







 本文探讨视频摘要与浓缩技术,涵盖视频摘要的类型、关键技术和应用领域,包括运动目标检测、轨迹跟踪、背景融合及摘要生成算法,旨在提供视频内容的高效浏览和检索方案。
本文探讨视频摘要与浓缩技术,涵盖视频摘要的类型、关键技术和应用领域,包括运动目标检测、轨迹跟踪、背景融合及摘要生成算法,旨在提供视频内容的高效浏览和检索方案。
广义上来说,摘要可以分为2种,第一种是直接提取视频中的关键帧合成新的视频,该方法虽然也可以缩短视频的时长,但是合成后视频给人一种快进看电影的感觉,而且实际使用较少,所用的方法包括SEDIM,SEDIM-IN,CEA,TEA等方法。
这里分享一个修改后的SEDIM程序,效果很好,http://download.csdn.net/detail/qq_14845119/9840872
算法流程如下图所示,
第二种摘要又称视频浓缩,是对视频内容的一个简单概括,以自动或半自动的方式,先通过运动目标分析,提取运动目标,然后对各个目标的运动轨迹进行分析,将不同的目标拼接到一个共同的背景场景中,并将它们以某种方式进行组合。视频摘要在视频分析和基于内容的视频检索中扮演着重要角色。基于浓缩的摘要是实际使用最广的一种。当然包含技术也更多。

video synopsis实现了将多帧视频融合到了1帧,是一种将时间叠加到空间上的转换。将不同时间出现的人物在同一时间显示出来。
主要技术包括:
(1)背景帧建模,生成一张背景图片,包括抽取静止帧,归一化等方法
(2)运动目标检测,包括帧间差,背景建模,混合高斯,等方法
(3)目标轨迹跟踪提取,包括光流,meanshift,camshift,KCF,TLD,STC,staple,multi-cut等方法
(4)轨迹优化算法,保证摘要后同一帧中的目标物尽量不重合或者最小化的减少重合覆盖问题
(5)目标背景融合拼接,包括阿尔法融合,泊松融合等方法
适用范围:本地视频文件,视频中目标物少,但整体视频长,可以收到良好的浓缩效果。
————————————————
视频摘要简介
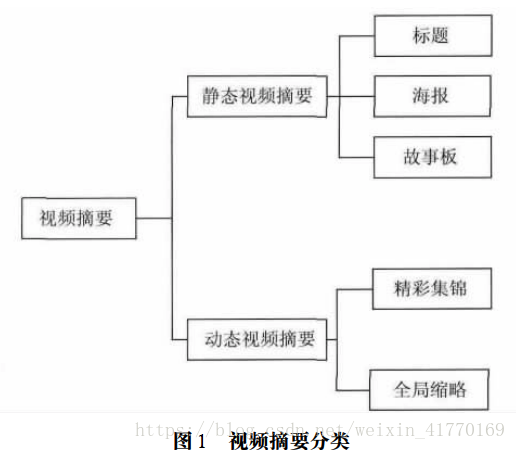
视频摘要分为静态视频摘要和动态视频摘要。静态视频摘要其实不算是视频,是关键帧融合而成。动态视频摘要,是对视频片段进行拼接,本身还是视频。
静态视频摘要主要分为:标题,海报和故事板。标题是视频中的文本检测与分析,构成的文本摘要。海报是关键帧组合。故事板是将结合了标题和海报。
动态视频摘要主要分为:精彩集锦和全局缩略。精彩集锦是指精彩片段,比如整场球赛中识别出进球片段。全局缩略是整个时间轴上的视频片段结合,比如电影的全局缩略,就是为了让用户快速看完,但是尽量不漏掉关键信息。
视频摘要的主要步骤
不管是静态视频摘要还是动态视频摘要,主要步骤都是:内容分析和摘要生成。

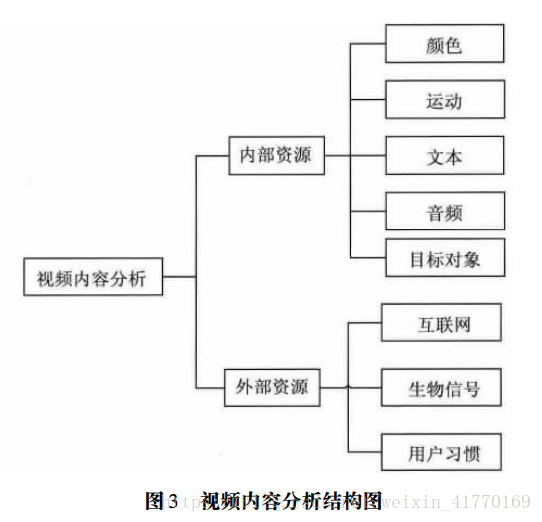
(1)内容分析主要分为:内部资源分析和外部资源分析。
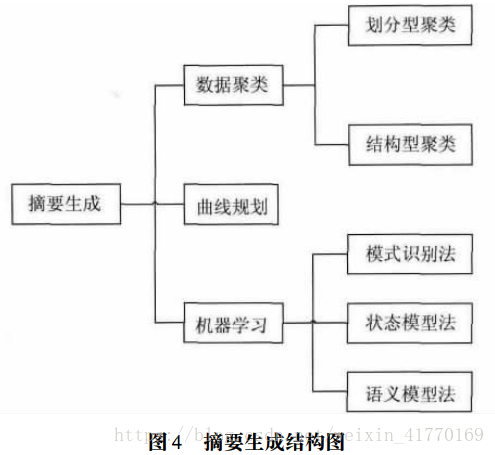
(2)摘要生成:数据聚类、曲线规划(去冗余再聚类串联)、机器学习-模式识别
数据聚类和曲线规划可以实现视频片段的去冗余和聚类,模式识别等可以实现对视频片段的内容理解。
3、视频摘要评价标准:大小、连续性、冗余性、运动强度
QBB应用场景规划
1、通过运动目标检测出视频中的精彩片段,通过音频分析检测出视频中匹配的音频部分,两部分融合切割出好的片段;
2、通过模式识别方法对切割后的视频片段进行场景理解。
这里可以结合用户上传的视频描述,模式识别分类出的视频场景理解结果,音频分析结果综合判定,给出内容描述。
相关paper:
Cycle-SUM:用于无监督视频摘要的周期一致的对抗LSTM网络
Video summarization produces a short summary of a full-length video and ideally encapsulates its most informative parts, alleviates the problem of video browsing, editing and indexing.
Video Summarization with Long Short-term Memory
DeepVideo: Video Summarization using Temporal Sequence Modelling
- intro: CS231n student project report
- paper: http://cs231n.stanford.edu/reports2016/216_Report.pdf
Semantic Video Trailers
Video Summarization using Deep Semantic Features
- inro: ACCV 2016
- arxiv: http://arxiv.org/abs/1609.08758
CNN-Based Prediction of Frame-Level Shot Importance for Video Summarization
- intro: International Conference on new Trends in Computer Sciences (ICTCS), Amman-Jordan, 2017
- arxiv: https://arxiv.org/abs/1708.07023
Video Summarization with Attention-Based Encoder-Decoder Networks
https://arxiv.org/abs/1708.09545
Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity-Representativeness Reward
- intro: AAAI 2018. Chinese Academy of Sciences & Queen Mary University of London
- project page: https://kaiyangzhou.github.io/project_vsumm_reinforce/index.html
- arxiv: https://arxiv.org/abs/1801.00054
- github: https://github.com//KaiyangZhou/vsumm-reinforce
Viewpoint-aware Video Summarization
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1804.02843
DTR-GAN: Dilated Temporal Relational Adversarial Network for Video Summarization
https://arxiv.org/abs/1804.11228
Learning Video Summarization Using Unpaired Data
https://arxiv.org/abs/1805.12174
Video Summarization Using Fully Convolutional Sequence Networks
https://arxiv.org/abs/1805.10538
Video Summarisation by Classification with Deep Reinforcement Learning
- intro: BMVC 2018
- arxiv: https://arxiv.org/abs/1807.03089
Query-Conditioned Three-Player Adversarial Network for Video Summarization
- intro: BMVC 2018
- arxiv: https://arxiv.org/abs/1807.06677
视频浓缩
视频浓缩技术通过对原始监控视频进行一定的分析处理,进而提取出原视频中的关键信息,并且将这些关键信息进行一定规律的组合,生成一段浓缩视频,且该浓缩视频能体现出原始视频中的内容。视频浓缩技术是一种将原视频进行时空压缩的方法,它首先提取原视频中的运动目标,然后对运动目标进行轨迹跟踪和分析,按照一定的轨迹组合方式将不同时刻的运动目标通过一定的图像合成技术拼接到相同的背景图像中,进而形成浓缩视频。该技术可以将几十个小时的监控视频浓缩成十几分钟的视频,而且不丢失原始运动信息,供用户进行浏览和分析。这样的浓缩视频除了减少视频长度,方便浏览,还可以实现对原视频目标的快速检索,帮助用户迅速地锁定感兴趣的目标。
视频摘要概述
参考文献:
1.CVPR2018:HSA-RNN(分层结构自适应的视频摘要方法)
2.AAAI 2017|新加坡信息通信研究院:主动视频摘要生成-通过与用户的在线交互定制摘要
6.有哪些video summarization/highlights方面的数据集?
8.视频摘要技术综述

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









