






目录
1.支持向量机(Support Vector Machine, SVM)简介
1.支持向量机(Support Vector Machine, SVM)简介
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。在机器学习领域,不仅可以用于分类问题,还可以进行回归分析。SVM通过将数据映射到高维空间中,找到一个最优的超平面来划分不同类别的数据点,从而实现了高效准确的分类。
2.基本原理
2.1 最大间隔
最大间隔是支持向量机(SVM)算法的关键概念之一。它指的是在所有可能的超平面中,选择具有最大间隔的超平面作为最优解。
在二分类问题中,我们希望找到一个超平面,能够将不同类别的数据点完全分开。这个超平面可以用线性方程表示为:
其中w是法向量,b是偏置项。超平面将数据空间划分为两个区域,分别对应不同的类别。
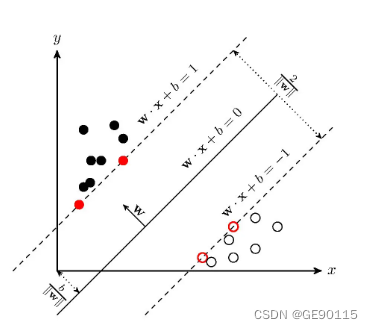
最大间隔的概念涉及到支持向量,即离超平面最近的训练样本点。这些支持向量在决策边界的确定和分类结果的预测中起到重要作用。
通过最大化间隔,SVM的目标是找到一个最优超平面,使得支持向量到超平面的距离最大化。这样做的好处是,对于新的未知数据点,其分类结果更加可靠,并且具有良好的泛化能力。
最大间隔超平面的求解可以转化为一个凸优化问题,通过求解约束最优化问题可以得到最优解。常见的求解方法有拉格朗日乘子法和SMO(Sequential Minimal Optimization)算法等。
2.2 对偶问题
在支持向量机(SVM)算法中,由于原始问题的求解比较困难,因此通常使用对偶问题来求解。对偶问题是将原问题转化为另一个优化问题的过程,通过求解对偶问题可以得到原始问题的最优解。
具体来说,SVM的对偶问题是基于拉格朗日乘子法推导出来的。在求解原始问题时,我们需要求解一个带有不等式约束的优化问题。如果直接求解这个优化问题,会面临计算难度大、收敛缓慢等问题。而通过构造拉格朗日函数,然后对其进行极大极小化,我们可以得到一个对偶问题,它的求解比原始问题更加简单。
SVM的对偶问题可以表示为一个二次规划问题,其中目标函数是拉格朗日函数的极小值,约束条件包括拉格朗日乘子的非负性和原始问题的互补松弛条件。通过使用优化算法求解对偶问题,我们可以得到最优的拉格朗日乘子,从而确定最优的超平面。
对偶问题的优点在于,一方面它可以转化为一个更简单的优化问题,另一方面它还可以帮助我们更好地理解SVM算法的原理和性质。此外,对偶问题还可以用于处理非线性问题,通过引入核函数将数据点映射到高维空间中,使其在高维空间中线性可分。
2.2.1 等式约束优化问题
拉格朗日程数法是等式约束优化问题:
令,函数
称为 Lagrange 函数,参数
称为 Lagrange 乘子没有非负要求。
利用必要条件找到可能的极值点:
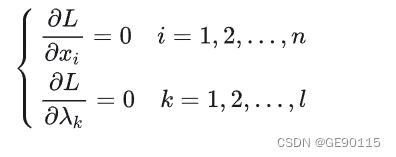
具体是否为极值点需根据问题本身的具体情况检验。这个方程组称为等式约束的极值必要条件。
等式约束下的 Lagrange 乘数法引入了 个 Lagrange 乘子,把
也看作优化变量,共有
个优化变量。
2.2.2 不等式约束优化问题
其中目标是在一组不等式约束条件下找到使目标函数最小或最大的变量取值。
一般来说,不等式约束优化问题可以表示为以下形式:
最小化(或最大化)目标函数
约束条件 , ..., m
其中,x 是变量向量,f(x) 是待优化的目标函数,是不等式约束函数,m 是约束条件的个数。
解决不等式约束优化问题的常用方法之一是使用拉格朗日乘子法(Lagrange Multiplier Method)。该方法通过引入拉格朗日乘子(Lagrange Multipliers),将约束优化问题转化为无约束优化问题。具体而言,引入一个拉格朗日函数,该函数由原目标函数和各个约束条件乘以相应的拉格朗日乘子组成。然后,通过求解拉格朗日函数对各个变量和乘子的偏导数为零的方程组,得到最优解。
2.2.3 强对偶性
对偶问题其实就是将:
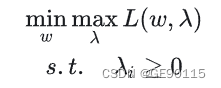
变成了:
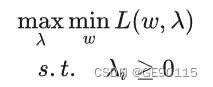
假设有个函数有:
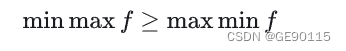
也就是说,最大的里面挑出来的最小的也要比最小的里面挑出来的最大的要大。这关系实际上就是弱对偶关系,而强对偶关系是当等号成立时,即:
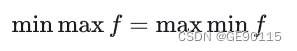
如果 是凸优化问题,强对偶性成立。而我们之前求的 KKT 条件是强对偶性的充要条件。
2.3 核函数
在SVM算法中,核函数是一种用于将输入空间映射到高维特征空间的函数。它的作用是通过引入非线性变换,将原始数据从低维空间转化为高维空间,使得数据在高维空间中更容易被线性分割。
核函数的引入可以解决原始数据在低维空间中不可分的问题。在高维特征空间中,数据可能会变得线性可分。这样一来,SVM就可以通过寻找一个超平面来划分数据,并且具有更好的分类性能和泛化能力。
核函数的优势在于,它不需要直接计算高维特征空间中的内积,而是通过核技巧(Kernel Trick)来间接计算。这样可以避免高维空间的计算复杂性,提高计算效率。常见的核函数包括线性核函数、多项式核函数、高斯核函数等,选择合适的核函数取决于数据的特点和问题的需求。
以高斯核函数(也称为径向基函数,Radial Basis Function,RBF)为例,它是最常用的核函数之一。高斯核函数将数据映射到无穷维的特征空间中,它的形式为:
高斯核函数对应于一个以数据点为中心的高斯分布,可以捕捉到数据点的局部特征。
通过使用核函数,SVM算法可以适应更复杂的数据分布,提高分类的准确性和泛化能力。同时,核函数也扩展了SVM算法的应用范围,使其可以处理非线性问题。
需要注意的是,在使用核函数时,选择合适的核函数和参数是很关键的。不同的核函数适用于不同类型的数据和问题,因此在实际应用中需要进行实验和调优,以找到最佳的核函数和参数组合。
常用的核函数:
在构造核函数后,验证其对输入空间内的任意格拉姆矩阵为半正定矩阵是困难的,因此通常的选择是使用现成的核函数。以下给出一些核函数的例子,其中未做说明的参数均是该核函数的超参数(hyper-parameter)

2.4 软间隔与正则化
损失函数(loss function)
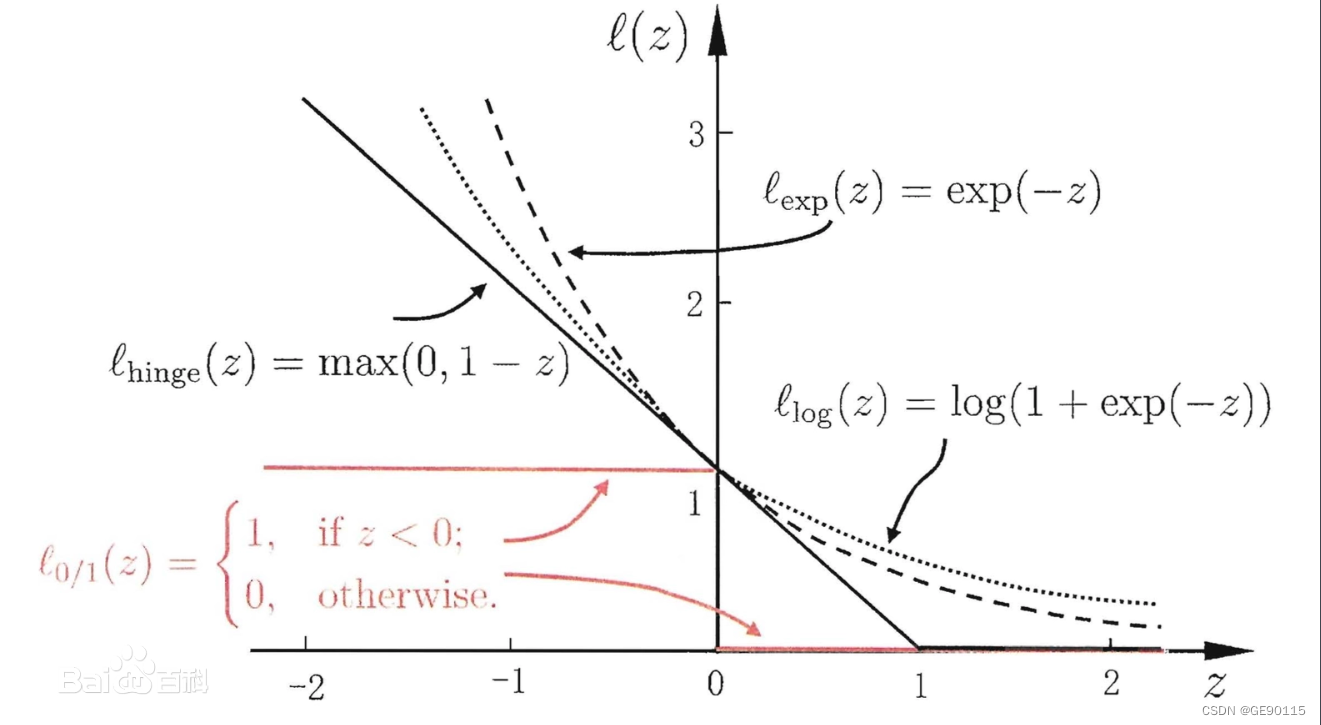
在一个分类问题不具有线性可分性时,使用超平面作为决策边界会带来分类损失,即部分支持向量不再位于间隔边界上,而是进入了间隔边界内部,或落入决策边界的错误一侧。损失函数可以对分类损失进行量化,其按数学意义可以得到的形式是0-1损失函数:
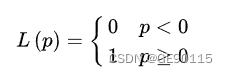
0-1损失函数不是连续函数,不利于优化问题的求解,因此通常的选择是构造代理损失(surrogate loss)。可用的选择包括铰链损失函数(hinge loss)、logistic损失函数(logistic loss)、和指数损失函数(exponential loss),其中SVM使用的是铰链损失函数
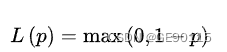
对替代损失的相合性研究表明,当代理损失是连续凸函数,并在任意取值下是0-1损失函数的上届,则求解代理损失最小化所得结果也是0-1损失最小化的解。铰链损失函数满足上述条件。
软间隔(Soft Margin)是指在SVM分类模型中允许一定数量的数据点出现在超平面的错误一侧,即容忍一定程度的分类错误。相比之下,硬间隔(Hard Margin)要求所有数据点都被正确地分类,这在实际应用中很难实现,特别是当数据存在噪声或重叠的情况下。
软间隔通过引入松弛变量(Slack Variable)来实现,松弛变量允许一些数据点位于超平面的错误一侧,同时在目标函数中增加一个惩罚项,以平衡分类准确性和间隔的大小。通过调整惩罚项的权重,可以控制模型对于误分类的容忍程度。
软间隔的优点在于它可以处理具有噪声或重叠的数据集,提高模型的鲁棒性和泛化能力。然而,过大的容错空间可能会导致模型过度拟合,因此在使用软间隔时需要进行适当的调参,以平衡分类错误和间隔的权衡。
正则化(Regularization)是一种用于防止过拟合的技术,它通过在优化目标函数中引入正则化项来限制模型的复杂度。正则化项通常是模型参数的平方和或绝对值和,其中的惩罚系数控制着正则化的强度。通过增加正则化项,可以对模型进行约束,防止它过于拟合训练数据,提高模型在测试数据上的泛化能力。
正则化的作用是在最小化目标函数时,使得模型更倾向于选择简单的解,避免过度拟合。它可以减少模型的方差,降低模型对噪声的敏感性,并且有助于提高模型在未知数据上的性能。
在SVM算法中,正则化通常以惩罚项的形式出现在优化目标函数中,例如L1正则化和L2正则化。L1正则化通过将模型参数的绝对值和作为惩罚项,促使模型选择稀疏的特征;而L2正则化通过将模型参数的平方和作为惩罚项,促使模型选择较小的参数值。
2.5 核方法
核方法(Kernel Methods)是一种在机器学习领域中广泛应用的技术,主要用于处理非线性问题和高维特征空间中的数据分析。
核方法的基本思想是通过引入核函数(Kernel Function)来将数据从原始空间映射到一个更高维的特征空间,使得原始数据在新的特征空间中更容易被线性分割。换句话说,核方法可以将非线性问题转化为线性问题来解决。
核函数是一种对称正定的函数,可以计算两个向量之间的内积。通过核技巧(Kernel Trick),我们可以在不直接计算高维特征空间中的内积的情况下,利用核函数隐式地计算出内积,从而避免了高维空间的计算复杂性。这样就使得在高维特征空间中进行计算变得高效和可行。
常见的核函数包括线性核函数、多项式核函数、高斯核函数等。线性核函数对应于在原始特征空间中直接进行线性分类,而多项式核函数和高斯核函数则可以处理更复杂的非线性关系。选择哪种核函数取决于数据的特点和问题的需求。
核方法在机器学习中有许多应用,其中最著名的应用之一是支持向量机(Support Vector Machine,SVM)。SVM利用核方法将数据映射到高维特征空间中,通过寻找一个最优的超平面来实现线性分类或回归。另外,核方法还广泛应用于主成分分析(Principal Component Analysis,PCA)、聚类分析、降维等领域。
核方法的优势在于能够处理非线性问题,通过引入核函数可以将数据映射到更高维的特征空间中,从而提高模型的表达能力和分类准确性。然而,选择合适的核函数和参数是很关键的,不同的核函数适用于不同类型的数据和问题,需要进行实验和调优来找到最佳的核函数和参数组合。
2.具体实现
使用支持向量机(SVM)进行分类的示例,具体实现利用鸢尾花数据集来实现
首先,导入必要的库和模块。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score然后,加载鸢尾花数据集,并选择其中的两个特征(萼片长度和萼片宽度)用于训练和可视化。
# 导入鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征,方便可视化
y = iris.target接下来,将数据集划分为训练集和测试集,以便评估模型的性能。
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)创建一个线性核函数的支持向量机(SVM)模型。
# 创建支持向量机模型
svm = SVC(kernel='linear')通过调用fit()方法,使用训练集对SVM模型进行训练。
# 训练模型
svm.fit(X_train, y_train)使用训练好的模型对测试集进行预测,得到分类结果。
# 预测测试集
y_pred = svm.predict(X_test)计算预测准确率,衡量模型在测试集上的性能。
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
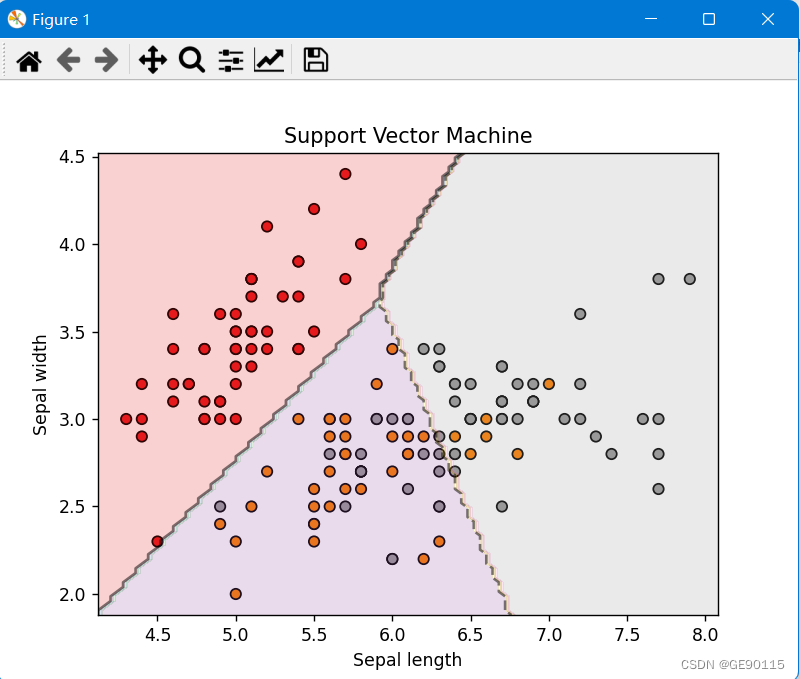
print("准确率:", accuracy)在数据可视化部分,使用散点图展示鸢尾花数据集,其中不同类别的样本用不同颜色表示。
绘制决策边界,将特征空间划分为不同的区域,用于决策样本的分类。
最后,显示图表,展示数据集、决策边界和分类结果。
# 绘制散点图
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1, edgecolors='k')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
# 绘制决策边界
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 100),
np.linspace(ylim[0], ylim[1], 100))
xy = np.column_stack([xx.reshape(-1), yy.reshape(-1)])
Z = svm.predict(xy)
Z = Z.reshape(xx.shape)
# 绘制等高线图
ax.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.Set1)
ax.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
plt.title('Support Vector Machine')
plt.show()输出的散点图:
完整代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 导入鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征,方便可视化
y = iris.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建支持向量机模型
svm = SVC(kernel='linear')
# 训练模型
svm.fit(X_train, y_train)
# 预测测试集
y_pred = svm.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 绘制散点图
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1, edgecolors='k')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
# 绘制决策边界
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 100),
np.linspace(ylim[0], ylim[1], 100))
xy = np.column_stack([xx.reshape(-1), yy.reshape(-1)])
Z = svm.predict(xy)
Z = Z.reshape(xx.shape)
# 绘制等高线图
ax.contourf(xx, yy, Z, alpha=0.2, cmap=plt.cm.Set1)
ax.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
plt.title('Support Vector Machine')
plt.show()















 3806
3806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









