






Python 从0到1构建MCP Server & Client
简介
MCP Server 是实现模型上下文协议(MCP)的服务器,旨在为 AI 模型提供一个标准化接口,连接外部数据源和工具,例如文件系统、数据库或 API。
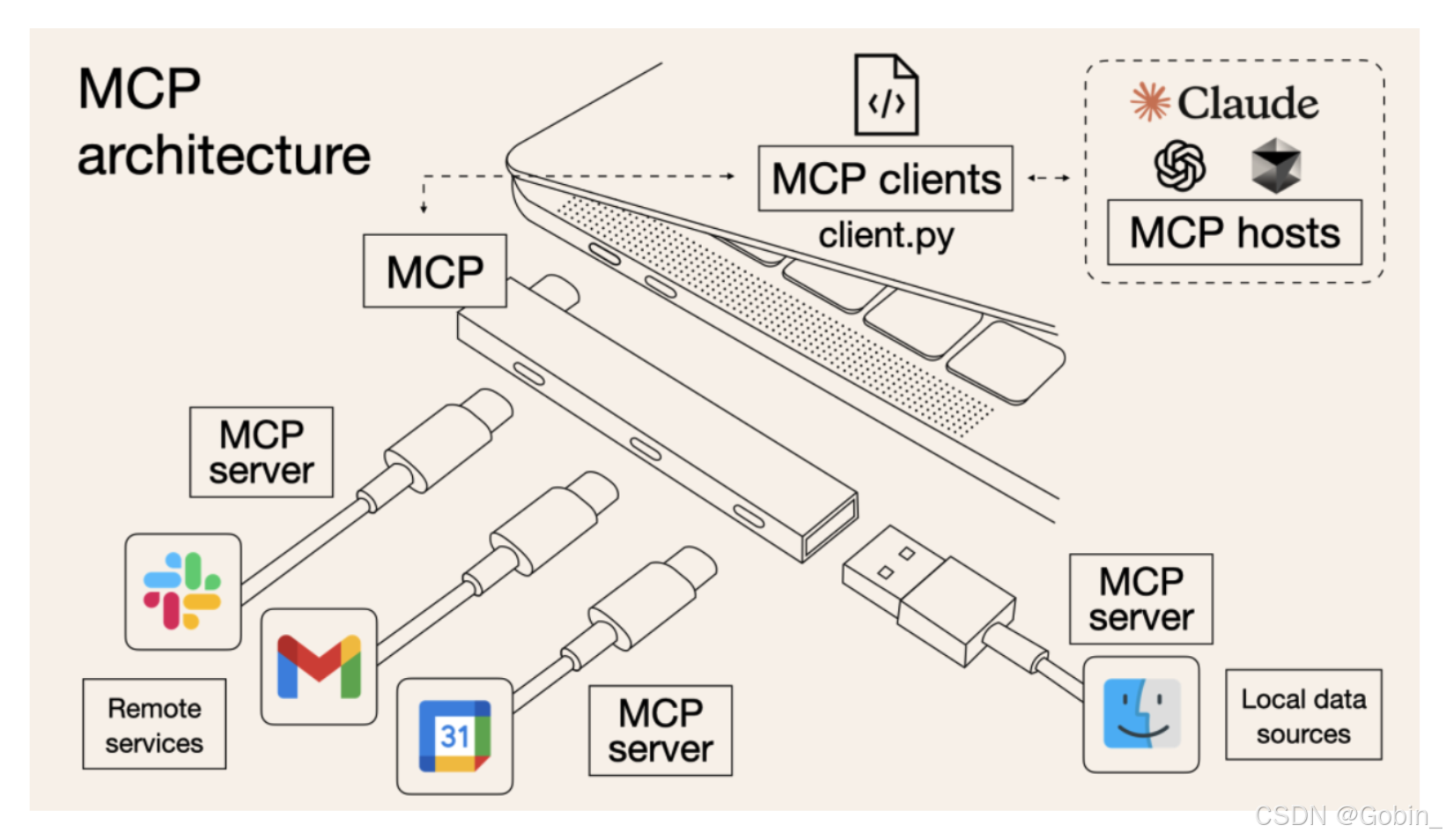
MCP 的优势
在 MCP 出现前,AI 调用工具基本通过 Function Call 完成,存在以下问题:
- 不同的大模型厂商 Function Call 格式不一致
- 大量 API 工具的输入和输出格式不一致,封装管理繁琐
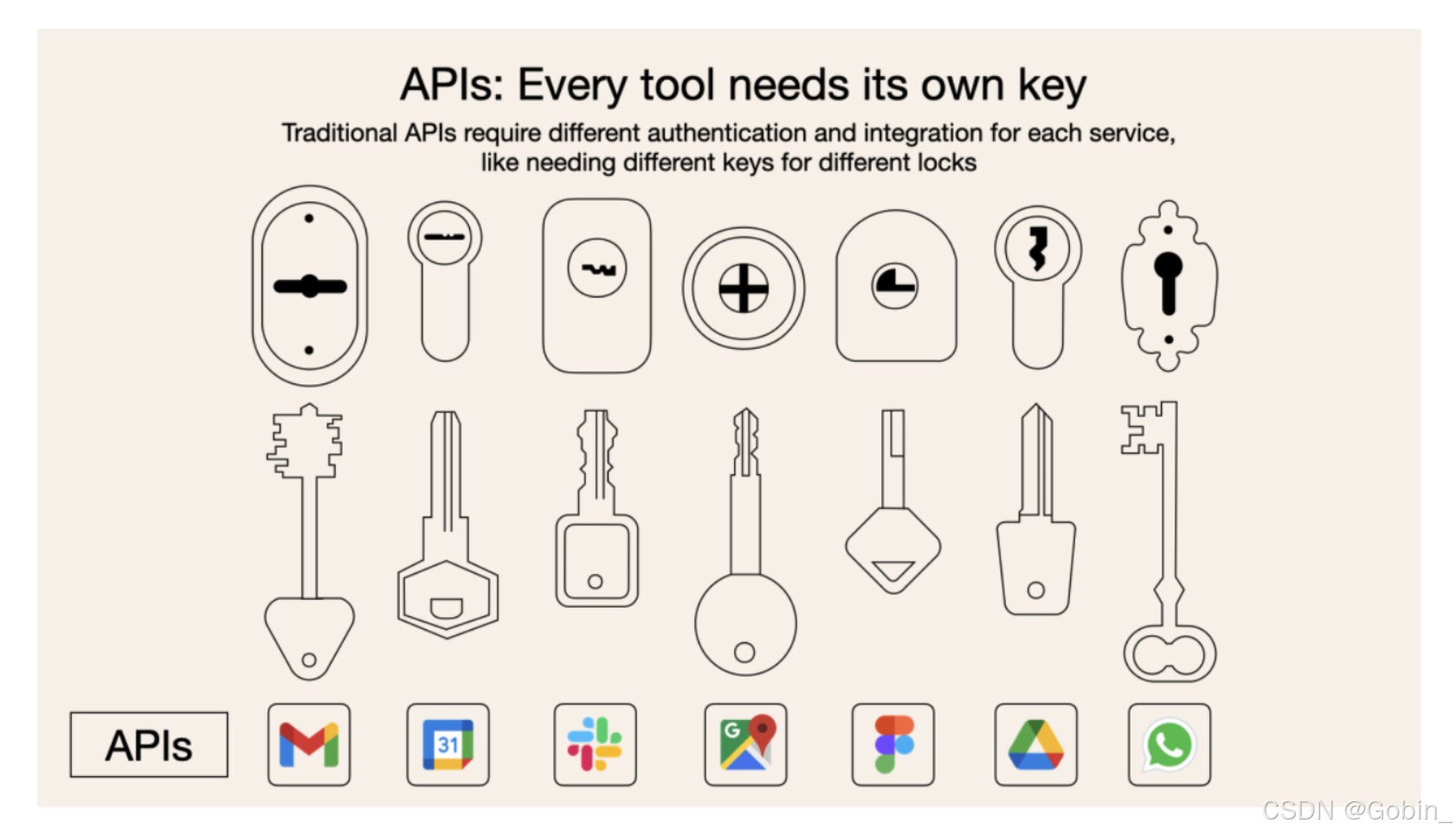
MCP 相当于一个统一的 USB-C,不仅统一了不同大模型厂商的 Function Call 格式,也对相关工具的封装进行了统一。
MCP 传输协议
目前 MCP 支持两种主要的传输协议:
-
Stdio 传输协议
- 针对本地使用
- 需要在用户本地安装命令行工具
- 对运行环境有特定要求
-
SSE(Server-Sent Events)传输协议
- 针对云服务部署
- 基于 HTTP 长连接实现
项目结构
MCP Server
- Stdio 传输协议(本地)
- SSE 传输协议(远程)
MCP Client(客户端)
- 自建客户端(Python)
- Cursor
- Cline
环境配置
1. 安装 UV 包
MacOS/Linux:
curl -LsSf https://astral.sh/uv/install.sh | sh
Windows:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
2. 初始化项目
# 创建项目目录
uv init mcp-server
cd mcp-server
# 创建并激活虚拟环境
uv venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
# 安装依赖
uv add "mcp[cli]" httpx
# 创建服务器实现文件
touch main.py
构建工具函数
为了让大模型能访问市面上主流框架的技术文档,我们主要通过用户输入的 query,结合指定 site 特定域名的谷歌搜索进行搜索相关网页,并对相关网页进行解析提取网页文本并返回。
1. 构建相关文档映射字典
docs_urls = {
"langchain": "python.langchain.com/docs",
"llama-index": "docs.llamaindex.ai/en/stable",
"autogen": "microsoft.github.io/autogen/stable",
"agno": "docs.agno.com",
"openai-agents-sdk": "openai.github.io/openai-agents-python",
"mcp-doc": "modelcontextprotocol.io",
"camel-ai": "docs.camel-ai.org",
"crew-ai": "docs.crewai.com"
}
2. 构建 MCP 工具
import json
import os
import httpx
from bs4 import BeautifulSoup
from mcp import tool
async def search_web(query: str) -> dict | None:
payload = json.dumps({"q": query, "num": 3})
headers = {
"X-API-KEY": os.getenv("SERPER_API_KEY"),
"Content-Type": "application/json",
}
async with httpx.AsyncClient() as client:
try:
response = await client.post(
SERPER_URL, headers=headers, data=payload, timeout=30.0
)
response.raise_for_status()
return response.json()
except httpx.TimeoutException:
return {"organic": []}
async def fetch_url(url: str):
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, timeout=30.0)
soup = BeautifulSoup(response.text, "html.parser")
text = soup.get_text()
return text
except httpx.TimeoutException:
return "Timeout error"
@tool()
async def get_docs(query: str, library: str):
"""
搜索给定查询和库的最新文档。
支持 langchain、llama-index、autogen、agno、openai-agents-sdk、mcp-doc、camel-ai 和 crew-ai。
参数:
query: 要搜索的查询 (例如 "React Agent")
library: 要搜索的库 (例如 "agno")
返回:
文档中的文本
"""
if library not in docs_urls:
raise ValueError(f"Library {library} not supported by this tool")
query = f"site:{docs_urls[library]} {query}"
results = await search_web(query)
if len(results["organic"]) == 0:
return "No results found"
text = ""
for result in results["organic"]:
text += await fetch_url(result["link"])
return text
封装 MCP Server (基于 Stdio 协议)
1. MCP Server (Stdio)
# main.py
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
import httpx
import json
import os
from bs4 import BeautifulSoup
from typing import Any
import httpx
from mcp.server.fastmcp import FastMCP
from starlette.applications import Starlette
from mcp.server.sse import SseServerTransport
from starlette.requests import Request
from starlette.routing import Mount, Route
from mcp.server import Server
import uvicorn
load_dotenv()
mcp = FastMCP("Agentdocs")
USER_AGENT = "Agentdocs-app/1.0"
SERPER_URL = "https://google.serper.dev/search"
docs_urls = {
"langchain": "python.langchain.com/docs",
"llama-index": "docs.llamaindex.ai/en/stable",
"autogen": "microsoft.github.io/autogen/stable",
"agno": "docs.agno.com",
"openai-agents-sdk": "openai.github.io/openai-agents-python",
"mcp-doc": "modelcontextprotocol.io",
"camel-ai": "docs.camel-ai.org",
"crew-ai": "docs.crewai.com"
}
async def search_web(query: str) -> dict | None:
payload = json.dumps({"q": query, "num": 2})
headers = {
"X-API-KEY": os.getenv("SERPER_API_KEY"),
"Content-Type": "application/json",
}
async with httpx.AsyncClient() as client:
try:
response = await client.post(
SERPER_URL, headers=headers, data=payload, timeout=30.0
)
response.raise_for_status()
return response.json()
except httpx.TimeoutException:
return {"organic": []}
async def fetch_url(url: str):
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, timeout=30.0)
soup = BeautifulSoup(response.text, "html.parser")
text = soup.get_text()
return text
except httpx.TimeoutException:
return "Timeout error"
@mcp.tool()
async def get_docs(query: str, library: str):
"""
搜索给定查询和库的最新文档。
支持 langchain、llama-index、autogen、agno、openai-agents-sdk、mcp-doc、camel-ai 和 crew-ai。
参数:
query: 要搜索的查询 (例如 "React Agent")
library: 要搜索的库 (例如 "agno")
返回:
文档中的文本
"""
if library not in docs_urls:
raise ValueError(f"Library {library} not supported by this tool")
query = f"site:{docs_urls[library]} {query}"
results = await search_web(query)
if len(results["organic"]) == 0:
return "No results found"
text = ""
for result in results["organic"]:
text += await fetch_url(result["link"])
return text
if __name__ == "__main__":
mcp.run(transport="stdio")
启动命令:
uv run main.py
2. 客户端配置
2.1 基于 Cline
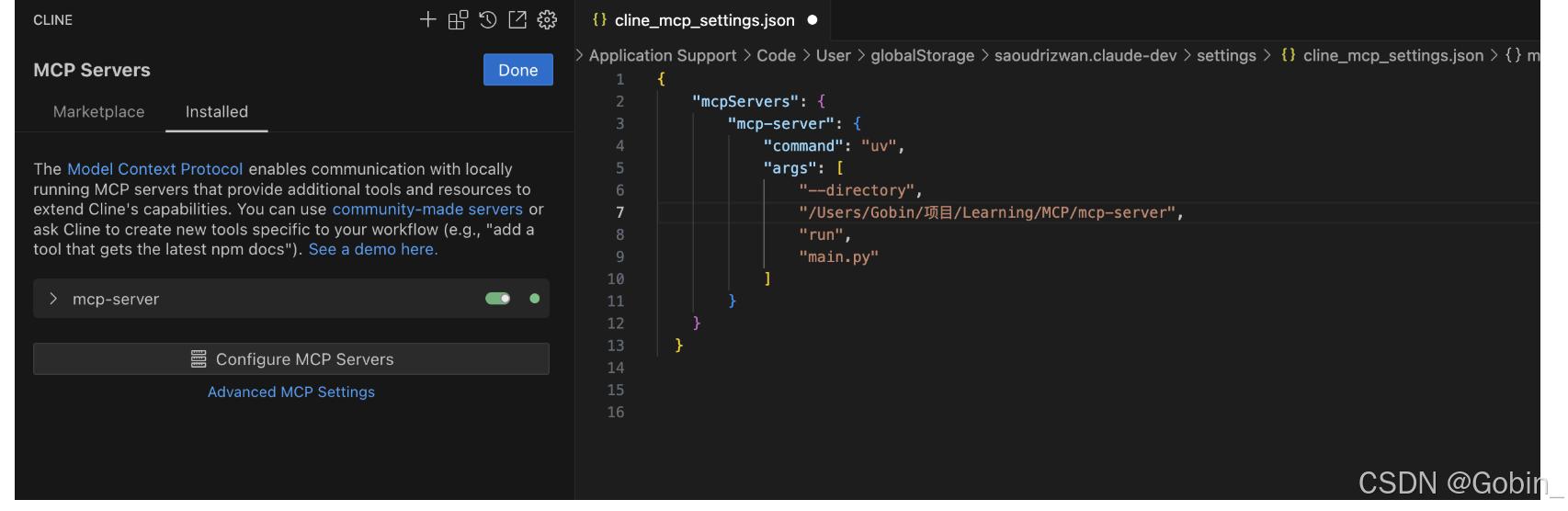
首先在 Visual Studio Code 安装 Cline 插件,然后进行配置 MCP
{
"mcpServers": {
"mcp-server": {
"command": "uv",
"args": [
"--directory",
"<你的项目路径>",
"run",
"main.py"
]
}
}
}
成功绑定如图(左侧绿灯):
2.2 基于 Cursor
项目根目录创建 .cursor 文件夹,并创建 mcp.json 文件,如:
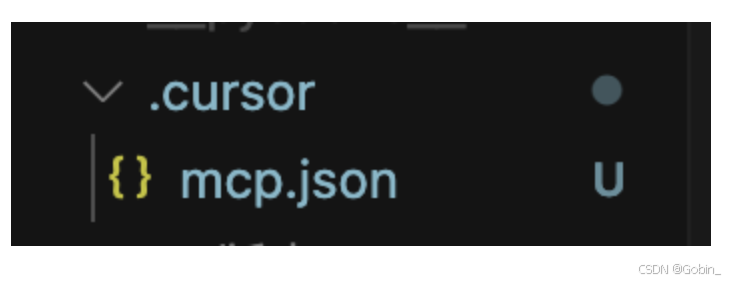
然后粘贴以下内容到 mcp.json
{
"mcpServers": {
"mcp-server": {
"command": "uv",
"args": [
"--directory",
"<你的项目路径>",
"run",
"main.py"
]
}
}
}
成功配置如图:

在 Features 开启 MCP 服务
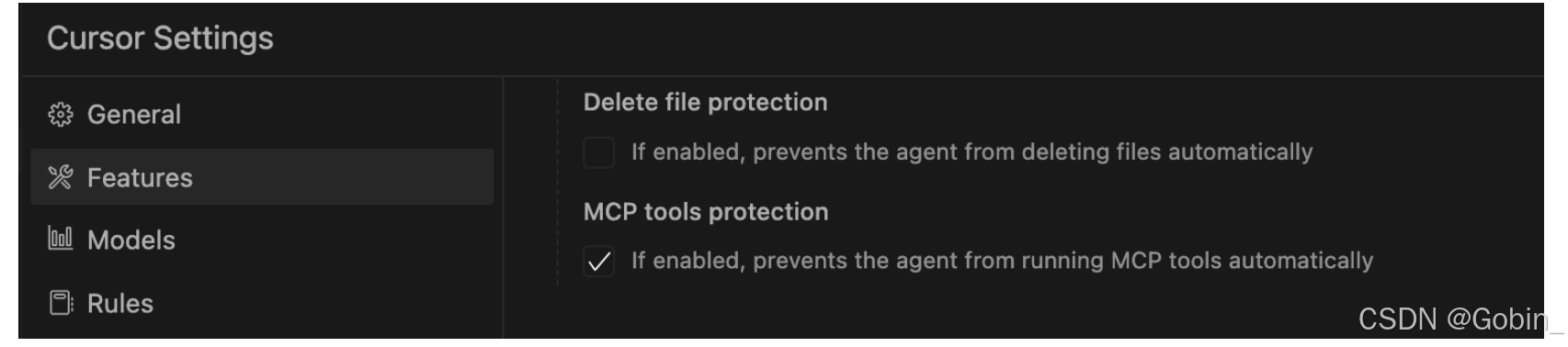
通过对话它便通过 MCP 获取相关文档信息进行回答:
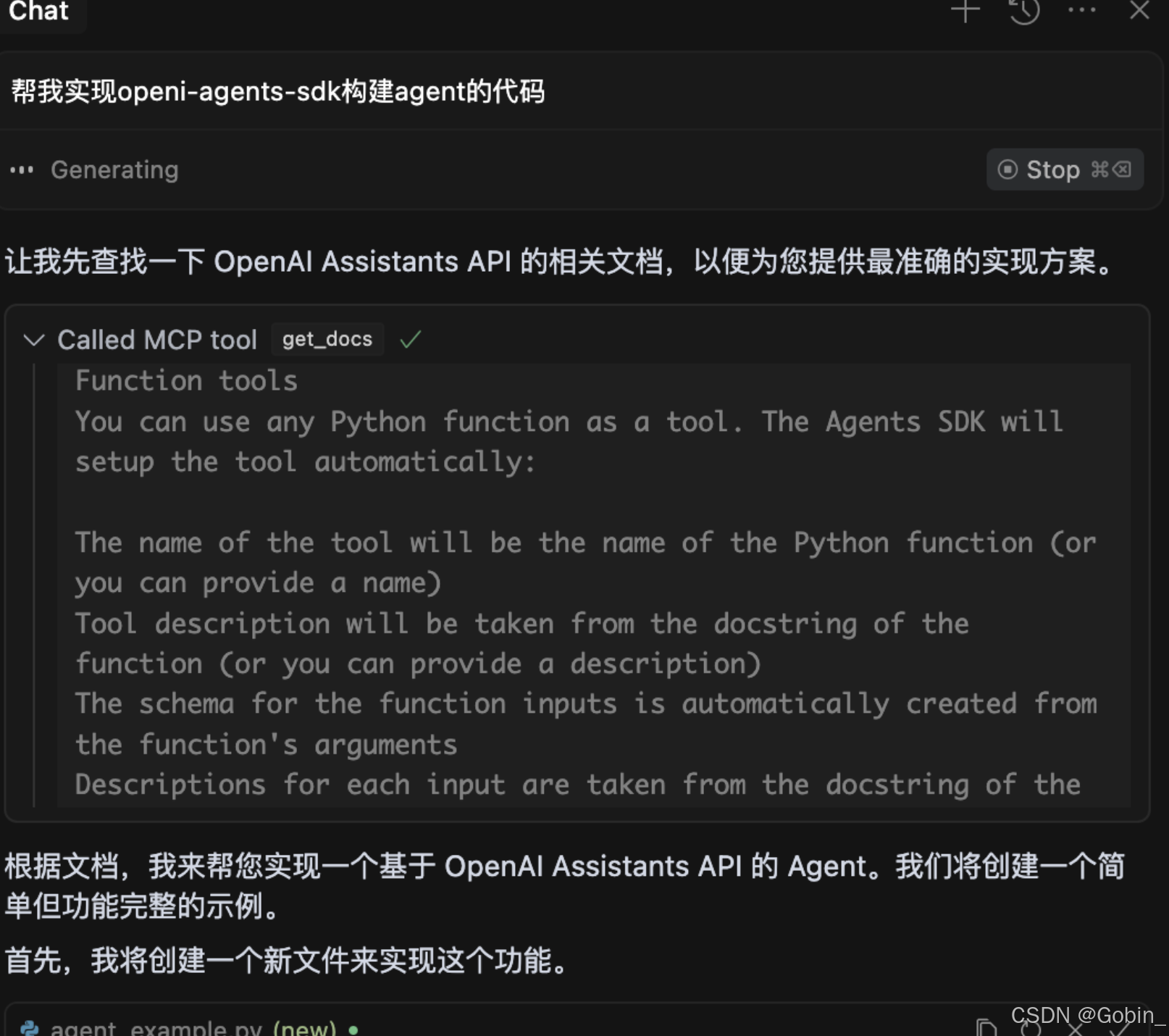
构建 SSE MCP Server (基于 SSE 协议)
1. 封装 MCP Server
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
import httpx
import json
import os
from bs4 import BeautifulSoup
from typing import Any
import httpx
from mcp.server.fastmcp import FastMCP
from starlette.applications import Starlette
from mcp.server.sse import SseServerTransport
from starlette.requests import Request
from starlette.routing import Mount, Route
from mcp.server import Server
import uvicorn
load_dotenv()
mcp = FastMCP("docs")
USER_AGENT = "docs-app/1.0"
SERPER_URL = "https://google.serper.dev/search"
docs_urls = {
"langchain": "python.langchain.com/docs",
"llama-index": "docs.llamaindex.ai/en/stable",
"autogen": "microsoft.github.io/autogen/stable",
"agno": "docs.agno.com",
"openai-agents-sdk": "openai.github.io/openai-agents-python",
"mcp-doc": "modelcontextprotocol.io",
"camel-ai": "docs.camel-ai.org",
"crew-ai": "docs.crewai.com"
}
async def search_web(query: str) -> dict | None:
payload = json.dumps({"q": query, "num": 2})
headers = {
"X-API-KEY": os.getenv("SERPER_API_KEY"),
"Content-Type": "application/json",
}
async with httpx.AsyncClient() as client:
try:
response = await client.post(
SERPER_URL, headers=headers, data=payload, timeout=30.0
)
response.raise_for_status()
return response.json()
except httpx.TimeoutException:
return {"organic": []}
async def fetch_url(url: str):
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, timeout=30.0)
soup = BeautifulSoup(response.text, "html.parser")
text = soup.get_text()
return text
except httpx.TimeoutException:
return "Timeout error"
@mcp.tool()
async def get_docs(query: str, library: str):
"""
搜索给定查询和库的最新文档。
支持 langchain、llama-index、autogen、agno、openai-agents-sdk、mcp-doc、camel-ai 和 crew-ai。
参数:
query: 要搜索的查询 (例如 "React Agent")
library: 要搜索的库 (例如 "agno")
返回:
文档中的文本
"""
if library not in docs_urls:
raise ValueError(f"Library {library} not supported by this tool")
query = f"site:{docs_urls[library]} {query}"
results = await search_web(query)
if len(results["organic"]) == 0:
return "No results found"
text = ""
for result in results["organic"]:
text += await fetch_url(result["link"])
return text
## sse传输
def create_starlette_app(mcp_server: Server, *, debug: bool = False) -> Starlette:
"""Create a Starlette application that can serve the provided mcp server with SSE."""
sse = SseServerTransport("/messages/")
async def handle_sse(request: Request) -> None:
async with sse.connect_sse(
request.scope,
request.receive,
request._send, # noqa: SLF001
) as (read_stream, write_stream):
await mcp_server.run(
read_stream,
write_stream,
mcp_server.create_initialization_options(),
)
return Starlette(
debug=debug,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
)
if __name__ == "__main__":
mcp_server = mcp._mcp_server
import argparse
parser = argparse.ArgumentParser(description='Run MCP SSE-based server')
parser.add_argument('--host', default='0.0.0.0', help='Host to bind to')
parser.add_argument('--port', type=int, default=8020, help='Port to listen on')
args = parser.parse_args()
# Bind SSE request handling to MCP server
starlette_app = create_starlette_app(mcp_server, debug=True)
uvicorn.run(starlette_app, host=args.host, port=args.port)
启动命令:
uv run main.py --host 0.0.0.0 --port 8020
以上 MCP server 代码直接在你的云服务器跑即可。
2. 构建 MCP Client
import asyncio
import json
import os
from typing import Optional
from contextlib import AsyncExitStack
import time
from mcp import ClientSession
from mcp.client.sse import sse_client
from openai import AsyncOpenAI
from dotenv import load_dotenv
load_dotenv() # load environment variables from .env
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.openai = AsyncOpenAI(api_key=os.getenv("OPENAI_API_KEY"), base_url=os.getenv("OPENAI_BASE_URL"))
async def connect_to_sse_server(self, server_url: str):
"""Connect to an MCP server running with SSE transport"""
# Store the context managers so they stay alive
self._streams_context = sse_client(url=server_url)
streams = await self._streams_context.__aenter__()
self._session_context = ClientSession(*streams)
self.session: ClientSession = await self._session_context.__aenter__()
# Initialize
await self.session.initialize()
# List available tools to verify connection
print("Initialized SSE client...")
print("Listing tools...")
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
async def cleanup(self):
"""Properly clean up the session and streams"""
if self._session_context:
await self._session_context.__aexit__(None, None, None)
if self._streams_context:
await self._streams_context.__aexit__(None, None, None)
async def process_query(self, query: str) -> str:
"""Process a query using OpenAI API and available tools"""
messages = [
{
"role": "user",
"content": query
}
]
response = await self.session.list_tools()
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema
}
} for tool in response.tools]
# Initial OpenAI API call
completion = await self.openai.chat.completions.create(
model=os.getenv("OPENAI_MODEL"),
max_tokens=1000,
messages=messages,
tools=available_tools
)
# Process response and handle tool calls
tool_results = []
final_text = []
assistant_message = completion.choices[0].message
if assistant_message.tool_calls:
for tool_call in assistant_message.tool_calls:
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# Execute tool call
result = await self.session.call_tool(tool_name, tool_args)
tool_results.append({"call": tool_name, "result": result})
final_text.append(f"[Calling tool {tool_name} with args {tool_args}]")
# Continue conversation with tool results
messages.extend([
{
"role": "assistant",
"content": None,
"tool_calls": [tool_call]
},
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": result.content[0].text
}
])
print(f"Tool {tool_name} returned: {result.content[0].text}")
print("messages", messages)
# Get next response from OpenAI
completion = await self.openai.chat.completions.create(
model=os.getenv("OPENAI_MODEL"),
max_tokens=1000,
messages=messages,
)
if isinstance(completion.choices[0].message.content, (dict, list)):
final_text.append(str(completion.choices[0].message.content))
else:
final_text.append(completion.choices[0].message.content)
else:
if isinstance(assistant_message.content, (dict, list)):
final_text.append(str(assistant_message.content))
else:
final_text.append(assistant_message.content)
return "\n".join(final_text)
async def chat_loop(self):
"""Run an interactive chat loop"""
print("\nMCP Client Started!")
print("Type your queries or 'quit' to exit.")
while True:
try:
query = input("\nQuery: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query)
print("\n" + response)
except Exception as e:
print(f"\nError: {str(e)}")
async def main():
if len(sys.argv) < 2:
print("Usage: uv run client.py <URL of SSE MCP server (i.e. http://localhost:8080/sse)>")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_sse_server(server_url=sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
import sys
asyncio.run(main())
启动命令:
uv run client.py http://0.0.0.0:8020/sse
Client 日志:
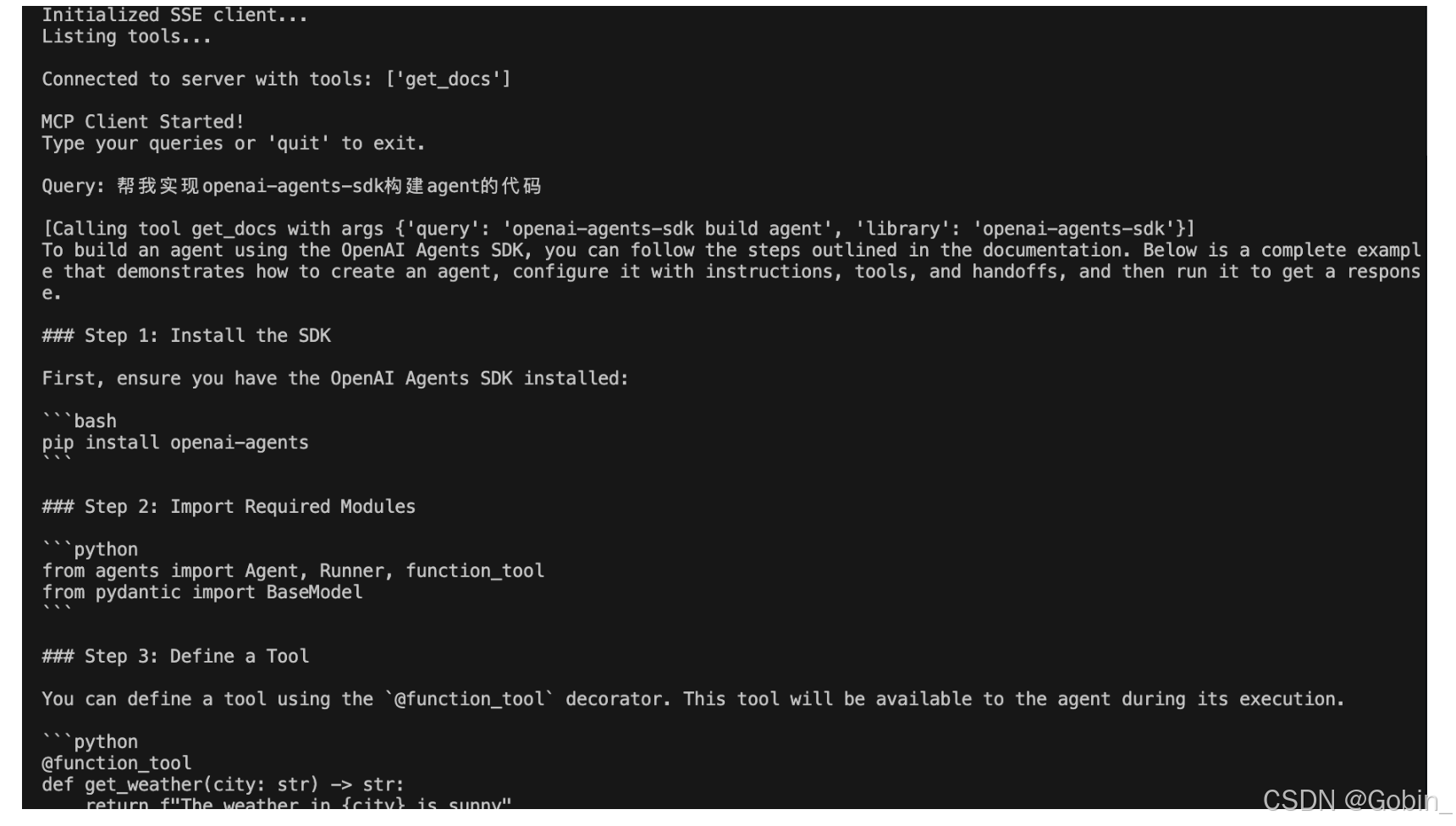
Server 日志:
以上便是 Python 从 0 到 1 搭建 MCP Server 以及 MCP Client 的完整教程。有不对的地方请多多指教。
完整代码:https://github.com/GobinFan/python-mcp-server-client
参考相关资料:
- https://www.youtube.com/watch?v=Ek8JHgZtmcI
- https://serper.dev/
- https://modelcontextprotocol.io/quickstart/server
- https://modelcontextprotocol.io/quickstart/client
- https://docs.cursor.com/context/model-context-protocol

















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









