







 本文深入探讨显卡控制机制,包括显卡驱动如何通过端口及内存映射与显卡交互,DirectX等API如何找到并利用显卡驱动,以及显卡内部组件如流处理器的作用。
本文深入探讨显卡控制机制,包括显卡驱动如何通过端口及内存映射与显卡交互,DirectX等API如何找到并利用显卡驱动,以及显卡内部组件如流处理器的作用。
1. 显卡驱动是怎么控制显卡的, 就是说, 使用那些指令控制显卡, 通过端口么?
2. DirectX 或 OpenGL 或 CUDA 或 OpenCL 怎么找到显卡驱动, 显卡驱动是不是要为他们提供接口的实现, 如果是, 那么DirectX和OpenGL和CUDA和OpenCL需要显卡驱动提供的接口都是什么, 这个文档在哪能下载到? 如果不是, 那么DirectX, OpenGL, CL, CUDA是怎么控制显卡的?
3. 显卡中的流处理器具体是做什么的, 是执行某些特殊运算么, 还是按某些顺序执行一组运算, 具体是什么, 光栅单元呢, 纹理单元呢?
4. 显卡 ( 或其他设备 ) 可以访问内存么? 内存地址映射的原理是什么, 为什么 B8000H 到 C7FFFH 是显存的地址, 向这个地址空间写入数据后, 是直接通过总线写入显存了么, 还是依然写在内存中, 显卡到内存中读取, 如果直接写到显存了, 会出现延时和等待么?
2. DirectX 或 OpenGL 或 CUDA 或 OpenCL 怎么找到显卡驱动, 显卡驱动是不是要为他们提供接口的实现, 如果是, 那么DirectX和OpenGL和CUDA和OpenCL需要显卡驱动提供的接口都是什么, 这个文档在哪能下载到? 如果不是, 那么DirectX, OpenGL, CL, CUDA是怎么控制显卡的?
3. 显卡中的流处理器具体是做什么的, 是执行某些特殊运算么, 还是按某些顺序执行一组运算, 具体是什么, 光栅单元呢, 纹理单元呢?
4. 显卡 ( 或其他设备 ) 可以访问内存么? 内存地址映射的原理是什么, 为什么 B8000H 到 C7FFFH 是显存的地址, 向这个地址空间写入数据后, 是直接通过总线写入显存了么, 还是依然写在内存中, 显卡到内存中读取, 如果直接写到显存了, 会出现延时和等待么?
5. 以上这些知识从哪些书籍上可以获得?
楼上说了很多了,补充点具体的,以前 DOS下做游戏,操作系统除了磁盘和文件管理外基本不管事情,所有游戏都是直接操作显卡和声卡的,用不了什么驱动。
虽然没有驱动,但是硬件标准还是放在那里,VGA, SVGA, VESA, VESA2.0 之类的硬件标准,最起码,你只做320x200x256c的游戏,或者 ModeX 下 320x240x256c 的游戏的话,需要用到VGA和部分 SVGA标准,而要做真彩高彩,更高分辨率的游戏的话,就必须掌握 VESA的各项规范了。
翻几段以前写的代码演示下:
例子1: 初始化 VGA/VESA 显示模式
基本是参考 VGA的编程手册来做:
转换成代码的话,类似这样:
基本就是通过中断指令,调用 INT 0x10的 0x00 方法,初始化VGA显示模式,如果模式号大于256,那么说明是一个 VESA显示模式,调用 VESA的中断函数来进行。
例子2: 画点
如果你初始化成功了 320 x 200 x 256 c 模式(INT 0x10, AX=0x13),那么画点就是象显存地址 0xA00000L 里面写一个字节(8位色彩深度):
首先我们使用 DOSBOX (DOS开发调试神器)来调试我们的代码,启动 DOSBOX以后,运行
然后写两条进入图形模式的指令:
输入空行后退出编辑模式,然后使用 'g' 命令运行刚才的这个小程序:
可以看到,显示模式初始化成功了,现在你已经进入了 320x200x256c的显示模式,大量的 DOS游戏是使用这个模式开发出来的(仙剑奇侠传,轩辕剑1/2,C&C)。
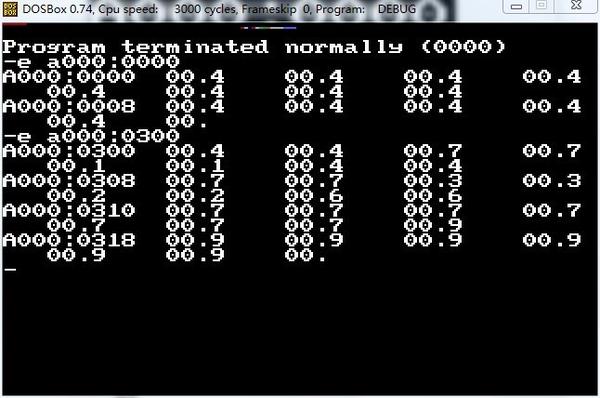
接下来我们编辑显存,使用 e命令,进行写显存(0xa00000L),注意这里我们还是实模式,显存需要拆分成段地址:0xa000,和偏移0000 来访问:
用了e 命令,写入了一连串字节,值都是“4”,点击放大上面的窗口,可以看到左上角已经被我写了几个点了,默认调色板下4是红色。
接着在 A000:0300处(坐标第3行第32列)写入更多颜色,这次更明显些,注意上面中间:
放大些:
这次写入了更多颜色,而且是在第三行中间部分,没挨着dosbox的窗口边缘,看起来更清晰了,是吧?
好了,有了上面的试验后,我们可以写代码了,大概类似这样:
这个代码可以用 TurboC++2.0, Borland C++ 3.1, TurboC2 来编译,当然,当年这么写是不行的,硬件慢的要死,各种 trick当然是能上则上,正确的写法是:
优化了两处,范围判断改用 unsigned以后,少了两次 >= 0的判断,同时乘法变成了移位和加法,旧式cpu计算乘法总是那么的费时。有了画点,写一个画线画圆画矩形就容易了,再返照写一个图块拷贝(BitBlt)也很容易,有了这些,应该够开发一个传统游戏。
旧游戏里绘制一般都是在系统内存中进行的,在内存中开辟一块模仿显存的区域,进行画点画线,贴图,绘制好以后,一个memcpy,直接拷贝到显存。但实模式下线性地址只有64KB,可用总内存只有差不多640KB,要存储大量的图元是很困难的,稍不注意就内存不够了,因此 DOS下开发游戏,最好都是上 Watcom C++ 或者 Djgpp(dos下的gcc导出)。
Watcom C++ 可以在dos下实现4g内存访问,现在可以下载 OpenWatcom 来编译,我不太喜欢 Djgpp,编译太慢,加上一大堆著名游戏都是 Watcom C++写成的,导致我更加鄙视 Djgpp 因此我之前主要是在 Watcom C++下开发,除去上面的画点外,后面翻到的代码片段基本都是 Watcom C++的。
例子3:设置调色板
看到这里,也许你不禁要发问:除了直接写显存外,好像各种初始化工作都是调用 BIOS 里预先设置好的 INT 10h中断来完成啊,这 INT 10h 又是具体怎么操作显卡的呢?
其实 INT10h 也可以画点(AH=0C, AL=颜色, BH=0, DX=纵坐标,CX=横坐标),BIOS的 INT 10h中画点实现其实也是直接写显存,但是执行的很慢,基本没人这么用,都是直接写显存的,操作显卡除了访问显存外,有些功能还需要访问端口来实现。
接下来以初始化调色盘为例,256下同屏每个点只有0-255的调色板索引,具体显示什么颜色需要查找一个:256 x 3 = 768 字节的调色板(每个索引3个字节:RGB)。那么改变具体颜色对应的调色盘的代码一般是:
设置一个颜色的调色盘需要先向 0x03c8端口写入颜色编号,接着在 0x03c9端口依次写入R,G,B三个分量的具体数值,具体指令为:
我们可以使用 Watcom C++ 的 outp 函数来实现 out指令调用:
这个例子用到的是 OUT指令写端口,x86架构下 OUT 可以向特定端口写入数据,端口你可以理解为和数据总线并立的另外一个 I/O 控制总线,通过北桥南桥映射到各个硬件的 I/O 数据引脚,x86 下通过端口可以方便的操作显卡,软盘,硬盘,8254计时器,键盘缓存,DMA 控制器等常见硬件,后面我们还会频繁使用。
而其他硬件下,并没有端口这样一个控制总线存在,那 GBA / NDS 里没有端口这样的存在,他们是用何种方法访问各种外设呢?答案是内存地址映射,GBA / NDS 下有一段低端内存地址被映射给了 I/O RAM,通过直接读写这些地址,就可以跟x86的 out/in 指令一样控制各硬件,完成:显示模式设置,显示对象,图层,时钟,DMA,手柄,音乐等控制。
好了,现可以通过端口读写调色板了,我们调用一下上面这个函数:display_set_palette (4, 0, 63, 0); 就可以把上面通过直写显存画在左上角的一串红色点(颜色4)改变成绿色而不用重新写显存了,注意,vga的调色盘是64为的,RGB的最大亮度为63。
传统256色的游戏中需要正确设置调色板才能让图像看起来正确,否则就是花的,使用调色板还有很多用法,比如游戏中常见的 fade in / fade out 效果,就是定时,每次把所有颜色的调色板读取出来,R,G,B各-1,然后保存回去,就淡出了,还有一些类似调色板流动等用法,可以很方便的制作波浪流动(图片不变,只改变调色板),传统游戏中用它来控制海水效果,不需要每次重绘,比如老游戏中天上闪烁的星星,大部分都是调色板变动一下。
例子4:初始化 ModeX
传统标准显卡有三种显示模式:VGA模式(模式号低于256),VESA模式(模式号高于256,提供更高解析度,真彩高彩等显示模式,以及线性地址访问)此外还有著名的 ModeX,Michael Abrash 提出 ModeX 以后,由于对比其他标准模式具备更好的色彩填充性能,因此在不少游戏中也得到了广泛使用,但是其初始化非常的 trick,主体代码为:
是不是有点天书的感觉?直接控制硬件就是这么琐碎,前面初始化显示模式都是用 int 10h中断完成的,其实 int 10h中断里设置显示模式的功能本身也是通过各种写端口来控制垂直扫描频率,水平扫描频率,显存映射方式,开始地址等达到具体设置某一个分辨率的目的,也就是说其实你可以绕开int 10h用自己的方式设置出一个新的显示模式来,ModeX 就是这样初始化的。
不得不说一句今天有驱动程序真幸福,费了我九牛二虎之力才初始化成功的 ModeX,今天一个函数调用就完成了,大家也发现了使用 int 10h中断,调用 BIOS 里面的预设程序控制显卡,只是初级用法,现在基本只用在 grub 等操作系统加载程序上了,进入了操作系统后,就再也不会调用 int 10h,而是赤裸裸的直接和显卡打交到。
例子5:显存分段映射
早期显卡显存只能按 64KB 大小分成若干个 bank 来映射到特定的物理地址,也就是说你使用 640 x 480 x 32bits 的显示模式时,全屏幕总共需要 1200KB 的显存来表示屏幕上面的每一个点,而由于显存每次只能分段映射一个 64KB 大小的 bank,所以每次写屏前都要把对应位置的显存先映射过来才能写,我们使用下面代码来切换 bank:
注意这里还有个窗口概念,一个窗口可以映射一个bank,大部分显卡只有一个窗口,则只能同时映射一段64KB的显存给cpu访问,而有的显卡有两个窗口(一个读,一个写)。
这个是标准做法,访问中断很慢,在绘制过程中频繁的访问中断是要命的,故 Trident 系列的显卡提供直接访问端口的方法来切换页面(Trident只有一个窗口,同时只能映射一个64KB的bank):
而如果你使用支持 VESA2.0 标准的显卡,在保护模式下,VESA2的接口提供了一系列函数入口供你调用,你可以直接在 Watcom C++ 下面调用这些函数完成页面切换,比调用中断的开销小多了。
听起来十分美妙,但是你想导出这些函数的入口地址来调用的话,你将需要:
1. 分配一块物理内存并锁定地址。
2. 调用vesa中断,向这个物理地址写入这些函数的代码。
3. 为该物理内存分配一个 selector 段地址,才能读取这些代码并拷贝到 Watcom C++默认段。
4. 按照入口表,初始化 Watcom C++ 里面的函数指针,并释放物理内存。
5. 然后你才可以开心的调用这些函数。
这个函数表,可以理解成就是 VESA 2.0 的一个初级阶段的驱动程序了。
简单一个页面切换,上面就提到了三种做法,你可以选择最保险也是性能最差的中断调用,也可以根据显卡支持选择写端口或者直接调用导出函数。
好在游戏基本都是二级缓存来绘制的,主要的绘制工作在系统内存的二级缓存里面完成,最后只需要在memcpy搬运到显存显示出来的时候,再去设置页面映射,然后整个 bank一次性拷贝,然后再切换到下一个 bank,这样“设置页面映射” 这个操作的调用次数就会比较少了。
这就是早年访问多于 64KB 显存的基本方法,多用在解析度超过 320x200 的模式中,如果你继续使用流行的 320x200 显示模式,你将不需要考虑这个事情,因为全屏幕只需要 62.5 KB的显存,没有切换 BANK 的需要。
但是早期缺乏统一的编程接口,今天这个显卡扩充一点功能,明天那个品牌又多两个效果,弄得你疲于奔命,因此 Windows 以后,这些工作都统一交给显卡驱动来完成了。
例子6:线性显存映射
由于分辨率越来越高,越来越多的软件用到了 640x480x256以上的显示模式,传统的 bank 映射方式已经显得越来越落后了,因此90年代中期的显卡纷纷开始支持 VESA 2.0 中的 “线性地址映射”,通过一些列初始化工作,将显示模式设置为 “线性地址”,这样在保护模式下,你就可以一整块的访问连续显存而用不着切换 bank了。
这是一种十分简单高效的方式,只要你的游戏用 Watcom C++ / Djgpp 开发,跑在保护模式下,这可以说是最美妙方方式了,可惜,当年并不是所有显卡都支持这样的方式,碰到不兼容的显卡你还得绕回去使用 bank 切换。
所以为了在 640x480x256c 下面正确绘制图形,一共有四种显存访问方式(bank切换3种+线性地址映射),应用程序写的好的话,需要把访问显存统一封装一下,并提供类似这样的接口:
背后则需要判断显卡的特性,普通显卡使用兼容性最好的的方式,而好点的显卡使用更快速的方式,并为上层提供统一的访问 framebuffer 的接口,由于早年的 C++ 编译器优化十分有限,这部分基本都是上千行的汇编代码直接实现,于是你又得捧起486、奔腾优化手册来,慢慢调试一点点计算 u,v 流水线的开销并安排好指令让它们最大程度并行执行。
一直到了 DirectX 时代,整个事情才简单了很多,微软一句话,所有 DirectX 兼容显卡必须支持线性地址映射,因此 DirectX 下面 Lock 一个 Surface 后可以毫无拘束连续访问显存,这样一个简单的操作,对比前面的实现,简直是一件十分幸福的事情。
例子7:DMA控制器访问
(待续)
虽然没有驱动,但是硬件标准还是放在那里,VGA, SVGA, VESA, VESA2.0 之类的硬件标准,最起码,你只做320x200x256c的游戏,或者 ModeX 下 320x240x256c 的游戏的话,需要用到VGA和部分 SVGA标准,而要做真彩高彩,更高分辨率的游戏的话,就必须掌握 VESA的各项规范了。
翻几段以前写的代码演示下:
例子1: 初始化 VGA/VESA 显示模式
基本是参考 VGA的编程手册来做:
INT 10,0 - Set Video Mode
AH = 00
AL = 00 40x25 B/W text (CGA,EGA,MCGA,VGA)
= 01 40x25 16 color text (CGA,EGA,MCGA,VGA)
= 02 80x25 16 shades of gray text (CGA,EGA,MCGA,VGA)
= 03 80x25 16 color text (CGA,EGA,MCGA,VGA)
= 04 320x200 4 color graphics (CGA,EGA,MCGA,VGA)
= 05 320x200 4 color graphics (CGA,EGA,MCGA,VGA)
= 06 640x200 B/W graphics (CGA,EGA,MCGA,VGA)
= 07 80x25 Monochrome text (MDA,HERC,EGA,VGA)
= 08 160x200 16 color graphics (PCjr)
= 09 320x200 16 color graphics (PCjr)
= 0A 640x200 4 color graphics (PCjr)
= 0B Reserved (EGA BIOS function 11)
= 0C Reserved (EGA BIOS function 11)
= 0D 320x200 16 color graphics (EGA,VGA)
= 0E 640x200 16 color graphics (EGA,VGA)
= 0F 640x350 Monochrome graphics (EGA,VGA)
= 10 640x350 16 color graphics (EGA or VGA with 128K)
640x350 4 color graphics (64K EGA)
= 11 640x480 B/W graphics (MCGA,VGA)
= 12 640x480 16 color graphics (VGA)
= 13 320x200 256 color graphics (MCGA,VGA)
= 8x EGA, MCGA or VGA ignore bit 7, see below
= 9x EGA, MCGA or VGA ignore bit 7, see below
- if AL bit 7=1, prevents EGA,MCGA & VGA from clearing display
- function updates byte at 40:49; bit 7 of byte 40:87
(EGA/VGA Display Data Area) is set to the value of AL bit 7
转换成代码的话,类似这样:
// enter standard graphic mode
int display_enter_graph(int mode)
{
short hr = 0;
union REGS r;
memset(&r, 0, sizeof(r));
if (mode < 0x100) {
r.w.ax = (short)mode;
int386(0x10, &r, &r);
r.h.ah = 0xf;
int386(0x10, &r, &r);
if (r.h.al != mode) hr = -1;
}
else {
r.w.ax = 0x4f02;
r.w.bx = (short)mode;
int386(0x10, &r, &r);
if (r.w.ax != 0x004f) hr = -1;
}
return hr;
}
例子2: 画点
如果你初始化成功了 320 x 200 x 256 c 模式(INT 0x10, AX=0x13),那么画点就是象显存地址 0xA00000L 里面写一个字节(8位色彩深度):
首先我们使用 DOSBOX (DOS开发调试神器)来调试我们的代码,启动 DOSBOX以后,运行
debug
然后写两条进入图形模式的指令:
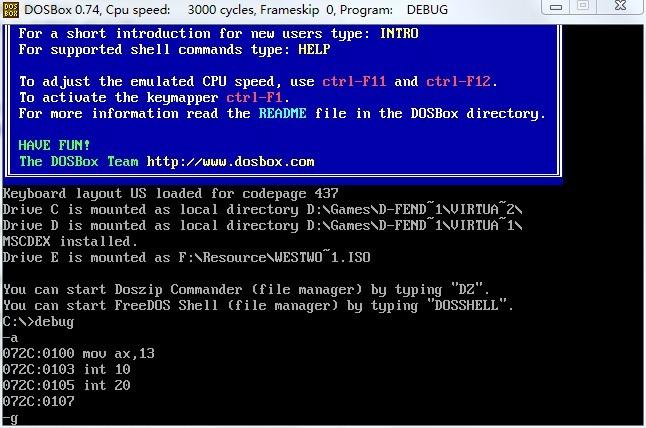
mov ax, 13 ; 设置 ah=0(0号函数上面有说明), al=0x13(0x13模式,320x200)
int 10 ; 调用显卡中断
int 20 ; DOS命令:退出程序
输入空行后退出编辑模式,然后使用 'g' 命令运行刚才的这个小程序:
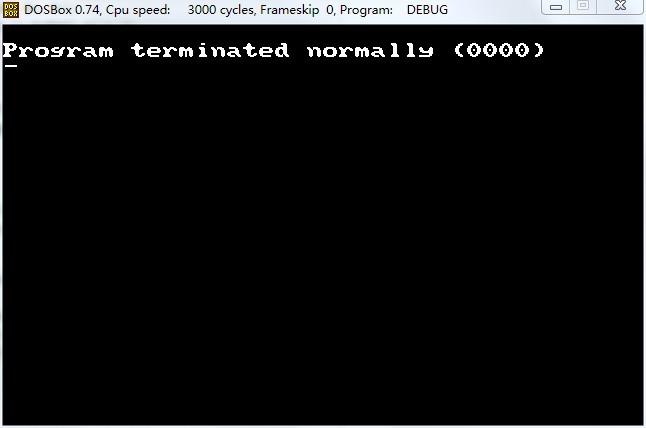
可以看到,显示模式初始化成功了,现在你已经进入了 320x200x256c的显示模式,大量的 DOS游戏是使用这个模式开发出来的(仙剑奇侠传,轩辕剑1/2,C&C)。
接下来我们编辑显存,使用 e命令,进行写显存(0xa00000L),注意这里我们还是实模式,显存需要拆分成段地址:0xa000,和偏移0000 来访问:
-e a000:0000
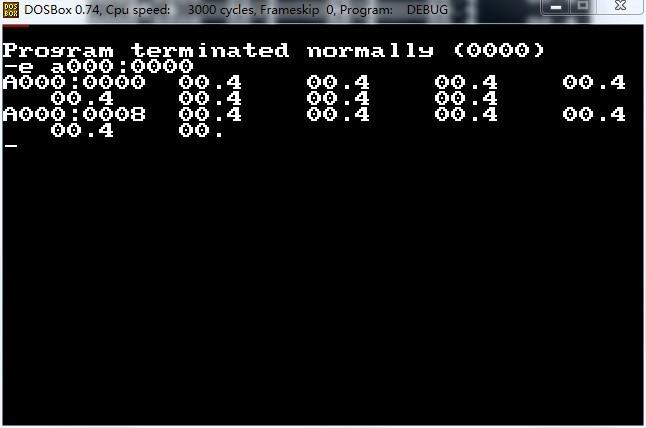
用了e 命令,写入了一连串字节,值都是“4”,点击放大上面的窗口,可以看到左上角已经被我写了几个点了,默认调色板下4是红色。
接着在 A000:0300处(坐标第3行第32列)写入更多颜色,这次更明显些,注意上面中间:
放大些:
这次写入了更多颜色,而且是在第三行中间部分,没挨着dosbox的窗口边缘,看起来更清晰了,是吧?
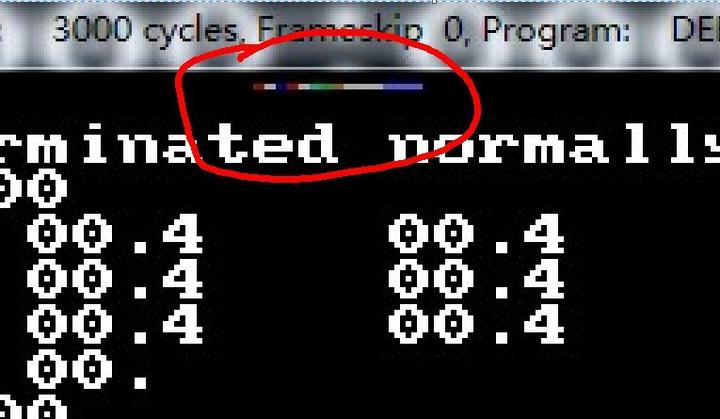 这次写入了更多颜色,而且是在第三行中间部分,没挨着dosbox的窗口边缘,看起来更清晰了,是吧?
这次写入了更多颜色,而且是在第三行中间部分,没挨着dosbox的窗口边缘,看起来更清晰了,是吧?
好了,有了上面的试验后,我们可以写代码了,大概类似这样:
void putpixel(int x, int y, unsigned char color)
{
static unsigned char far *videobuf = (unsigned char far*)0xa0000000;
if (x >= 0 && y >= 0 && x < 320 && y < 200) {
videobuf[y * 320 + x] = color;
}
}
这个代码可以用 TurboC++2.0, Borland C++ 3.1, TurboC2 来编译,当然,当年这么写是不行的,硬件慢的要死,各种 trick当然是能上则上,正确的写法是:
void putpixel(int x, int y, unsigned char color)
{
static unsigned char far *videobuf = (unsigned char far*)0xa0000000;
if (((unsigned)x) < 320 && ((unsigned)y) < 200) {
videobuf[(y << 6) + (unsigned)(y << 8) + x] = color;
}
}
旧游戏里绘制一般都是在系统内存中进行的,在内存中开辟一块模仿显存的区域,进行画点画线,贴图,绘制好以后,一个memcpy,直接拷贝到显存。但实模式下线性地址只有64KB,可用总内存只有差不多640KB,要存储大量的图元是很困难的,稍不注意就内存不够了,因此 DOS下开发游戏,最好都是上 Watcom C++ 或者 Djgpp(dos下的gcc导出)。
Watcom C++ 可以在dos下实现4g内存访问,现在可以下载 OpenWatcom 来编译,我不太喜欢 Djgpp,编译太慢,加上一大堆著名游戏都是 Watcom C++写成的,导致我更加鄙视 Djgpp 因此我之前主要是在 Watcom C++下开发,除去上面的画点外,后面翻到的代码片段基本都是 Watcom C++的。
例子3:设置调色板
看到这里,也许你不禁要发问:除了直接写显存外,好像各种初始化工作都是调用 BIOS 里预先设置好的 INT 10h中断来完成啊,这 INT 10h 又是具体怎么操作显卡的呢?
其实 INT10h 也可以画点(AH=0C, AL=颜色, BH=0, DX=纵坐标,CX=横坐标),BIOS的 INT 10h中画点实现其实也是直接写显存,但是执行的很慢,基本没人这么用,都是直接写显存的,操作显卡除了访问显存外,有些功能还需要访问端口来实现。
接下来以初始化调色盘为例,256下同屏每个点只有0-255的调色板索引,具体显示什么颜色需要查找一个:256 x 3 = 768 字节的调色板(每个索引3个字节:RGB)。那么改变具体颜色对应的调色盘的代码一般是:
设置一个颜色的调色盘需要先向 0x03c8端口写入颜色编号,接着在 0x03c9端口依次写入R,G,B三个分量的具体数值,具体指令为:
mov edx, 0x03c7
mov al, color
out dx, al
inc dx
mov al, R
out dx, al
mov al, G
out dx, al
mov al, B
out dx, al
我们可以使用 Watcom C++ 的 outp 函数来实现 out指令调用:
void display_set_palette(unsigned char color, char r, char g, char b)
{
short port = 0x03c8;
outp(port, color);
port++;
outp(port, r);
outp(port, g);
outp(port, b);
}
这个例子用到的是 OUT指令写端口,x86架构下 OUT 可以向特定端口写入数据,端口你可以理解为和数据总线并立的另外一个 I/O 控制总线,通过北桥南桥映射到各个硬件的 I/O 数据引脚,x86 下通过端口可以方便的操作显卡,软盘,硬盘,8254计时器,键盘缓存,DMA 控制器等常见硬件,后面我们还会频繁使用。
而其他硬件下,并没有端口这样一个控制总线存在,那 GBA / NDS 里没有端口这样的存在,他们是用何种方法访问各种外设呢?答案是内存地址映射,GBA / NDS 下有一段低端内存地址被映射给了 I/O RAM,通过直接读写这些地址,就可以跟x86的 out/in 指令一样控制各硬件,完成:显示模式设置,显示对象,图层,时钟,DMA,手柄,音乐等控制。
好了,现可以通过端口读写调色板了,我们调用一下上面这个函数:display_set_palette (4, 0, 63, 0); 就可以把上面通过直写显存画在左上角的一串红色点(颜色4)改变成绿色而不用重新写显存了,注意,vga的调色盘是64为的,RGB的最大亮度为63。
传统256色的游戏中需要正确设置调色板才能让图像看起来正确,否则就是花的,使用调色板还有很多用法,比如游戏中常见的 fade in / fade out 效果,就是定时,每次把所有颜色的调色板读取出来,R,G,B各-1,然后保存回去,就淡出了,还有一些类似调色板流动等用法,可以很方便的制作波浪流动(图片不变,只改变调色板),传统游戏中用它来控制海水效果,不需要每次重绘,比如老游戏中天上闪烁的星星,大部分都是调色板变动一下。
例子4:初始化 ModeX
传统标准显卡有三种显示模式:VGA模式(模式号低于256),VESA模式(模式号高于256,提供更高解析度,真彩高彩等显示模式,以及线性地址访问)此外还有著名的 ModeX,Michael Abrash 提出 ModeX 以后,由于对比其他标准模式具备更好的色彩填充性能,因此在不少游戏中也得到了广泛使用,但是其初始化非常的 trick,主体代码为:
outpw(0x3C4, 0x0100); /* synchronous reset */
outp(0x3D4, 0x11); /* enable crtc regs 0-7 */
outp(0x3D5, inp(0x3D5) & 0x7F);
outpw(0x3C4, 0x0604); /* disable chain-4 */
for (reg=mode->regs; reg->port; reg++) { /* set the VGA registers */
if (reg->port == 0x3C0) {
inp(0x3DA);
outp(0x3C0, reg->index | 0x20);
outp(0x3C0, reg->value);
}
else if (reg->port == 0x3C2) {
outp(reg->port, reg->value);
}
else {
outp(reg->port, reg->index);
outp(reg->port + 1, reg->value);
}
}
if (mode->hrs) {
outp(0x3D4, 0x11); outp(0x3D5, inp(0x3D5) & 0x7F);
outp(0x3D4, 0x04); outp(0x3D5, inp(0x3D5) + mode->hrs);
outp(0x3D4, 0x11); outp(0x3D5, inp(0x3D5) | 0x80);
}
if (mode->shift) {
outp(0x3CE, 0x05);
outp(0x3CF, (inp(0x3CF) & 0x60) | 0x40);
inp(0x3DA);
outp(0x3C0, 0x30);
outp(0x3C0, inp(0x3C1) | 0x40);
for (c=0; c<16; c++) {
outp(0x3C0, c);
outp(0x3C0, c);
}
outp(0x3C0, 0x20);
}
if (mode->repeat) {
outp(0x3D4, 0x09);
outp(0x3D5, (inp(0x3D5) & 0x60) | mode->repeat);
}
outp(0x3D4, 0x13); /* set scanline length */
outp(0x3D5, width / 8);
outpw(0x3C4, 0x0300); /* restart sequencer */
是不是有点天书的感觉?直接控制硬件就是这么琐碎,前面初始化显示模式都是用 int 10h中断完成的,其实 int 10h中断里设置显示模式的功能本身也是通过各种写端口来控制垂直扫描频率,水平扫描频率,显存映射方式,开始地址等达到具体设置某一个分辨率的目的,也就是说其实你可以绕开int 10h用自己的方式设置出一个新的显示模式来,ModeX 就是这样初始化的。
不得不说一句今天有驱动程序真幸福,费了我九牛二虎之力才初始化成功的 ModeX,今天一个函数调用就完成了,大家也发现了使用 int 10h中断,调用 BIOS 里面的预设程序控制显卡,只是初级用法,现在基本只用在 grub 等操作系统加载程序上了,进入了操作系统后,就再也不会调用 int 10h,而是赤裸裸的直接和显卡打交到。
例子5:显存分段映射
早期显卡显存只能按 64KB 大小分成若干个 bank 来映射到特定的物理地址,也就是说你使用 640 x 480 x 32bits 的显示模式时,全屏幕总共需要 1200KB 的显存来表示屏幕上面的每一个点,而由于显存每次只能分段映射一个 64KB 大小的 bank,所以每次写屏前都要把对应位置的显存先映射过来才能写,我们使用下面代码来切换 bank:
int display_vesa_switch(int window, int bank)
{
union REGS r;
r.x.eax = 0x4f05;
r.x.ebx = window;
r.x.edx = bank;
int386(0x10, &r, &r);
return 0;
}
注意这里还有个窗口概念,一个窗口可以映射一个bank,大部分显卡只有一个窗口,则只能同时映射一段64KB的显存给cpu访问,而有的显卡有两个窗口(一个读,一个写)。
这个是标准做法,访问中断很慢,在绘制过程中频繁的访问中断是要命的,故 Trident 系列的显卡提供直接访问端口的方法来切换页面(Trident只有一个窗口,同时只能映射一个64KB的bank):
int display_trident_switch(unsigned char bank)
{
outp(0x3c4, 0x0e);
outp(0x3c5, bank ^ 0x2);
return 0;
}
而如果你使用支持 VESA2.0 标准的显卡,在保护模式下,VESA2的接口提供了一系列函数入口供你调用,你可以直接在 Watcom C++ 下面调用这些函数完成页面切换,比调用中断的开销小多了。
听起来十分美妙,但是你想导出这些函数的入口地址来调用的话,你将需要:
1. 分配一块物理内存并锁定地址。
2. 调用vesa中断,向这个物理地址写入这些函数的代码。
3. 为该物理内存分配一个 selector 段地址,才能读取这些代码并拷贝到 Watcom C++默认段。
4. 按照入口表,初始化 Watcom C++ 里面的函数指针,并释放物理内存。
5. 然后你才可以开心的调用这些函数。
这个函数表,可以理解成就是 VESA 2.0 的一个初级阶段的驱动程序了。
简单一个页面切换,上面就提到了三种做法,你可以选择最保险也是性能最差的中断调用,也可以根据显卡支持选择写端口或者直接调用导出函数。
好在游戏基本都是二级缓存来绘制的,主要的绘制工作在系统内存的二级缓存里面完成,最后只需要在memcpy搬运到显存显示出来的时候,再去设置页面映射,然后整个 bank一次性拷贝,然后再切换到下一个 bank,这样“设置页面映射” 这个操作的调用次数就会比较少了。
这就是早年访问多于 64KB 显存的基本方法,多用在解析度超过 320x200 的模式中,如果你继续使用流行的 320x200 显示模式,你将不需要考虑这个事情,因为全屏幕只需要 62.5 KB的显存,没有切换 BANK 的需要。
但是早期缺乏统一的编程接口,今天这个显卡扩充一点功能,明天那个品牌又多两个效果,弄得你疲于奔命,因此 Windows 以后,这些工作都统一交给显卡驱动来完成了。
例子6:线性显存映射
由于分辨率越来越高,越来越多的软件用到了 640x480x256以上的显示模式,传统的 bank 映射方式已经显得越来越落后了,因此90年代中期的显卡纷纷开始支持 VESA 2.0 中的 “线性地址映射”,通过一些列初始化工作,将显示模式设置为 “线性地址”,这样在保护模式下,你就可以一整块的访问连续显存而用不着切换 bank了。
这是一种十分简单高效的方式,只要你的游戏用 Watcom C++ / Djgpp 开发,跑在保护模式下,这可以说是最美妙方方式了,可惜,当年并不是所有显卡都支持这样的方式,碰到不兼容的显卡你还得绕回去使用 bank 切换。
所以为了在 640x480x256c 下面正确绘制图形,一共有四种显存访问方式(bank切换3种+线性地址映射),应用程序写的好的话,需要把访问显存统一封装一下,并提供类似这样的接口:
//---------------------------------------------------------------------
// Framebuffer Access
//---------------------------------------------------------------------
// copy rect from memory to video frame buffer
void display_bits_set(int sx, int sy, const void *src, long pitch,
int x, int y, int w, int h);
// get rect from frame buffer to memory
void display_bits_get(int sx, int sy, void *dst, long pitch,
int x, int y, int w, int h);
// write row to video frame buffer
void display_row_write(int x, int y, const void *buffer, int npixels);
// read row from video frame buffer
void display_row_read(int x, int y, void *buffer, int npixels);
背后则需要判断显卡的特性,普通显卡使用兼容性最好的的方式,而好点的显卡使用更快速的方式,并为上层提供统一的访问 framebuffer 的接口,由于早年的 C++ 编译器优化十分有限,这部分基本都是上千行的汇编代码直接实现,于是你又得捧起486、奔腾优化手册来,慢慢调试一点点计算 u,v 流水线的开销并安排好指令让它们最大程度并行执行。
一直到了 DirectX 时代,整个事情才简单了很多,微软一句话,所有 DirectX 兼容显卡必须支持线性地址映射,因此 DirectX 下面 Lock 一个 Surface 后可以毫无拘束连续访问显存,这样一个简单的操作,对比前面的实现,简直是一件十分幸福的事情。
例子7:DMA控制器访问
(待续)


在这里回答一下第一个,第二个,第四个和第五个问题。
在回答这个问题之前,必须要有一些限定。因为显卡是有很多种,显卡所在平台也很多种,不能一概而论。我的回答都是基于Intel x86平台下的Intel自家的GEN显示核心单元(也就是市面上的HD 4000什么的)。操作系统大多数以Linux为例。
>>> Q1. 显卡驱动是怎么控制显卡的, 就是说, 使用那些指令控制显卡, 通过端口么?
目前的显卡驱动,不是单纯的一个独立的驱动模块,而是几个驱动模块的集合。用户态和内核态驱动都有。以Linux桌面系统为例,按照模块划分,内核驱动有drm/i915模块, 用户驱动包括libdrm, Xorg的DDX和DIX,3D的LibGL, Video的Libva等等,各个用户态驱动可能相互依赖,相互协作,作用各不相同。限于篇幅无法一一介绍。如果按照功能划分的话,大概分成5大类,display, 2D, 3D, video, 以及General Purpose Computing 通用计算。Display是关于如何显示内容,比如分辨率啊,刷新率啊,多屏显示啊。2D现在用的很少了,基本就是画点画线加速,快速内存拷贝(也就是一种DMA)。3D就复杂了,基本现在2D的事儿也用3D干。3D涉及很多计算机图形学的知识,我的短板,我就不多说了。Video是指硬件加速的视频编解码。通用计算就是对于OpenCL,OpenCV,CUDA这些框架的支持。
回到问题,驱动如何控制显卡。
首先,操作硬件的动作是敏感动作,一般只有内核才有权限。个别情况会由用户态操作,但是也是通过内核建立寄存器映射才行。
理解驱动程序最重要的一句话是,寄存器是软件控制硬件的唯一途径。所以你问如何控制显卡,答案就是靠读写显卡提供的寄存器。
通过什么读写呢?据我所知的目前的显卡驱动,基本没有用低效的端口IO的方式读写。现在都是通过MMIO把寄存器映射的内核地址空间,然后用内存访问指令(也就是一般的C语言赋值语句)来访问。具体可以参考”内核内存映射,MMIO“的相关资料。
>>>Q2.2. DirectX 或 OpenGL 或 CUDA 或 OpenCL 怎么找到显卡驱动, 显卡驱动是不是要为他们提供接口的实现, 如果是, 那么DirectX和OpenGL和CUDA和OpenCL需要显卡驱动提供的接口都是什么, 这个文档在哪能下载到? 如果不是, 那么DirectX, OpenGL, CL, CUDA是怎么控制显卡的?
这个问题我仅仅针对OpenGL和OpenCL在Linux上的实现尝试回答一下。
a.关于如何找到驱动?首先这里我们要明确一下驱动程序是什么,对于OpenGL来说,有个用户态的库叫做LibGL.so,这个就是OpenGL的用户态驱动(也可以称之为库,但是一定会另外再依赖一个硬件相关的动态库,这个就是更狭义的驱动),直接对应用程序提供API。同样,OpenCL,也有一个LibCL.so.。这些so文件都依赖下层更底层的用户态驱动作为支持(在Linux下,显卡相关的驱动,一般是一个通用层驱动.so文件提供API,然后下面接一个平台相关的.so文件提供对应的硬件支持。比如LibVA.so提供视频加速的API,i965_video_drv.so是他的后端,提供Intel平台对应libva的硬件加速的实现)。 下面给你一张大图:
如图可见,最上层的用户态驱动向下依赖很多设备相关的驱动,最后回到Libdrm这层,这一层是内核和用户态的临界。一般在这里,想用显卡的程序会open一个/dev/dri/card0的设备节点,这个节点是由显卡内核驱动创建的。当然这个open的动作不是由应用程序直接进行的,通常会使用一些富足函数,比如drmOpenByName, drmOpenByBusID. 在此之前还会有一些查询的操作,查询板卡的名称或者Bus ID。然后调用对应的辅助函数打开设备节点。打开之后,他就可以根据DRI的规范来使用显卡的功能。我说的这一切都是有规范的,在Linux里叫DRI(Direct Rendering Infrastructure)。
所有这些图片文档都可以 Direct Rendering Infrastructure 和 freedesktop上的页面DRI wiki找到 DRI Wiki
显卡驱动的结构很复杂,这里有设计原因也有历史原因。
b.关于接口的定义,源代码都可以在我上面提供的链接里找到。这一套是规范,有协议的。
c.OpenGL, OpenCL或者LibVA之类的需要显卡提供点阵运算,通用计算,或者编解码服务的驱动程序,一般都是通过两种途径操作显卡。第一个是使用DRM提供的ioctl机制,就是系统调用。这类操作一般包括申请释放显存对象,映射显存对象,执行GPU指令等等。另一种是用户态驱动把用户的API语意翻译成为一组GPU指令,然后在内核驱动的帮助下(就是第一种的执行GPU指令的ioctl)把指令下达给GPU做运算。具体细节就不多说了,这些可以通过阅读源代码获得。
>>>Q4. 显卡 ( 或其他设备 ) 可以访问内存么? 内存地址映射的原理是什么, 为什么 B8000H 到 C7FFFH 是显存的地址, 向这个地址空间写入数据后, 是直接通过总线写入显存了么, 还是依然写在内存中, 显卡到内存中读取, 如果直接写到显存了, 会出现延时和等待么?
a..可以访问内存。如果访问不了,那显示的东西是从哪儿来的呢?你在硬盘的一部A片,总不能自己放到显卡里解码渲染吧?
b.显卡访问内存,3种主要方式。
第一种,就是framebuffer。CPU搞一块内存名叫Framebuffer,里面放上要显示的东西,显卡有个部件叫DIsplay Controller会扫描那块内存,然后把内容显示到屏幕上。至于具体如何配置成功的,Long story, 这里不细说了。
第二种,DMA。DMA懂吧?就是硬件设备直接从内存取数据,当然需要软件先配置,这就是graphics driver的活儿。在显卡驱动里,DMA还有个专用的名字叫Blit。
第三种,内存共享。Intel的平台,显存和内存本质都是主存。区别是CPU用的需要MMU映射,GPU用的需要GPU的MMU叫做GTT映射。所以共享内存的方法很简单,把同一个物理页既填到MMU页表里,也填到GTT页表里。具体细节和原理,依照每个人的基础不同,需要看的文档不同。。。
c.为什么是那个固定地址?这个地址学名叫做Aperture空间,就是为了吧显存映射到一个段连续的物理空间。为什么要映射,就是为了显卡可以连续访问一段地址。因为内存是分页的,但是硬件经常需要连续的页。其实还有一个更重要的原因是为了解决叫做tiling的关于图形内存存储形势和不同内存不一致的问题(这个太专业了对于一般人来说)。
这地址的起始地址是平台相关,PC平台一般由固件(BIOS之流)统筹规划总线地址空间之后为显卡特别划分一块。地址区间的大小一般也可以在固件里指定或者配置。
另外,还有一类地址也是高位固定划分的称为stolen memory,这个是x86平台都有的,就是窃取一块物理内存专门为最基本的图形输出使用,比如终端字符显示,framebuffer。起始地址也是固件决定,大小有默认值也可以配置。
d. 刚才说了,Intel的显存内存一回事儿。至于独立显卡有独立显存的平台来回答你这个问题是这样的:任何访存都是通过总线的,直接写也是通过总线写,拷贝也是通过总线拷贝;有时候需要先写入临时内存再拷贝一遍到目标区域,原因很多种;写操作都是通过PCI总线都有延迟,写谁都有。总线就是各个设备共享的资源,需要仲裁之类的机制,肯定有时候要等一下。
>>>Q5. 以上这些知识从哪些书籍上可以获得?
Intel Graphics for Linux*, 从这里看起吧少年。这类过于专业的知识,不建议在一般经验交流的平台求助,很难得到准确的答案。你这类问题,需要的就是准确答案。不然会把本来就不容易理解的问题变得更复杂。
在回答这个问题之前,必须要有一些限定。因为显卡是有很多种,显卡所在平台也很多种,不能一概而论。我的回答都是基于Intel x86平台下的Intel自家的GEN显示核心单元(也就是市面上的HD 4000什么的)。操作系统大多数以Linux为例。
>>> Q1. 显卡驱动是怎么控制显卡的, 就是说, 使用那些指令控制显卡, 通过端口么?
目前的显卡驱动,不是单纯的一个独立的驱动模块,而是几个驱动模块的集合。用户态和内核态驱动都有。以Linux桌面系统为例,按照模块划分,内核驱动有drm/i915模块, 用户驱动包括libdrm, Xorg的DDX和DIX,3D的LibGL, Video的Libva等等,各个用户态驱动可能相互依赖,相互协作,作用各不相同。限于篇幅无法一一介绍。如果按照功能划分的话,大概分成5大类,display, 2D, 3D, video, 以及General Purpose Computing 通用计算。Display是关于如何显示内容,比如分辨率啊,刷新率啊,多屏显示啊。2D现在用的很少了,基本就是画点画线加速,快速内存拷贝(也就是一种DMA)。3D就复杂了,基本现在2D的事儿也用3D干。3D涉及很多计算机图形学的知识,我的短板,我就不多说了。Video是指硬件加速的视频编解码。通用计算就是对于OpenCL,OpenCV,CUDA这些框架的支持。
回到问题,驱动如何控制显卡。
首先,操作硬件的动作是敏感动作,一般只有内核才有权限。个别情况会由用户态操作,但是也是通过内核建立寄存器映射才行。
理解驱动程序最重要的一句话是,寄存器是软件控制硬件的唯一途径。所以你问如何控制显卡,答案就是靠读写显卡提供的寄存器。
通过什么读写呢?据我所知的目前的显卡驱动,基本没有用低效的端口IO的方式读写。现在都是通过MMIO把寄存器映射的内核地址空间,然后用内存访问指令(也就是一般的C语言赋值语句)来访问。具体可以参考”内核内存映射,MMIO“的相关资料。
>>>Q2.2. DirectX 或 OpenGL 或 CUDA 或 OpenCL 怎么找到显卡驱动, 显卡驱动是不是要为他们提供接口的实现, 如果是, 那么DirectX和OpenGL和CUDA和OpenCL需要显卡驱动提供的接口都是什么, 这个文档在哪能下载到? 如果不是, 那么DirectX, OpenGL, CL, CUDA是怎么控制显卡的?
这个问题我仅仅针对OpenGL和OpenCL在Linux上的实现尝试回答一下。
a.关于如何找到驱动?首先这里我们要明确一下驱动程序是什么,对于OpenGL来说,有个用户态的库叫做LibGL.so,这个就是OpenGL的用户态驱动(也可以称之为库,但是一定会另外再依赖一个硬件相关的动态库,这个就是更狭义的驱动),直接对应用程序提供API。同样,OpenCL,也有一个LibCL.so.。这些so文件都依赖下层更底层的用户态驱动作为支持(在Linux下,显卡相关的驱动,一般是一个通用层驱动.so文件提供API,然后下面接一个平台相关的.so文件提供对应的硬件支持。比如LibVA.so提供视频加速的API,i965_video_drv.so是他的后端,提供Intel平台对应libva的硬件加速的实现)。 下面给你一张大图:
如图可见,最上层的用户态驱动向下依赖很多设备相关的驱动,最后回到Libdrm这层,这一层是内核和用户态的临界。一般在这里,想用显卡的程序会open一个/dev/dri/card0的设备节点,这个节点是由显卡内核驱动创建的。当然这个open的动作不是由应用程序直接进行的,通常会使用一些富足函数,比如drmOpenByName, drmOpenByBusID. 在此之前还会有一些查询的操作,查询板卡的名称或者Bus ID。然后调用对应的辅助函数打开设备节点。打开之后,他就可以根据DRI的规范来使用显卡的功能。我说的这一切都是有规范的,在Linux里叫DRI(Direct Rendering Infrastructure)。
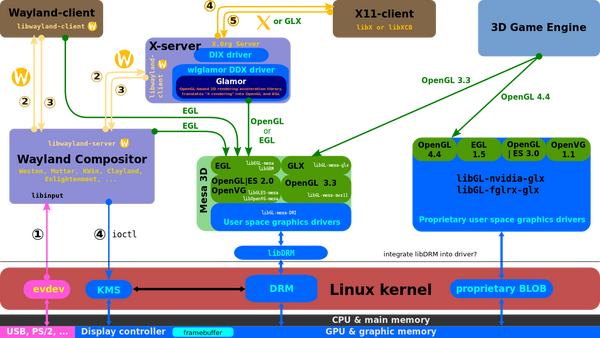 如图可见,最上层的用户态驱动向下依赖很多设备相关的驱动,最后回到Libdrm这层,这一层是内核和用户态的临界。一般在这里,想用显卡的程序会open一个/dev/dri/card0的设备节点,这个节点是由显卡内核驱动创建的。当然这个open的动作不是由应用程序直接进行的,通常会使用一些富足函数,比如drmOpenByName, drmOpenByBusID. 在此之前还会有一些查询的操作,查询板卡的名称或者Bus ID。然后调用对应的辅助函数打开设备节点。打开之后,他就可以根据DRI的规范来使用显卡的功能。我说的这一切都是有规范的,在Linux里叫DRI(Direct Rendering Infrastructure)。
如图可见,最上层的用户态驱动向下依赖很多设备相关的驱动,最后回到Libdrm这层,这一层是内核和用户态的临界。一般在这里,想用显卡的程序会open一个/dev/dri/card0的设备节点,这个节点是由显卡内核驱动创建的。当然这个open的动作不是由应用程序直接进行的,通常会使用一些富足函数,比如drmOpenByName, drmOpenByBusID. 在此之前还会有一些查询的操作,查询板卡的名称或者Bus ID。然后调用对应的辅助函数打开设备节点。打开之后,他就可以根据DRI的规范来使用显卡的功能。我说的这一切都是有规范的,在Linux里叫DRI(Direct Rendering Infrastructure)。
所有这些图片文档都可以 Direct Rendering Infrastructure 和 freedesktop上的页面DRI wiki找到 DRI Wiki
显卡驱动的结构很复杂,这里有设计原因也有历史原因。
b.关于接口的定义,源代码都可以在我上面提供的链接里找到。这一套是规范,有协议的。
c.OpenGL, OpenCL或者LibVA之类的需要显卡提供点阵运算,通用计算,或者编解码服务的驱动程序,一般都是通过两种途径操作显卡。第一个是使用DRM提供的ioctl机制,就是系统调用。这类操作一般包括申请释放显存对象,映射显存对象,执行GPU指令等等。另一种是用户态驱动把用户的API语意翻译成为一组GPU指令,然后在内核驱动的帮助下(就是第一种的执行GPU指令的ioctl)把指令下达给GPU做运算。具体细节就不多说了,这些可以通过阅读源代码获得。
>>>Q4. 显卡 ( 或其他设备 ) 可以访问内存么? 内存地址映射的原理是什么, 为什么 B8000H 到 C7FFFH 是显存的地址, 向这个地址空间写入数据后, 是直接通过总线写入显存了么, 还是依然写在内存中, 显卡到内存中读取, 如果直接写到显存了, 会出现延时和等待么?
a..可以访问内存。如果访问不了,那显示的东西是从哪儿来的呢?你在硬盘的一部A片,总不能自己放到显卡里解码渲染吧?
b.显卡访问内存,3种主要方式。
第一种,就是framebuffer。CPU搞一块内存名叫Framebuffer,里面放上要显示的东西,显卡有个部件叫DIsplay Controller会扫描那块内存,然后把内容显示到屏幕上。至于具体如何配置成功的,Long story, 这里不细说了。
第二种,DMA。DMA懂吧?就是硬件设备直接从内存取数据,当然需要软件先配置,这就是graphics driver的活儿。在显卡驱动里,DMA还有个专用的名字叫Blit。
第三种,内存共享。Intel的平台,显存和内存本质都是主存。区别是CPU用的需要MMU映射,GPU用的需要GPU的MMU叫做GTT映射。所以共享内存的方法很简单,把同一个物理页既填到MMU页表里,也填到GTT页表里。具体细节和原理,依照每个人的基础不同,需要看的文档不同。。。
c.为什么是那个固定地址?这个地址学名叫做Aperture空间,就是为了吧显存映射到一个段连续的物理空间。为什么要映射,就是为了显卡可以连续访问一段地址。因为内存是分页的,但是硬件经常需要连续的页。其实还有一个更重要的原因是为了解决叫做tiling的关于图形内存存储形势和不同内存不一致的问题(这个太专业了对于一般人来说)。
这地址的起始地址是平台相关,PC平台一般由固件(BIOS之流)统筹规划总线地址空间之后为显卡特别划分一块。地址区间的大小一般也可以在固件里指定或者配置。
另外,还有一类地址也是高位固定划分的称为stolen memory,这个是x86平台都有的,就是窃取一块物理内存专门为最基本的图形输出使用,比如终端字符显示,framebuffer。起始地址也是固件决定,大小有默认值也可以配置。
d. 刚才说了,Intel的显存内存一回事儿。至于独立显卡有独立显存的平台来回答你这个问题是这样的:任何访存都是通过总线的,直接写也是通过总线写,拷贝也是通过总线拷贝;有时候需要先写入临时内存再拷贝一遍到目标区域,原因很多种;写操作都是通过PCI总线都有延迟,写谁都有。总线就是各个设备共享的资源,需要仲裁之类的机制,肯定有时候要等一下。
>>>Q5. 以上这些知识从哪些书籍上可以获得?
Intel Graphics for Linux*, 从这里看起吧少年。这类过于专业的知识,不建议在一般经验交流的平台求助,很难得到准确的答案。你这类问题,需要的就是准确答案。不然会把本来就不容易理解的问题变得更复杂。


from: https://www.zhihu.com/question/20722310#answer-37937615

















 4873
4873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









