









在学习目标检测的过程中,遇到很多含混不清的的概念,记录下来,与大家交流,欢迎留言讨论。
1、目标检测中的 正/负样本:
样本即预测出来的box。Faster R-CNN中的anchor boxes以及SSD中的特征图中的default boxes,这些框中的一部分被选为正样本(正确识别目标),一部分被选为负样本(出现误检),另外一部分被当作背景或者不参与运算。不同的框架有不同的策略,大致筛选策略是根据IOU的值,选取个阈值范围进行判定。two-stage算法会在生成RP阶段保证正:负=1:3,包括YOLO在内的大部分one-stage算法无此环节。
2、目标检测中的(样本)类别不平衡问题:
在训练的过程中要特别注意均衡正负样本之间的比例。 因为,因为负样本占比过大会使得模型的参数迭代方向偏离重心,由“把正要样本正确识别为正样本”偏向为“不把负样本误认为正样本”。one-stage目标检测算法在训练时会将所有框(正负样本)投入训练,因此普遍存在类别不平衡的问题。解释了为什么one-stage算法相比two-stage算法检测精度(mAP)较低。
3、Hard-Negative Mining :
负样本是指相对于正样本,不含有目标的样本。负样本包括很多,有完全不包含目标的的,也有部分含有的,也就是容易/不容易被分为负样本的。其中较容易被判定是负样本(比如全是背景)的对于训练并不能起到很好的监督作用。需要找一些难划分的负样本来增强网络的判别性能。在训练好分类器之后进行分类,但分类器效果不是很好,会得到一些错误的正样本,这个时候这些判别错误的样本可以作为负样本继续训练网络。
3、目标检测中的"训练集类别比例失调"问题:
Yolo算法以在训练数据集中随机抽取组成的一个批次内的所有图片,作为网络迭代一次的依据。某类别图片占比过小,会使得此次迭代对该类效果较小;
4、Confidence(置信度)in YOLO:
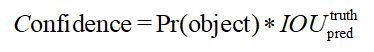
5、Score(类别置信度)in YOLO:
![]()
解释了为什么通过降低thresh,增加的边界框绝大多数类别正确,仅仅是位置不够准确,因为类别精度和置信度无关。
6、Post-Possess(后处理,不参与训练)in YOLO:
(1)“阈值筛选”:针对每个类别的所有边界框的对应score;
(2)“NMS 筛选”:针对所有边界框,保证没有重复的边界框;
(3)“Score 筛选”:针对每个边界框,保证一个框对应一个目标;
(4)“Thresh 筛选”:针对所有边界框,保证定位精度;
出自YOLOv3论文: “We still train on full images with no hard negative mining or any of that stuff”
说明YOLOv3算法不存在负样本筛选的过程,所以在负样本占比过高这一点上仍有改进空间。
7、Anchor in YOLO:
YOLOv3的anchor是通过聚类而固定的,若一开始就选择了更好的、更有代表性的先验 Anchor Boxes,那么网络就更容易学到准确的预测位置。 Faster R-CNN 中 Anchor Box 的大小和比例是按经验设定的,然后网络会在训练过程中调整 Anchor Box 的尺寸。说明在Anchor的设置上仍有改进空间。
9、Two-Stage in Detection:
两阶段方法包括两部分:第一部分(例如:Selective Search,RPN )生成一个稀疏的region proposal集合,第二部分进一步分类和回归,使用卷积网络确定准确的对象区域和相应的类别标签。

8、one-stage in Detection:
YOLO 使用单个前馈卷积网络直接预测对象类和位置。 SSD 方法在多个 ConvNet 层扩展了不同尺度的 固定的anchors,强制每个层专注于预测确定的尺寸对象。 YOLOv2 添加所有卷积层上的批量标准化,使用带 anchor boxes 的卷积层替代全FC层来预测 bounding boxes 等。YOLOv3引入resnet、FPN同时增加anchor boxes的数目。YOLO系算法将所有样本投入迭代训练。














 2384
2384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









