






前言
可能由于TJU的并行计算用的是天津的超算,所以网上稍微找了一圈都没有找到合适的攻略,在一顿探索后,打算造福后人 英雄登场,大概写一下对这个课实验的教程。
注意:代码等仅供同学们加深对课程知识点的理解,严禁抄袭,要是查重(不确定有没有)什么的被老师抓到了后果自负
资源
考虑到一些潜在的风险,就不提供完整的东西了,就下面给出一些我的参考代码供大家更好地学习并行计算。
环境准备
按pdf实验指导书,下载easyconnect,可以vpn登录天津超算。然后如果你有用vscode远程连接的经验的话,可以不用下载filezila,直接用vscode远程连接,然后可视化看着方便,而且也可以直接拖拽文件上传到虚拟机。
远程连接的方法就不细说了,大概就是ssh那里新建,然后把对应的IP地址输进去,然后输密码啥的。不过第一次连接因为要下载vscode对应组件时间比较慢。有的时候需要关掉重新打开(尤其是先点远程连接,再开VPN的时候,大概率会卡住一直转,关掉重新连接一次即可)
然后指导书上那种用cmd,ssh的连接其实没必要,而且操作起来更困难。第一节课VPN那个弄好就可以直接上vscode了。
第一步,写串行并行程序
远程连接后,可以先新建一个文件夹lab1,然后终端输入
cd lab1
进入文件夹,之后可以正常攥写串行和并行的程序,用c语言或者c++都可以。因为老师发的参考文件是c语言的,所以我给的代码就是c语言的了。
大概讲一下原理,这个程序是写了一个结构体,存储能够确定每个线程计算范围的数据,然后main函数里面创造对应的线程,通过把结构体传进去,核心进行cal()函数计算,每个线程算自己的那部分,然后通过互斥变量mutex互斥访问全局变量 my_res,来保证答案正确。(大概是这么个流程,因为这个程序我也是直接从老师那改一点的,理解也不是特别深刻)
并行程序↓
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
double my_res;
pthread_mutex_t mutex; // 互斥变量
typedef struct Args {
double x;
long max_n;
long begin;
long step;
} Args;
void *cal(void *_arg) {
long i, j;
double my_val, tem;
Args *arg = (Args *)_arg;
my_val = 0.0;
for (i = arg->begin; i <= arg->max_n; i += arg->step) {
tem = 1.0;
for (j = 1; j <= 2*i+1; j++) {
tem *= arg->x / (double)j;
}
if (i % 2 > 0) {
my_val -= tem;
} else {
my_val += tem;
}
}
pthread_mutex_lock(&mutex);
my_res += my_val; // 互斥修改my_val
pthread_mutex_unlock(&mutex);
return NULL;
}
int main(int argc, char *argv[]) {
if (argc != 4) {
printf("Parameters error: x N threads!\n");
exit(1);
}
pthread_mutex_init(&mutex, NULL); // 初始化互斥变量
long i;
double x = atof(argv[1]);
long max_n = atol(argv[2]);
int threads = atoi(argv[3]);
Args *arg;
double* my_val;
pthread_t *pid;
pid = (pthread_t *)malloc(threads * sizeof(pthread_t));
my_res = 0.0;
for (i = 0; i < threads; i++) {
arg = (Args *)malloc(sizeof(Args));
arg->x = x;
arg->max_n = max_n;
arg->begin = i;
arg->step = threads;
pthread_create(&pid[i], NULL, cal, (void *)arg);
}
for (i = 0; i < threads; i++)
pthread_join(pid[i], NULL);
printf("n = %ld, res =%lf\n", max_n, my_res);
free(pid);
pthread_mutex_destroy(&mutex);
return 0;
}
串行程序↓
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int main(int argc, char *argv[]) {
long i;
double x = atof(argv[1]);
long max_n = atol(argv[2]);
double res = 0;
int factor = 1;
for (int i = 0; i <= max_n; i++, factor = -factor) {
double tmp = 1.0;
for (int j = 1; j <= 2 * i + 1; j++)
tmp *= x / j;
tmp *= factor;
res += tmp;
}
printf("n = %ld, res = %lf\n", max_n, res);
}
第二步,小规模测试程序准确性
写好程序后,使用以下命令编译(多线程要加那个-pthread,串行程序不用应该也行)
g++ -pthread -o test.o test.c
这里的test是你写的程序的文件名,表示将test.c文件编译成可执行文件test.o
然后就可以通过
./test.o 参数1 参数2 参数3
来本地执行该程序,计算正弦值,所以可以取一些
π
\pi
π 之类的值测一下准确性。
注意:老师给的参考代码中没有保证互斥访问全局变量,因此需要改的部分就是加一下互斥访问
第三步,编写测试脚本提交任务
第二步确定了代码的正确性之后,就可以大规模地测试数据,为攥写报告准备。
我的脚本代码如下:
脚本名字:test.sh
#!/bin/bash
touch run.log
time yhrun -p thcp1 -n 1 -c 8 ./test.o 5 10000 8 &> run.log
time yhrun -p thcp1 -n 1 -c 8 ./test.o 5 20000 8 &> run.log
time yhrun -p thcp1 -n 1 -c 8 ./test.o 5 50000 8 &> run.log
time yhrun -p thcp1 -n 1 -c 8 ./test.o 5 100000 8 &> run.log
time yhrun -p thcp1 -n 1 -c 8 ./test.o 5 200000 8 &> run.log
time yhrun -p thcp1 -n 1 -c 8 ./test.o 5 500000 8 &> run.log
time yhrun -p thcp1 -n 1 -c 8 ./test.o 5 1000000 8 &> run.log
意思就是,测试7次程序,8个线程,并将结果写到run.log(不过因为覆盖关系,最终只会显示最后一次的结果,不过这个结果并不重要,因为我们报告主要去分析时间)
写好脚本之后,就可以使用指令提交任务
yhbatch -p thcp1 -n 1 ./test.sh

提交后,就会生成对应序列号的文件在当前路径,点击里面就是各个时间
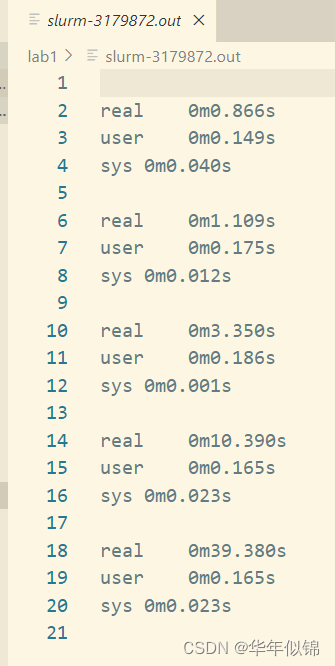
然后每个数据里面有3个时间,后两个不重要,我们报告里要去分析的就是第一个时间real time
结尾
然后这个实验的主要流程就是这样了,通过更改脚本文件里面的参数,选择适当的数据范围测试串行程序和并行程序,然后报告里面算一下加速比和效率,就好了。
吐槽一下,这个报告里面内容真的多,还要写什么课程感受啥的,问了几个同学,好像都是第一次写完,后面的报告就复制第一次里面的内容,有点麻烦的。我的报告就放在开头的github里面了,需要自取,仅供同学们学习参考用,严禁抄袭,违者后果自负。
常见问题
我每次实验一开始必效率大于1
算出来加速比大于线程数,即效率大于1的话,可以检查一下,用并行程序单线程运行,看看时间跟串行程序比较,就可以发现问题。有可能是数据类型double float这样的精度导致计算时间不同,也有可能是串行程序和并行程序本身算法的原理就不一样。保险起见,基本都可以用并行程序单线程执行当作串行程序时间来分析(懒得去写串行程序的话)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









