






文章目录
1. 什么是LSTM
-
LSTM(长短时记忆网络,Long Short-Term Memory)专门用来处理「时间序列」数据的神经网络。
-
LSTM 比普通的神经网络厉害的地方:
-
能记住长时间的过去信息(比如今天的股价可能受上个月的趋势影响)
-
能忘掉无关的信息(比如 10 年前的股价对今天的预测没啥用)
-
可以自动学习哪些信息重要,哪些可以忽略
-
-
LSTM 主要由遗忘门、输入门、输出门这三部分组成(如何结合LSTM的数据流图也可以将记忆单元作为其中的一部分):
-
遗忘门:决定要丢弃哪些过去的信息(比如太久的数据就不管了)
-
输入门:决定要记住哪些新的信息
-
输出门:决定最终输出什么信息
-
记忆单元:对历史数据进行记忆存储
-
2. 公式解析
LSTM 是 RNN 的一种改进版本,专门用来处理时间序列数据,解决普通 RNN由于梯度消失和梯度爆炸而引发的 容易遗忘远程信息的缺点。
2.1 传统RNN
在传统的 RNN 中,隐状态
h
t
h_t
ht 是根据当前输入
x
t
x_t
xt 和上一时刻的隐状态
h
t
−
1
h_{t-1}
ht−1 计算得到的:
h
t
=
t
a
n
h
(
W
h
h
t
−
1
+
W
x
x
t
+
b
h
)
h_t = tanh(W_hh_{t-1} + W_xx_t + b_h)
ht=tanh(Whht−1+Wxxt+bh)
- h t h_t ht : 是当前时刻的隐状态
- x t x_t xt:当前输入
- W h 、 W x W_h、W_x Wh、Wx:是可训练的权重矩阵
- b h b_h bh:偏置项
- t a n h ( ∗ ) tanh(*) tanh(∗) :激活函数
RNN 存在梯度消失和梯度爆炸问题,导致无法学习长期依赖关系。因此,LSTM 通过门控机制来解决这个问题。
2.2 LSTM的公式
LSTM 通过**三个门(遗忘门、输入门、输出门)和一个记忆单元(Cell State)**来控制信息的流动,使得网络能够记住长期信息,同时避免梯度消失问题。
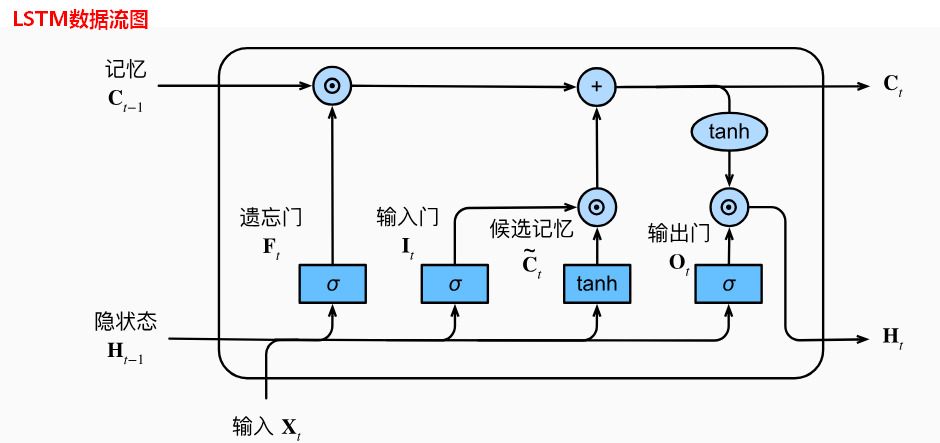
- 公式汇总(可以按照后续遗忘门、输入门、记忆单元、输出门进行记忆)
f t = σ ( x t W x f + h t − 1 W h f + b f ) f_t = \sigma(x_tW_{xf} + h_{t-1}W_{hf} + b_f) ft=σ(xtWxf+ht−1Whf+bf)
i t = σ ( x t W x i + h t − 1 W h i + b i ) i_t = \sigma(x_tW_{xi}+h_{t-1}W_{hi} + b_i) it=σ(xtWxi+ht−1Whi+bi)
C ~ t = t a n h ( x t W x c + h t − 1 W h c + b c ) \tilde{C}_t = tanh(x_tW_{xc} + h_{t-1}W_{hc} + b_c) C~t=tanh(xtWxc+ht−1Whc+bc)
C t = f t ⊙ C t − 1 + i t ⊙ C ~ t C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t Ct=ft⊙Ct−1+it⊙C~t
o t = σ ( x t W x o + h t − 1 W h o + b o ) o_t = \sigma(x_tW_{xo} + h_{t-1}W_{ho} + b_o) ot=σ(xtWxo+ht−1Who+bo)
h t = o t ⊙ t a n h ( C t ) h_t = o_t \odot tanh(C_t) ht=ot⊙tanh(Ct)
-
维度变化
根据LSTM 公式,我们来细化一下维度的变化:假设有 h h h 个隐藏单元,批量大小为 n n n,输入维度为 d d d,因此:
-
输入 x t x_t xt 的维度为 n × d n \times d n×d
-
上一时刻隐状态 h t − 1 h_{t-1} ht−1 的维度 n × h n \times h n×h
-
遗忘门 f t f_t ft、输入门 i t i_t it 、输出门 o t o_t ot 的维度均为 n × h n \times h n×h
-
C ~ t , C t \tilde{C}_t,C_t C~t,Ct 的维度均为 n × h n \times h n×h
-
模型参数 W x i , W x f , W x o W_{xi},W_{xf},W_{xo} Wxi,Wxf,Wxo 的维度均为 d × h d \times h d×h
-
模型参数 W h i , W h f , W h o W_{hi},W_{hf},W_{ho} Whi,Whf,Who 的维度均为 h × h h \times h h×h
-
模型参数 b i , b f , b o , b c b_{i},b_{f},b_{o},b_{c} bi,bf,bo,bc 的维度为 1 × h 1 \times h 1×h
-
-
其他说明
-
遗忘门、输入门、输出门: 均有 s i g m o i d sigmoid sigmoid 函数激活,门控输出值都在 ( 0 , 1 ) (0,1) (0,1) 之间的值
-
候选记忆单元:与遗忘门、输入门、输出门的计算类似,但是使用 t a n h tanh tanh 作为激活函数,使得输出值范围为 ( − 1 , 1 ) (-1,1) (−1,1)
-
LSTM 引入了记忆单元,有些文献认为其是隐状态的一种特殊类型,他与隐状态具有相同的形状,设计的目的用于记录附加的记忆信息
- 记忆单元:由遗忘门、输入门 控制,引入这种设计师为了缓解梯度消失和梯度爆炸的问题,并更好地捕获序列中长距离依赖关系
-
隐状态
- 由输出门控制,在LSTM中,它仅仅是记忆单元的 t a n h tanh tanh 的门控版本,确保了隐状态的值始终位于 ( − 1 , 1 ) (-1,1) (−1,1) 区间之间
- 输出门接近1,就能够有效地将所有记忆信息传递给预测部分
- 输出门接近0,我们只保留记忆单元内的所有信息,而不需要更新隐状态
-
2.2.1 遗忘门
- 公式
f t = σ ( x t W x f + h t − 1 W h f + b f ) f_t = \sigma(x_tW_{xf} + h_{t-1}W_{hf} + b_f) ft=σ(xtWxf+ht−1Whf+bf)
- 参数解释
- f t f_t ft:遗忘门的输出(0-1之间的值)
- W x f , W h f , b f W_{x_f},W_{hf},b_f Wxf,Whf,bf:遗忘门的权重和偏置
- h t − 1 h_{t-1} ht−1:上一时刻的隐藏状态
- x t x_t xt:当前时刻的输入
- σ ( ∗ ) \sigma(*) σ(∗):sigmoid激活函数,用于输出 0-1 之间的概率值,决定遗忘多少信息
- 作用
- 如果 f t f_t ft 近似为0,则表示遗忘过去信息
- 如果 f t f_t ft 近似为1, 则表示完全保留过去信息
2.2.2 输入门
-
公式
i t = σ ( x t W x i + h t − 1 W h i + b i ) i_t = \sigma(x_tW_{xi}+h_{t-1}W_{hi} + b_i) it=σ(xtWxi+ht−1Whi+bi)C ~ t = t a n h ( x t W x c + h t − 1 W h c + b c ) \tilde{C}_t = tanh(x_tW_{xc} + h_{t-1}W_{hc} + b_c) C~t=tanh(xtWxc+ht−1Whc+bc)
-
参数解释
- i t i_t it:输入门的输出(0-1之间的值),决定当前输入信息的重要性
- C ~ t \tilde{C}_t C~t:候选记忆单元状态,用 t a n h tanh tanh 激活,使其取值为 ( − 1 , 1 ) (-1,1) (−1,1)
- W x i , W h i , W x c , W h c , b i , b c W_{xi},W_{hi},W_{xc},W_{hc},b_i,b_c Wxi,Whi,Wxc,Whc,bi,bc: 可训练的模型参数
-
作用
- i t i_t it:控制新信息的引入程度
- C ~ t \tilde{C}_t C~t:是新加入的候选记忆信息
2.2.3 记忆单元更新
-
公式
C ~ t = t a n h ( x t W x c + h t − 1 W h c + b c ) \tilde{C}_t = tanh(x_tW_{xc} + h_{t-1}W_{hc} + b_c) C~t=tanh(xtWxc+ht−1Whc+bc) -
参数解释
- C t C_t Ct:当前时刻的记忆单元状态
- ⊙ \odot ⊙:代表逐元素相乘(Hadamard 乘积)
- W x c , W h c , b c W_{xc},W_{hc},b_c Wxc,Whc,bc :可训练的模型参数
-
作用
- 上一时刻的记忆单元信息 C t − 1 C_{t-1} Ct−1 经过 f t f_t ft 处理后,决定要保留多少记忆信息
- 新信息(候选记忆单元) C ~ t \tilde{C}_t C~t 经过 i t i_t it 处理后,决定要新加入多少信息到记忆单元中
2.2.4 输出门
-
公式
o t = σ ( x t W x o + h t − 1 W h o + b o ) o_t = \sigma(x_tW_{xo} + h_{t-1}W_{ho} + b_o) ot=σ(xtWxo+ht−1Who+bo)h t = o t ⊙ t a n h ( C t ) h_t = o_t \odot tanh(C_t) ht=ot⊙tanh(Ct)
-
参数解释
- o t o_t ot:控制 LSTM 单元的输出信息量
- h t h_t ht:当前的隐状态,也是输出
- W x o , W h o , b o W_{xo},W_{ho},b_o Wxo,Who,bo :可训练的模型参数
-
作用
- 用 o t o_t ot 控制哪些信息最终影响输出
- 用 t a n h ( C t ) tanh(C_t) tanh(Ct) 让输出新信息保持在 ( − 1 , 1 ) (-1,1) (−1,1) 范围内
3. LSTM优缺点与适用场景
3.1 优点
- 能处理长时间依赖:LSTM 通过 遗忘门、输入门、输出门 机制,可以记住重要的历史信息,忽略无关的过去数据。
- 能处理非线性时间序列:比传统统计方法(如 ARIMA)更适用于复杂模式的数据,如金融市场、语音识别等。
- 自动特征学习:不需要手动提取特征,LSTM 可以从数据中自动学习重要模式。
- 适用于高维时间序列:如多变量天气预测(温度、湿度、气压等多个变量影响)。
- 能处理不规则时间间隔数据:不像 ARIMA 需要等间隔数据,LSTM 能适应不规则时间序列。
3.2 缺点
- 计算成本高:LSTM 的参数较多,训练时间长,计算量比传统时间序列模型大。需要 GPU 加速才能高效训练。
- 对短期数据可能表现不佳:在数据量少或模式变化快的情况下,LSTM 可能无法比简单的 ARIMA 或回归方法表现更好。
- 超参数调整困难:需要调整隐藏层大小、时间步数、学习率等参数,调整不当可能导致模型过拟合或欠拟合。
- 黑盒特性:传统时间序列模型(如 ARIMA)有清晰的数学公式,而 LSTM 的计算过程较复杂,难以解释其内部逻辑。
3.3 适用场景
LSTM 适用于 处理时间依赖性强、长时间依赖、非线性、复杂模式的数据。典型应用场景如下
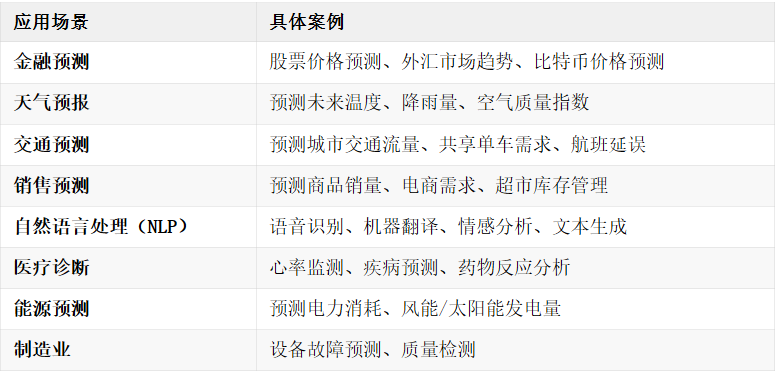
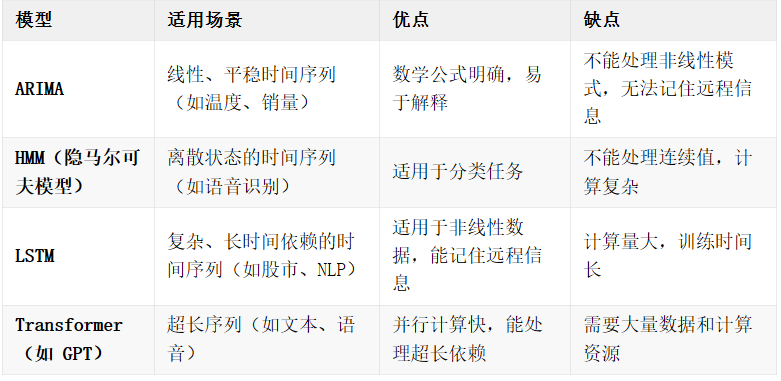
3.4 LSTM vs 其他时间序列模型

















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









