






 本文探讨了大模型部署在设备、推理和服务层面的挑战,提出技术方案如量化、PageAttention等,并重点介绍LMDeploy的轻量化、TurboMind推理引擎和量化方法,以及安装、部署和最佳实践指南。
本文探讨了大模型部署在设备、推理和服务层面的挑战,提出技术方案如量化、PageAttention等,并重点介绍LMDeploy的轻量化、TurboMind推理引擎和量化方法,以及安装、部署和最佳实践指南。
一、大模型部署的背景
大模型部署面临着一些挑战:
1. 设备上的挑战:在手机终端上推大模型存储和加载速度慢,没有互联网时部署困难。
2. 推理上的挑战:推理是输入输出的过程,需要提高生成速度和效率,解决动态推理问题。
3. 服务方面的挑战:需要提高服务的吞吐量和平均响应时长,来解决个体用户的响应时间问题。

可行的解决方案:
1. 技术方案:模型并行、低比特量化、Page Attention、transformer的缓存优化和计算优化等。
2. 云端方案:使用专用的框架和算法,如deepspeed、tensorrt-llm、vllm和LMdeploy等。移动端方案:llama.cpp和mlc-llm等。
二、LMDeploy部署
LMDeploy是llm在英伟达设备上部署的全流程解决方案,包括轻量化、推理和服务。
1. 轻量化包括4bit和8bit量化。
2. 推理支持推理引擎,如turbomind和pytorch。
3. 服务如API server、gradio、triton service等。

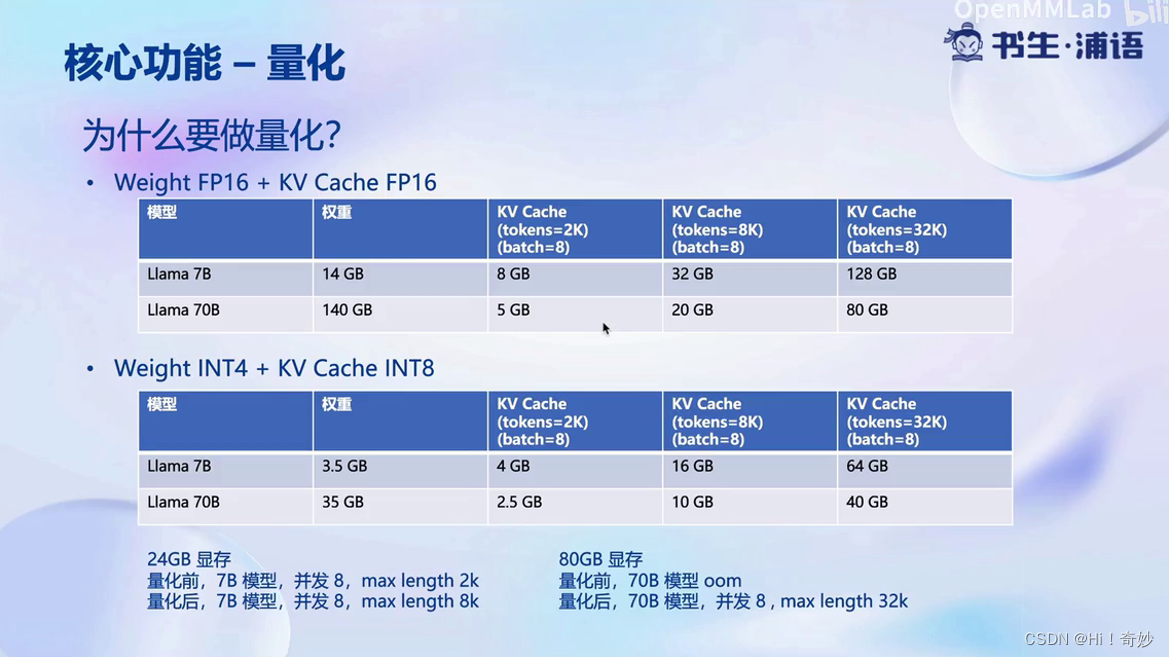
1、量化
量化是该系统的核心功能之一,可以提高显存利用率并增加并发能力,可以使模型的长度增加,从而提高推理速度。

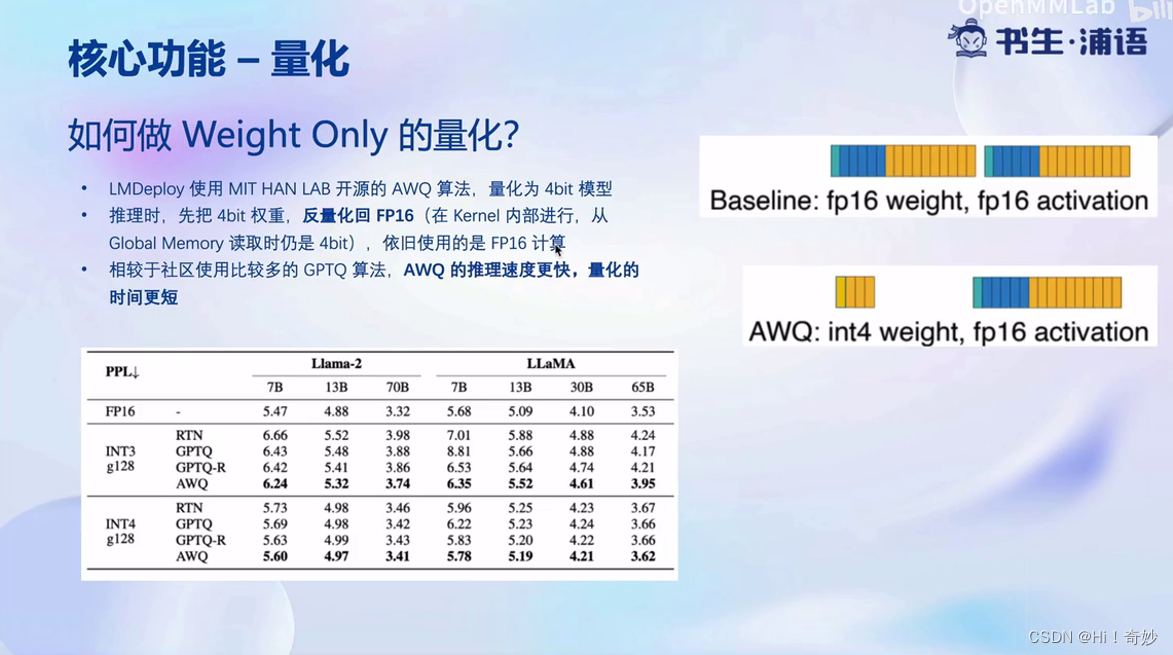
AWQ算法:在矩阵或模型推理过程中,一部分参数是非常重要的,可以不量化这些参数,只量化其他参数,从而最大化性能和减少显存。
2、TurboMind
TurboMind的优势:
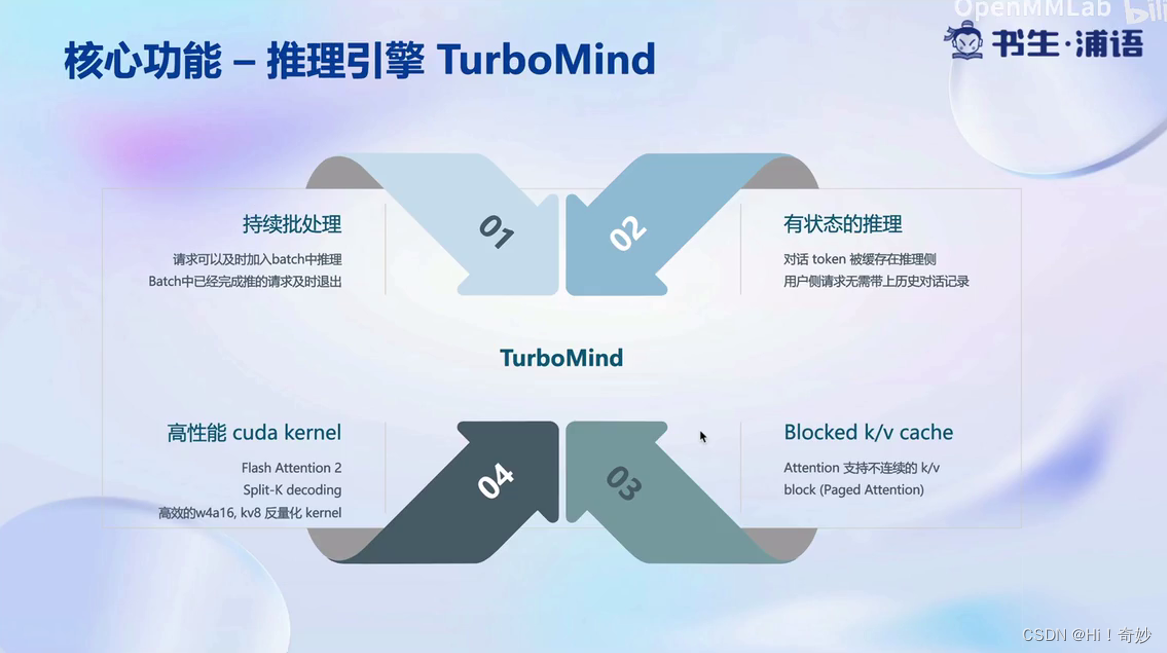
持续批处理是指将请求放入队列中,并按照时间轴进行处理。

大模型动态设计与推理服务:
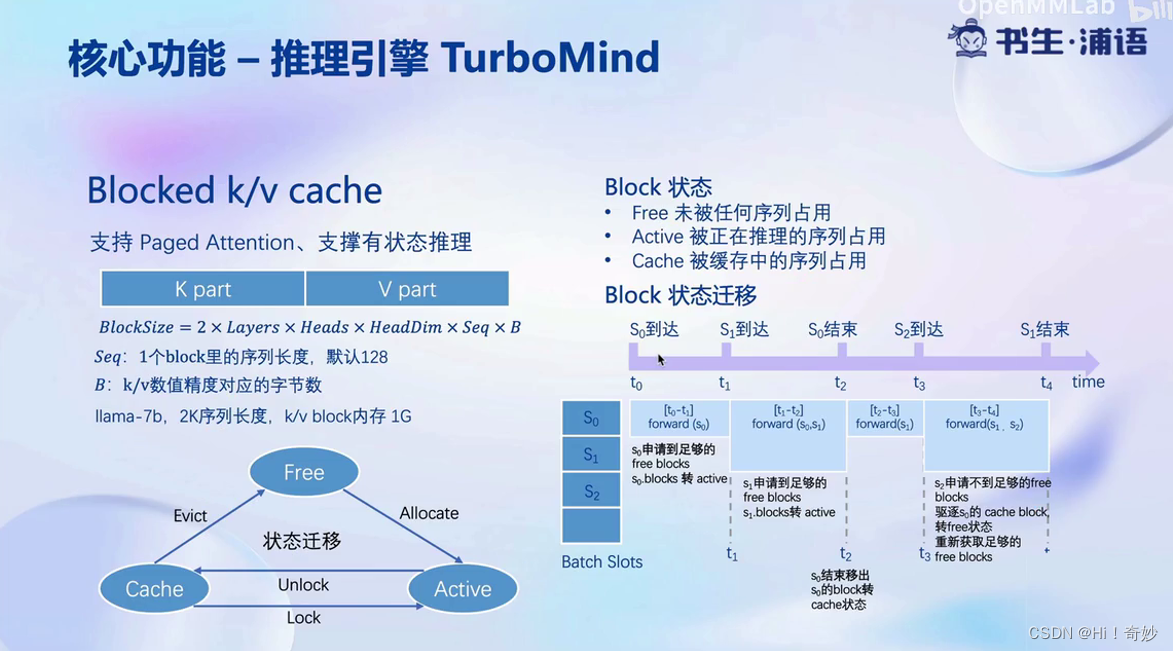
有状态的推理是指服务端将token和KV的block缓存起来,以减少显存。
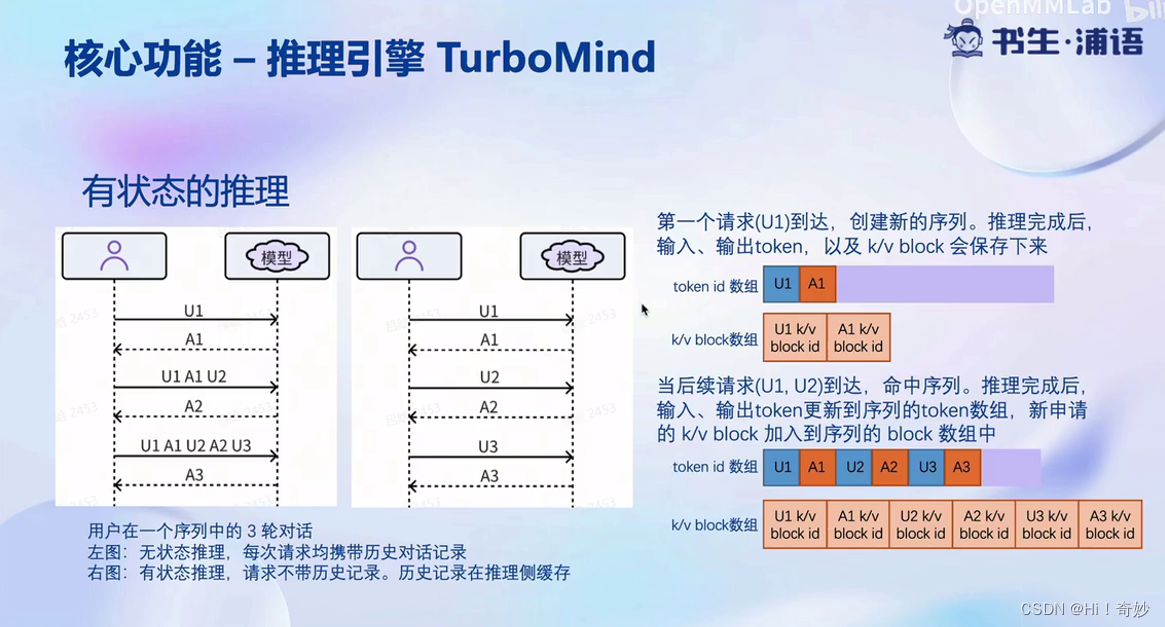
KV是指在attention或生成过程中,使用历史的KV信息,进行分块的方式达到缓存的目的。
三、安装、部署和量化
1. 环境配置:安装LMdeploy。
2. 服务部署:包括在线转换和离线转换两种方式。
3. 推理引擎:使用TurboMind作为核心推理引擎,提供API服务和代码集成等。
4. 最佳实践:介绍了使用方式和推荐的最佳实践。
5. 模型量化:KV Cashe量化和W4A16量化。
(参考tutorial/lmdeploy/lmdeploy.md at main · InternLM/tutorial (github.com),按部就班做下去,基本都会成功)

















 2899
2899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









