






查看图片的生成参数
1、打开Stable Diffusion WebUI,点击Tab菜单中的【图像信息/PNG Info】,不同版本的WebUI可能显示的文字或略有不同。
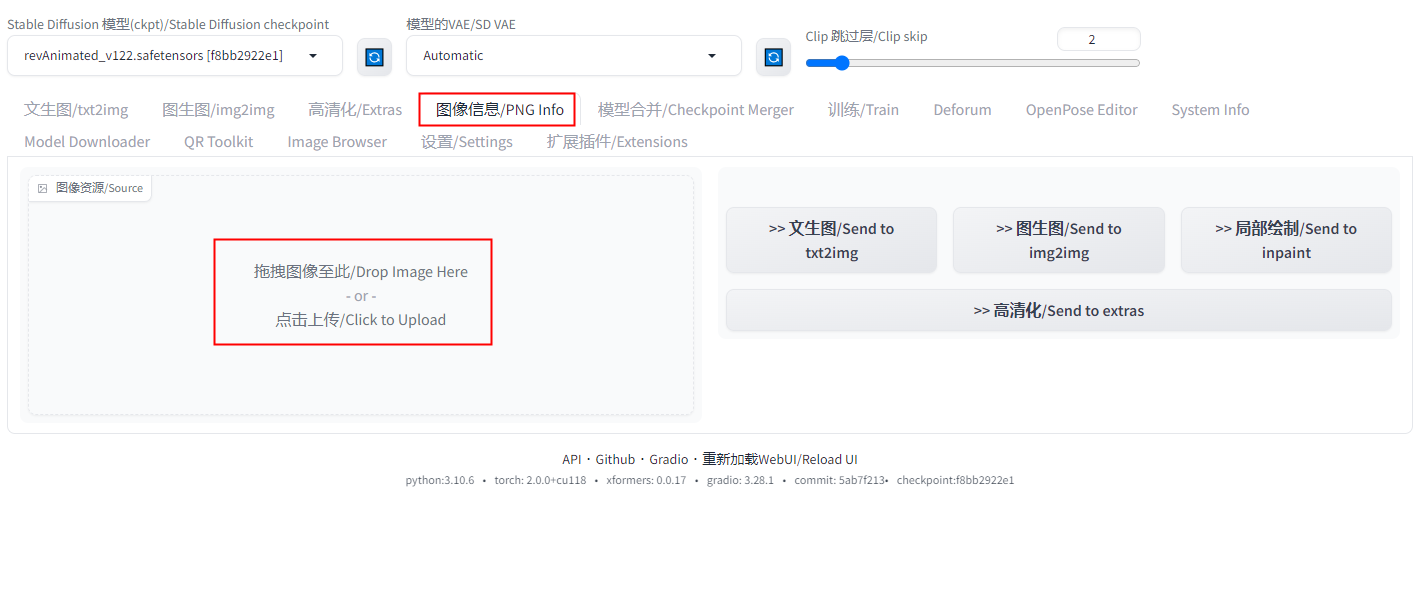
2、在左侧选择本地的一张图片,如果是Stable Diffusion生成的图片,我们可以在右边看到图片的生成参数,依次是:提示词、反向提示词、模型详细参数。

我们还可以在参数的下边看到几个按钮,他们可以把参数或者图片发送到生成窗口,这样可以节省一些复制参数的时间,有兴趣的可以试试。
如果不是SD生成的图片,或者被抹除的信息,我们就什么也得不到:
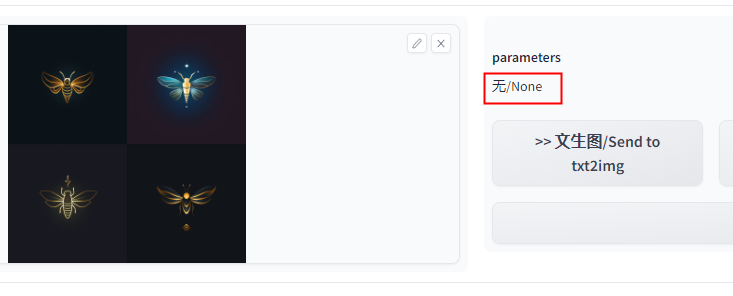
抹除图片的生成参数
这里介绍一个开源的小工具:exifcleaner,地址在:https://github.com/szTheory/exifcleaner/releases
如果你访问Github不方便,也可以从我的网盘下载这个文件,步骤是关注微/信/公/众/号:萤火遛AI,然后发消息:图片参数抹除,即可获得下载地址。
可以看到,它提供了很多操作系统的版本,大家可以选择适合自己的。
我这里直接下载 ExifCleaner-3.6.0.exe 这个Windows免安装版本,启动后界面如图所示:
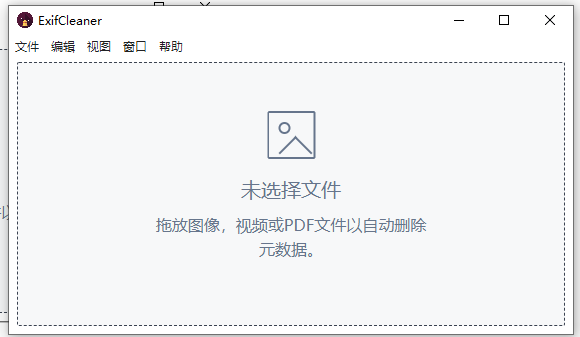
把需要抹除信息的图片拖进去就好了,处理完毕后显示信息如下图所示:
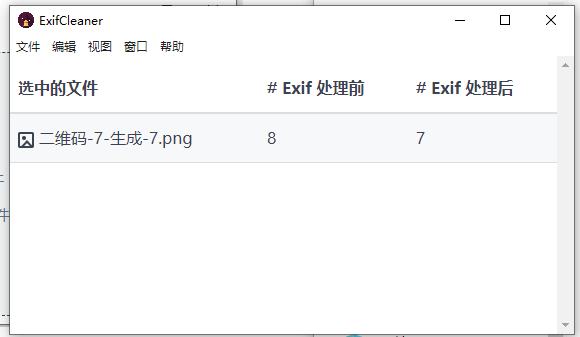
然后我们再次通过Stable Diffusion WebUI读取图片信息,验证相关参数确实被抹除了。

注意:这个处理工具默认是处理完毕后直接替换原来的图片,所以如果你还想保留原来的图片,记得先复制一份。


















 4970
4970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











