






1、rk3588启用NPU
启用三个内核->RKNNLite.NPU_CORE_0_1_2
rknn_lite = RKNNLite(verbose=False)
ret = rknn_lite.load_rknn(RKNN_MODEL)
ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1_2)2、查看NPU使用情况:
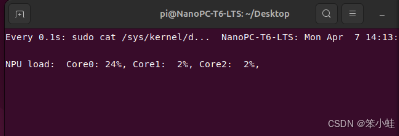
watch sudo cat /sys/kernel/debug/rknpu/load该命令将每两秒运行一次(默认),使用情况如下:
 若需要查看当前npu使用情况,去掉watch!
若需要查看当前npu使用情况,去掉watch!
每0.1秒运行一次:watch -n 0.01 sudo cat /sys/kernel/debug/rknpu/load



















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











