






往期实验的传送门:
实验二:多线程计算矩阵幂
实验一:多线程计算正弦值
实验三:多进程计算矩阵幂
前言
其实在实验三能顺利做完,有了代码的框架之后,再做实验四其实没什么难度了,只需要稍微改点东西。不过这里我怀疑我的代码也存在一些问题,因为最终分析加速比的时候,实验测出来的实验四的效果不如实验三。所以这里只能给大家仅供参考了,也欢迎大家指出我的问题到底在哪里。
免责声明:注意:代码等仅供同学们加深对课程知识点的理解,严禁抄袭,要是查重(不确定有没有)什么的被老师抓到了后果自负
环境要求
由于本次实验是MPI+OpenMP,所以和上次实验一样,需要先加载一下mpi环境,就跟着pdf指导书里面输入指令。
module load openmpi/4.1.4-mpi-x-gcc9.3.0
就是让虚拟机配置一下mpi的环境,然后才有办法编译用mpi库的程序。
算法介绍
这次实验的算法主体上是在实验三的代码基础上稍加改动,可以先去看看文章最前面的实验三传送门。实验三中是创建多个进程,将矩阵划分为多个子矩阵再分别进行矩阵乘法运算。本次实验的多级并行化,就是让每个进程分到的子矩阵,再次用多线程,进一步划分成更小的子矩阵之后让每个线程算最小的子矩阵。然后再汇总,其他大体跟实验三相同。
然后具体应该如何使用OpenMP多线程呢,可以参考一下ppt课件的实例:
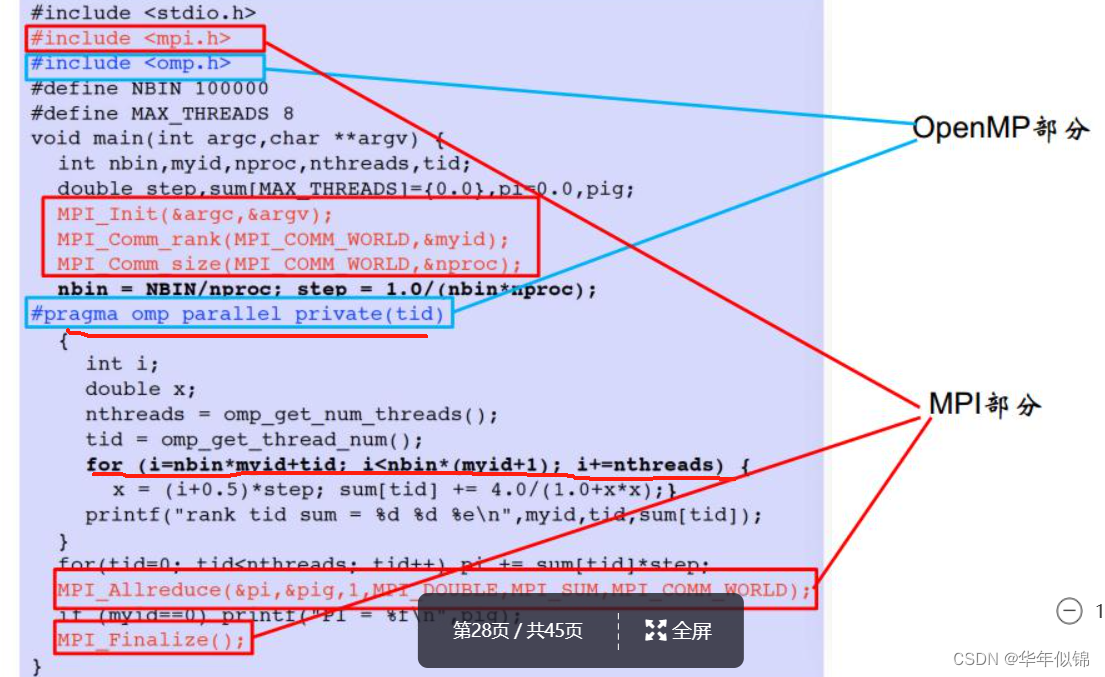
然后我们可以模仿着ppt里面的例子写,OpenMP的多线程利用tid号进行操作,具体的看下面代码里我的操作。
算法流程图:
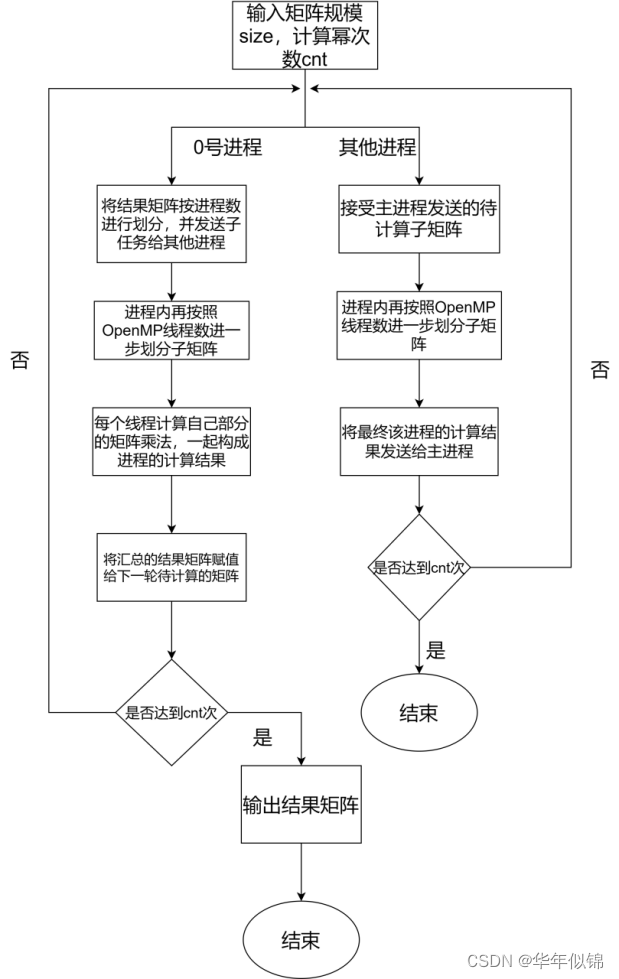
先上代码,然后讲解在代码注释里面:
#include <iostream>
#include <mpi.h>
#include <time.h>
#include <omp.h>
#define ll long long
using namespace std;
const int mod = 1e9 + 7;
int main(int argc, char** argv) {
srand(time(0));
int my_rank;
int num_procs;
int size = atoi(argv[1]);
int cnt = atoi(argv[2]);
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
int line = size / num_procs; // 每个进程计算的行数
int* local_a = new int[line * size];
int* b = new int[size * size];
int* ans = new int[line * size];
int* a = new int[size * size];
int* c = new int[size * size]; //用来缓冲区接受数据
ll trace = 0;
//cout << "mpi ran = " << my_rank << endl;
if (my_rank == 0) {
for (int i = 0; i < size; i++) { // a是计算矩阵,b是结果矩阵
for (int j = 0; j < size; j++) {
a[i * size + j] = rand() % 10;
// a[i * size + j] = 1;
b[i * size + j] = 0;
if (i == j)
b[i * size + j] = 1;
}
}
for (int ii = 1; ii <= cnt; ii++) {
MPI_Scatter(a, line * size, MPI_INT, local_a, line * size, MPI_INT, 0,
MPI_COMM_WORLD);
MPI_Bcast(b, size * size, MPI_INT, 0, MPI_COMM_WORLD);
int tid, nthreads;
omp_set_num_threads(4);
#pragma omp parallel private(tid)
{
nthreads = omp_get_num_threads();
tid = omp_get_thread_num(); // 当前线程的编号
// cout << "openmp tid = " << tid << endl;
// cout << "nthreads = " << nthreads << endl;
for (int i = tid; i < line; i += nthreads){ // 每个线程计算该进程中分配到的若干行
for (int j = 0; j < size; j++) {
int temp = 0;
for (int k = 0; k < size; k++)
temp = (temp + 1ll * a[i * size + k] * b[k * size + j]) % mod;
ans[i * size + j] = temp;
}
// printf("nthreads ii rank tid = %d %d %d %d \n", nthreads, ii, my_rank, tid);
}
}
MPI_Gather(ans, line * size, MPI_INT, c, line * size, MPI_INT, 0,
MPI_COMM_WORLD);
for (int i = 0; i < size; i++)
for (int j = 0; j < size; j++)
b[i * size + j] = c[i * size + j];
}
// cout << "ans:" << endl;
// for (int i = 0; i < size; i++) {
// for (int j = 0; j < size; j++) {
// cout << b[i * size + j] << " ";
// }
// cout << endl;
// }
// for (int i = 0; i < size; i++)
// for (int j = 0; j < size; j++)
// trace = (trace + b[i * size + j]) % mod;
// cout << trace << endl;
} else {
while (cnt--) {
int* buffer = new int[size * line];
MPI_Scatter(a, line * size, MPI_INT, buffer, line * size, MPI_INT, 0,
MPI_COMM_WORLD);
MPI_Bcast(b, size * size, MPI_INT, 0, MPI_COMM_WORLD);
// 接受矩阵后,利用openmp多线程计算buffer跟b的矩阵乘法
// 即将line再次划分,给多线程计算
omp_set_num_threads(4);
int tid, nthreads;
#pragma omp parallel private(tid)
{
// cout << "fuck" << endl;
nthreads = omp_get_num_threads(); // 总线程数
tid = omp_get_thread_num(); // 当前线程的编号
// cout << nthreads << endl;
for (int i = tid; i < line; i += nthreads){
for (int j = 0; j < size; j++) {
int temp = 0;
for (int k = 0; k < size; k++)
temp = (temp + 1ll * buffer[i * size + k] * b[k * size + j]) % mod;
ans[i * size + j] = temp;
}
}
//printf("rank tid = %d %d \n", my_rank, tid);
}
MPI_Gather(ans, line * size, MPI_INT, c + my_rank * line * size,
line * size, MPI_INT, 0, MPI_COMM_WORLD);
delete[] buffer;
}
}
delete[] a, local_a, b, ans, c;
MPI_Finalize();
return 0;
}
代码中有很大一部分是注释掉的,这部分内容主要是为了保证矩阵乘法的正确性,可以通过小规模的矩阵的输出矩阵,来验证一下我们的矩阵乘法程序的正确性。
写好程序后,注意现在的编译命令改为
mpic++ -fopenmp -o bing.o bing.cpp
如果前面没有输那句 module load配一下mpi环境的话编译会报错。
因为这次懒得写串行了,我就直接用单核单线程来替代串行程序,脚本如下:
#!/bin/bash
module load openmpi/4.1.4-mpi-x-gcc9.3.0
# time yhrun -p thcp1 -N 1 -n 1 -c 1 bing.o 10 2 &> chuan.log
# time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 960 200 &> bing.log
# time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 1600 10 &> bing.log
time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 80 500 &> bing.log
time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 240 100 &> bing.log
time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 240 200 &> bing.log
time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 496 100 &> bing.log
time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 496 200 &> bing.log
time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 960 200 &> bing.log
time yhrun -p thcp1 -N 2 -n 2 -c 4 bing.o 1600 10 &> bing.log
编写好脚本bing.sh后,最后提交任务
yhbatch -p thcp1 -N 2 -n 2 ./bing.sh
注意事项
这里有两个地方,是我当初卡了一段时间的问题,我上面的代码是已经解决了我发现的问题的最终版本。
问题一:矩阵划分问题
因为是模仿实验三,实验三中特地强调了,我们输入的矩阵规模必须是8的倍数。然后在这次实验中一开始我忘了这个事情,开始测的就是
10
×
10
10 \times 10
10×10 的规模,然后也没错。
然后我想了很久,最后发现,因为实验三是MPI那块,分8个进程,所以规模是8的倍数。然后这次实验里,最后指令只要求MPI分2个进程,所以只要是2的倍数都可以正常计算,而里面细分的多线程是没有均分的要求限制,故其实就是正确的。
问题二:加速比异常问题
噔噔咚,每次实验必遇到的加速比异常来咯
一开始我算出来加速比超级高,远超8倍。为了检测问题,果断在sh脚本中改成单核单线程运行,发现显然比穿行时间要快。所以控制了一下变量,发现只可能是OpenMP的多线程有问题。
然后输出一下tid,发现虽然我们脚本里控制 -c4,只使用4个线程,但是实际上他使用的远超4个线程,所以实际上的并行核心数量远超8个,所以加速比爆炸了。
因为后面还需要分析不同实验的加速比,所以还是得控制一下变量,就让2个进程,每个进程内的OpenMP都使用4个线程了。所以可以看到我上面的代码中有一行
omp_set_num_threads(4);
就是为了让他控制一下只使用4个线程。
尾声
到此,四次实验都完成了,最后还会交一个大作业,就是对比后三次实验,不同并行计算方式情况下的加速比等,还需要搞个ppt和录视频介绍。
为了要对比,所以最后还是把实验二重新测了一次,不然这几次实验的数据规模不同,不太好分析。然后会发现,我实验二的方式,是9个线程,所以最后我还是按照行划分的方式,重新写了一次实验二,重新测数据了。
至于加速比等的对比,我这里建议将数据放到excel上,然后用excel来画一些柱形图之类的,看起来能比较美观一些。当然如果会python画图啥的肯定更好。
也欢迎大家写一写自己的实验记录,功在当代,利在千秋啊,这就是TJU的精神传承。
















 5527
5527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









