






5月9日,在北京阿里云AI智领者峰会上,阿里云CTO周靖人公布百炼大模型平台最新进展。百炼平台从模型开发、应用开发到算力底座全面升级,更加易用、更加开放,引入更多模型,还率先兼容LlamaIndex等开源框架,企业可自由替换能力组件来适配自身系统。针对当下企业最关注的RAG链路,百炼提供灵活开放的企业级检索增强服务,5到10行代码即可搭建RAG应用,让大模型拥有“最强外挂”。

2023年10月,阿里云发布了百炼大模型平台,开发者可通过“拖拉拽”5分钟开发一款大模型应用,几小时“炼”出一个专属模型,把精力专注于应用创新。本次大会上,百炼升级成为阿里云承载云+AI能力的重要平台,提供一站式、全托管的大模型定制与应用服务。升级后,百炼可以更好支持地大型企业和成熟开发者的需求。
“当下企业应用大模型存在三种范式:一是对大模型开箱即用,二是对大模型进行微调和持续训练,三是基于模型开发应用,其中最典型的需求是RAG,以企业数据对大模型进行知识增强。围绕这些需求,百炼打造了模型中心和应用中心,提供最丰富的模型和最易用的工具箱。”周靖人介绍。

对希望直接调用模型进行推理的企业,百炼集成了上百款大模型api,除了通义、Llama、ChatGLM等系列,还首家托管百川等系列三方模型,覆盖国内外主流厂商,联动魔搭开源社区,同时支持企业上架通用或行业模型,给开发者提供足够多的模型选择。同时,百炼依托阿里云AI基础设施,支持千亿级模型的万级并发推理,充分满足企业需求。
对需进一步训练模型的用户,百炼提供从数据管理、模型调优、评测到部署的全链路模型服务,用户可弹性按需调用算力,无需关心底层架构。训练过程可视化,还可自动评测模型质量,并与其他模型对比。
对希望打造RAG应用的企业,百炼支持Assistant API开发模式,可在百炼上轻松创建知识库,并一键开启知识检索增强(RAG),通过Assistant API联合输出。同时,百炼支持agent智能体开发,并能实现多智能体协作、对话记忆等高级功能。
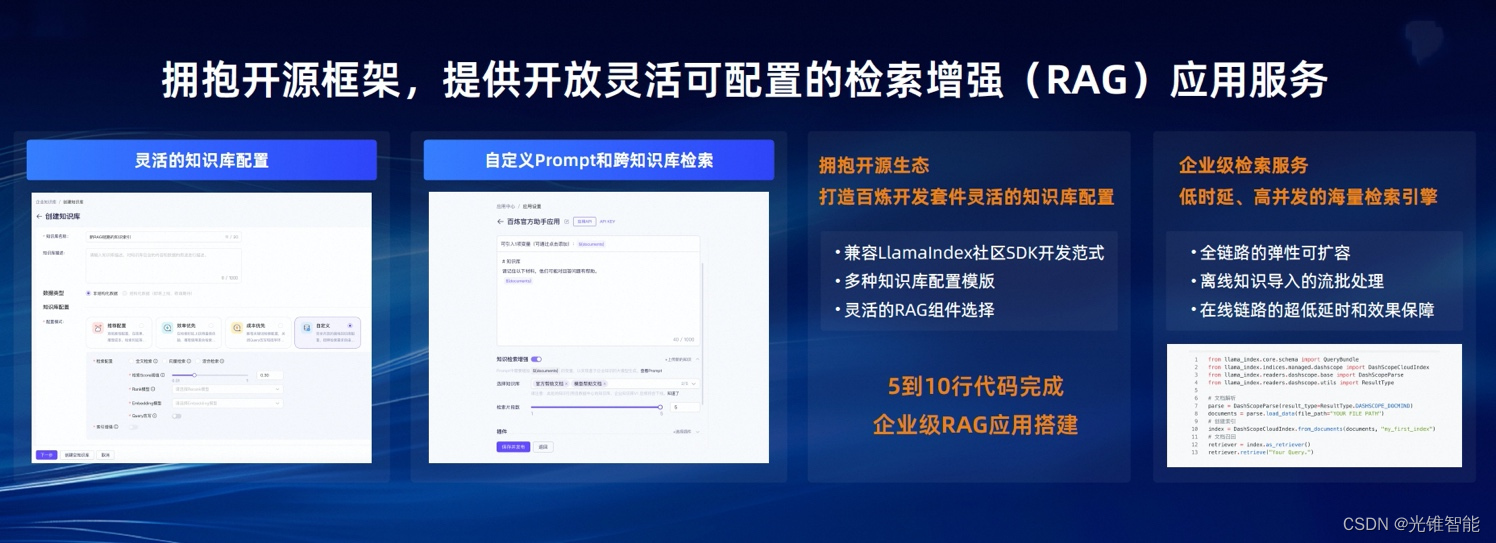
阿里云百炼的一大重要优势,在于最大程度的开放性和自由度。当下一些大模型应用平台采用封闭链路,不支持替换原子能力,导致企业开发应用时无法引入自研插件,和业务场景充分融合。
百炼率先兼容并优化了LlamaIndex等开源架构,拥抱社区生态,支持从本地或不同云端导入SQL、pdf、excel、ppt等各种类型数据源,还支持根据需求自由替换精细的能力组件,让AI应用丝滑嵌入企业原有业务系统。
周靖人表示,接下来,百炼将继续做对开发者最友好、最开放的大模型平台。阿里云欢迎更多大模型上架,百炼将进一步支持三方模型的微调训练和云上专属部署,帮助大模型生态中的企业提供商业化服务。
据了解,阿里云百炼发布半年来,已服务一汽、微博、完美世界、朗新集团、央视网、蓝凌科技等众多企业。例如,一汽红旗在百炼上调用通义千问和大模型分析能力打造了专属BI智能体,管理人员可随时让大模型生成销售额图表,并分析相关情况。

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









