







引言
常见的五种神经网络系列第三篇,主要介绍深度信念网络。内容分为上下两篇进行介绍,本文主要是深度信念网络(上)篇,主要介绍以下内容:
- 背景
- 玻尔兹曼机
- 受限玻尔兹曼机
该系列的其他文章:
- 常见的五种神经网络(1)-前馈神经网络
- 常见的五种神经网络(2)-卷积神经网络
- 常见的五种神经网络(3)-循环神经网络(上篇)
- 常见的五种神经网络(3)-循环神经网络(中篇)
- 常见的五种神经网络(3)-循环神经网络(下篇)
- 常见的五种神经网络(4)-深度信念网络(上篇)
- 常见的五种神经网络(4)-深度信念网络(下篇)
- 常见的五种神经网络(5)-生成对抗网络
背景
对于一个复杂的数据分布,我们往往只能观测到有限的局部特征,并且这些特征通常会包含一定的噪声。如果要对这个数据分布进行建模,就需要挖掘出可观测变量之间复杂的依赖关系,以及可观测变量背后隐藏的内部表示。
而深度信念网络可以有效的学习变量之间复杂的依赖关系。深度信念网络中包含很多层的隐变量,可以有效的学习数据的内部特征表示,也可以作为一种有效的非线性降维方法,这些学习到的内部特征表示包含了数据的更高级的、有价值的信息,因此十分有助于后续的分类和回归等任务。
玻尔兹曼机是生成模型的一种基础模型,和深度信念网络的共同问题是推断和学习,因为这两种模型都比较复杂,并且都包含隐变量,他们的推断和学习一般通过MCMC方法来进行近似估计。这两种模型和神经网络有很强的对应关系,在一定程度上也称为随机神经网络(Stochastic Neural Network,SNN)。
因为深度信念网络是有多层玻尔兹曼机组成的,所以本篇文章我们先来了解一下玻尔兹曼机和受限玻尔兹曼机。
玻尔兹曼机
介绍
玻尔兹曼机(Boltzmann Machine)可以看作是一种随机动力系统,每个变量的状态都以一定的概率受到其他变量的影响。玻尔兹曼机可以用概率无向图模型来描述,如下所示:
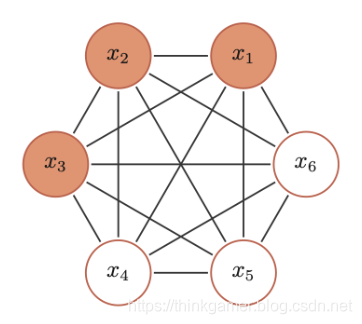
BM的三个性质:
- 二值输出:每个随机变量可以用一个二值的随机变量表示
- 全连接:所有节点之间是全连接的
- 权重对称:每两个变量之间的相互影响是对称的
BM中的每个变量
X
X
X的联合概率由玻尔兹曼分布得到,即:
p
(
x
)
=
1
Z
e
x
p
(
−
E
(
x
)
T
)
p(x) = \frac{1}{Z} exp(\frac{-E(x)}{T})
p(x)=Z1exp(T−E(x))
其中
Z
Z
Z为配分函数,能量函数
E
(
X
)
E(X)
E(X)的定义为:
E
(
x
)
=
△
E
(
X
=
x
)
=
−
(
∑
i
<
j
w
i
j
x
i
x
j
+
∑
i
b
i
x
i
)
E(x) \overset{\bigtriangleup }{=} E(X=x) = -( \sum_{i<j } w_{ij}x_ix_j + \sum_{i} b_i x_i )
E(x)=△E(X=x)=−(i<j∑wijxixj+i∑bixi)
其中 w i j w_{ij} wij是两个变量之间的连接权重, x i ∈ { 0 , 1 } x_i \in \{0,1\} xi∈{0,1}表示状态, b i b_i bi是变量 x i x_i xi的偏置。
玻尔兹曼机可以用来解决两类问题,一是搜索问题,当给定变量之间的连接权重,需要找到一组二值变量,使得整个网络的能量最低。另一类是学习问题,当给定一部分变量的观测值时,计算一组最优的权重。
生成模型
在玻尔兹曼机中配分函数 Z Z Z通常难以计算,因此联合概率分布 p ( x ) p(x) p(x)一般通过MCMC(马尔科夫链蒙特卡罗,Markov Chain Monte Carlo)方法来近似,生成一组服从 p ( x ) p(x) p(x)分布的样本。这里介绍基于吉布斯采样的样本生成方法。
1. 全条件概率
吉布斯采样需要计算每个变量
X
i
X_i
Xi的全条件概率
p
(
x
i
∣
x
∖
i
)
p(x_i|x_{\setminus i})
p(xi∣x∖i),其中
x
∖
i
x_{\setminus i}
x∖i表示除了
X
i
X_i
Xi外其它变量的取值。
对于玻尔兹曼机中的一个变量
X
i
X_i
Xi,当给定其他变量
x
∖
i
x_{\setminus i}
x∖i时,全条件概率公式
p
(
x
i
∣
x
∖
i
)
p(x_i|x_{\setminus i})
p(xi∣x∖i)为:
p
(
x
i
=
1
∣
x
∖
i
)
=
σ
(
∑
j
w
i
j
x
j
+
b
i
T
)
p
(
x
i
=
0
∣
x
∖
i
)
=
1
−
p
(
x
i
=
1
∣
x
∖
i
)
p(x_i=1|x_{\setminus i}) = \sigma( \frac{ \sum_{j} w_{ij}x_j +b_i }{T} ) \\ p(x_i=0|x_{\setminus i}) = 1- p(x_i=1|x_{\setminus i})
p(xi=1∣x∖i)=σ(T∑jwijxj+bi)p(xi=0∣x∖i)=1−p(xi=1∣x∖i)
其中
σ
(
.
)
\sigma(.)
σ(.)为sigmoid函数。
2. 吉布斯采样
玻尔兹曼机的吉布斯采样过程为:随机选择一个变量 X i X_i Xi,然后根据其全条件概率 p ( x i ∣ x ∖ i ) p(x_i|x_{\setminus i}) p(xi∣x∖i)来设置其状态,即以 p ( x i = 1 ∣ x ∖ i ) p(x_i=1|x_{\setminus i}) p(xi=1∣x∖i)的概率将变量 X i X_i Xi设为1,否则全为0。在固定温度 T T T的情况下,在运动不够时间之后,玻尔兹曼机会达到热平衡。此时,任何全局状态的概率服从玻尔兹曼分布 p ( x ) p(x) p(x),只与系统的能量有关,与初始状态无关。
要使得玻尔兹曼机达到热平衡,其收敛速度和温度
T
T
T相关。当系统温度非常高
T
→
∞
T \rightarrow \infty
T→∞时,
p
(
x
i
∣
x
∖
i
)
→
0.5
p(x_i|x_{\setminus i}) \rightarrow 0.5
p(xi∣x∖i)→0.5,即每个变量状态的改变十分容易,每一种系统状态都是一样的,从而很快可以达到热平衡。当系统温度非常低
T
→
0
T \rightarrow 0
T→0时,如果
Δ
E
i
(
x
∖
i
)
>
0
\Delta E_i(x_{ \setminus i}) > 0
ΔEi(x∖i)>0,则
p
(
x
i
∣
x
∖
i
)
→
1
p(x_i|x_{\setminus i}) \rightarrow 1
p(xi∣x∖i)→1,如果
Δ
E
i
(
x
∖
i
)
<
0
\Delta E_i(x_{ \setminus i}) < 0
ΔEi(x∖i)<0,则
p
(
x
i
∣
x
∖
i
)
→
0
p(x_i|x_{\setminus i}) \rightarrow 0
p(xi∣x∖i)→0,即:
x
i
=
{
1
i
f
∑
j
w
i
j
x
j
+
b
i
≥
0
0
o
t
h
e
r
w
i
s
e
x_i = \left\{\begin{matrix} 1 & if \sum_{j}w_{ij}x_j + b_i \geq 0\\ 0 & otherwise \end{matrix}\right.
xi={10if∑jwijxj+bi≥0otherwise
因此,当$ \rightarrow 0$时,随机性方法变成了确定性方法,这时,玻尔兹曼机退化为一个Hopfield网络。Hopfield网络是一种确定性的动力系统,每次的状态更新都会使系统的能量降低;而玻尔兹曼机时一种随机性动力系统,每次的状态更新则以一定的概率使得系统的能力上升。
3. 能量最小化与模拟退火
要使得动力系统达到热平衡,温度 T T T的选择十分关键。一个比较好的折中方法是让系统刚开始在一个比较高的温度下运行达到热平衡,然后逐渐降低直到系统在一个比较低的温度下达到热平衡。这样我们就能够得到一个能量全局最小的分布。这个过程被称为模拟退火(Simulated Annealing)。
模拟退火是一种寻找全局最优的近似方法。
受限玻尔兹曼机
介绍
全连接的玻尔兹曼机十分复杂,虽然基于采样的方法提高了学习效率,但在权重更新的过程中仍十分低效。在实际应用中,使用比较广泛的一种带限制的版本,即受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是一个二分图结构的无向图模型,如下所示。
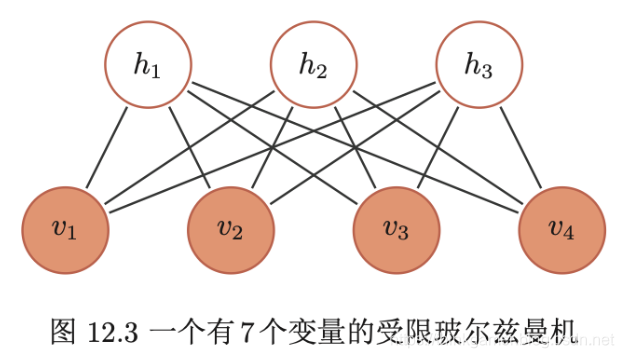
首先玻尔兹曼机中的变量也分为隐藏变量和可观测变量。分别用可观测层和隐藏层来表示这两组变量。同一层中的节点之间没有连接,而不同层一个层中的节点与另一层中的所有节点连接,这和两层的全连接神经网络结构相同。
一个受限玻尔兹曼机由 m 1 m_1 m1个可观测变量和 m 2 m_2 m2个隐变量组成,其定义如下:
- 可观测的随机向量 v = [ v 1 , . . . , v m 1 ] T v=[v_1, ..., v_{m_1}]^T v=[v1,...,vm1]T
- 隐藏的随机向量 h = [ h 1 , . . . , h m 2 ] T h=[h_1, ... , h_{m_2}]^T h=[h1,...,hm2]T
- 权重矩阵 W ∈ R m 1 ∗ m 2 W \in R^{m_1 * m_2} W∈Rm1∗m2,其中每个元素 w i j w_{ij} wij为可观测变量 v i v_i vi和隐变量 h j h_j hj之间边的权重
- 偏置 a ∈ R m 1 a \in R^{m_1} a∈Rm1和 b ∈ R m 2 b \in R^{m_2} b∈Rm2,其中 a i a_i ai为每个可观测变量 v i v_i vi得偏置, b j b_j bj为每个隐变量 h j h_j hj得偏置
受限玻尔兹曼机得能量函数定义为:
E
(
v
,
h
)
=
−
∑
i
a
i
v
i
−
∑
j
b
j
h
j
−
∑
i
∑
j
v
i
w
i
j
h
j
=
−
a
T
v
−
b
T
h
−
v
T
W
h
E(v,h) = - \sum_{i} a_iv_i - \sum_{j}b_j h_j - \sum_{i}\sum_{j}v_i w_{ij}h_j = -a^Tv -b^Th - v^T W h
E(v,h)=−i∑aivi−j∑bjhj−i∑j∑viwijhj=−aTv−bTh−vTWh
受限玻尔兹曼机得联合概率分布为
p
(
v
,
h
)
p(v,h)
p(v,h)定义为:
p
(
v
,
h
)
=
1
Z
e
x
p
(
−
E
(
v
,
h
)
)
=
1
Z
e
x
p
(
a
T
v
)
e
x
p
(
b
T
h
)
e
x
p
(
v
T
W
h
)
p(v,h) = \frac{1}{Z} exp(-E(v,h)) = \frac{1}{Z} exp(a^Tv)exp(b^Th)exp(v^TWh)
p(v,h)=Z1exp(−E(v,h))=Z1exp(aTv)exp(bTh)exp(vTWh)
其中
Z
=
∑
v
,
h
e
x
p
(
−
E
(
v
,
h
)
)
Z=\sum_{v,h}exp(-E(v,h))
Z=∑v,hexp(−E(v,h))为配分函数。
生成模型
受限玻尔兹曼机得联合概率分布p(v,h)一般也通过吉布斯采样的方法来近似,生成一组服从 p ( v , h ) p(v,h) p(v,h)分布的样本。
1. 全条件概率
吉布斯采样需要计算每个变量
V
i
V_i
Vi和
H
j
H_j
Hj的全条件概率。受限玻尔兹曼机中的同层的变量之间没有连接。从无向图的性质可知,在给定可观测变量时,隐变量之间相互条件独立,同样在给定隐变量时,可观测变量之间也相互条件独立,即有:
p
(
v
i
∣
v
∖
i
,
h
)
=
p
(
v
i
∣
h
)
p
(
h
j
∣
v
,
h
∖
j
)
=
p
(
h
j
∣
v
)
p(v_i | v_{\setminus i},h) = p(v_i|h) \\ p(h_j | v,h_{\setminus j}) = p(h_j|v)
p(vi∣v∖i,h)=p(vi∣h)p(hj∣v,h∖j)=p(hj∣v)
其中
v
∖
i
v_{\setminus i}
v∖i表示除变量
V
i
V_i
Vi外其他可观测变量得取值,
h
∖
j
h_{\setminus j}
h∖j为除变量
H
j
H_j
Hj外其它隐变量的取值。因此,
V
i
V_i
Vi的全条件概率只需要计算
p
(
v
i
∣
h
)
p(v_i|h)
p(vi∣h),而
H
j
H_j
Hj的全条件概率只需要计算
p
(
h
j
∣
v
)
p(h_j|v)
p(hj∣v)
在受限玻尔兹曼机中,每个可观测变量和隐变量的条件概率为:
p
(
v
i
=
1
∣
h
)
=
σ
(
a
i
+
∑
j
w
i
j
h
j
)
p
(
h
j
=
1
∣
v
)
=
σ
(
b
j
+
∑
i
w
i
j
v
i
)
p(v_i=1|h) = \sigma (a_i + \sum_{j}w_{ij} h_j) \\ p(h_j=1|v) = \sigma (b_j + \sum_{i}w_{ij} v_i)
p(vi=1∣h)=σ(ai+j∑wijhj)p(hj=1∣v)=σ(bj+i∑wijvi)
其中 σ \sigma σ为sigmoid函数。
2. RBM中得吉布斯采样
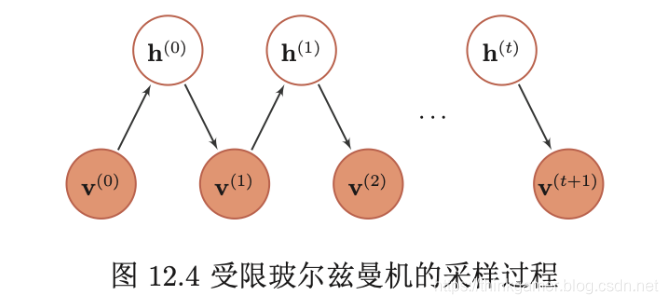
受限玻尔兹曼机得采样过程如下:
- (给定)或随机初始化一个可观测的向量 v 0 v_0 v0,计算隐变量得概率,并从中采样一个隐向量 h 0 h_0 h0
- 基于 h 0 h_0 h0,计算可观测变量得概率,并从中采样一个个可观测的向量 v 1 v_1 v1
- 重复 t t t次后,获得 ( v t , h t ) (v_t, h_t) (vt,ht)
- 当 t → ∞ t \rightarrow \infty t→∞时, ( v t , h t ) (v_t,h_t) (vt,ht)的采样服从 p ( v , h ) p(v,h) p(v,h)分布
下图为上述采样过程的示例:
3. 对比散度学习算法
由于首先玻尔兹曼机得特殊结构,因此可以使用一种比吉布斯采样更高效的学习算法,即对比散度(Contrastive Divergence)。对比散度算法仅需k步吉布斯采样。
为了提高效率,对比散度算法用一个训练样本作为可观测向量的初始值,然后交替对可观测向量和隐藏向量进行吉布斯采用,不需要等到收敛,只需要k步就行了。这就是CD-k算法,通常,k=1就可以学得很好。对比散度得流程如下所示:

4. 受限玻尔兹曼机得类型
在具体的不同任务中,需要处理得数据类型不一定是二值得,也可能时连续值,为了能够处理这些数据,就需要根据输入或输出得数据类型来设计新的能量函数。一般来说受限玻尔兹曼机有以下三种:
- “伯努利-伯努利”受限玻尔兹曼机:即上面介绍得可观测变量喝隐变量都为二值类型得受限玻尔兹曼机
- “高斯-伯努利”受限玻尔兹曼机:假设可观测变量为高斯分布,隐变量为伯努利分布,其能量函数定义为:
E ( v , h ) = ∑ i ( v i − μ i ) 2 2 σ i 2 − ∑ j b j h j − ∑ i ∑ j v i σ i w i j h j E(v,h) = \sum_{i} \frac{(v_i - \mu_i)^2}{2 \sigma_i^2} - \sum{j} b_jh_j - \sum_{i}\sum{j} \frac{v_i}{\sigma_i}w_ijh_j E(v,h)=i∑2σi2(vi−μi)2−∑jbjhj−i∑∑jσiviwijhj
其中每个可观测变量 v i v_i vi服从 ( μ i , σ i ) (\mu_i, \sigma_i) (μi,σi)的高斯分布。 - “伯努利-高斯”受限玻尔兹曼机:假设可观测变量为伯努利分布,隐变量为高斯分布,其能量函数定义为:
E ( v , h ) = ∑ i a i v j − ∑ j ( h j − u j ) 2 2 σ j 2 − ∑ i ∑ j v i w i j h j σ j E(v,h)=\sum_{i}a_i v_j - \sum_{j} \frac{(h_j-u_j)^2}{2\sigma_j^2} - \sum_{i}\sum_{j}v_iw_{ij}\frac{h_j}{\sigma_j} E(v,h)=i∑aivj−j∑2σj2(hj−uj)2−i∑j∑viwijσjhj
其中每个隐变量 h j h_j hj服从 ( μ j , σ j ) (\mu_j, \sigma_j) (μj,σj)的高斯分布















 1903
1903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









