







EM算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测到的隐变量。
EM估计GMM参数
1)初始值:
方1:协方差矩阵Σk设为单位矩阵,每个模型比例的先验概率πk=1/N,均值uk设为随机数。
方2:由k均值(k-means)聚类算法对样本进行聚类,利用各类的均值作为uk,并计算Σk,πk取各类样本占样本总数的比例。
一般选用方法一。
2)EM算法:
E-Step :E就是Expectation的意思,就是假设模型参数已知的情况下求隐含变量Z分别取z1,z2,…的概率。在GMM中就是求数据点由各个 component生成的概率。
γ(i,k)=αk∗Pr(Zk|xi,π,μ,Σ) ——就是当前观测数据属于第k个componen的概率
注意到我们在Z的后验概率前面乘以了一个权值因子 αk ,它表示选中类别 zk 的频率,在GMM中它就是 πk 。
M-Step: M就是Maximization的意思,就是用最大似然的方法求出模型参数。现在我们认为上一步求出的r(i,k)就是“数据点xi由component k生成的概率”。根据公式(3),(4),(5)可以推出均值、协方差和权值的更新公式为:
Nk=∑Ni=1γ(i,k)
μ(k)=1Nk∑Ni=1γ(i,k)xi
π(k)=NkN
Σk=1Nk∑Ni=1γ(i,k)(xi−μk)(xi−μk)T
3)收敛条件:
不断地迭代E和M步骤,重复更新上面的三个值,直到参数的变化不显著。
GMM是一种聚类算法,每个component就是一个聚类中心。即在只有样本点,不知道样本分类(含有隐含变量)的情况下,计算出模型参数(π,u和Σ),这可以用EM算法来求解。再用训练好的模型去差别样本所属的分类,方法是:step1随机选择K个component中的一个(被选中的概率是πk);step2把样本代入刚选好的component,判断是否属于这个类别,如果不属于则回到step1。
R中的包mclust可用于分析高斯混合模型的聚类
例如:
##基于GMM的模型的聚类分析,GMM中的每一个高斯分布都可以代表数据的一类
library(mclust)
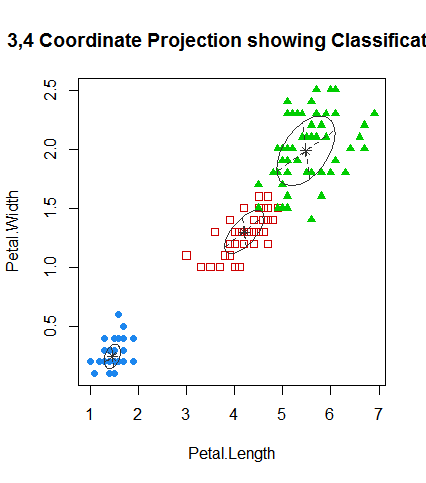
mc <- Mclust(iris[,1:4],3)
plot(mc,what="classification",dimens=c(3,4))
table(iris$Species,mc$classification)
1 2 3
setosa 50 0 0
versicolor 0 45 5
virginica 0 0 50















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









