于这两个操作,选取期望较小的那个,取min即可。
不过这么写完会发现样例跑不出来,调试后发现,对于操作2,当骰子扔到1的时候,又循环调用了递归自己,所以死循环了。对式子分析了一下,发现可以移项求出
d
p
[
i
]
dp[i]
dp[i] 的表达式,所以最终操作2的式子是
d
p
[
i
]
=
1
5
∑
j
=
2
6
d
p
[
i
/
j
]
+
6
5
×
Y
dp[i] = \frac{1}{5}\sum_{j=2}^{6}dp[i/j] + \frac{6}{5}\times Y
dp[i]=51∑j=26dp[i/j]+56×Y ,dp[i]就对这两个式子取min即可得到,保险起见可以再加一个记忆化,开long double保证一下精度。
代码:
#include <bits/stdc++.h>
#define int long long
#define inf 0x3f3f3f3f
#define ll long long
#define pii pair<int, int>
#define db long double
using namespace std;
const int maxn = 1e5 + 10;
const int mod = 998244353;
int n, a, x, y;
map<int, db> mp;
db dfs(int now) {
if (now == 0)
return 0;
if (mp[now])
return mp[now];
db res1 = x + dfs(now / a);
db res2 = 0;
for (int i = 2; i <= 6; i++)
res2 += 1.0 / 5 * dfs(now / i);
res2 += 6.0 / 5 * y;
return mp[now] = min(res1, res2);
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> a >> x >> y;
cout << fixed << setprecision(15) << dfs(n) << endl;
// system("pause");
return 0;
}
F - Transpose
递归,括号序列
题意是,给定一个带大小写字母的合法括号序列,每次选择一对括号(之间不能有其他括号),然后翻转该括号内的字符串,并将字母大小写反转,问最终的字符串长什么样。
首先对于括号序列,不难想到利用栈来求出每个括号匹配的另一半的位置,然后如果从最内部的括号开始,按题意去模拟翻转过程,很显然会超时,考虑一个较长的字母串,外面套很多层括号,每次去括号都需要对整个字母串翻转,但是我们又不知道连着的两层括号其实可以抵消。
于是,得考虑一些其他思路。
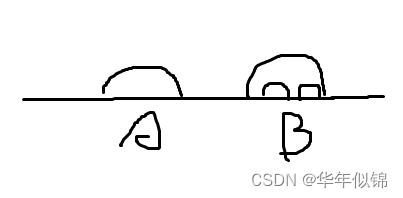
然后在草稿纸上画一画图,考虑上图的情况。横线是字母串,半圆表示需要进行翻转的区间,考虑这样的字母串应该要如何表示出来。
首先遍历字母串,A前面的部分就正常一个一个字母输出,然后到了A,就会考虑,能不能把整个A当成一个整体,去输出A解析后的字符串。因为A就一个嵌套,所以很容易处理出来A,接着往后到了B。也类似的,去考虑解析B,只要去看B内部的内容,B的内部又相当于是一条横线,两个待翻转区间,这时候就感觉出来这有点子问题的意思了,可以考虑递归解决。
因为处理A的时候,会发现,因为有一层括号,所以A内部的字符串我们应该逆序遍历,并且大小写翻转。而大小写是否改变,是跟括号嵌套的层数有关,所以考虑递归的函数里增加一个参数表示当前嵌套的层数,奇数次就逆序遍历,大小写反转,偶数次就正常顺着遍历。最终每个位置只遍历了一次,
O
(
n
)
O(n)
O(n) 的解决了该问题。
还有为了递归括号的内部,需要前面用栈预处理一下每个括号匹配的位置,然后递归的时候边界调整为匹配的括号的内侧一格处,怎么用栈匹配细节见代码:
#include <bits/stdc++.h>
// #define int long long
#define inf 0x3f3f3f3f
#define ll long long
#define pii pair<int, int>
#define db double
using namespace std;
const int maxn = 5e5 + 10;
const int mod = 998244353;
int pos[maxn];
char ch[maxn];
string cal(int l, int r, int num) {
if (l > r)
return "";
string ans;
if (num & 1) {
for (int i = r; i >= l; i--) {
if (ch[i] == ')') {
ans += cal(pos[i] + 1, i - 1, num + 1);
i = pos[i];
} else {
if (ch[i] <= 'Z')
ch[i] -= 'A' - 'a';
else
ch[i] -= 'a' - 'A';
ans += ch[i];
}
}
} else {
for (int i = l; i <= r; i++) {
if (ch[i] == '(') {
ans += cal(i + 1, pos[i] - 1, num + 1);
i = pos[i];
} else {
ans += ch[i];
}
}
}
return ans;
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
string str;
cin >> str;
int n = str.length();
for (int i = 1; i <= n; i++)
ch[i] = str[i - 1], pos[i] = i;
stack<int> stk;
for (int i = 1; i <= n; i++) {
if (ch[i] == '(')
stk.push(i);
else if (ch[i] == ')')
pos[stk.top()] = i, pos[i] = stk.top(), stk.pop();
}
cout << cal(1, n, 0) << endl;
// system("pause");
return 0;
}
G - Mediator
根号分治,强制在线
题意很简单,初始都是单点,两种操作,一是加一条边联通两个连通块,二是询问两个点是否有公共的相邻点。数据范围都是
1
0
5
10^5
105, 并且利用“加密”来强制在线。
考虑操作2的查询,发现如果我们存图,用vector存每个点的相邻点,操作2等价于两个vector求交集。集合求交也是很典的问题了,离线的话就可以用启发式合并,将查询捆绑,每次遍历查询之类的,参考百度之星的这道题 (当然这题也可以用在线的做法做)
但是这题强制在线,不能提前知道查询,提前建树,所以只好采取在线的做法。
首先,如果询问的两个点的度数比较小,那么直接暴力的遍历,复杂度也不会很大。但如果很多次询问都是问两个度数很大的点,每次遍历他们的相邻节点,复杂度就不能接受了。求集合交集,容易考虑使用bitset优化,交集就只要让两个bitset做与运算,与出来的1就代表交集部分。
但是如果给每个节点都开一个bitset,又显然不能接受这样的空间,但是因为度数很大的节点,数量不会多,所以根据
度数
×
点数
=
2
×
边数
度数\times 点数 = 2 \times 边数
度数×点数=2×边数, 即度数大于
2
×
n
\sqrt{2\times n}
2×n 的点数(记作超级点)不会超过
2
×
n
\sqrt{2\times n}
2×n个,我们只需要准备
2
×
n
\sqrt{2\times n}
2×n 个bitset即可,这样的空间复杂度是允许的。
然后对于查询,如果问的两个点都是超级点,则将它们对应的bitset 与一下,再遍历一遍结果,找是否有1,复杂度是
O
(
n
/
w
)
O(n/w)
O(n/w)。如果一个是超级点,一个是普通点,则遍历普通点的邻接表,判断超级点对应的bitset的对应位是否为1,复杂度
O
(
2
×
n
)
O(\sqrt{2\times n})
O(2×n) 。如果是两个普通点,则直接遍历第一个邻接表,标记元素是否出现,在遍历第二个邻接表时候判断每个元素是否出现过。复杂度
O
(
2
×
n
)
O(\sqrt{2\times n})
O(2×n)。所以均摊下来复杂度是可以接受的。
然后就是细节方面问题,维护每个点的度数,操作1给两个点度数增加,判断是否超过根号,超过了就新分配一个bitset给该节点,并且将邻接表里对应的位置1.然后注意,如果操作1已经是超级点了,别忘了给对应的位置1(之前wa3发就是忘记这个了)
代码:
#include <bits/stdc++.h>
#define int long long
#define inf 0x3f3f3f3f
#define ll long long
#define pii pair<int, int>
#define db double
using namespace std;
const int maxn = 2e5 + 20;
const int mod = 998244353;
int x[maxn], in[maxn];
int sq = 450;
int lst = 0, cnt;
int flag[maxn];
vector<int> G[maxn];
bitset<100100> bs[460];
int vis[maxn];
signed main() {
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int n, q;
cin >> n >> q;
for (int i = 1; i <= q; i++) {
int a, b, c;
cin >> a >> b >> c;
int op = 1 + (((a * (1 + lst)) % mod)) % 2;
int u = 1 + (((b * (1 + lst)) % mod)) % n;
int v = 1 + (((c * (1 + lst)) % mod)) % n;
if (op == 1) {
in[u]++;
in[v]++;
G[u].push_back(v);
G[v].push_back(u);
if (flag[u])
bs[flag[u]][v] = 1;
if (flag[v])
bs[flag[v]][u] = 1;
if (!flag[u] && in[u] >= sq) {
flag[u] = ++cnt;
bs[cnt].reset();
for (auto it : G[u])
bs[cnt][it] = 1;
}
if (!flag[v] && in[v] >= sq) {
flag[v] = ++cnt;
bs[cnt].reset();
for (auto it : G[v])
bs[cnt][it] = 1;
}
} else {
int ok = 0;
if (flag[u] && flag[v]) {
auto it = bs[flag[u]] & bs[flag[v]];
for (int i = 1; i <= n; i++)
if (it[i]) {
lst = i;
ok = 1;
break;
}
} else if ((!flag[u] && flag[v]) || (!flag[v] && flag[u])) {
if (flag[u] > 0)
swap(u, v);
for (auto it : G[u]) {
if (bs[flag[v]][it]) {
lst = it;
ok = 1;
break;
}
}
} else {
for (auto it : G[u])
vis[it] = 1;
for (auto it : G[v])
if (vis[it]) {
lst = it;
ok = 1;
break;
}
for (auto it : G[u])
vis[it] = 0;
}
if (!ok)
lst = 0;
cout << lst << "\n";
}
}
// system("pause");
return 0;
}

















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









