







 文章详细介绍了Linux内核中buffer_head数据结构的历史演变,以及它在当前系统中如何与bio共同管理I/O操作。buffer_head主要用于映射磁盘块到内存页,跟踪状态,并在页内管理多个块。在写入操作中,buffer_head的脏标志用于标记需要写回的数据。当写入完成后,buffer头的脏标志会在提交给块层时清除。
文章详细介绍了Linux内核中buffer_head数据结构的历史演变,以及它在当前系统中如何与bio共同管理I/O操作。buffer_head主要用于映射磁盘块到内存页,跟踪状态,并在页内管理多个块。在写入操作中,buffer_head的脏标志用于标记需要写回的数据。当写入完成后,buffer头的脏标志会在提交给块层时清除。
内核版本:5.9.0
数据结构
/*
* Historically, a buffer_head was used to map a single block
* within a page, and of course as the unit of I/O through the
* filesystem and block layers. Nowadays the basic I/O unit
* is the bio, and buffer_heads are used for extracting block
* mappings (via a get_block_t call), for tracking state within
* a page (via a page_mapping) and for wrapping bio submission
* for backward compatibility reasons (e.g. submit_bh).
*/
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head *b_this_page;/* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */
size_t b_size; /* size of mapping,等于block size */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
atomic_t b_count; /* users using this buffer_head */
spinlock_t b_uptodate_lock; /* Used by the first bh in a page, to
* serialise IO completion of other
* buffers in the page */
};历史上:buffer_head用来将一个单独的block映射到一个page,一般80x86体系结构上,根据block size大小,一个page可以包含1-8个block,比如如果block size = 1K,那么一个缓存page缓存4个block,且buffer_head是文件系统和block layer的io基本单位。
现在:bio取代了buffer_head作为io基本单位。
buffer_head和page关系
假设page size = 4K, block size = 1K
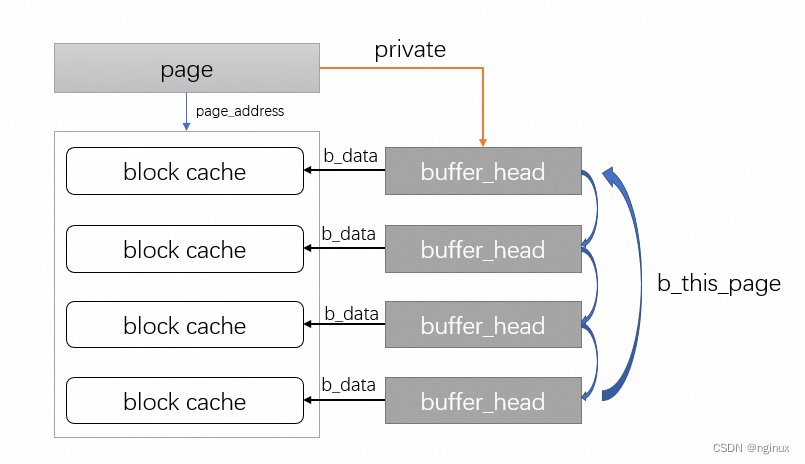
- 一个4K page可以缓存4个1K的block, 每一个block通过buffer_head描述,这四个buffer_head通过b_this_page单向连接。
- buffer_head中的b_data指向对应的缓冲区地址。注意:如果page是high mem,b_data存放的缓冲区业内的偏移量,比如第一个缓冲区b_data = 0,第二个是1K,第三个是2K。如果page在非high mem,b_data指向对应缓冲区的虚拟地址。
- page中的private指向第一个buffer_head
数据结构构建的代码
fs/buffer.c :
//创建page的buffer_head
static struct buffer_head *create_page_buffers(struct page *page, struct inode *inode, unsigned int b_state)
{
BUG_ON(!PageLocked(page));
//inode->i_blkbits是用bit表示的块大小,比如block size = 4K, i_blkbits = 12;
//create_empty_buffers进行真正的创建逻辑。
if (!page_has_buffers(page))
create_empty_buffers(page, 1 << READ_ONCE(inode->i_blkbits),
b_state);
//返回page->private,即首个buffer_head
return page_buffers(page);
}
/* If we *know* page->private refers to buffer_heads */
#define page_buffers(page) \
({ \
BUG_ON(!PagePrivate(page)); \
((struct buffer_head *)page_private(page)); \
})
#define page_has_buffers(page) PagePrivate(page)
/*
* We attach and possibly dirty the buffers atomically wrt
* __set_page_dirty_buffers() via private_lock. try_to_free_buffers
* is already excluded via the page lock.
*/
void create_empty_buffers(struct page *page,
unsigned long blocksize, unsigned long b_state)
{
struct buffer_head *bh, *head, *tail;
//真正的buffer_head创建函数,返回首个buffer_head
head = alloc_page_buffers(page, blocksize, true);
bh = head;
//tail指向最后一个buffer_head,将首个和最后一个buffer_head连接
do {
bh->b_state |= b_state;
tail = bh;
bh = bh->b_this_page;
} while (bh);
tail->b_this_page = head;
spin_lock(&page->mapping->private_lock);
if (PageUptodate(page) || PageDirty(page)) {
bh = head;
do {
if (PageDirty(page))
set_buffer_dirty(bh);
if (PageUptodate(page))
set_buffer_uptodate(bh);
bh = bh->b_this_page;
} while (bh != head);
}
//设置page->private指向首个buffer_head
attach_page_private(page, head);
spin_unlock(&page->mapping->private_lock);
}
struct buffer_head *alloc_page_buffers(struct page *page, unsigned long size,
bool retry)
{
struct buffer_head *bh, *head;
gfp_t gfp = GFP_NOFS | __GFP_ACCOUNT;
long offset;
struct mem_cgroup *memcg;
if (retry)
gfp |= __GFP_NOFAIL;
memcg = get_mem_cgroup_from_page(page);
memalloc_use_memcg(memcg);
head = NULL;
offset = PAGE_SIZE;
//当前场景offset = 4K size = 1K
while ((offset -= size) >= 0) {
bh = alloc_buffer_head(gfp);
if (!bh)
goto no_grow;
bh->b_this_page = head;
bh->b_blocknr = -1;
head = bh;
bh->b_size = size;
/* Link the buffer to its page */
set_bh_page(bh, page, offset);
}
out:
memalloc_unuse_memcg();
mem_cgroup_put(memcg);
return head;
/*
* In case anything failed, we just free everything we got.
*/
no_grow:
if (head) {
do {
bh = head;
head = head->b_this_page;
free_buffer_head(bh);
} while (head);
}
goto out;
}
/**
* attach_page_private - Attach private data to a page.
* @page: Page to attach data to.
* @data: Data to attach to page.
*
* Attaching private data to a page increments the page's reference count.
* The data must be detached before the page will be freed.
*/
static inline void attach_page_private(struct page *page, void *data)
{
get_page(page);
set_page_private(page, (unsigned long)data);
SetPagePrivate(page);
}buffer_head的状态b_state
enum bh_state_bits {
BH_Uptodate, /* Contains valid data */
BH_Dirty, /* Is dirty */
BH_Lock, /* Is locked */
BH_Req, /* Has been submitted for I/O */
BH_Mapped, /* Has a disk mapping */
BH_New, /* Disk mapping was newly created by get_block */
BH_Async_Read, /* Is under end_buffer_async_read I/O */
BH_Async_Write, /* Is under end_buffer_async_write I/O */
BH_Delay, /* Buffer is not yet allocated on disk */
BH_Boundary, /* Block is followed by a discontiguity */
BH_Write_EIO, /* I/O error on write */
BH_Unwritten, /* Buffer is allocated on disk but not written */
BH_Quiet, /* Buffer Error Prinks to be quiet */
BH_Meta, /* Buffer contains metadata */
BH_Prio, /* Buffer should be submitted with REQ_PRIO */
BH_Defer_Completion, /* Defer AIO completion to workqueue */
BH_PrivateStart,/* not a state bit, but the first bit available
* for private allocation by other entities
*/
};BH_Uptodate : 内核注释是“valid data",所谓的有效数据是说buffer_head中数据或者跟磁盘数据相同,或者说buffer_head包含了最新的需要写回磁盘的数据。所以BH_Uptodate不能错误的认为buffer_head中数据跟磁盘数据相等。
BH_Dirty : 缓冲区数据更新,跟磁盘文件不同,必须写回块设备。
BH_Lock : 加锁,通常是缓冲区正在进行磁盘传输。
BH_Req : 提交io请求。
BH_Mapped : 缓冲区和磁盘已映射,即buffer_head中b_bdev和b_blocknr已设置(比如调用了ext4_get_block完成了映射)。
BH_New : 磁盘映射刚刚创建。
b_state相关函数 include/linux/buffer_head.h
/*
* macro tricks to expand the set_buffer_foo(), clear_buffer_foo()
* and buffer_foo() functions.
* To avoid reset buffer flags that are already set, because that causes
* a costly cache line transition, check the flag first.
*/
#define BUFFER_FNS(bit, name) \
static __always_inline void set_buffer_##name(struct buffer_head *bh) \
{ \
if (!test_bit(BH_##bit, &(bh)->b_state)) \
set_bit(BH_##bit, &(bh)->b_state); \
} \
static __always_inline void clear_buffer_##name(struct buffer_head *bh) \
{ \
clear_bit(BH_##bit, &(bh)->b_state); \
} \
static __always_inline int buffer_##name(const struct buffer_head *bh) \
{ \
return test_bit(BH_##bit, &(bh)->b_state); \
}
/*
* test_set_buffer_foo() and test_clear_buffer_foo()
*/
#define TAS_BUFFER_FNS(bit, name) \
static __always_inline int test_set_buffer_##name(struct buffer_head *bh) \
{ \
return test_and_set_bit(BH_##bit, &(bh)->b_state); \
} \
static __always_inline int test_clear_buffer_##name(struct buffer_head *bh) \
{ \
return test_and_clear_bit(BH_##bit, &(bh)->b_state); \
} \
/*
* Emit the buffer bitops functions. Note that there are also functions
* of the form "mark_buffer_foo()". These are higher-level functions which
* do something in addition to setting a b_state bit.
*/
BUFFER_FNS(Uptodate, uptodate)
BUFFER_FNS(Dirty, dirty)
TAS_BUFFER_FNS(Dirty, dirty)
BUFFER_FNS(Lock, locked)
BUFFER_FNS(Req, req)
TAS_BUFFER_FNS(Req, req)
BUFFER_FNS(Mapped, mapped)
BUFFER_FNS(New, new)
BUFFER_FNS(Async_Read, async_read)
BUFFER_FNS(Async_Write, async_write)
BUFFER_FNS(Delay, delay)
BUFFER_FNS(Boundary, boundary)
BUFFER_FNS(Write_EIO, write_io_error)
BUFFER_FNS(Unwritten, unwritten)
BUFFER_FNS(Meta, meta)
BUFFER_FNS(Prio, prio)
BUFFER_FNS(Defer_Completion, defer_completion)是不是每次读取文件page都有buffer_head?
并不是,内核page_has_buffers函数可以判断page是否有buffer_head,典型的使用buffer_head的场景是磁盘数据不连续的情况,假设一个page 4K, block size = 1K,所以一个page中可以存储4个block数据,而4个block数据可能并不连续,这种情况会调用block_read_full_page每次读取一个块来填充page,每个块会分配一个buffer_head。
假设读取的数据磁盘上是连续的,那么直接使用bio更为高效,这种情况下page->private = NULL,也就是没有使用buffer_head。所以ext4_mpage_readpages函数一个重要功能就是处理磁盘数据连续和不连续的情况,不连续就会调用block_read_full_page。
写数据场景buffer_head bh_state状态
我们来考虑一个场景,write(fd, "abc", sizeof("abc"),向某个文件末尾写入"abc"字符,假设block size 4K,那么一个page中只有一个buffer缓冲区,一个buffer_head指向,写入的abc前再假设这个page's buffer_head的bh_state是mapped,且page cache依然在address space树中,那么此时调用write写入字符是cp到page cache即可,但同时要把inode标志成dirty,同时buffer_head的bh_state也要置位置dirty,这个逻辑是在哪里实现的?write_end的时候,调用栈:
#0 __block_commit_write (page=0xffffea00000c67c0, from=<optimized out>, to=<optimized out>, inode=<optimized out>) at fs/buffer.c:2086
#1 0xffffffff8148276e in block_write_end (file=<optimized out>, mapping=<optimized out>, pos=<optimized out>, len=<optimized out>, copied=<optimized out>, page=<optimized out>, fsdata=0x0 <fixed_percpu_data>)
at fs/buffer.c:2162
#2 0xffffffff81482862 in generic_write_end (file=<optimized out>, mapping=0xffff888006250bc0, pos=6859, len=<optimized out>, copied=<optimized out>, page=0xffffea00000c67c0, fsdata=0x0 <fixed_percpu_data>)
at fs/buffer.c:2176
#3 0xffffffff815617cf in ext4_da_write_end (file=<optimized out>, mapping=0xffff888006250bc0, pos=<optimized out>, len=103090608, copied=80, page=<optimized out>, fsdata=0x0 <fixed_percpu_data>)
at fs/ext4/inode.c:3091
#4 0xffffffff8132c008 in generic_perform_write (file=<optimized out>, i=<optimized out>, pos=6859) at mm/filemap.c:3516
#5 0xffffffff8153eb9c in ext4_buffered_write_iter (iocb=0xffff888004567d90, from=0xffff888004567d30) at fs/ext4/file.c:269
#6 0xffffffff8153ed7a in ext4_file_write_iter (iocb=0xffff888004567d90, from=<optimized out>) at fs/ext4/file.c:660
#7 0xffffffff8140eae2 in call_write_iter (file=<optimized out>, iter=<optimized out>, kio=<optimized out>) at ./include/linux/fs.h:1882
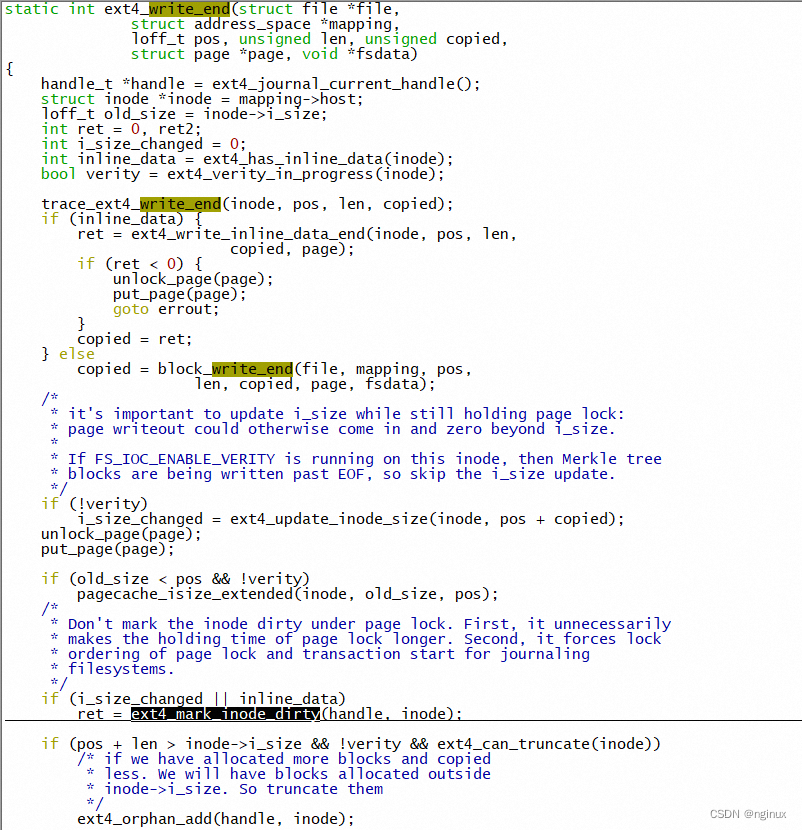
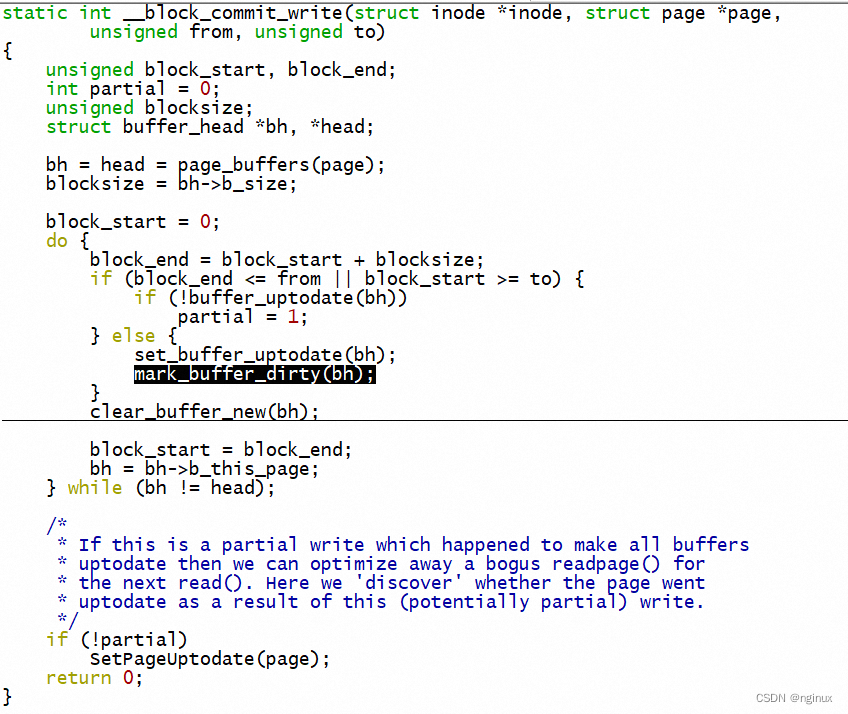
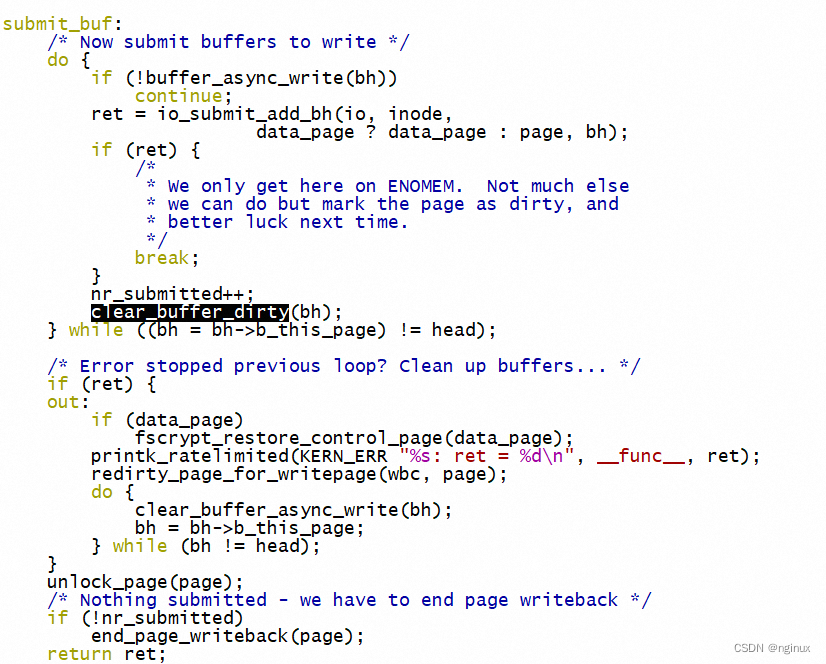
上述写文件场景,buffer_head的dirty标志是什么时候clear的?
bh提交给block layer时候就清理掉了(所以并不是要等writeback完成),代码fs/ext4/page-io.c : ext4_bio_write_page:
参考文章:


















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









