







PRML学习总结(10)——Approximate Inference
在有些情况下,精确推断是难以实现,只能寻求近似推断,根据近似⽅法依赖于随机近似还是确定近似,⽅法⼤体分为两⼤类。随机⽅法,例如第11章介绍的马尔科夫链蒙特卡罗⽅法,使得贝叶斯⽅法能够在许多领域中⼴泛使⽤。这些⽅法通常具有这样的性质:给定⽆限多的计算资源,它们可以⽣成精确的结果,近似的来源是使⽤了有限的处理时间。在实际应⽤中,取样⽅法需要的计算量会相当⼤,经常将这些⽅法的应⽤限制在了⼩规模的问题中。并且,判断⼀种取样⽅法是否⽣成了服从所需的概率分布的独⽴样本是很困难的。
本章中,我们介绍了⼀系列的确定性近似⽅法,有些⽅法对于⼤规模的数据很适⽤。这些⽅法基于对后验概率分布的解析近似,例如通过假设后验概率分布可以通过⼀种特定的⽅式分解,或者假设后验概率分布有⼀个具体的参数形式,例如⾼斯分布。对于这种情况,这些⽅法永远⽆法⽣成精确的解,因此这些⽅法的优点和缺点与取样⽅法是互补的。
10.1 Variational Inference
假设我们有⼀个纯粹的贝叶斯模型,其中每个参数都有⼀个先验概率分布。这个模型也可以有潜在变量以及参数,我们会把所有潜在变量和参数组成的集合记作
Z
\mathbf Z
Z。类似地,我们会把所有观测变量的集合记作
X
\mathbf X
X。例如,我们可能有
N
N
N个独⽴同分布的数据,其中
X
=
{
x
1
,
…
,
x
N
}
\mathbf{X}=\left\{\mathbf{x}_{1}, \dots, \mathbf{x}_{N}\right\}
X={x1,…,xN}且
Z
=
{
z
1
,
…
,
z
N
}
\mathbf{Z}=\left\{\mathbf{z}_{1}, \dots, \mathbf{z}_{N}\right\}
Z={z1,…,zN}。我们的概率模型确定了联合分布
p
(
X
,
Z
)
p(\mathbf{X}, \mathbf{Z})
p(X,Z),我们的目标是寻找后验分布
p
(
Z
∣
X
)
p(\mathbf{Z}|\mathbf{X})
p(Z∣X)和模型evidence
p
(
X
)
p(\mathbf{X})
p(X)的近似分布,之前在EM算法中介绍了
ln
p
(
X
)
=
L
(
q
)
+
K
L
(
q
∥
p
)
\ln p(\mathbf{X})=\mathcal{L}(q)+\mathrm{KL}(q \| p)
lnp(X)=L(q)+KL(q∥p)其中
L
(
q
)
=
∫
q
(
Z
)
ln
{
p
(
X
,
Z
)
q
(
Z
)
}
d
Z
K
L
(
q
∥
p
)
=
−
∫
q
(
Z
)
ln
{
p
(
Z
∣
X
)
q
(
Z
)
}
d
Z
\begin{aligned} \mathcal{L}(q) &=\int q(\mathbf{Z}) \ln \left\{\frac{p(\mathbf{X}, \mathbf{Z})}{q(\mathbf{Z})}\right\} \mathrm{d} \mathbf{Z} \\ \mathrm{KL}(q \| p) &=-\int q(\mathbf{Z}) \ln \left\{\frac{p(\mathbf{Z} | \mathbf{X})}{q(\mathbf{Z})}\right\} \mathrm{d} \mathbf{Z} \end{aligned}
L(q)KL(q∥p)=∫q(Z)ln{q(Z)p(X,Z)}dZ=−∫q(Z)ln{q(Z)p(Z∣X)}dZ与EM不同的是,参数
θ
\boldsymbol \theta
θ一起包括在
Z
\mathbf Z
Z中。和之前的分析一样,当最大化lower bound
L
(
q
)
\mathcal{L}(q)
L(q)时,就是在最小化KL部分,也就是说,当
q
(
Z
)
q(\mathbf Z)
q(Z)足够自由时,KL部分就会消失,从而
q
(
Z
)
=
p
(
Z
∣
X
)
q(\mathbf Z)=p(\mathbf Z|\mathbf X)
q(Z)=p(Z∣X)。但是现在我们考虑的模型十分复杂,真是后验是没法计算的。于是,我们转⽽考虑概率分布
q
(
Z
)
q(\mathbf Z)
q(Z)的⼀个受限制的类别,然后寻找这个类别中使得KL散度达到最⼩值的概率分布。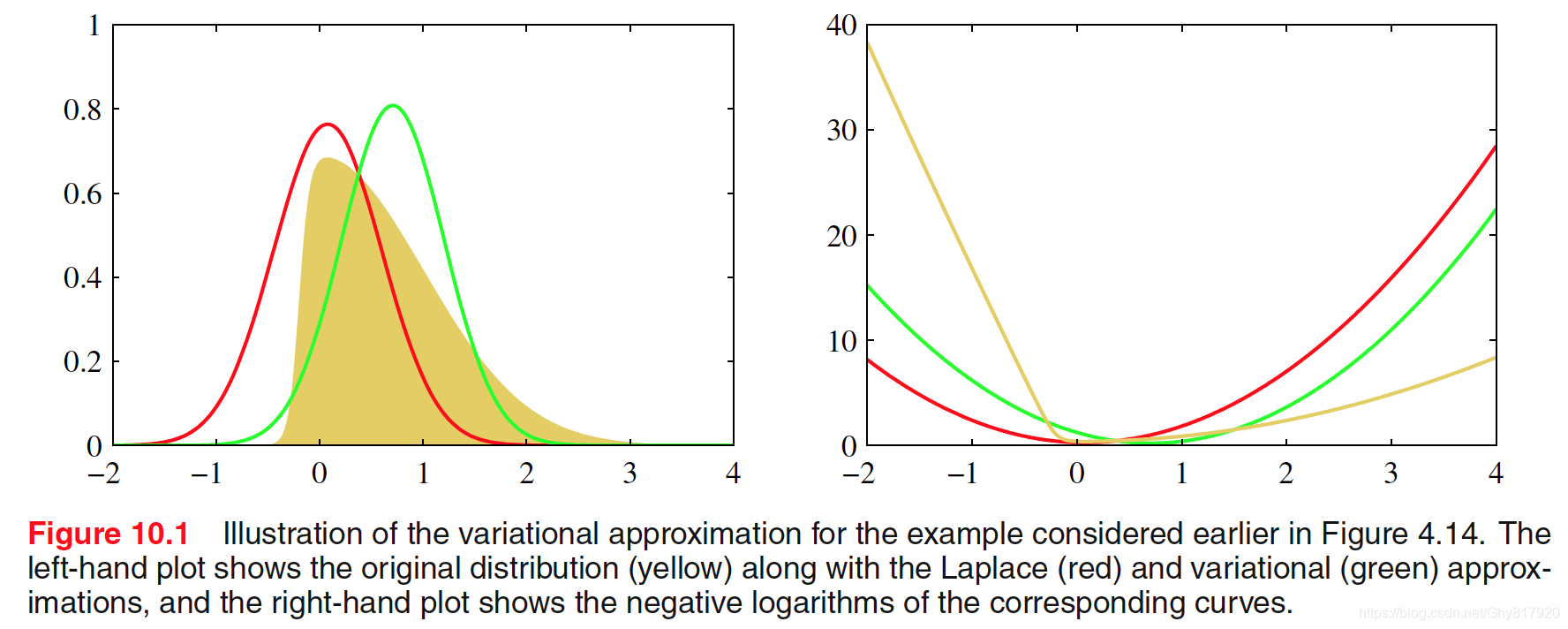
10.1.1 Factorized distributions
下面介绍一种平均场理论,也就是将 q ( Z ) q(\mathbf Z) q(Z)分解为 q ( Z ) = ∏ i = 1 M q i ( Z i ) q(\mathbf{Z})=\prod_{i=1}^{M} q_{i}\left(\mathbf{Z}_{i}\right) q(Z)=i=1∏Mqi(Zi)在这种分解的限制下,优化ELBO,只考虑 q j q_{j} qj L ( q ) = ∫ ∏ i q i { ln p ( X , Z ) − ∑ i ln q i } d Z = ∫ q j { ∫ ln p ( X , Z ) ∏ i ≠ j q i d Z i } d Z j − ∫ q j ln q j d Z j + const = ∫ q j ln p ~ ( X , Z j ) d Z j − ∫ q j ln q j d Z j + const \begin{aligned} \mathcal{L}(q) &=\int \prod_{i} q_{i}\left\{\ln p(\mathbf{X}, \mathbf{Z})-\sum_{i} \ln q_{i}\right\} \mathrm{d} \mathbf{Z} \\ &=\int q_{j}\left\{\int \ln p(\mathbf{X}, \mathbf{Z}) \prod_{i \neq j} q_{i} \mathrm{d} \mathbf{Z}_{i}\right\} \mathrm{d} \mathbf{Z}_{j}-\int q_{j} \ln q_{j} \mathrm{d} \mathbf{Z}_{j}+\text { const } \\ &=\int q_{j} \ln \widetilde{p}\left(\mathbf{X}, \mathbf{Z}_{j}\right) \mathrm{d} \mathbf{Z}_{j}-\int q_{j} \ln q_{j} \mathrm{d} \mathbf{Z}_{j}+\text { const } \end{aligned} L(q)=∫i∏qi{lnp(X,Z)−i∑lnqi}dZ=∫qj⎩⎨⎧∫lnp(X,Z)i̸=j∏qidZi⎭⎬⎫dZj−∫qjlnqjdZj+ const =∫qjlnp (X,Zj)dZj−∫qjlnqjdZj+ const 当我们固定 { q i ≠ j } \left\{q_{i \neq j}\right\} {qi̸=j}时,可以发现最大ELBO就是在 q j ( Z j ) = p ~ ( X , Z j ) q_{j}\left(\mathbf{Z}_{j}\right)=\widetilde{p}\left(\mathbf{X}, \mathbf{Z}_{j}\right) qj(Zj)=p (X,Zj)。 ln q j ⋆ ( Z j ) = E i ≠ j [ ln p ( X , Z ) ] + const. \ln q_{j}^{\star}\left(\mathbf{Z}_{j}\right)=\mathbb{E}_{i \neq j}[\ln p(\mathbf{X}, \mathbf{Z})]+\text { const. } lnqj⋆(Zj)=Ei̸=j[lnp(X,Z)]+ const. 注意的是,const就是一个配比因子,归一化。 q j ⋆ ( Z j ) = exp ( E i ≠ j [ ln p ( X , Z ) ] ) ∫ exp ( E i ≠ j [ ln p ( X , Z ) ] ) d Z j q_{j}^{\star}\left(\mathbf{Z}_{j}\right)=\frac{\exp \left(\mathbb{E}_{i \neq j}[\ln p(\mathbf{X}, \mathbf{Z})]\right)}{\int \exp \left(\mathbb{E}_{i \neq j}[\ln p(\mathbf{X}, \mathbf{Z})]\right) \mathrm{d} \mathbf{Z}_{j}} qj⋆(Zj)=∫exp(Ei̸=j[lnp(X,Z)])dZjexp(Ei̸=j[lnp(X,Z)])得到这样的结果,我们就可以采用迭代的方式得到最终结果。
10.1.2 Properties of factorized approximations
我们的变分推断的⽅法基于的是真实后验概率分布的分解近似。让我们现在考虑⼀下使⽤分解概率分布的⽅式近似⼀个⼀般的概率分布的问题。⾸先,我们讨论使⽤分解的⾼斯分布近似⼀个⾼斯分布的问题,这会让我们认识到在使⽤分解近似时会引⼊的不准确性有哪些类型。需要近似的二维高斯分布为
p
(
z
)
=
N
(
z
∣
μ
,
Λ
−
1
)
p(\mathbf{z})=\mathcal{N}\left(\mathbf{z} | \boldsymbol{\mu}, \mathbf{\Lambda}^{-1}\right)
p(z)=N(z∣μ,Λ−1),利用
q
(
z
)
=
q
1
(
z
1
)
q
2
(
z
2
)
q(\mathbf{z})=q_{1}\left(z_{1}\right) q_{2}\left(z_{2}\right)
q(z)=q1(z1)q2(z2)近似它。
ln
q
1
⋆
(
z
1
)
=
E
z
2
[
ln
p
(
z
)
]
+
const
=
E
z
2
[
−
1
2
(
z
1
−
μ
1
)
2
Λ
11
−
(
z
1
−
μ
1
)
Λ
12
(
z
2
−
μ
2
)
]
+
c
o
n
s
t
=
−
1
2
z
1
2
Λ
11
+
z
1
μ
1
Λ
11
−
z
1
Λ
12
(
E
[
z
2
]
−
μ
2
)
+
const.
\begin{aligned} \ln q_{1}^{\star}\left(z_{1}\right) &=\mathbb{E}_{z_{2}}[\ln p(\mathbf{z})]+\text { const } \\ &=\mathbb{E}_{z_{2}}\left[-\frac{1}{2}\left(z_{1}-\mu_{1}\right)^{2} \Lambda_{11}-\left(z_{1}-\mu_{1}\right) \Lambda_{12}\left(z_{2}-\mu_{2}\right)\right]+\mathrm{const} \\ &=-\frac{1}{2} z_{1}^{2} \Lambda_{11}+z_{1} \mu_{1} \Lambda_{11}-z_{1} \Lambda_{12}\left(\mathbb{E}\left[z_{2}\right]-\mu_{2}\right)+\text { const. } \end{aligned}
lnq1⋆(z1)=Ez2[lnp(z)]+ const =Ez2[−21(z1−μ1)2Λ11−(z1−μ1)Λ12(z2−μ2)]+const=−21z12Λ11+z1μ1Λ11−z1Λ12(E[z2]−μ2)+ const. 上式的右边刚好关于
z
1
z_1
z1的二次函数,则说明
q
⋆
(
z
1
)
q^{\star}\left(z_{1}\right)
q⋆(z1)刚好也是高斯分布,需要说明的是,平均场理论,我们并没有规定各个分解后的分布的类型,这儿就能推出分布是个什么类型。
q
⋆
(
z
1
)
=
N
(
z
1
∣
m
1
,
Λ
11
−
1
)
q^{\star}\left(z_{1}\right)=\mathcal{N}\left(z_{1} | m_{1}, \Lambda_{11}^{-1}\right)
q⋆(z1)=N(z1∣m1,Λ11−1)其中
m
1
=
μ
1
−
Λ
11
−
1
Λ
12
(
E
[
z
2
]
−
μ
2
)
m_{1}=\mu_{1}-\Lambda_{11}^{-1} \Lambda_{12}\left(\mathbb{E}\left[z_{2}\right]-\mu_{2}\right)
m1=μ1−Λ11−1Λ12(E[z2]−μ2)同理可得
q
2
⋆
(
z
2
)
=
N
(
z
2
∣
m
2
,
Λ
22
−
1
)
q_{2}^{\star}\left(z_{2}\right)=\mathcal{N}\left(z_{2} | m_{2}, \Lambda_{22}^{-1}\right)
q2⋆(z2)=N(z2∣m2,Λ22−1)
m
2
=
μ
2
−
Λ
22
−
1
Λ
21
(
E
[
z
1
]
−
μ
1
)
m_{2}=\mu_{2}-\Lambda_{22}^{-1} \Lambda_{21}\left(\mathbb{E}\left[z_{1}\right]-\mu_{1}\right)
m2=μ2−Λ22−1Λ21(E[z1]−μ1)可以发现
q
⋆
(
z
1
)
q^{\star}\left(z_{1}\right)
q⋆(z1)和
q
2
⋆
(
z
2
)
q_{2}^{\star}\left(z_{2}\right)
q2⋆(z2)相互耦合,即互相包括了期望值,因此可以采用迭代的方式进行求解。通过分析可以发现,最终均值就是
E
[
z
1
]
=
μ
1
\mathbb{E}\left[z_{1}\right]=\mu_{1}
E[z1]=μ1,
E
[
z
2
]
=
μ
2
\mathbb{E}\left[z_{2}\right]=\mu_{2}
E[z2]=μ2。结果如图10.2(a),我们看到,均值被正确地描述了,但是
q
(
z
)
q(\mathbf z)
q(z)的⽅差由
p
(
z
)
p(\mathbf z)
p(z)的最⼩⽅差的⽅向所确定,沿着垂直⽅向的⽅差被强烈地低估了。这是⼀个⼀般的结果,即分解变分近似对后验概率分布的近似倾向于过于紧凑。
作为⽐较,假设我们最⼩化相反的Kullback-Leibler散度
K
L
(
p
∥
q
)
\mathrm{KL}(p \| q)
KL(p∥q)。正如我们将看到的那样,这种形式的KL散度被⽤于另⼀种近似推断的框架中,这种框架被称为期望传播(expectation propagation)。于是,我们考虑⼀般的最⼩化
K
L
(
p
∥
q
)
\mathrm{KL}(p \| q)
KL(p∥q)的问题,其中
q
(
Z
)
q(\mathbf Z)
q(Z)是形式为
q
(
Z
)
=
∏
i
=
1
M
q
i
(
Z
i
)
q(\mathbf{Z})=\prod_{i=1}^{M} q_{i}\left(\mathbf{Z}_{i}\right)
q(Z)=∏i=1Mqi(Zi)的分解近似。这样,KL散度可以写成
K
L
(
p
∥
q
)
=
−
∫
p
(
Z
)
[
∑
i
=
1
M
ln
q
i
(
Z
i
)
]
d
Z
+
const
\mathrm{KL}(p \| q)=-\int p(\mathbf{Z})\left[\sum_{i=1}^{M} \ln q_{i}\left(\mathbf{Z}_{i}\right)\right] \mathrm{d} \mathbf{Z}+\text { const }
KL(p∥q)=−∫p(Z)[i=1∑Mlnqi(Zi)]dZ+ const
q
j
⋆
(
Z
j
)
=
∫
p
(
Z
)
∏
i
≠
j
d
Z
i
=
p
(
Z
j
)
q_{j}^{\star}\left(\mathbf{Z}_{j}\right)=\int p(\mathbf{Z}) \prod_{i \neq j} \mathrm{d} \mathbf{Z}_{i}=p\left(\mathbf{Z}_{j}\right)
qj⋆(Zj)=∫p(Z)i̸=j∏dZi=p(Zj)以上结果为一个解析解,不需要迭代,结果如图10.2(b)。我们再⼀次看到,对均值的近似是正确的,但是它把相当多的概率质量放到了实际上具有很低的概率的变量空间区域中。之所以会造成这样的不同
K
L
(
q
∥
p
)
=
−
∫
q
(
Z
)
ln
{
p
(
Z
)
q
(
Z
)
}
d
Z
\mathrm{KL}(q \| p)=-\int q(\mathbf{Z}) \ln \left\{\frac{p(\mathbf{Z})}{q(\mathbf{Z})}\right\} \mathrm{d} \mathbf{Z}
KL(q∥p)=−∫q(Z)ln{q(Z)p(Z)}dZ当
p
(
Z
)
p(\mathbf Z)
p(Z)为0的区域,
q
(
Z
)
q(\mathbf Z)
q(Z)必须也为0,否则会让上式引入一个很大的正数贡献。而反KL散度,当
p
(
Z
)
p(\mathbf Z)
p(Z)为0的区域,当
q
(
Z
)
q(\mathbf Z)
q(Z)不为0时,不会引入正数贡献,并且
p
(
Z
)
p(\mathbf Z)
p(Z)不为0的区域,
q
(
Z
)
q(\mathbf Z)
q(Z)必须不为0。
当用单高斯近似多元高斯时,基于最⼩化
K
L
(
q
∥
p
)
\mathrm{KL}(q \| p)
KL(q∥p)的变分⽅法倾向于找到这些峰值中的⼀个。相反,如果我们最⼩化
K
L
(
p
∥
q
)
\mathrm{KL}(p \| q)
KL(p∥q),那么得到的近似会在所有的均值上取平均。在混合模型问题中,这种⽅法会给出较差的预测分布(因为两个较好的参数值的平均值通常不是⼀个较好的参数值)。可以使⽤
K
L
(
p
∥
q
)
\mathrm{KL}(p \| q)
KL(p∥q)定义⼀个有⽤的推断步骤,但是这需要⼀种与这⾥讨论的内容相当不同的⽅法。当我们讨论期望传播的时候,我们会仔细讨论这⼀点。
以上两个KL散度其实为alpha家族
D
α
(
p
∥
q
)
=
4
1
−
α
2
(
1
−
∫
p
(
x
)
(
1
+
α
)
/
2
q
(
x
)
(
1
−
α
)
/
2
d
x
)
\mathrm{D}_{\alpha}(p \| q)=\frac{4}{1-\alpha^{2}}\left(1-\int p(x)^{(1+\alpha) / 2} q(x)^{(1-\alpha) / 2} \mathrm{d} x\right)
Dα(p∥q)=1−α24(1−∫p(x)(1+α)/2q(x)(1−α)/2dx)

10.1.3 Example: The univariate Gaussian
考虑一个高斯分布,我们的目标是去近似均值和精度的后验分布。似然为
p
(
D
∣
μ
,
τ
)
=
(
τ
2
π
)
N
/
2
exp
{
−
τ
2
∑
n
=
1
N
(
x
n
−
μ
)
2
}
p(\mathcal{D} | \mu, \tau)=\left(\frac{\tau}{2 \pi}\right)^{N / 2} \exp \left\{-\frac{\tau}{2} \sum_{n=1}^{N}\left(x_{n}-\mu\right)^{2}\right\}
p(D∣μ,τ)=(2πτ)N/2exp{−2τn=1∑N(xn−μ)2}引入共轭先验为
p
(
μ
∣
τ
)
=
N
(
μ
∣
μ
0
,
(
λ
0
τ
)
−
1
)
p
(
τ
)
=
Gam
(
τ
∣
a
0
,
b
0
)
\begin{aligned} p(\mu | \tau) &=\mathcal{N}\left(\mu | \mu_{0},\left(\lambda_{0} \tau\right)^{-1}\right) \\ p(\tau) &=\operatorname{Gam}\left(\tau | a_{0}, b_{0}\right) \end{aligned}
p(μ∣τ)p(τ)=N(μ∣μ0,(λ0τ)−1)=Gam(τ∣a0,b0)对于这个问题我们能够计算出精确的后验分布,这儿我们采用平均场变分推理
q
(
μ
,
τ
)
=
q
μ
(
μ
)
q
τ
(
τ
)
q(\mu, \tau)=q_{\mu}(\mu) q_{\tau}(\tau)
q(μ,τ)=qμ(μ)qτ(τ)可得
ln
q
μ
⋆
(
μ
)
=
E
τ
[
ln
p
(
D
∣
μ
,
τ
)
+
ln
p
(
μ
∣
τ
)
]
+
const
=
−
E
[
τ
]
2
{
λ
0
(
μ
−
μ
0
)
2
+
∑
n
=
1
N
(
x
n
−
μ
)
2
}
+
const.
\begin{aligned} \ln q_{\mu}^{\star}(\mu) &=\mathbb{E}_{\tau}[\ln p(\mathcal{D} | \mu, \tau)+\ln p(\mu | \tau)]+\text { const } \\ &=-\frac{\mathbb{E}[\tau]}{2}\left\{\lambda_{0}\left(\mu-\mu_{0}\right)^{2}+\sum_{n=1}^{N}\left(x_{n}-\mu\right)^{2}\right\}+\text { const. } \end{aligned}
lnqμ⋆(μ)=Eτ[lnp(D∣μ,τ)+lnp(μ∣τ)]+ const =−2E[τ]{λ0(μ−μ0)2+n=1∑N(xn−μ)2}+ const. 可以发现该分布为一个高斯分布,
N
(
μ
∣
μ
N
,
λ
N
−
1
)
\mathcal{N}\left(\mu | \mu_{N}, \lambda_{N}^{-1}\right)
N(μ∣μN,λN−1)其中
μ
N
=
λ
0
μ
0
+
N
x
‾
λ
0
+
N
λ
N
=
(
λ
0
+
N
)
E
[
τ
]
\begin{aligned} \mu_{N} &=\frac{\lambda_{0} \mu_{0}+N \overline{x}}{\lambda_{0}+N} \\ \lambda_{N} &=\left(\lambda_{0}+N\right) \mathbb{E}[\tau] \end{aligned}
μNλN=λ0+Nλ0μ0+Nx=(λ0+N)E[τ]注意当
N
→
∞
N \rightarrow \infty
N→∞时,就变为了MLE。同样地
ln
q
τ
⋆
(
τ
)
=
E
μ
[
ln
p
(
D
∣
μ
,
τ
)
+
ln
p
(
μ
∣
τ
)
]
+
ln
p
(
τ
)
+
const
=
(
a
0
−
1
)
ln
τ
−
b
0
τ
+
N
2
ln
τ
−
τ
2
E
μ
[
∑
n
=
1
N
(
x
n
−
μ
)
2
+
λ
0
(
μ
−
μ
0
)
2
]
+
const
\begin{aligned} \ln q_{\tau}^{\star}(\tau)=& \mathbb{E}_{\mu}[\ln p(\mathcal{D} | \mu, \tau)+\ln p(\mu | \tau)]+\ln p(\tau)+\text { const } \\=&\left(a_{0}-1\right) \ln \tau-b_{0} \tau+\frac{N}{2} \ln \tau \\ &-\frac{\tau}{2} \mathbb{E}_{\mu}\left[\sum_{n=1}^{N}\left(x_{n}-\mu\right)^{2}+\lambda_{0}\left(\mu-\mu_{0}\right)^{2}\right]+\text { const } \quad \end{aligned}
lnqτ⋆(τ)==Eμ[lnp(D∣μ,τ)+lnp(μ∣τ)]+lnp(τ)+ const (a0−1)lnτ−b0τ+2Nlnτ−2τEμ[n=1∑N(xn−μ)2+λ0(μ−μ0)2]+ const 此时为一个gamma分布
Gam
(
τ
∣
a
N
,
b
N
)
\operatorname{Gam}\left(\tau | a_{N}, b_{N}\right)
Gam(τ∣aN,bN)
a
N
=
a
0
+
N
2
b
N
=
b
0
+
1
2
E
μ
[
∑
n
=
1
N
(
x
n
−
μ
)
2
+
λ
0
(
μ
−
μ
0
)
2
]
\begin{aligned} a_{N} &=a_{0}+\frac{N}{2} \\ b_{N} &=b_{0}+\frac{1}{2} \mathbb{E}_{\mu}\left[\sum_{n=1}^{N}\left(x_{n}-\mu\right)^{2}+\lambda_{0}\left(\mu-\mu_{0}\right)^{2}\right] \end{aligned}
aNbN=a0+2N=b0+21Eμ[n=1∑N(xn−μ)2+λ0(μ−μ0)2]需要说明的是,我们并没有事先规定各个分布的类型,而是很自然地推导出。由于以上两个分布相互耦合,同样可以采取迭代的方式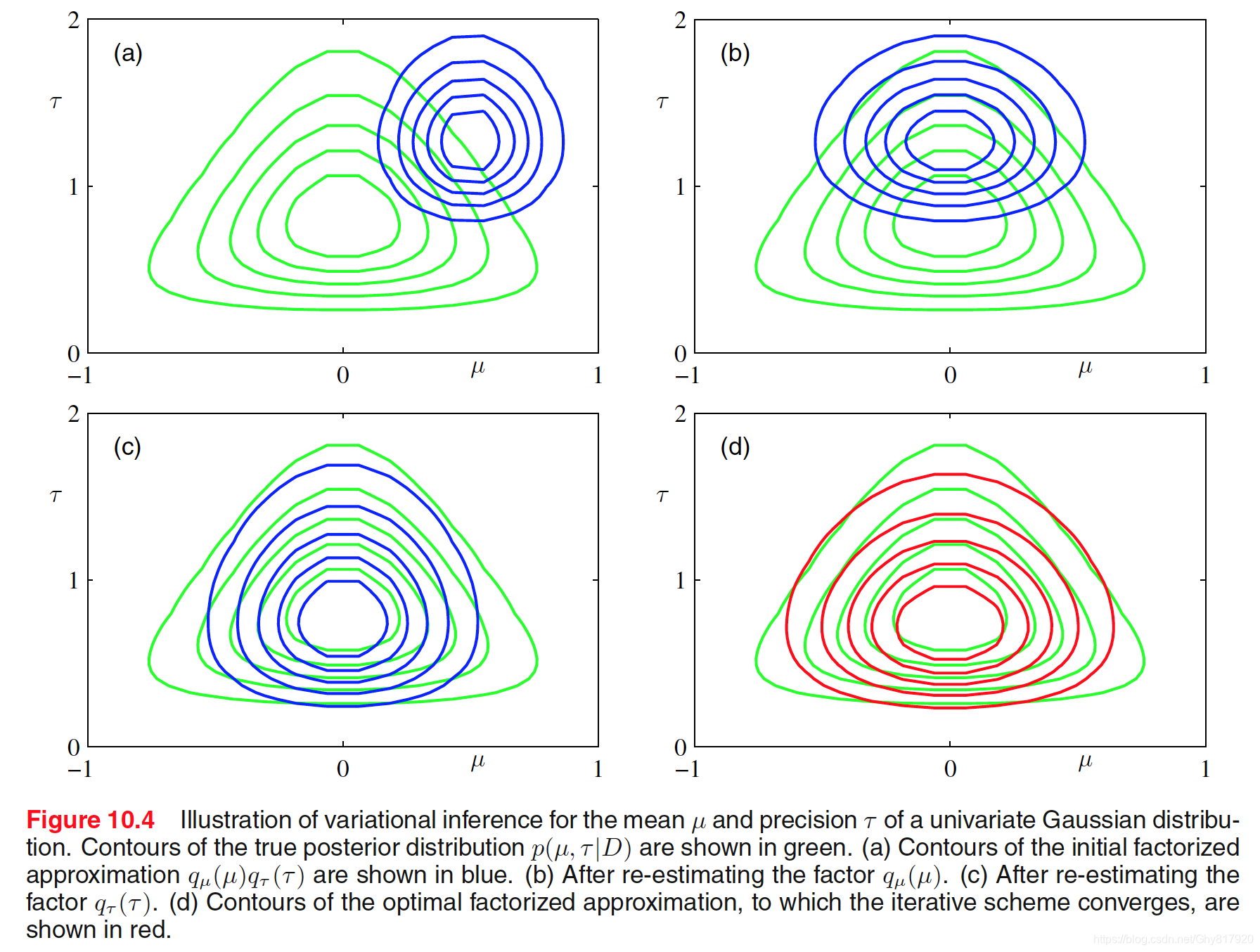
10.1.4 Model comparison

10.2. Illustration: Variational Mixture of Gaussians
这儿讨论的是全贝叶斯的GMM

p
(
Z
∣
π
)
=
∏
n
=
1
N
∏
k
=
1
K
π
k
z
n
k
p(\mathbf{Z} | \boldsymbol{\pi})=\prod_{n=1}^{N} \prod_{k=1}^{K} \pi_{k}^{z_{n k}}
p(Z∣π)=n=1∏Nk=1∏Kπkznk
p
(
X
∣
Z
,
μ
,
Λ
)
=
∏
n
=
1
N
∏
k
=
1
K
N
(
x
n
∣
μ
k
,
Λ
k
−
1
)
z
n
k
p(\mathbf{X} | \mathbf{Z}, \boldsymbol{\mu}, \boldsymbol{\Lambda})=\prod_{n=1}^{N} \prod_{k=1}^{K} \mathcal{N}\left(\mathbf{x}_{n} | \boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}^{-1}\right)^{z_{n k}}
p(X∣Z,μ,Λ)=n=1∏Nk=1∏KN(xn∣μk,Λk−1)znk
p
(
π
)
=
Dir
(
π
∣
α
0
)
=
C
(
α
0
)
∏
k
=
1
K
π
k
α
0
−
1
p(\boldsymbol{\pi})=\operatorname{Dir}\left(\boldsymbol{\pi} | \boldsymbol{\alpha}_{0}\right)=C\left(\boldsymbol{\alpha}_{0}\right) \prod_{k=1}^{K} \pi_{k}^{\alpha_{0}-1}
p(π)=Dir(π∣α0)=C(α0)k=1∏Kπkα0−1
p
(
μ
,
Λ
)
=
p
(
μ
∣
Λ
)
p
(
Λ
)
=
∏
k
=
1
K
N
(
μ
k
∣
m
0
,
(
β
0
Λ
k
)
−
1
)
W
(
Λ
k
∣
W
0
,
ν
0
)
\begin{aligned} p(\boldsymbol{\mu}, \boldsymbol{\Lambda}) &=p(\boldsymbol{\mu} | \boldsymbol{\Lambda}) p(\boldsymbol{\Lambda}) \\ &=\prod_{k=1}^{K} \mathcal{N}\left(\boldsymbol{\mu}_{k} | \mathbf{m}_{0},\left(\beta_{0} \boldsymbol{\Lambda}_{k}\right)^{-1}\right) \mathcal{W}\left(\boldsymbol{\Lambda}_{k} | \mathbf{W}_{0}, \nu_{0}\right) \end{aligned}
p(μ,Λ)=p(μ∣Λ)p(Λ)=k=1∏KN(μk∣m0,(β0Λk)−1)W(Λk∣W0,ν0)
10.2.1 Variational distribution
首先写成该模型的联合分布
p
(
X
,
Z
,
π
,
μ
,
Λ
)
=
p
(
X
∣
Z
,
μ
,
Λ
)
p
(
Z
∣
π
)
p
(
π
)
p
(
μ
∣
Λ
)
p
(
Λ
)
p(\mathbf{X}, \mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})=p(\mathbf{X} | \mathbf{Z}, \boldsymbol{\mu}, \boldsymbol{\Lambda}) p(\mathbf{Z} | \boldsymbol{\pi}) p(\boldsymbol{\pi}) p(\boldsymbol{\mu} | \boldsymbol{\Lambda}) p(\boldsymbol{\Lambda})
p(X,Z,π,μ,Λ)=p(X∣Z,μ,Λ)p(Z∣π)p(π)p(μ∣Λ)p(Λ)利用平均场变分
q
(
Z
,
π
,
μ
,
Λ
)
=
q
(
Z
)
q
(
π
,
μ
,
Λ
)
q(\mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})=q(\mathbf{Z}) q(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})
q(Z,π,μ,Λ)=q(Z)q(π,μ,Λ)首先更新第一个因子
ln
q
⋆
(
Z
)
=
E
π
,
μ
,
Λ
[
ln
p
(
X
,
Z
,
π
,
μ
,
Λ
)
]
+
const.
\ln q^{\star}(\mathbf{Z})=\mathbb{E}_{\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda}}[\ln p(\mathbf{X}, \mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})]+\text { const. }
lnq⋆(Z)=Eπ,μ,Λ[lnp(X,Z,π,μ,Λ)]+ const. 则
ln
q
⋆
(
Z
)
=
E
π
[
ln
p
(
Z
∣
π
)
]
+
E
μ
,
Λ
[
ln
p
(
X
∣
Z
,
μ
,
Λ
)
]
+
const.
\ln q^{\star}(\mathbf{Z})=\mathbb{E}_{\pi}[\ln p(\mathbf{Z} | \boldsymbol{\pi})]+\mathbb{E}_{\boldsymbol{\mu}, \boldsymbol{\Lambda}}[\ln p(\mathbf{X} | \mathbf{Z}, \boldsymbol{\mu}, \boldsymbol{\Lambda})]+\text { const. }
lnq⋆(Z)=Eπ[lnp(Z∣π)]+Eμ,Λ[lnp(X∣Z,μ,Λ)]+ const. 进一步
ln
q
⋆
(
Z
)
=
∑
n
=
1
N
∑
k
=
1
K
z
n
k
ln
ρ
n
k
+
const
\ln q^{\star}(\mathbf{Z})=\sum_{n=1}^{N} \sum_{k=1}^{K} z_{n k} \ln \rho_{n k}+\text { const }
lnq⋆(Z)=n=1∑Nk=1∑Kznklnρnk+ const 其中
ln
ρ
n
k
=
E
[
ln
π
k
]
+
1
2
E
[
ln
∣
Λ
k
∣
]
−
D
2
ln
(
2
π
)
−
1
2
E
μ
k
,
Λ
k
[
(
x
n
−
μ
k
)
T
Λ
k
(
x
n
−
μ
k
)
]
\begin{aligned} \ln \rho_{n k}=& \mathbb{E}\left[\ln \pi_{k}\right]+\frac{1}{2} \mathbb{E}\left[\ln \left|\boldsymbol{\Lambda}_{k}\right|\right]-\frac{D}{2} \ln (2 \pi) \\ &-\frac{1}{2} \mathbb{E}_{\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}}\left[\left(\mathbf{x}_{n}-\boldsymbol{\mu}_{k}\right)^{\mathrm{T}} \boldsymbol{\Lambda}_{k}\left(\mathbf{x}_{n}-\boldsymbol{\mu}_{k}\right)\right] \end{aligned}
lnρnk=E[lnπk]+21E[ln∣Λk∣]−2Dln(2π)−21Eμk,Λk[(xn−μk)TΛk(xn−μk)]从而
q
⋆
(
Z
)
∝
∏
n
=
1
N
∏
k
=
1
K
ρ
n
k
z
n
k
q^{\star}(\mathbf{Z}) \propto \prod_{n=1}^{N} \prod_{k=1}^{K} \rho_{n k}^{z_{n k}}
q⋆(Z)∝n=1∏Nk=1∏Kρnkznk归一化后
q
⋆
(
Z
)
=
∏
n
=
1
N
∏
k
=
1
K
r
n
k
z
n
k
q^{\star}(\mathbf{Z})=\prod_{n=1}^{N} \prod_{k=1}^{K} r_{n k}^{z_{n k}}
q⋆(Z)=n=1∏Nk=1∏Krnkznk其中
r
n
k
=
ρ
n
k
∑
j
=
1
K
ρ
n
j
r_{n k}=\frac{\rho_{n k}}{\sum_{j=1}^{K} \rho_{n j}}
rnk=∑j=1Kρnjρnk有
E
[
z
n
k
]
=
r
n
k
\mathbb{E}\left[z_{n k}\right]=r_{n k}
E[znk]=rnk预先定义
N
k
=
∑
n
=
1
N
r
n
k
x
‾
k
=
1
N
k
∑
n
=
1
N
r
n
k
x
n
S
k
=
1
N
k
∑
n
=
1
N
r
n
k
(
x
n
−
x
‾
k
)
(
x
n
−
x
‾
k
)
T
\begin{aligned} N_{k} &=\sum_{n=1}^{N} r_{n k} \\ \overline{\mathbf{x}}_{k} &=\frac{1}{N_{k}} \sum_{n=1}^{N} r_{n k} \mathbf{x}_{n} \\ \mathbf{S}_{k} &=\frac{1}{N_{k}} \sum_{n=1}^{N} r_{n k}\left(\mathbf{x}_{n}-\overline{\mathbf{x}}_{k}\right)\left(\mathbf{x}_{n}-\overline{\mathbf{x}}_{k}\right)^{\mathrm{T}} \end{aligned}
NkxkSk=n=1∑Nrnk=Nk1n=1∑Nrnkxn=Nk1n=1∑Nrnk(xn−xk)(xn−xk)T考虑第二个因子
q
(
π
,
μ
,
Λ
)
q(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})
q(π,μ,Λ),
ln
q
⋆
(
π
,
μ
,
Λ
)
=
ln
p
(
π
)
+
∑
k
=
1
K
ln
p
(
μ
k
,
Λ
k
)
+
E
Z
[
ln
p
(
Z
∣
π
)
]
+
∑
k
=
1
K
∑
n
=
1
N
E
[
z
n
k
]
ln
N
(
x
n
∣
μ
k
,
Λ
k
−
1
)
+
const.
\begin{array}{c}{\ln q^{\star}(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})=\ln p(\boldsymbol{\pi})+\sum_{k=1}^{K} \ln p\left(\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}\right)+\mathbb{E}_{\mathbf{Z}}[\ln p(\mathbf{Z} | \boldsymbol{\pi})]} {\quad+\sum_{k=1}^{K} \sum_{n=1}^{N} \mathbb{E}\left[z_{n k}\right] \ln \mathcal{N}\left(\mathbf{x}_{n} | \boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}^{-1}\right)+\text { const. }}\end{array}
lnq⋆(π,μ,Λ)=lnp(π)+∑k=1Klnp(μk,Λk)+EZ[lnp(Z∣π)]+∑k=1K∑n=1NE[znk]lnN(xn∣μk,Λk−1)+ const. 可以看到一些项只与
π
\boldsymbol \pi
π有关,有些与
μ
,
Λ
\boldsymbol \mu, \boldsymbol \Lambda
μ,Λ有关,说明可以将该因子进一步分解为
q
(
π
)
q
(
μ
,
Λ
)
q(\boldsymbol{\pi}) q(\boldsymbol{\mu}, \boldsymbol{\Lambda})
q(π)q(μ,Λ),
q
(
π
,
μ
,
Λ
)
=
q
(
π
)
∏
k
=
1
K
q
(
μ
k
,
Λ
k
)
q(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})=q(\boldsymbol{\pi}) \prod_{k=1}^{K} q\left(\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}\right)
q(π,μ,Λ)=q(π)k=1∏Kq(μk,Λk)从而可得
ln
q
⋆
(
π
)
=
(
α
0
−
1
)
∑
k
=
1
K
ln
π
k
+
∑
k
=
1
K
∑
n
=
1
N
r
n
k
ln
π
k
+
const
\ln q^{\star}(\boldsymbol{\pi})=\left(\alpha_{0}-1\right) \sum_{k=1}^{K} \ln \pi_{k}+\sum_{k=1}^{K} \sum_{n=1}^{N} r_{n k} \ln \pi_{k}+\text { const }
lnq⋆(π)=(α0−1)k=1∑Klnπk+k=1∑Kn=1∑Nrnklnπk+ const 整理后
q
⋆
(
π
)
=
Dir
(
π
∣
α
)
q^{\star}(\boldsymbol{\pi})=\operatorname{Dir}(\boldsymbol{\pi} | \boldsymbol{\alpha})
q⋆(π)=Dir(π∣α)其中
α
k
=
α
0
+
N
k
\alpha_{k}=\alpha_{0}+N_{k}
αk=α0+Nk最后,变分后验概率分布
q
⋆
(
μ
k
,
Λ
k
)
q^{\star}\left(\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}\right)
q⋆(μk,Λk)⽆法分解成边缘概率分布的乘积,但是我们总可以使⽤概率的乘积规则,将其写成
q
⋆
(
μ
k
,
Λ
k
)
=
q
⋆
(
μ
k
∣
Λ
k
)
q
⋆
(
Λ
k
)
q^{\star}\left(\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}\right)=q^{\star}\left(\boldsymbol{\mu}_{k} | \boldsymbol{\Lambda}_{k}\right) q^{\star}\left(\boldsymbol{\Lambda}_{k}\right)
q⋆(μk,Λk)=q⋆(μk∣Λk)q⋆(Λk)。跟预期地一样
q
⋆
(
μ
k
,
Λ
k
)
=
N
(
μ
k
∣
m
k
,
(
β
k
Λ
k
)
−
1
)
W
(
Λ
k
∣
W
k
,
ν
k
)
q^{\star}\left(\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}\right)=\mathcal{N}\left(\boldsymbol{\mu}_{k} | \mathbf{m}_{k},\left(\beta_{k} \boldsymbol{\Lambda}_{k}\right)^{-1}\right) \mathcal{W}\left(\boldsymbol{\Lambda}_{k} | \mathbf{W}_{k}, \nu_{k}\right)
q⋆(μk,Λk)=N(μk∣mk,(βkΛk)−1)W(Λk∣Wk,νk)其中
β
k
=
β
0
+
N
k
m
k
=
1
β
k
(
β
0
m
0
+
N
k
x
‾
k
)
W
k
−
1
=
W
0
−
1
+
N
k
S
k
+
β
0
N
k
β
0
+
N
k
(
x
‾
k
−
m
0
)
(
x
‾
k
−
m
0
)
T
ν
k
=
ν
0
+
N
k
\begin{aligned} \beta_{k} &=\beta_{0}+N_{k} \\ \mathbf{m}_{k} &=\frac{1}{\beta_{k}}\left(\beta_{0} \mathbf{m}_{0}+N_{k} \overline{\mathbf{x}}_{k}\right) \\ \mathbf{W}_{k}^{-1} &=\mathbf{W}_{0}^{-1}+N_{k} \mathbf{S}_{k}+\frac{\beta_{0} N_{k}}{\beta_{0}+N_{k}}\left(\overline{\mathbf{x}}_{k}-\mathbf{m}_{0}\right)\left(\overline{\mathbf{x}}_{k}-\mathbf{m}_{0}\right)^{\mathrm{T}} \\ \nu_{k} &=\nu_{0}+N_{k} \end{aligned}
βkmkWk−1νk=β0+Nk=βk1(β0m0+Nkxk)=W0−1+NkSk+β0+Nkβ0Nk(xk−m0)(xk−m0)T=ν0+Nk之前在使用“责任”
r
n
k
\boldsymbol{r}_{n k}
rnk,又涉及计算
E
μ
k
,
Λ
k
[
(
x
n
−
μ
k
)
T
Λ
k
(
x
n
−
μ
k
)
]
=
D
β
k
−
1
+
ν
k
(
x
n
−
m
k
)
T
W
k
(
x
n
−
m
k
)
ln
Λ
~
k
≡
E
[
ln
∣
Λ
k
∣
]
=
∑
i
=
1
D
ψ
(
ν
k
+
1
−
i
2
)
+
D
ln
2
+
ln
∣
W
k
∣
ln
π
~
k
≡
E
[
ln
π
k
]
=
ψ
(
α
k
)
−
ψ
(
α
^
)
\begin{aligned} \mathbb{E}_{\mu_{k}, \Lambda_{k}}\left[\left(\mathbf{x}_{n}-\boldsymbol{\mu}_{k}\right)^{\mathrm{T}} \boldsymbol{\Lambda}_{k}\left(\mathbf{x}_{n}-\boldsymbol{\mu}_{k}\right)\right] \\=& D \beta_{k}^{-1}+\nu_{k}\left(\mathbf{x}_{n}-\mathbf{m}_{k}\right)^{\mathrm{T}} \mathbf{W}_{k}\left(\mathbf{x}_{n}-\mathbf{m}_{k}\right) \\ \ln \widetilde{\Lambda}_{k} \equiv \mathbb{E}\left[\ln \left|\boldsymbol{\Lambda}_{k}\right|\right]=\sum_{i=1}^{D} \psi\left(\frac{\nu_{k}+1-i}{2}\right)+D \ln 2+\ln \left|\mathbf{W}_{k}\right| \\ \ln \widetilde{\pi}_{k} \equiv \mathbb{E}\left[\ln \pi_{k}\right]=\psi\left(\alpha_{k}\right)-\psi(\widehat{\alpha}) \end{aligned}
Eμk,Λk[(xn−μk)TΛk(xn−μk)]=lnΛ
k≡E[ln∣Λk∣]=i=1∑Dψ(2νk+1−i)+Dln2+ln∣Wk∣lnπ
k≡E[lnπk]=ψ(αk)−ψ(α
)Dβk−1+νk(xn−mk)TWk(xn−mk)这两部分是相互耦合的,当把上面的再代入
r
n
k
\boldsymbol{r}_{n k}
rnk
r
n
k
∝
π
~
k
Λ
~
k
1
/
2
exp
{
−
D
2
β
k
−
ν
k
2
(
x
n
−
m
k
)
T
W
k
(
x
n
−
m
k
)
}
r_{n k} \propto \widetilde{\pi}_{k} \widetilde{\Lambda}_{k}^{1 / 2} \exp \left\{-\frac{D}{2 \beta_{k}}-\frac{\nu_{k}}{2}\left(\mathbf{x}_{n}-\mathbf{m}_{k}\right)^{\mathrm{T}} \mathbf{W}_{k}\left(\mathbf{x}_{n}-\mathbf{m}_{k}\right)\right\}
rnk∝π
kΛ
k1/2exp{−2βkD−2νk(xn−mk)TWk(xn−mk)}在最大似然EM中,有
r
n
k
∝
π
k
∣
Λ
k
∣
1
/
2
exp
{
−
1
2
(
x
n
−
μ
k
)
T
Λ
k
(
x
n
−
μ
k
)
}
r_{n k} \propto \pi_{k}\left|\boldsymbol{\Lambda}_{k}\right|^{1 / 2} \exp \left\{-\frac{1}{2}\left(\mathbf{x}_{n}-\boldsymbol{\mu}_{k}\right)^{\mathrm{T}} \boldsymbol{\Lambda}_{k}\left(\mathbf{x}_{n}-\boldsymbol{\mu}_{k}\right)\right\}
rnk∝πk∣Λk∣1/2exp{−21(xn−μk)TΛk(xn−μk)}可以发现变分贝叶斯也是两个步迭代优化。
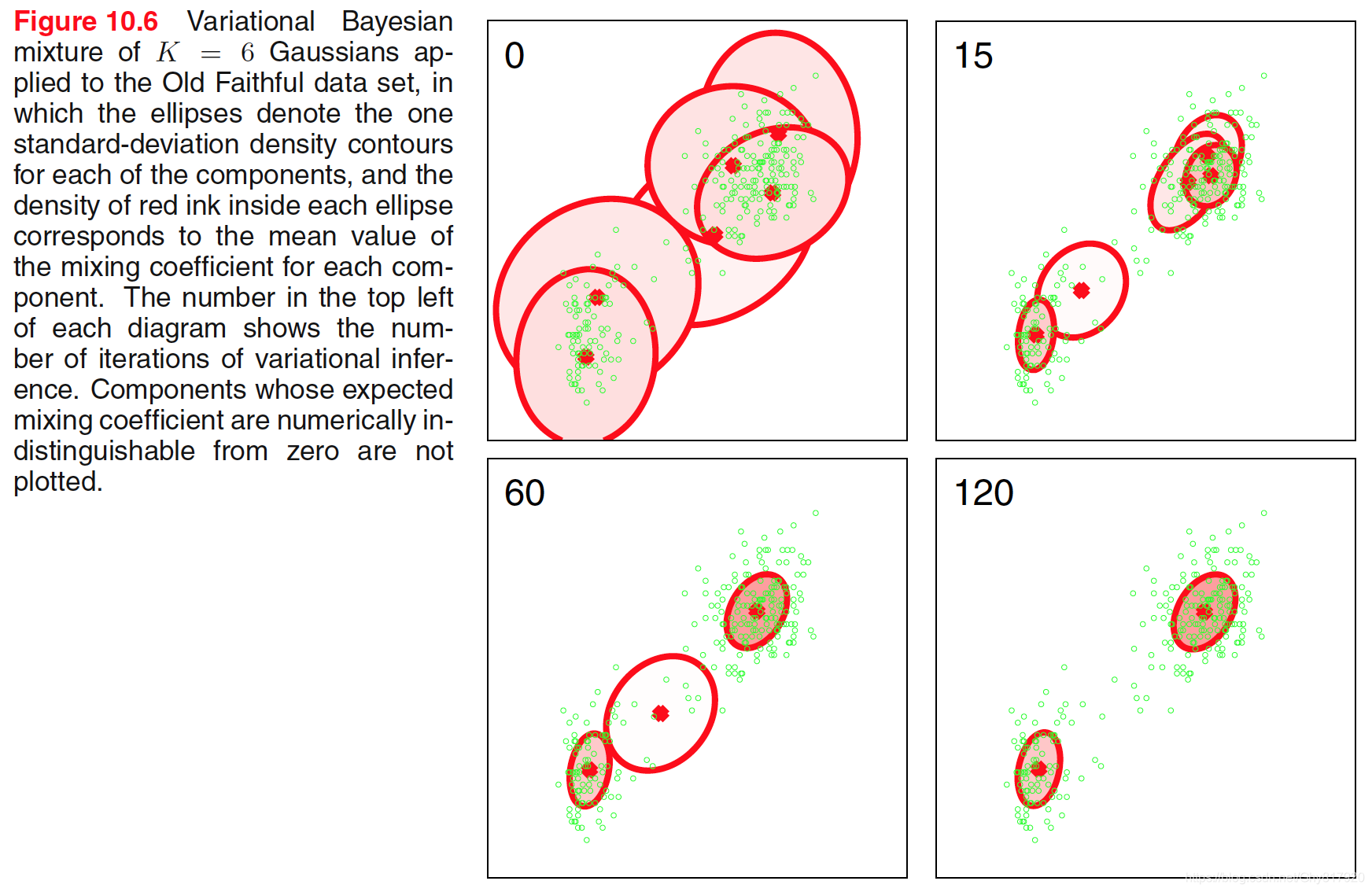
可以发现优化后,并不会出现GMM的奇点。我们看到,在收敛之后,只有两个分量的混合系数的期望值可以与它们的先验值(先验设置为一个很小的数)区分开。这种效果可以根据贝叶斯模型中数据拟合与模型复杂度之间的折中来定性地理解。这种模型中的复杂度惩罚的来源是参数被推离了它们的先验值。对于解释数据点没有作⽤的分量满⾜
r
n
k
≃
0
r_{n k} \simeq 0
rnk≃0,从而
N
k
≃
0
N_{k} \simeq 0
Nk≃0,那么有些退化为先验值
α
k
≃
α
0
\alpha_{k} \simeq \alpha_{0}
αk≃α0。原则上,这些分量会微⼩地适应于数据点,但是对于⼀⼤类先验分布来说,这种微⼩的调整的效果太⼩了,以⾄于⽆法在数值上看出来。对于⾼斯混合模型,后验概率分布中的混合系数的期望值为
E
[
π
k
]
=
α
k
+
N
k
K
α
0
+
N
\mathbb{E}\left[\pi_{k}\right]=\frac{\alpha_{k}+N_{k}}{K \alpha_{0}+N}
E[πk]=Kα0+Nαk+Nk考虑某个退化的分量
N
k
≃
0
N_{k} \simeq 0
Nk≃0 and
α
k
≃
α
0
\alpha_{k} \simeq \alpha_{0}
αk≃α0,当
α
0
→
0
,
\alpha_{0} \rightarrow 0,
α0→0, then
E
[
π
k
]
→
0
\mathbb{E}\left[\pi_{k}\right] \rightarrow 0
E[πk]→0,此时该分量就不起作用,而
α
0
→
∞
,
\alpha_{0} \rightarrow \infty,
α0→∞, then
E
[
π
k
]
→
1
/
K
\mathbb{E}\left[\pi_{k}\right] \rightarrow 1/K
E[πk]→1/K。之前狄利克雷分布的参数表示,当越小,则倾向让某些分量为0,从而本实验设置为
α
0
=
1
0
−
3
\alpha_{0}=10^{-3}
α0=10−3。

10.2.2 Variational lower bound
在实际应⽤中,能够在重新估计期间监视模型的下界是很有⽤的,这可以⽤来检测是否收敛。它也可以为解的数学表达式和它们的软件执⾏提供⼀个有价值的检查,因为在迭代重新估计的每个步骤中,这个下界的值应该不会减⼩。我们可以进⼀步地使⽤变分下界检查更新⽅程的数学推导和它们的软件执⾏的正确性,⽅法是使⽤有限差来检查每次更新确实给出了下界的⼀个(具有限制条件的)极⼤值。
L
=
∑
Z
∭
q
(
Z
,
π
,
μ
,
Λ
)
ln
{
p
(
X
,
Z
,
π
,
μ
,
Λ
)
q
(
Z
,
π
,
μ
,
Λ
)
}
d
π
d
μ
d
Λ
=
E
[
ln
p
(
X
,
Z
,
μ
,
μ
,
Λ
)
]
−
E
[
ln
q
(
Z
,
π
,
μ
,
Λ
)
]
=
E
[
ln
p
(
X
∣
Z
,
μ
,
Λ
)
]
+
E
[
ln
p
(
Z
,
π
,
μ
,
Λ
)
]
−
E
[
ln
q
(
Z
)
]
−
E
[
ln
q
(
π
)
]
−
E
[
ln
q
(
μ
,
Λ
)
]
\begin{aligned} \mathcal{L}=& \sum_{\mathbf{Z}} \iiint q(\mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda}) \ln \left\{\frac{p(\mathbf{X}, \mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})}{q(\mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})}\right\} \mathrm{d} \boldsymbol{\pi} \mathrm{d} \boldsymbol{\mu} \mathrm{d} \boldsymbol{\Lambda} \\=& \mathbb{E}[\ln p(\mathbf{X}, \mathbf{Z}, \boldsymbol{\mu}, \boldsymbol{\mu}, \boldsymbol{\Lambda})]-\mathbb{E}[\ln q(\mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})] \\=& \mathbb{E}[\ln p(\mathbf{X} | \mathbf{Z}, \boldsymbol{\mu}, \boldsymbol{\Lambda})]+\mathbb{E}[\ln p(\mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})] \\ &-\mathbb{E}[\ln q(\mathbf{Z})]-\mathbb{E}[\ln q(\boldsymbol{\pi})]-\mathbb{E}[\ln q(\boldsymbol{\mu}, \boldsymbol{\Lambda})] \end{aligned}
L===Z∑∭q(Z,π,μ,Λ)ln{q(Z,π,μ,Λ)p(X,Z,π,μ,Λ)}dπdμdΛE[lnp(X,Z,μ,μ,Λ)]−E[lnq(Z,π,μ,Λ)]E[lnp(X∣Z,μ,Λ)]+E[lnp(Z,π,μ,Λ)]−E[lnq(Z)]−E[lnq(π)]−E[lnq(μ,Λ)]
对于这些期望,由于模型有共轭先验,因此变分后验分布的函数形式是已知的。通过使⽤这些分布的⼀般的参数形式,我们可以推导出下界的形式,将下界作为概率分布的参数的函数。关于这些参数最⼤化下界就会得到所需的重估计⽅程。
10.2.3 Predictive density
为了得到预测分布,即预测 x ^ \widehat{\mathbf{x}} x , p ( x ^ ∣ X ) = ∑ z ^ ∭ p ( x ^ ∣ z ^ , μ , Λ ) p ( z ^ ∣ π ) p ( π , μ , Λ ∣ X ) d π d μ d Λ p(\widehat{\mathbf{x}} | \mathbf{X})=\sum_{\hat{\mathbf{z}}} \iiint p(\widehat{\mathbf{x}} | \widehat{\mathbf{z}}, \boldsymbol{\mu}, \boldsymbol{\Lambda}) p(\widehat{\mathbf{z}} | \boldsymbol{\pi}) p(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda} | \mathbf{X}) \mathrm{d} \boldsymbol{\pi} \mathrm{d} \boldsymbol{\mu} \mathrm{d} \boldsymbol{\Lambda} p(x ∣X)=z^∑∭p(x ∣z ,μ,Λ)p(z ∣π)p(π,μ,Λ∣X)dπdμdΛ其中 p ( π , μ , Λ ∣ X ) p(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda} | \mathbf{X}) p(π,μ,Λ∣X)是未知的真实后验分布, p ( x ^ ∣ X ) = ∑ k = 1 K ∭ π k N ( x ^ ∣ μ k , Λ k − 1 ) p ( π , μ , Λ ∣ X ) d π d μ d Λ p(\widehat{\mathbf{x}} | \mathbf{X})=\sum_{k=1}^{K} \iiint \pi_{k} \mathcal{N}\left(\widehat{\mathbf{x}} | \boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}^{-1}\right) p(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda} | \mathbf{X}) \mathrm{d} \boldsymbol{\pi} \mathrm{d} \boldsymbol{\mu} \mathrm{d} \boldsymbol{\Lambda} p(x ∣X)=k=1∑K∭πkN(x ∣μk,Λk−1)p(π,μ,Λ∣X)dπdμdΛ可以将真实后验用变分后验代替 p ( x ^ ∣ X ) = ∑ k = 1 K ∭ π k N ( x ^ ∣ μ k , Λ k − 1 ) q ( π ) q ( μ k , Λ k ) d π d μ k d Λ k p(\widehat{\mathbf{x}} | \mathbf{X})=\sum_{k=1}^{K} \iiint \pi_{k} \mathcal{N}\left(\widehat{\mathbf{x}} | \boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}^{-1}\right) q(\boldsymbol{\pi}) q\left(\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}\right) \mathrm{d} \boldsymbol{\pi} \mathrm{d} \boldsymbol{\mu}_{k} \mathrm{d} \boldsymbol{\Lambda}_{k} p(x ∣X)=k=1∑K∭πkN(x ∣μk,Λk−1)q(π)q(μk,Λk)dπdμkdΛk从而可得一个student分布 p ( x ^ ∣ X ) = 1 α ^ ∑ k = 1 K α k St ( x ^ ∣ m k , L k , ν k + 1 − D ) p(\widehat{\mathbf{x}} | \mathbf{X})=\frac{1}{\widehat{\alpha}} \sum_{k=1}^{K} \alpha_{k} \operatorname{St}\left(\widehat{\mathbf{x}} | \mathbf{m}_{k}, \mathbf{L}_{k}, \nu_{k}+1-D\right) p(x ∣X)=α 1k=1∑KαkSt(x ∣mk,Lk,νk+1−D)其中 L k = ( ν k + 1 − D ) β k ( 1 + β k ) W k \mathbf{L}_{k}=\frac{\left(\nu_{k}+1-D\right) \beta_{k}}{\left(1+\beta_{k}\right)} \mathbf{W}_{k} Lk=(1+βk)(νk+1−D)βkWk
10.2.4 Determining the number of components

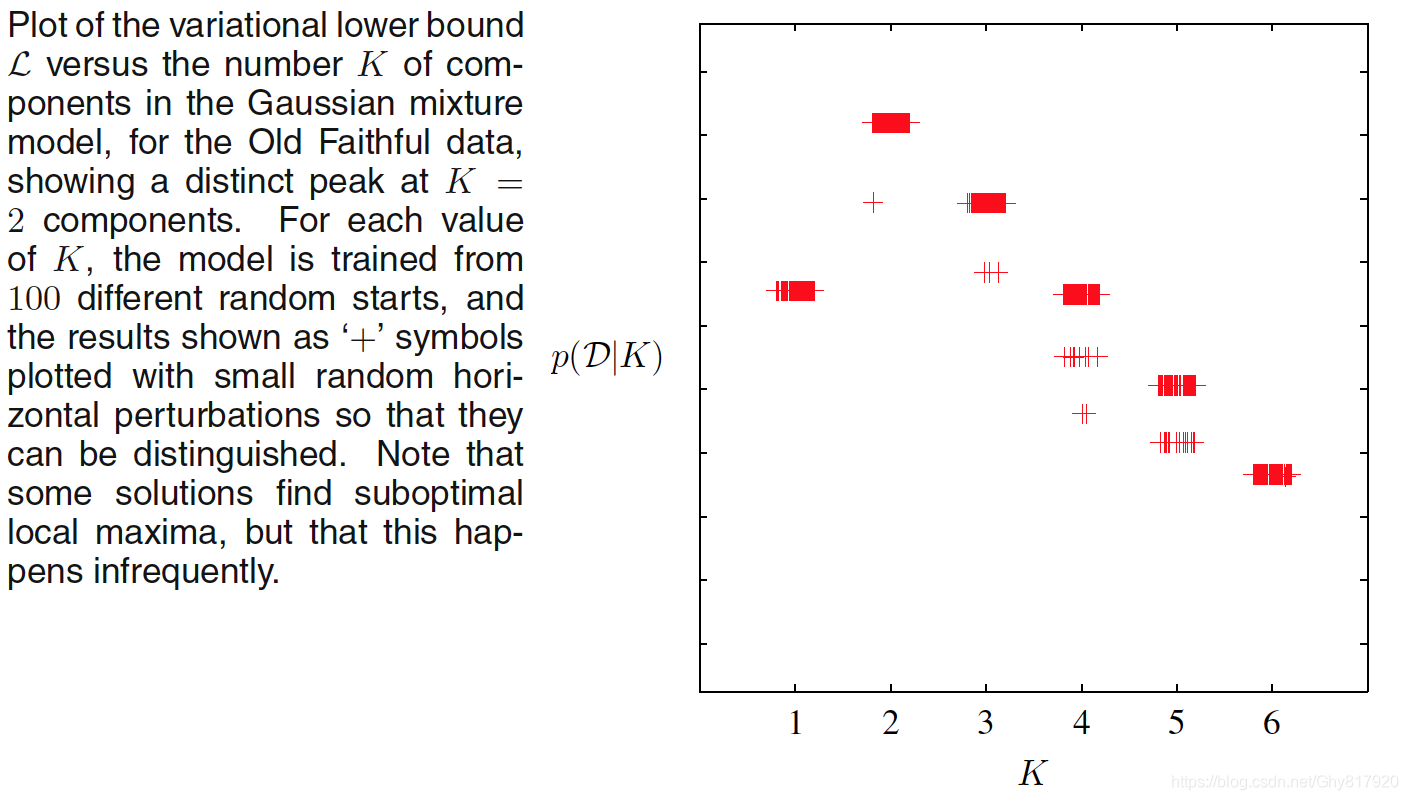

10.2.5 Induced factorizations
再推导变分更新时,一开始仅仅考虑
q
(
Z
,
π
,
μ
,
Λ
)
=
q
(
Z
)
q
(
π
,
μ
,
Λ
)
q(\mathbf{Z}, \boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})=q(\mathbf{Z}) q(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})
q(Z,π,μ,Λ)=q(Z)q(π,μ,Λ)但是最优的结果又推导出一些新的分解
q
(
π
,
μ
,
Λ
)
=
q
(
π
)
∏
k
=
1
K
q
(
μ
k
,
Λ
k
)
q(\boldsymbol{\pi}, \boldsymbol{\mu}, \boldsymbol{\Lambda})=q(\boldsymbol{\pi}) \prod_{k=1}^{K} q\left(\boldsymbol{\mu}_{k}, \boldsymbol{\Lambda}_{k}\right)
q(π,μ,Λ)=q(π)k=1∏Kq(μk,Λk)这些额外的分解的产⽣原因是假定的分解⽅式与真实分布的条件独⽴性质相互作⽤的结果,正如图模型所告诉的那样

我们会把这些额外的分解⽅式成为诱导分解(induced factorizations),因为它们产⽣于在变分后验分布中假定的分解⽅式与真实联合概率分布的条件独⽴性质之间的相互作⽤。在变分⽅法的数值实现中,考虑这些附加的分解⽅式很重要。例如,对于⼀组变量上的⾼斯分布来说,如果分布的最优形式的精度矩阵总是对⾓矩阵(对应于关于由那个⾼斯分布独⽴描述的变量的分解⽅式),那么在计算过程中始终保留⼀个完整的精度矩阵是⼀种很低效的做法。
使⽤⼀种基于d-划分的简单的图检测⽅法,这种诱导的分解⽅式可以很容易地被检测到。我们将潜在变量划分为三个互斥的组
A
,
B
,
C
\mathbf{A}, \mathbf{B}, \mathbf{C}
A,B,C,然后让我们假定我们可以在变量
C
\mathbf{C}
C与剩余变量之间进⾏分解,即
q
(
A
,
B
,
C
)
=
q
(
A
,
B
)
q
(
C
)
q(\mathbf{A}, \mathbf{B}, \mathbf{C})=q(\mathbf{A}, \mathbf{B}) q(\mathbf{C})
q(A,B,C)=q(A,B)q(C)则
ln
q
⋆
(
A
,
B
)
=
E
C
[
ln
p
(
X
,
A
,
B
,
C
)
]
+
const
=
E
C
[
ln
p
(
A
,
B
∣
X
,
C
)
]
+
const
\begin{aligned} \ln q^{\star}(\mathbf{A}, \mathbf{B}) &=\mathbb{E}_{\mathbf{C}}[\ln p(\mathbf{X}, \mathbf{A}, \mathbf{B}, \mathbf{C})]+\text { const } \\ &=\mathbb{E}_{\mathbf{C}}[\ln p(\mathbf{A}, \mathbf{B} | \mathbf{X}, \mathbf{C})]+\text { const } \end{aligned}
lnq⋆(A,B)=EC[lnp(X,A,B,C)]+ const =EC[lnp(A,B∣X,C)]+ const 那么此处我们可以考虑是否存在
q
⋆
(
A
,
B
)
=
q
⋆
(
A
)
q
⋆
(
B
)
q^{\star}(\mathbf{A}, \mathbf{B})=q^{\star}(\mathbf{A}) q^{\star}(\mathbf{B})
q⋆(A,B)=q⋆(A)q⋆(B),这仅仅发生在
ln
p
(
A
,
B
∣
X
,
C
)
=
ln
p
(
A
∣
X
,
C
)
+
ln
p
(
B
∣
X
,
C
)
\ln p(\mathbf{A}, \mathbf{B} | \mathbf{X}, \mathbf{C})=\ln p(\mathbf{A} | \mathbf{X}, \mathbf{C})+\ln p(\mathbf{B} | \mathbf{X}, \mathbf{C})
lnp(A,B∣X,C)=lnp(A∣X,C)+lnp(B∣X,C),也就是说
A
⊥
B
∣
X
,
C
\mathbf{A} \perp \mathbf{B} | \mathbf{X}, \mathbf{C}
A⊥B∣X,C
10.3 Variational Linear Regression
作为变分推断的第⼆个例⼦,我们回到3.3节的贝叶斯线性回归模型中。在模型证据框架中,我们通过使⽤最⼤化似然函数的⽅法进⾏点估计,从⽽近似了在
α
\alpha
α和
β
\beta
β 上的积分。⼀个纯粹的贝叶斯⽅法会对所有的超参数和参数进⾏积分。虽然精确的积分是⽆法计算的,但是我们可以使⽤变分⽅法来找到⼀个可以处理的近似。为了简化讨论,我们会假设噪声精度参数
β
\beta
β 已知,并且固定于它的真实值,虽然这个框架很容易扩展来包含
β
\beta
β 上的概率分布。对于线性回归模型来说,可以证明变分⽅法等价于模型证据的框架。
p
(
t
∣
w
)
=
∏
n
=
1
N
N
(
t
n
∣
w
T
ϕ
n
,
β
−
1
)
p
(
w
∣
α
)
=
N
(
w
∣
0
,
α
−
1
I
)
\begin{aligned} p(\mathbf{t} | \mathbf{w}) &=\prod_{n=1}^{N} \mathcal{N}\left(t_{n} | \mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}, \beta^{-1}\right) \\ p(\mathbf{w} | \alpha) &=\mathcal{N}\left(\mathbf{w} | \mathbf{0}, \alpha^{-1} \mathbf{I}\right) \end{aligned}
p(t∣w)p(w∣α)=n=1∏NN(tn∣wTϕn,β−1)=N(w∣0,α−1I)其中
ϕ
n
=
ϕ
(
x
n
)
\phi_{n}=\phi\left(\mathbf{x}_{n}\right)
ϕn=ϕ(xn),取
α
\alpha
α的共轭先验
p
(
α
)
=
Gam
(
α
∣
a
0
,
b
0
)
p(\alpha)=\operatorname{Gam}\left(\alpha | a_{0}, b_{0}\right)
p(α)=Gam(α∣a0,b0)则
p
(
t
,
w
,
α
)
=
p
(
t
∣
w
)
p
(
w
∣
α
)
p
(
α
)
p(\mathbf{t}, \mathbf{w}, \alpha)=p(\mathbf{t} | \mathbf{w}) p(\mathbf{w} | \alpha) p(\alpha)
p(t,w,α)=p(t∣w)p(w∣α)p(α)
10.3.1 Variational distribution
首要目标是找到一个对后验分布
p
(
w
,
α
∣
t
)
p(\mathbf{w}, \alpha | \mathbf{t})
p(w,α∣t)的近似,采用的变分分解为
q
(
w
,
α
)
=
q
(
w
)
q
(
α
)
q(\mathbf{w}, \alpha)=q(\mathbf{w}) q(\alpha)
q(w,α)=q(w)q(α)对
α
\alpha
α有
ln
q
⋆
(
α
)
=
ln
p
(
α
)
+
E
w
[
ln
p
(
w
∣
α
)
]
+
const
=
(
a
0
−
1
)
ln
α
−
b
0
α
+
M
2
ln
α
−
α
2
E
[
w
T
w
]
+
c
o
n
s
t
.
\begin{array}{l}{\ln q^{\star}(\alpha)=\ln p(\alpha)+\mathbb{E}_{\mathbf{w}}[\ln p(\mathbf{w} | \alpha)]+\text { const }} \\ {\quad=\left(a_{0}-1\right) \ln \alpha-b_{0} \alpha+\frac{M}{2} \ln \alpha-\frac{\alpha}{2} \mathbb{E}\left[\mathbf{w}^{\mathrm{T}} \mathbf{w}\right]+\mathrm{const.}}\end{array}
lnq⋆(α)=lnp(α)+Ew[lnp(w∣α)]+ const =(a0−1)lnα−b0α+2Mlnα−2αE[wTw]+const.刚好为
q
⋆
(
α
)
=
Gam
(
α
∣
a
N
,
b
N
)
q^{\star}(\alpha)=\operatorname{Gam}\left(\alpha | a_{N}, b_{N}\right)
q⋆(α)=Gam(α∣aN,bN)其中
a
N
=
a
0
+
M
2
b
N
=
b
0
+
1
2
E
[
w
T
w
]
\begin{aligned} a_{N} &=a_{0}+\frac{M}{2} \\ b_{N} &=b_{0}+\frac{1}{2} \mathbb{E}\left[\mathbf{w}^{\mathrm{T}} \mathbf{w}\right] \end{aligned}
aNbN=a0+2M=b0+21E[wTw]同理有
ln
q
⋆
(
w
)
=
ln
p
(
t
∣
w
)
+
E
α
[
ln
p
(
w
∣
α
)
]
+
c
o
n
s
t
=
−
β
2
∑
n
=
1
N
{
w
T
ϕ
n
−
t
n
}
2
−
1
2
E
[
α
]
w
T
w
+
const
=
−
1
2
w
T
(
E
[
α
]
I
+
β
Φ
T
Φ
)
w
+
β
w
T
Φ
T
t
+
const.
\begin{aligned} \ln q^{\star}(\mathbf{w}) &=\ln p(\mathbf{t} | \mathbf{w})+\mathbb{E}_{\alpha}[\ln p(\mathbf{w} | \alpha)]+\mathrm{const} \\ &=-\frac{\beta}{2} \sum_{n=1}^{N}\left\{\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}-t_{n}\right\}^{2}-\frac{1}{2} \mathbb{E}[\alpha] \mathbf{w}^{\mathrm{T}} \mathbf{w}+\text { const } \\ &=-\frac{1}{2} \mathbf{w}^{\mathrm{T}}\left(\mathbb{E}[\alpha] \mathbf{I}+\beta \mathbf{\Phi}^{\mathrm{T}} \mathbf{\Phi}\right) \mathbf{w}+\beta \mathbf{w}^{\mathrm{T}} \mathbf{\Phi}^{\mathrm{T}} \mathbf{t}+\text { const. } \end{aligned}
lnq⋆(w)=lnp(t∣w)+Eα[lnp(w∣α)]+const=−2βn=1∑N{wTϕn−tn}2−21E[α]wTw+ const =−21wT(E[α]I+βΦTΦ)w+βwTΦTt+ const. 刚好为高斯
q
⋆
(
w
)
=
N
(
w
∣
m
N
,
S
N
)
q^{\star}(\mathbf{w})=\mathcal{N}\left(\mathbf{w} | \mathbf{m}_{N}, \mathbf{S}_{N}\right)
q⋆(w)=N(w∣mN,SN)其中
m
N
=
β
S
N
Φ
T
t
S
N
=
(
E
[
α
]
I
+
β
Φ
T
Φ
)
−
1
\begin{aligned} \mathbf{m}_{N} &=\beta \mathbf{S}_{N} \mathbf{\Phi}^{\mathrm{T}} \mathbf{t} \\ \mathbf{S}_{N} &=\left(\mathbb{E}[\alpha] \mathbf{I}+\beta \mathbf{\Phi}^{\mathrm{T}} \mathbf{\Phi}\right)^{-1} \end{aligned}
mNSN=βSNΦTt=(E[α]I+βΦTΦ)−1注意这个结果与
α
\alpha
α被当成固定参数时得到的后验概率分布
S
N
−
1
=
α
I
+
β
Φ
T
Φ
\mathbf{S}_{N}^{-1}=\alpha \mathbf{I}+\beta \boldsymbol{\Phi}^{\mathrm{T}} \mathbf{\Phi}
SN−1=αI+βΦTΦ相似。又因
E
[
α
]
=
a
N
/
b
N
E
[
w
w
T
]
=
m
N
m
N
T
+
S
N
\begin{aligned} \mathbb{E}[\alpha] &=a_{N} / b_{N} \\ \mathbb{E}\left[\mathbf{w} \mathbf{w}^{\mathrm{T}}\right] &=\mathbf{m}_{N} \mathbf{m}_{N}^{\mathrm{T}}+\mathbf{S}_{N} \end{aligned}
E[α]E[wwT]=aN/bN=mNmNT+SN这样就可以迭代地更新变分后验。
当
a
0
=
b
0
=
0
a_{0}=b_{0}=0
a0=b0=0时,对应于一个无限宽的
α
\alpha
α先验,那么
E
[
α
]
=
a
N
b
N
=
M
/
2
E
[
w
T
w
]
/
2
=
M
m
N
T
m
N
+
Tr
(
S
N
)
\mathbb{E}[\alpha]=\frac{a_{N}}{b_{N}}=\frac{M / 2}{\mathbb{E}\left[\mathbf{w}^{\mathrm{T}} \mathbf{w}\right] / 2}=\frac{M}{\mathbf{m}_{N}^{\mathrm{T}} \mathbf{m}_{N}+\operatorname{Tr}\left(\mathbf{S}_{N}\right)}
E[α]=bNaN=E[wTw]/2M/2=mNTmN+Tr(SN)M变分⽅法得到的解与使⽤EM算法最⼤化模型证据函数的⽅法得到的解完全相同,唯⼀的区别是
α
\alpha
α的点估计被替换为了它的期望值。由于分布
q
(
w
)
q(\mathbf{w})
q(w)只通过期望
E
[
α
]
\mathbb{E}[\alpha]
E[α]对
q
(
α
)
q(\alpha)
q(α)产⽣依赖,因此我们看到这两种⽅法对于⽆限宽的先验概率分布会给出相同的结果。
10.3.2 Predictive distribution
p ( t ∣ x , t ) = ∫ p ( t ∣ x , w ) p ( w ∣ t ) d w ≃ ∫ p ( t ∣ x , w ) q ( w ) d w = ∫ N ( t ∣ w T ϕ ( x ) , β − 1 ) N ( w ∣ m N , S N ) d w = N ( t ∣ m N T ϕ ( x ) , σ 2 ( x ) ) \begin{aligned} p(t | \mathbf{x}, \mathbf{t}) &=\int p(t | \mathbf{x}, \mathbf{w}) p(\mathbf{w} | \mathbf{t}) \mathrm{d} \mathbf{w} \\ & \simeq \int p(t | \mathbf{x}, \mathbf{w}) q(\mathbf{w}) \mathrm{d} \mathbf{w} \\ &=\int \mathcal{N}\left(t | \mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}(\mathbf{x}), \beta^{-1}\right) \mathcal{N}\left(\mathbf{w} | \mathbf{m}_{N}, \mathbf{S}_{N}\right) \mathrm{d} \mathbf{w} \\ &=\mathcal{N}\left(t | \mathbf{m}_{N}^{\mathrm{T}} \boldsymbol{\phi}(\mathbf{x}), \sigma^{2}(\mathbf{x})\right) \end{aligned} p(t∣x,t)=∫p(t∣x,w)p(w∣t)dw≃∫p(t∣x,w)q(w)dw=∫N(t∣wTϕ(x),β−1)N(w∣mN,SN)dw=N(t∣mNTϕ(x),σ2(x))其中 σ 2 ( x ) = 1 β + ϕ ( x ) T S N ϕ ( x ) \sigma^{2}(\mathbf{x})=\frac{1}{\beta}+\boldsymbol{\phi}(\mathbf{x})^{\mathrm{T}} \mathbf{S}_{N} \boldsymbol{\phi}(\mathbf{x}) σ2(x)=β1+ϕ(x)TSNϕ(x)
10.3.3 Lower bound
另⼀个很重要的量是下界
L
(
q
)
=
E
[
ln
p
(
w
,
α
,
t
)
]
−
E
[
ln
q
(
w
,
α
)
]
=
E
w
[
ln
p
(
t
∣
w
)
]
+
E
w
,
α
[
ln
p
(
w
∣
α
)
]
+
E
α
[
ln
p
(
α
)
]
−
E
α
[
ln
q
(
w
)
]
w
−
E
[
ln
q
(
α
)
]
\begin{aligned} \mathcal{L}(q)=& \mathbb{E}[\ln p(\mathbf{w}, \alpha, \mathbf{t})]-\mathbb{E}[\ln q(\mathbf{w}, \alpha)] \\=& \mathbb{E}_{\mathbf{w}}[\ln p(\mathbf{t} | \mathbf{w})]+\mathbb{E}_{\mathbf{w}, \alpha}[\ln p(\mathbf{w} | \alpha)]+\mathbb{E}_{\alpha}[\ln p(\alpha)] \\ &-\mathbb{E}_{\alpha}[\ln q(\mathbf{w})]_{\mathbf{w}}-\mathbb{E}[\ln q(\alpha)] \end{aligned}
L(q)==E[lnp(w,α,t)]−E[lnq(w,α)]Ew[lnp(t∣w)]+Ew,α[lnp(w∣α)]+Eα[lnp(α)]−Eα[lnq(w)]w−E[lnq(α)]使⽤之前章节得到的结果,计算各项的值是很容易的,结果为
E
[
ln
p
(
t
∣
w
)
]
w
=
N
2
ln
(
β
2
π
)
−
β
2
t
T
t
+
β
m
N
T
Φ
T
t
−
β
2
Tr
[
Φ
T
Φ
(
m
N
m
N
T
+
S
N
)
]
\begin{aligned} \mathbb{E}[\ln p(\mathbf{t} | \mathbf{w})]_{\mathbf{w}}=& \frac{N}{2} \ln \left(\frac{\beta}{2 \pi}\right)-\frac{\beta}{2} \mathbf{t}^{\mathrm{T}} \mathbf{t}+\beta \mathbf{m}_{N}^{\mathrm{T}} \mathbf{\Phi}^{\mathrm{T}} \mathbf{t} \\ &-\frac{\beta}{2} \operatorname{Tr}\left[\mathbf{\Phi}^{\mathrm{T}} \mathbf{\Phi}\left(\mathbf{m}_{N} \mathbf{m}_{N}^{\mathrm{T}}+\mathbf{S}_{N}\right)\right] \end{aligned}
E[lnp(t∣w)]w=2Nln(2πβ)−2βtTt+βmNTΦTt−2βTr[ΦTΦ(mNmNT+SN)]
E
[
ln
p
(
w
∣
α
)
]
w
,
α
=
−
M
2
ln
(
2
π
)
+
M
2
(
ψ
(
a
N
)
−
ln
b
N
)
−
a
N
2
b
N
[
m
N
T
m
N
+
Tr
(
S
N
)
]
\begin{aligned} \mathbb{E}[\ln p(\mathbf{w} | \alpha)]_{\mathbf{w}, \alpha}=&-\frac{M}{2} \ln (2 \pi)+\frac{M}{2}\left(\psi\left(a_{N}\right)-\ln b_{N}\right) \\ &-\frac{a_{N}}{2 b_{N}}\left[\mathbf{m}_{N}^{\mathrm{T}} \mathbf{m}_{N}+\operatorname{Tr}\left(\mathbf{S}_{N}\right)\right] \end{aligned}
E[lnp(w∣α)]w,α=−2Mln(2π)+2M(ψ(aN)−lnbN)−2bNaN[mNTmN+Tr(SN)]
E
[
ln
p
(
α
)
]
α
=
a
0
ln
b
0
+
(
a
0
−
1
)
[
ψ
(
a
N
)
−
ln
b
N
]
−
b
0
a
N
b
N
−
ln
Γ
(
a
N
)
\begin{aligned} \mathbb{E}[\ln p(\alpha)]_{\alpha}=& a_{0} \ln b_{0}+\left(a_{0}-1\right)\left[\psi\left(a_{N}\right)-\ln b_{N}\right] \\ &-b_{0} \frac{a_{N}}{b_{N}}-\ln \Gamma\left(a_{N}\right) \end{aligned}
E[lnp(α)]α=a0lnb0+(a0−1)[ψ(aN)−lnbN]−b0bNaN−lnΓ(aN)
−
E
[
ln
q
(
w
)
]
w
=
1
2
ln
∣
S
N
∣
+
M
2
[
1
+
ln
(
2
π
)
]
−
E
[
ln
q
(
α
)
]
α
=
ln
Γ
(
a
N
)
−
(
a
N
−
1
)
ψ
(
a
N
)
−
ln
b
N
+
a
N
\begin{aligned}-\mathbb{E}[\ln q(\mathbf{w})]_{\mathbf{w}} &=\frac{1}{2} \ln \left|\mathbf{S}_{N}\right|+\frac{M}{2}[1+\ln (2 \pi)] \\-\mathbb{E}[\ln q(\alpha)]_{\alpha} &=\ln \Gamma\left(a_{N}\right)-\left(a_{N}-1\right) \psi\left(a_{N}\right)-\ln b_{N}+a_{N} \end{aligned}
−E[lnq(w)]w−E[lnq(α)]α=21ln∣SN∣+2M[1+ln(2π)]=lnΓ(aN)−(aN−1)ψ(aN)−lnbN+aN给出了下界
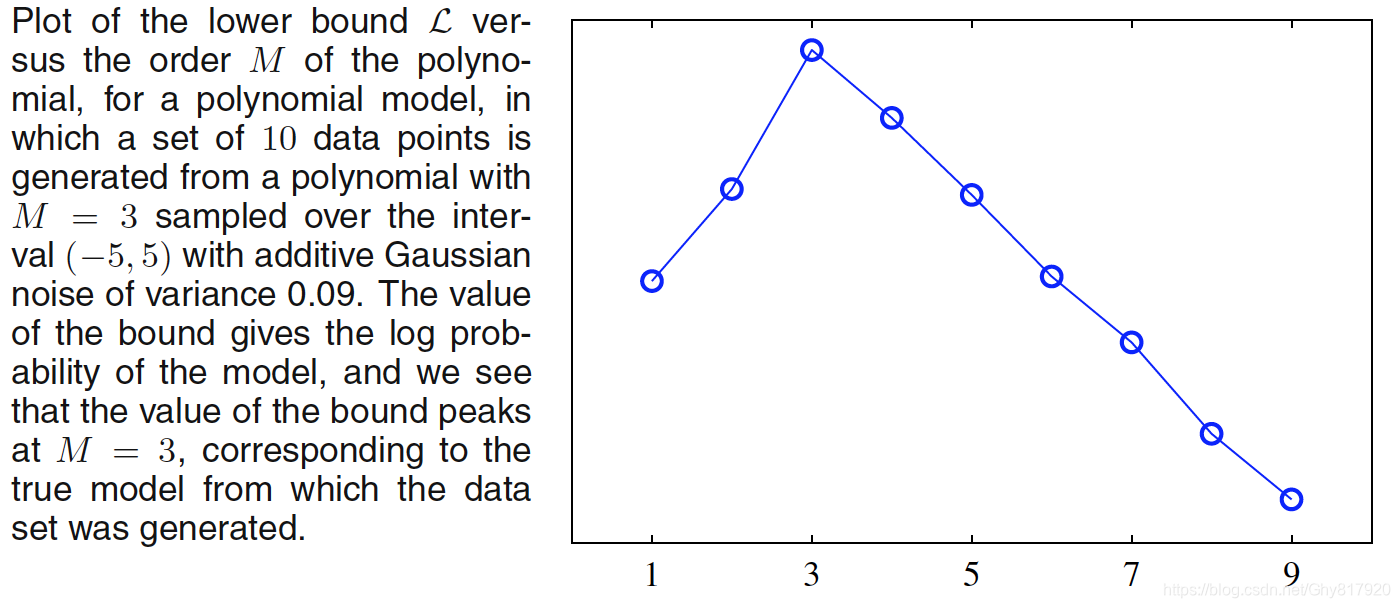
L
(
q
)
\mathcal{L}(q)
L(q)与多项式模型的阶数的关系图像,数据集是从⼀个三阶多项式中⼈⼯⽣成的。这⾥,先验参数被设置为
a
0
=
b
0
=
0
a_{0}=b_{0}=0
a0=b0=0,对应于⽆信息先验
p
(
α
)
∝
1
/
α
p(\alpha) \propto 1 / \alpha
p(α)∝1/α。根据2.3.6节的讨论,它是
l
n
α
ln\alpha
lnα 上的均匀分布。正如我们在10.1节看到的那样,
L
\mathcal{L}
L表⽰模型的对数边缘似然函数
p
(
M
∣
t
)
p(M | \mathbf{t})
p(M∣t)的下界。因此,变分框架将最⾼的概率赋予了
M
=
3
M = 3
M=3的模型。这与最⼤似然的结果相反。最⼤似然⽅法通过增加模型的复杂度尽可能地让误差变⼩,直到误差趋于零,这导致了最⼤似然⽅法倾向于选择具有严重过拟合现象的模型。
10.4 Exponential Family Distributions
考虑独⽴同分布数据的情形。我们将数据的值记作 X = { x n } \mathbf{X}=\left\{\mathbf{x}_{n}\right\} X={xn},其相应的隐变量为 Z = { z n } \mathbf{Z}=\left\{\mathbf{z}_{n}\right\} Z={zn},它们为指数族分布 p ( X , Z ∣ η ) = ∏ n = 1 N h ( x n , z n ) g ( η ) exp { η T u ( x n , z n ) } p(\mathbf{X}, \mathbf{Z} | \boldsymbol{\eta})=\prod_{n=1}^{N} h\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right) g(\boldsymbol{\eta}) \exp \left\{\boldsymbol{\eta}^{\mathrm{T}} \mathbf{u}\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right)\right\} p(X,Z∣η)=n=1∏Nh(xn,zn)g(η)exp{ηTu(xn,zn)}引入共轭先验 p ( η ∣ ν 0 , χ 0 ) = f ( ν 0 , χ 0 ) g ( η ) ν 0 exp { ν o η T χ 0 } p\left(\boldsymbol{\eta} | \nu_{0}, \boldsymbol{\chi}_{0}\right)=f\left(\nu_{0}, \boldsymbol{\chi}_{0}\right) g(\boldsymbol{\eta})^{\nu_{0}} \exp \left\{\nu_{o} \boldsymbol{\eta}^{\mathrm{T}} \boldsymbol{\chi}_{0}\right\} p(η∣ν0,χ0)=f(ν0,χ0)g(η)ν0exp{νoηTχ0}考虑变分分解为 q ( Z , η ) = q ( Z ) q ( η ) q(\mathbf{Z}, \boldsymbol{\eta})=q(\mathbf{Z}) q(\boldsymbol{\eta}) q(Z,η)=q(Z)q(η)则 ln q ⋆ ( Z ) = E η [ ln p ( X , Z ∣ η ) ] + const = ∑ n = 1 N { ln h ( x n , z n ) + E [ η T ] u ( x n , z n ) } + c o n s t . \begin{aligned} \ln q^{\star}(\mathbf{Z}) &=\mathbb{E}_{\eta}[\ln p(\mathbf{X}, \mathbf{Z} | \boldsymbol{\eta})]+\text { const } \\ &=\sum_{n=1}^{N}\left\{\ln h\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right)+\mathbb{E}\left[\boldsymbol{\eta}^{\mathrm{T}}\right] \mathbf{u}\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right)\right\}+\mathrm{const.} \end{aligned} lnq⋆(Z)=Eη[lnp(X,Z∣η)]+ const =n=1∑N{lnh(xn,zn)+E[ηT]u(xn,zn)}+const.那么可以诱导分解为 q ⋆ ( Z ) = ∏ n q ⋆ ( z n ) q^{\star}(\mathbf{Z})=\prod_{n} q^{\star}\left(\mathbf{z}_{n}\right) q⋆(Z)=∏nq⋆(zn)即 q ⋆ ( z n ) = h ( x n , z n ) g ( E [ η ] ) exp { E [ η T ] u ( x n , z n ) } q^{\star}\left(\mathbf{z}_{n}\right)=h\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right) g(\mathbb{E}[\boldsymbol{\eta}]) \exp \left\{\mathbb{E}\left[\boldsymbol{\eta}^{\mathrm{T}}\right] \mathbf{u}\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right)\right\} q⋆(zn)=h(xn,zn)g(E[η])exp{E[ηT]u(xn,zn)}同样地 ln q ⋆ ( η ) = ln p ( η ∣ ν 0 , χ 0 ) + E Z [ ln p ( X , Z ∣ η ) ] + const = ν 0 ln g ( η ) + η T χ 0 + ∑ n = 1 N { ln g ( η ) + η T E z n [ u ( x n , z n ) ] } + c o n s t . \begin{aligned} & \ln q^{\star}(\boldsymbol{\eta})=\ln p\left(\boldsymbol{\eta} | \nu_{0}, \boldsymbol{\chi}_{0}\right)+\mathbb{E}_{\mathbf{Z}}[\ln p(\mathbf{X}, \mathbf{Z} | \boldsymbol{\eta})]+\text { const } \\=& \nu_{0} \ln g(\boldsymbol{\eta})+\boldsymbol{\eta}^{\mathrm{T}} \boldsymbol{\chi}_{0}+\sum_{n=1}^{N}\left\{\ln g(\boldsymbol{\eta})+\boldsymbol{\eta}^{\mathrm{T}} \mathbb{E}_{\mathbf{z}_{n}}\left[\mathbf{u}\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right)\right]\right\}+\mathrm{const.} \end{aligned} =lnq⋆(η)=lnp(η∣ν0,χ0)+EZ[lnp(X,Z∣η)]+ const ν0lng(η)+ηTχ0+n=1∑N{lng(η)+ηTEzn[u(xn,zn)]}+const.进而 q ⋆ ( η ) = f ( ν N , χ N ) g ( η ) ν N exp { η T χ N } q^{\star}(\boldsymbol{\eta})=f\left(\nu_{N}, \boldsymbol{\chi}_{N}\right) g(\boldsymbol{\eta})^{\nu_{N}} \exp \left\{\boldsymbol{\eta}^{\mathrm{T}} \boldsymbol{\chi}_{N}\right\} q⋆(η)=f(νN,χN)g(η)νNexp{ηTχN}其中 ν N = ν 0 + N χ N = χ 0 + ∑ n = 1 N E z n [ u ( x n , z n ) ] \begin{aligned} \nu_{N} &=\nu_{0}+N \\ \chi_{N} &=\chi_{0}+\sum_{n=1}^{N} \mathbb{E}_{\mathbf{z}_{n}}\left[\mathbf{u}\left(\mathbf{x}_{n}, \mathbf{z}_{n}\right)\right] \end{aligned} νNχN=ν0+N=χ0+n=1∑NEzn[u(xn,zn)]所以可以迭代地更新这两个变分分布。
10.4.1 Variational message passing
我们通过详细讨论⼀个具体的模型来说明变分⽅法的应⽤,这个模型是⾼斯模型的贝叶斯混合。这个模型可以被表⽰为有向图。这⾥我们从更⼀般的⾓度来讨论由有向图描述的模型中对变分⽅法的使⽤,推导出⼀些具有⼴泛适⽤性的结果。
对于有向图有
p
(
x
)
=
∏
i
p
(
x
i
∣
p
a
i
)
p(\mathbf{x})=\prod_{i} p\left(\mathbf{x}_{i} | \mathrm{pa}_{i}\right)
p(x)=i∏p(xi∣pai)其中
x
i
\mathbf x_i
xi可能为观测变量也可能为隐变量,现在考虑一个变分近似
q
(
x
)
=
∏
i
q
i
(
x
i
)
q(\mathbf{x})=\prod_{i} q_{i}\left(\mathbf{x}_{i}\right)
q(x)=i∏qi(xi)注意,对于观测结点,在变分分布中没有因⼦
q
i
(
x
i
)
q_i(\mathbf x_i)
qi(xi)。那么
ln
q
j
⋆
(
x
j
)
=
E
i
≠
j
[
∑
i
ln
p
(
x
i
∣
p
a
i
)
]
+
c
o
n
s
t
.
\ln q_{j}^{\star}\left(\mathrm{x}_{j}\right)=\mathbb{E}_{i \neq j}\left[\sum_{i} \ln p\left(\mathrm{x}_{i} | \mathrm{pa}_{i}\right)\right]+\mathrm{const.}
lnqj⋆(xj)=Ei̸=j[i∑lnp(xi∣pai)]+const.
q
j
⋆
(
x
j
)
q_{j}^{\star}\left(\mathrm{x}_{j}\right)
qj⋆(xj)所依赖的所有结点组成的集合对应于结点
x
j
\mathbf x_j
xj的马尔科夫毯。也就是更新某一个节点只需要进行局部的计算即可。如果我们现在确定模型的形式,其中所有的条件概率分布都有⼀个共轭-指数族的结构,那么变分推断的过程可以被转化为局部信息传递算法(Winn and Bishop, 2005)。特别地,对于⼀个特定的结点来说,⼀旦它接收到了来⾃所有的⽗结点和所有的⼦结点的信息,那么与这个结点相关联的概率分布就可以被更新。这反过来需要⼦结点从它们的同⽗结点已经接收完毕信息。下界的计算也可以得到简化,因为许多必要的值已经作为信息传递框架的⼀部分计算完毕。分布的信息传递形式有很好的缩放性质,对于⼤的⽹络很合适。
10.5. Local Variational Methods
10.1节和10.2节讨论的变分框架可以被看做“全局”⽅法。之所以这样说,是因为它直接寻找所有随机变量上的完整的后验概率分布的近似。另⼀种“局部”的⽅法涉及到寻找模型中的单独的变量或者变量组上定义的函数的界限。
对于凹函数有
f
(
x
)
=
max
λ
{
λ
x
−
g
(
λ
)
}
g
(
λ
)
=
max
x
{
λ
x
−
f
(
x
)
}
\begin{aligned} f(x) &=\max _{\lambda}\{\lambda x-g(\lambda)\} \\ g(\lambda) &=\max _{x}\{\lambda x-f(x)\} \end{aligned}
f(x)g(λ)=λmax{λx−g(λ)}=xmax{λx−f(x)}凸函数有
f
(
x
)
=
min
λ
{
λ
x
−
g
(
λ
)
}
g
(
λ
)
=
min
x
{
λ
x
−
f
(
x
)
}
\begin{aligned} f(x) &=\min _{\lambda}\{\lambda x-g(\lambda)\} \\ g(\lambda) &=\min _{x}\{\lambda x-f(x)\} \end{aligned}
f(x)g(λ)=λmin{λx−g(λ)}=xmin{λx−f(x)}
但对于不凸不凹的函数,只能寻求一种可逆变化,对于
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac{1}{1+e^{-x}}
σ(x)=1+e−x1取log之后就称为一个凸函数,从而
g
(
λ
)
=
min
x
{
λ
x
−
f
(
x
)
}
=
−
λ
ln
λ
−
(
1
−
λ
)
ln
(
1
−
λ
)
g(\lambda)=\min _{x}\{\lambda x-f(x)\}=-\lambda \ln \lambda-(1-\lambda) \ln (1-\lambda)
g(λ)=xmin{λx−f(x)}=−λlnλ−(1−λ)ln(1−λ)这样就得到了一个upper bound
ln
σ
(
x
)
⩽
λ
x
−
g
(
λ
)
\ln \sigma(x) \leqslant \lambda x-g(\lambda)
lnσ(x)⩽λx−g(λ)则
σ
(
x
)
⩽
exp
(
λ
x
−
g
(
λ
)
)
\sigma(x) \leqslant \exp (\lambda x-g(\lambda))
σ(x)⩽exp(λx−g(λ))
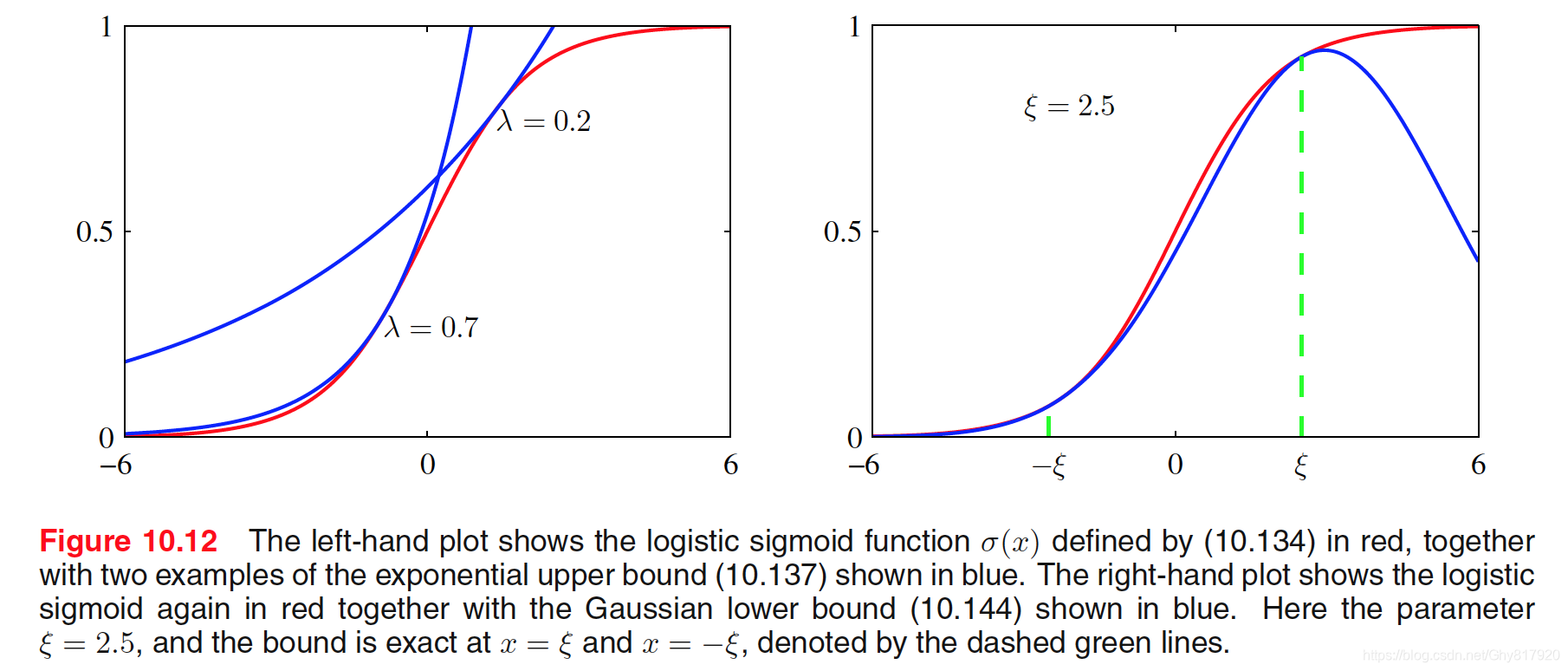
我们还可以得到其lower bound
ln
σ
(
x
)
=
−
ln
(
1
+
e
−
x
)
=
−
ln
{
e
−
x
/
2
(
e
x
/
2
+
e
−
x
/
2
)
}
=
x
/
2
−
ln
(
e
x
/
2
+
e
−
x
/
2
)
\begin{aligned} \ln \sigma(x) &=-\ln \left(1+e^{-x}\right)=-\ln \left\{e^{-x / 2}\left(e^{x / 2}+e^{-x / 2}\right)\right\} \\ &=x / 2-\ln \left(e^{x / 2}+e^{-x / 2}\right) \end{aligned}
lnσ(x)=−ln(1+e−x)=−ln{e−x/2(ex/2+e−x/2)}=x/2−ln(ex/2+e−x/2)其中
f
(
x
)
=
−
ln
(
e
x
/
2
+
e
−
x
/
2
)
f(x)=-\ln \left(e^{x / 2}+e^{-x / 2}\right)
f(x)=−ln(ex/2+e−x/2)为
x
2
x^2
x2凹函数,可以通过求二阶导数证明。这样
g
(
λ
)
=
max
x
2
{
λ
x
2
−
f
(
x
2
)
}
g(\lambda)=\max _{x^{2}}\left\{\lambda x^{2}-f\left(\sqrt{x^{2}}\right)\right\}
g(λ)=x2max{λx2−f(x2)}则求导为
0
=
λ
−
d
x
d
x
2
d
d
x
f
(
x
)
=
λ
+
1
4
x
tanh
(
x
2
)
0=\lambda-\frac{d x}{d x^{2}} \frac{d}{d x} f(x)=\lambda+\frac{1}{4 x} \tanh \left(\frac{x}{2}\right)
0=λ−dx2dxdxdf(x)=λ+4x1tanh(2x)这是一个关于
x
x
x的值
λ
(
ξ
)
=
−
1
4
ξ
tanh
(
ξ
2
)
=
−
1
2
ξ
[
σ
(
ξ
)
−
1
2
]
\lambda(\xi)=-\frac{1}{4 \xi} \tanh \left(\frac{\xi}{2}\right)=-\frac{1}{2 \xi}\left[\sigma(\xi)-\frac{1}{2}\right]
λ(ξ)=−4ξ1tanh(2ξ)=−2ξ1[σ(ξ)−21]我们将
ξ
\xi
ξ看作变分参数,则
g
(
λ
)
=
λ
(
ξ
)
ξ
2
−
f
(
ξ
)
=
λ
(
ξ
)
ξ
2
+
ln
(
e
ξ
/
2
+
e
−
ξ
/
2
)
g(\lambda)=\lambda(\xi) \xi^{2}-f(\xi)=\lambda(\xi) \xi^{2}+\ln \left(e^{\xi / 2}+e^{-\xi / 2}\right)
g(λ)=λ(ξ)ξ2−f(ξ)=λ(ξ)ξ2+ln(eξ/2+e−ξ/2)从而
f
(
x
)
⩾
λ
x
2
−
g
(
λ
)
=
λ
x
2
−
λ
ξ
2
−
ln
(
e
ξ
/
2
+
e
−
ξ
/
2
)
f(x) \geqslant \lambda x^{2}-g(\lambda)=\lambda x^{2}-\lambda \xi^{2}-\ln \left(e^{\xi / 2}+e^{-\xi / 2}\right)
f(x)⩾λx2−g(λ)=λx2−λξ2−ln(eξ/2+e−ξ/2)则
σ
(
x
)
⩾
σ
(
ξ
)
exp
{
(
x
−
ξ
)
/
2
−
λ
(
ξ
)
(
x
2
−
ξ
2
)
}
\sigma(x) \geqslant \sigma(\xi) \exp \left\{(x-\xi) / 2-\lambda(\xi)\left(x^{2}-\xi^{2}\right)\right\}
σ(x)⩾σ(ξ)exp{(x−ξ)/2−λ(ξ)(x2−ξ2)}下面来说说具体怎么使用,当计算
I
=
∫
σ
(
a
)
p
(
a
)
d
a
I=\int \sigma(a) p(a) \mathrm{d} a
I=∫σ(a)p(a)da时,
p
(
a
)
p(a)
p(a)往往为高斯分布,这样是没法求得,因此可以使用局部变分
σ
(
a
)
⩾
f
(
a
,
ξ
)
\sigma(a) \geqslant f(a, \xi)
σ(a)⩾f(a,ξ),则
I
⩾
∫
f
(
a
,
ξ
)
p
(
a
)
d
a
=
F
(
ξ
)
I \geqslant \int f(a, \xi) p(a) \mathrm{d} a=F(\xi)
I⩾∫f(a,ξ)p(a)da=F(ξ)

10.6 Variational Logistic Regression
我们现在回到4.5节研究的贝叶斯logistic回归模型,说明局部变分⽅法的应⽤。在4.5节,我们将注意⼒集中于拉普拉斯近似的使⽤,⽽这⾥,我们考虑⼀种贝叶斯的⽅法,本⽅法基于Jaakkola and Jordan(2000)的⽅法。与拉普拉斯⽅法相似,这也会⽣成后验概率分布的⾼斯近似。然⽽,变分⽅法的极⼤的灵活性使得模型的准确率与拉普拉斯相⽐有所提升。此外,与拉普拉斯⽅法不同,变分⽅法最优化⼀个具有良好定义的⽬标函数,这个⽬标函数由模型证据的⼀个严格界限给定。Dybowski and Roberts(2005)也从贝叶斯的⾓度研究了logistic回归问题,使⽤了蒙特卡罗取样的技术。
10.6.1 Variational posterior distribution
首先假设先验超参数固定 m 0 \mathbf{m}_{0} m0 and S 0 \mathbf{S}_{0} S0。 p ( t ) = ∫ p ( t ∣ w ) p ( w ) d w = ∫ [ ∏ n = 1 N p ( t n ∣ w ) ] p ( w ) d w p(\mathbf{t})=\int p(\mathbf{t} | \mathbf{w}) p(\mathbf{w}) \mathrm{d} \mathbf{w}=\int\left[\prod_{n=1}^{N} p\left(t_{n} | \mathbf{w}\right)\right] p(\mathbf{w}) \mathrm{d} \mathbf{w} p(t)=∫p(t∣w)p(w)dw=∫[n=1∏Np(tn∣w)]p(w)dw似然为 p ( t ∣ w ) = σ ( a ) t { 1 − σ ( a ) } 1 − t = ( 1 1 + e − a ) t ( 1 − 1 1 + e − a ) 1 − t = e a t e − a 1 + e − a = e a t σ ( − a ) \begin{aligned} p(t | \mathbf{w}) &=\sigma(a)^{t}\{1-\sigma(a)\}^{1-t} \\ &=\left(\frac{1}{1+e^{-a}}\right)^{t}\left(1-\frac{1}{1+e^{-a}}\right)^{1-t} \\ &=e^{a t} \frac{e^{-a}}{1+e^{-a}}=e^{a t} \sigma(-a) \end{aligned} p(t∣w)=σ(a)t{1−σ(a)}1−t=(1+e−a1)t(1−1+e−a1)1−t=eat1+e−ae−a=eatσ(−a)其中 a = w T ϕ a=\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi} a=wTϕ,为了获得 p ( t ) p(\mathbf{t}) p(t)的lower bound,由之前的上一节推导的结果可知 σ ( z ) ⩾ σ ( ξ ) exp { ( z − ξ ) / 2 − λ ( ξ ) ( z 2 − ξ 2 ) } \sigma(z) \geqslant \sigma(\xi) \exp \left\{(z-\xi) / 2-\lambda(\xi)\left(z^{2}-\xi^{2}\right)\right\} σ(z)⩾σ(ξ)exp{(z−ξ)/2−λ(ξ)(z2−ξ2)}其中 λ ( ξ ) = 1 2 ξ [ σ ( ξ ) − 1 2 ] \lambda(\xi)=\frac{1}{2 \xi}\left[\sigma(\xi)-\frac{1}{2}\right] λ(ξ)=2ξ1[σ(ξ)−21]则 p ( t ∣ w ) = e a t σ ( − a ) ⩾ e a t σ ( ξ ) exp { − ( a + ξ ) / 2 − λ ( ξ ) ( a 2 − ξ 2 ) } p(t | \mathbf{w})=e^{a t} \sigma(-a) \geqslant e^{a t} \sigma(\xi) \exp \left\{-(a+\xi) / 2-\lambda(\xi)\left(a^{2}-\xi^{2}\right)\right\} p(t∣w)=eatσ(−a)⩾eatσ(ξ)exp{−(a+ξ)/2−λ(ξ)(a2−ξ2)}注意,由于这个下界分别作⽤于似然函数的每⼀项,因此存在⼀个变分参数 ξ n \xi_{n} ξn,对应于训练集的每个观测 ( ϕ n , t n ) \left(\phi_{n}, t_{n}\right) (ϕn,tn)。使⽤ a = w T ϕ a=\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi} a=wTϕ,乘以先验概率分布,我们可以得到下⾯的 t \mathbf t t和 w \mathbf w w的联合概率分布。 p ( t , w ) = p ( t ∣ w ) p ( w ) ⩾ h ( w , ξ ) p ( w ) p(\mathbf{t}, \mathbf{w})=p(\mathbf{t} | \mathbf{w}) p(\mathbf{w}) \geqslant h(\mathbf{w}, \boldsymbol{\xi}) p(\mathbf{w}) p(t,w)=p(t∣w)p(w)⩾h(w,ξ)p(w)其中 h ( w , ξ ) = ∏ n = 1 N σ ( ξ n ) exp { w T ϕ n t n − ( w T ϕ n + ξ n ) / 2 − λ ( ξ n ) ( [ w T ϕ n ] 2 − ξ n 2 ) } \begin{aligned} h(\mathbf{w}, \boldsymbol{\xi})=& \prod_{n=1}^{N} \sigma\left(\xi_{n}\right) \exp \left\{\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n} t_{n}-\left(\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}+\xi_{n}\right) / 2\right.\\ &-\lambda\left(\xi_{n}\right)\left(\left[\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}\right]^{2}-\xi_{n}^{2}\right) \} \end{aligned} h(w,ξ)=n=1∏Nσ(ξn)exp{wTϕntn−(wTϕn+ξn)/2−λ(ξn)([wTϕn]2−ξn2)}取ln ln { p ( t ∣ w ) p ( w ) } ⩾ ln p ( w ) + ∑ n = 1 N { ln σ ( ξ n ) + w T ϕ n t n − ( w T ϕ n + ξ n ) / 2 − λ ( ξ n ) ( [ w T ϕ n ] 2 − ξ n 2 ) } \begin{array}{c}{\ln \{p(\mathbf{t} | \mathbf{w}) p(\mathbf{w})\} \geqslant \ln p(\mathbf{w})+\sum_{n=1}^{N}\left\{\ln \sigma\left(\xi_{n}\right)+\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n} t_{n}\right.} \\ {-\left(\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}+\xi_{n}\right) / 2-\lambda\left(\xi_{n}\right)\left(\left[\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}\right]^{2}-\xi_{n}^{2}\right) \}}\end{array} ln{p(t∣w)p(w)}⩾lnp(w)+∑n=1N{lnσ(ξn)+wTϕntn−(wTϕn+ξn)/2−λ(ξn)([wTϕn]2−ξn2)}将先验代入 − 1 2 ( w − m 0 ) T S 0 − 1 ( w − m 0 ) + ∑ n = 1 N { w T ϕ n ( t n − 1 / 2 ) − λ ( ξ n ) w T ( ϕ n ϕ n T ) w } + c o n s t . \begin{array}{c}{-\frac{1}{2}\left(\mathbf{w}-\mathbf{m}_{0}\right)^{\mathrm{T}} \mathbf{S}_{0}^{-1}\left(\mathbf{w}-\mathbf{m}_{0}\right)} \\ {+\sum_{n=1}^{N}\left\{\mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}\left(t_{n}-1 / 2\right)-\lambda\left(\xi_{n}\right) \mathbf{w}^{\mathrm{T}}\left(\boldsymbol{\phi}_{n} \boldsymbol{\phi}_{n}^{\mathrm{T}}\right) \mathbf{w}\right\}+\mathrm{const.}}\end{array} −21(w−m0)TS0−1(w−m0)+∑n=1N{wTϕn(tn−1/2)−λ(ξn)wT(ϕnϕnT)w}+const.这刚好为 w \mathbf w w的二次函数,则说明后验为一个高斯 q ( w ) = N ( w ∣ m N , S N ) q(\mathbf{w})=\mathcal{N}\left(\mathbf{w} | \mathbf{m}_{N}, \mathbf{S}_{N}\right) q(w)=N(w∣mN,SN)其中 m N = S N ( S 0 − 1 m 0 + ∑ n = 1 N ( t n − 1 / 2 ) ϕ n ) S N − 1 = S 0 − 1 + 2 ∑ n = 1 N λ ( ξ n ) ϕ n ϕ n T \begin{aligned} \mathbf{m}_{N} &=\mathbf{S}_{N}\left(\mathbf{S}_{0}^{-1} \mathbf{m}_{0}+\sum_{n=1}^{N}\left(t_{n}-1 / 2\right) \boldsymbol{\phi}_{n}\right) \\ \mathbf{S}_{N}^{-1} &=\mathbf{S}_{0}^{-1}+2 \sum_{n=1}^{N} \lambda\left(\xi_{n}\right) \boldsymbol{\phi}_{n} \boldsymbol{\phi}_{n}^{\mathrm{T}} \end{aligned} mNSN−1=SN(S0−1m0+n=1∑N(tn−1/2)ϕn)=S0−1+2n=1∑Nλ(ξn)ϕnϕnT与Laplace framework一样,得到了一个近似后验的高斯分布。然后,变分参数 { ξ n } \left\{\xi_{n}\right\} {ξn}提供的额外的灵活性使得这个近似的精度更⾼
10.6.2 Optimizing the variational parameters
我们现在得到了后验概率分布的⼀个归⼀化的⾼斯近似。我们稍后会使⽤这个近似得到对于新数据的预测分布。然⽽,⾸先我们需要通过最⼤化边缘似然函数的下界,确定变分参数
{
ξ
n
}
\left\{\xi_{n}\right\}
{ξn}。
ln
p
(
t
)
=
ln
∫
p
(
t
∣
w
)
p
(
w
)
d
w
⩾
ln
∫
h
(
w
,
ξ
)
p
(
w
)
d
w
=
L
(
ξ
)
\ln p(\mathbf{t})=\ln \int p(\mathbf{t} | \mathbf{w}) p(\mathbf{w}) \mathrm{d} \mathbf{w} \geqslant \ln \int h(\mathbf{w}, \boldsymbol{\xi}) p(\mathbf{w}) \mathrm{d} \mathbf{w}=\mathcal{L}(\boldsymbol{\xi})
lnp(t)=ln∫p(t∣w)p(w)dw⩾ln∫h(w,ξ)p(w)dw=L(ξ)与3.5节的线性回归模型的超参数
α
\alpha
α的最优化⼀样,有两种⽅法确定
{
ξ
n
}
\left\{\xi_{n}\right\}
{ξn}。在第⼀种⽅法中,我们看到函数
L
(
ξ
)
\mathcal{L}(\boldsymbol{\xi})
L(ξ)由
w
\mathbf w
w上的积分定义,因此我们可以将
w
\mathbf w
w看成⼀个潜在变量,然后使⽤EM算法。在第⼆种⽅法中,我们解析地对
w
\mathbf w
w积分,然后直接关于
ξ
\xi
ξ进⾏最⼤化。让我们⾸先考虑EM⽅法。
首先初始化
{
ξ
n
}
\left\{\xi_{n}\right\}
{ξn},记作
ξ
o
l
d
\boldsymbol{\xi}^{\mathrm{old}}
ξold,在E-step找到关于
w
\mathbf w
w的后验
q
(
w
)
=
N
(
w
∣
m
N
,
S
N
)
q(\mathbf{w})=\mathcal{N}\left(\mathbf{w} | \mathbf{m}_{N}, \mathbf{S}_{N}\right)
q(w)=N(w∣mN,SN)在M-step
Q
(
ξ
,
ξ
o
l
d
)
=
E
[
ln
h
(
w
,
ξ
)
p
(
w
)
]
Q\left(\boldsymbol{\xi}, \boldsymbol{\xi}^{\mathrm{old}}\right)=\mathbb{E}[\ln h(\mathbf{w}, \boldsymbol{\xi}) p(\mathbf{w})]
Q(ξ,ξold)=E[lnh(w,ξ)p(w)]
Q
(
ξ
,
ξ
old
)
=
∑
n
=
1
N
{
ln
σ
(
ξ
n
)
−
ξ
n
/
2
−
λ
(
ξ
n
)
(
ϕ
n
T
E
[
w
W
T
]
ϕ
n
−
ξ
n
2
)
}
+
const
Q\left(\boldsymbol{\xi}, \boldsymbol{\xi}^{\text { old }}\right)=\sum_{n=1}^{N}\left\{\ln \sigma\left(\xi_{n}\right)-\xi_{n} / 2-\lambda\left(\xi_{n}\right)\left(\boldsymbol{\phi}_{n}^{\mathrm{T}} \mathbb{E}\left[\mathbf{w} \mathbf{W}^{\mathrm{T}}\right] \boldsymbol{\phi}_{n}-\xi_{n}^{2}\right)\right\}+\text { const }
Q(ξ,ξ old )=n=1∑N{lnσ(ξn)−ξn/2−λ(ξn)(ϕnTE[wWT]ϕn−ξn2)}+ const 求导为0
0
=
λ
′
(
ξ
n
)
(
ϕ
n
T
E
[
w
w
T
]
ϕ
n
−
ξ
n
2
)
0=\lambda^{\prime}\left(\xi_{n}\right)\left(\phi_{n}^{\mathrm{T}} \mathbb{E}\left[\mathbf{w} \mathbf{w}^{\mathrm{T}}\right] \boldsymbol{\phi}_{n}-\xi_{n}^{2}\right)
0=λ′(ξn)(ϕnTE[wwT]ϕn−ξn2)可以得到
(
ξ
n
new
)
2
=
ϕ
n
T
E
[
w
w
T
]
ϕ
n
=
ϕ
n
T
(
S
N
+
m
N
m
N
T
)
ϕ
n
\left(\xi_{n}^{\text { new }}\right)^{2}=\phi_{n}^{\mathrm{T}} \mathbb{E}\left[\mathbf{w} \mathbf{w}^{\mathrm{T}}\right] \boldsymbol{\phi}_{n}=\boldsymbol{\phi}_{n}^{\mathrm{T}}\left(\mathbf{S}_{N}+\mathbf{m}_{N} \mathbf{m}_{N}^{\mathrm{T}}\right) \boldsymbol{\phi}_{n}
(ξn new )2=ϕnTE[wwT]ϕn=ϕnT(SN+mNmNT)ϕn这样就可以迭代地更新变分参数。注意到这个lower bound是可以关于
w
\mathbf w
w积分的,然后直接对
ξ
\xi
ξ求导也能得到和EM一样的结果。
L
(
ξ
)
=
1
2
ln
∣
S
N
∣
∣
S
0
∣
−
1
2
m
N
T
S
N
−
1
m
N
+
1
2
m
0
T
S
0
−
1
m
0
+
∑
n
=
1
N
{
ln
σ
(
ξ
n
)
−
1
2
ξ
n
−
λ
(
ξ
n
)
ξ
n
2
}
\begin{aligned} \mathcal{L}(\boldsymbol{\xi})=& \frac{1}{2} \ln \frac{\left|\mathbf{S}_{N}\right|}{\left|\mathbf{S}_{0}\right|}-\frac{1}{2} \mathbf{m}_{N}^{\mathrm{T}} \mathbf{S}_{N}^{-1} \mathbf{m}_{N}+\frac{1}{2} \mathbf{m}_{0}^{\mathrm{T}} \mathbf{S}_{0}^{-1} \mathbf{m}_{0} \\ &+\sum_{n=1}^{N}\left\{\ln \sigma\left(\xi_{n}\right)-\frac{1}{2} \xi_{n}-\lambda\left(\xi_{n}\right) \xi_{n}^{2}\right\} \end{aligned}
L(ξ)=21ln∣S0∣∣SN∣−21mNTSN−1mN+21m0TS0−1m0+n=1∑N{lnσ(ξn)−21ξn−λ(ξn)ξn2}下图为一个具体例子
10.6.3 Inference of hyperparameters
⽬前为⽌,我们将先验概率分布的超参数
α
\alpha
α看成⼀个已知参数。我们现在将贝叶斯logistic回归模型进⾏推⼴,使得这个参数的值可以从数据集中推断出来。这可以通过将全局变分近似和局部变分近似结合到⼀个框架中的⽅式完成,从⽽在每个阶段都保留边缘似然函数的下界
特别地,我们再次考虑⼀个简单的各向同性的⾼斯先验概率分布,形式为
p
(
w
∣
α
)
=
N
(
w
∣
0
,
α
−
1
I
)
p(\mathbf{w} | \alpha)=\mathcal{N}\left(\mathbf{w} | \mathbf{0}, \alpha^{-1} \mathbf{I}\right)
p(w∣α)=N(w∣0,α−1I)引入超先验
p
(
α
)
=
Gam
(
α
∣
a
0
,
b
0
)
p(\alpha)=\operatorname{Gam}\left(\alpha | a_{0}, b_{0}\right)
p(α)=Gam(α∣a0,b0)则边缘似然为
p
(
t
)
=
∬
p
(
w
,
α
,
t
)
d
w
d
α
p(\mathbf{t})=\iint p(\mathbf{w}, \alpha, \mathbf{t}) \mathrm{d} \mathbf{w} \mathrm{d} \alpha
p(t)=∬p(w,α,t)dwdα
p
(
w
,
α
,
t
)
=
p
(
t
∣
w
)
p
(
w
∣
α
)
p
(
α
)
p(\mathbf{w}, \alpha, \mathbf{t})=p(\mathbf{t} | \mathbf{w}) p(\mathbf{w} | \alpha) p(\alpha)
p(w,α,t)=p(t∣w)p(w∣α)p(α)然而上式是没法解析处理的,我们会在同⼀个模型中使⽤全局的变分⽅法和局部的变分⽅法来解决这个问题。
⾸先,我们引⼊⼀个变分分布
q
(
w
,
α
)
q(\mathbf{w}, \alpha)
q(w,α),则有
ln
p
(
t
)
=
L
(
q
)
+
K
L
(
q
∥
p
)
\ln p(\mathbf{t})=\mathcal{L}(q)+\mathrm{KL}(q \| p)
lnp(t)=L(q)+KL(q∥p)其中
L
(
q
)
=
∬
q
(
w
,
α
)
ln
{
p
(
w
,
α
,
t
)
q
(
w
,
α
)
}
d
w
d
α
K
L
(
q
∥
p
)
=
−
∬
q
(
w
,
α
)
ln
{
p
(
w
,
α
∣
t
)
)
q
(
w
,
α
)
}
d
w
d
α
\begin{aligned} \mathcal{L}(q) &=\iint q(\mathbf{w}, \alpha) \ln \left\{\frac{p(\mathbf{w}, \alpha, \mathbf{t})}{q(\mathbf{w}, \alpha)}\right\} \mathrm{d} \mathbf{w} \mathrm{d} \alpha \\ \mathrm{KL}(q \| p) &=-\iint q(\mathbf{w}, \alpha) \ln \left\{\frac{p(\mathbf{w}, \alpha | \mathbf{t}) )}{q(\mathbf{w}, \alpha)}\right\} \mathrm{d} \mathbf{w} \mathrm{d} \alpha \end{aligned}
L(q)KL(q∥p)=∬q(w,α)ln{q(w,α)p(w,α,t)}dwdα=−∬q(w,α)ln{q(w,α)p(w,α∣t))}dwdα然而这个lower bound仍然不可处理,由于
p
(
t
∣
w
)
p(\mathbf{t} | \mathbf{w})
p(t∣w)。那么可以考虑使用一个局部变分
ln
p
(
t
)
⩾
L
(
q
)
⩾
L
~
(
q
,
ξ
)
=
∬
q
(
w
,
α
)
ln
{
h
(
w
,
ξ
)
p
(
w
∣
α
)
p
(
α
)
q
(
w
,
α
)
}
d
w
d
α
\begin{aligned} \ln p(\mathbf{t}) & \geqslant \mathcal{L}(q) \geqslant \widetilde{\mathcal{L}}(q, \boldsymbol{\xi}) \\ &=\iint q(\mathbf{w}, \alpha) \ln \left\{\frac{h(\mathbf{w}, \boldsymbol{\xi}) p(\mathbf{w} | \alpha) p(\alpha)}{q(\mathbf{w}, \alpha)}\right\} \mathrm{d} \mathbf{w} \mathrm{d} \alpha \end{aligned}
lnp(t)⩾L(q)⩾L
(q,ξ)=∬q(w,α)ln{q(w,α)h(w,ξ)p(w∣α)p(α)}dwdα接下来我们假设变分分布可以在参数和超参数之间进⾏分解,即
q
(
w
,
α
)
=
q
(
w
)
q
(
α
)
q(\mathbf{w}, \alpha)=q(\mathbf{w}) q(\alpha)
q(w,α)=q(w)q(α)按照变分
ln
q
(
w
)
=
E
α
[
ln
{
h
(
w
,
ξ
)
p
(
w
∣
α
)
p
(
α
)
}
]
+
c
o
n
s
t
=
ln
h
(
w
,
ξ
)
+
E
α
[
ln
p
(
w
∣
α
)
]
+
c
o
n
s
t
.
\begin{aligned} \ln q(\mathbf{w}) &=\mathbb{E}_{\alpha}[\ln \{h(\mathbf{w}, \boldsymbol{\xi}) p(\mathbf{w} | \alpha) p(\alpha)\}]+\mathrm{const} \\ &=\ln h(\mathbf{w}, \boldsymbol{\xi})+\mathbb{E}_{\alpha}[\ln p(\mathbf{w} | \alpha)]+\mathrm{const.} \end{aligned}
lnq(w)=Eα[ln{h(w,ξ)p(w∣α)p(α)}]+const=lnh(w,ξ)+Eα[lnp(w∣α)]+const.代入后
ln
q
(
w
)
=
−
E
[
α
]
2
w
T
w
+
∑
n
=
1
N
{
(
t
n
−
1
/
2
)
w
T
ϕ
n
−
λ
(
ξ
n
)
w
T
ϕ
n
ϕ
n
T
w
}
+
const.
\ln q(\mathbf{w})=-\frac{\mathbb{E}[\alpha]}{2} \mathbf{w}^{\mathrm{T}} \mathbf{w}+\sum_{n=1}^{N}\left\{\left(t_{n}-1 / 2\right) \mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n}-\lambda\left(\xi_{n}\right) \mathbf{w}^{\mathrm{T}} \boldsymbol{\phi}_{n} \boldsymbol{\phi}_{n}^{\mathrm{T}} \mathbf{w}\right\}+\text { const. }
lnq(w)=−2E[α]wTw+n=1∑N{(tn−1/2)wTϕn−λ(ξn)wTϕnϕnTw}+ const. 可以发现其为高斯
q
(
w
)
=
N
(
w
∣
μ
N
,
Σ
N
)
q(\mathbf{w})=\mathcal{N}\left(\mathbf{w} | \boldsymbol{\mu}_{N}, \mathbf{\Sigma}_{N}\right)
q(w)=N(w∣μN,ΣN)其中
Σ
N
−
1
μ
N
=
∑
n
=
1
N
(
t
n
−
1
/
2
)
ϕ
n
Σ
N
−
1
=
E
[
α
]
I
+
2
∑
n
=
1
N
λ
(
ξ
n
)
ϕ
n
ϕ
n
T
\begin{aligned} \boldsymbol{\Sigma}_{N}^{-1} \boldsymbol{\mu}_{N} &=\sum_{n=1}^{N}\left(t_{n}-1 / 2\right) \boldsymbol{\phi}_{n} \\ \boldsymbol{\Sigma}_{N}^{-1} &=\mathbb{E}[\alpha] \mathbf{I}+2 \sum_{n=1}^{N} \lambda\left(\xi_{n}\right) \boldsymbol{\phi}_{n} \boldsymbol{\phi}_{n}^{\mathrm{T}} \end{aligned}
ΣN−1μNΣN−1=n=1∑N(tn−1/2)ϕn=E[α]I+2n=1∑Nλ(ξn)ϕnϕnT同样的
ln
q
(
α
)
=
E
w
[
ln
p
(
w
∣
α
)
]
+
ln
p
(
α
)
+
c
o
n
s
t
.
\ln q(\alpha)=\mathbb{E}_{\mathbf{w}}[\ln p(\mathbf{w} | \alpha)]+\ln p(\alpha)+\mathrm{const.}
lnq(α)=Ew[lnp(w∣α)]+lnp(α)+const.
ln
q
(
α
)
=
M
2
ln
α
−
α
2
E
[
w
T
w
]
+
(
a
0
−
1
)
ln
α
−
b
0
α
+
c
o
n
s
t
.
\ln q(\alpha)=\frac{M}{2} \ln \alpha-\frac{\alpha}{2} \mathbb{E}\left[\mathbf{w}^{\mathrm{T}} \mathbf{w}\right]+\left(a_{0}-1\right) \ln \alpha-b_{0} \alpha+\mathrm{const.}
lnq(α)=2Mlnα−2αE[wTw]+(a0−1)lnα−b0α+const.
q
(
α
)
=
Gam
(
α
∣
a
N
,
b
N
)
=
1
Γ
(
a
0
)
a
0
b
0
α
a
0
−
1
e
−
b
0
α
q(\alpha)=\operatorname{Gam}\left(\alpha | a_{N}, b_{N}\right)=\frac{1}{\Gamma\left(a_{0}\right)} a_{0}^{b_{0}} \alpha^{a_{0}-1} e^{-b_{0} \alpha}
q(α)=Gam(α∣aN,bN)=Γ(a0)1a0b0αa0−1e−b0α其中
a
N
=
a
0
+
M
2
b
N
=
b
0
+
1
2
E
w
[
w
T
w
]
\begin{aligned} a_{N} &=a_{0}+\frac{M}{2} \\ b_{N} &=b_{0}+\frac{1}{2} \mathbb{E}_{\mathbf{w}}\left[\mathbf{w}^{\mathrm{T}} \mathbf{w}\right] \end{aligned}
aNbN=a0+2M=b0+21Ew[wTw]我们还需要最优化变分参数
ξ
n
\xi_{n}
ξn,这也可以通过最⼤化下界
L
~
(
q
,
ξ
)
\widetilde{\mathcal{L}}(q, \boldsymbol{\xi})
L
(q,ξ)的⽅式得到。略去与
ξ
\xi
ξ⽆关的项,对
α
\alpha
α积分,我们有
L
~
(
q
,
ξ
)
=
∫
q
(
w
)
ln
h
(
w
,
ξ
)
d
w
+
c
o
n
s
t
.
\widetilde{\mathcal{L}}(q, \boldsymbol{\xi})=\int q(\mathbf{w}) \ln h(\mathbf{w}, \boldsymbol{\xi}) \mathrm{d} \mathbf{w}+\mathrm{const.}
L
(q,ξ)=∫q(w)lnh(w,ξ)dw+const.这个与之前推导的结果一样,则
(
ξ
n
new
)
2
=
ϕ
n
T
(
Σ
N
+
μ
N
μ
N
T
)
ϕ
n
\left(\xi_{n}^{\text { new }}\right)^{2}=\phi_{n}^{\mathrm{T}}\left(\boldsymbol{\Sigma}_{N}+\boldsymbol{\mu}_{N} \boldsymbol{\mu}_{N}^{\mathrm{T}}\right) \boldsymbol{\phi}_{n}
(ξn new )2=ϕnT(ΣN+μNμNT)ϕn这样就能迭代起来了。
10.7 Expectation Propagation
在本章的最后⼀节,我们讨论确定性近似推断的另⼀种形式,被称为期望传播(expectation propagation),或者EP(Minka, 2001a; Minka, 2001b)。与⽬前为⽌讨论的变分贝叶斯⽅法相同,这种⽅法也基于对Kullback-Leibler散度的最⼩化,但是现在形式相反,从⽽得到了性质相当不同的近似结果。
考虑最小化
K
L
(
p
∥
q
)
\mathrm{KL}(p \| q)
KL(p∥q),其中
p
(
z
)
p(\mathbf{z})
p(z)固定,且
q
(
z
)
q(\mathbf{z})
q(z)为指数族分布。
q
(
z
)
=
h
(
z
)
g
(
η
)
exp
{
η
T
u
(
z
)
}
q(\mathbf{z})=h(\mathbf{z}) g(\boldsymbol{\eta}) \exp \left\{\boldsymbol{\eta}^{\mathrm{T}} \mathbf{u}(\mathbf{z})\right\}
q(z)=h(z)g(η)exp{ηTu(z)}则目标函数为
K
L
(
p
∥
q
)
=
−
ln
g
(
η
)
−
η
T
E
p
(
z
)
[
u
(
z
)
]
+
c
o
n
s
t
\mathrm{KL}(p \| q)=-\ln g(\boldsymbol{\eta})-\boldsymbol{\eta}^{\mathrm{T}} \mathbb{E}_{p(\mathbf{z})}[\mathbf{u}(\mathbf{z})]+\mathrm{const}
KL(p∥q)=−lng(η)−ηTEp(z)[u(z)]+const对自然参数求导
−
∇
ln
g
(
η
)
=
E
p
(
z
)
[
u
(
z
)
]
-\nabla \ln g(\boldsymbol{\eta})=\mathbb{E}_{p(\mathbf{z})}[\mathbf{u}(\mathbf{z})]
−∇lng(η)=Ep(z)[u(z)]之前在第二章有
−
∇
ln
g
(
η
)
=
E
q
(
z
)
[
u
(
z
)
]
-\nabla \ln g(\boldsymbol{\eta})=\mathbb{E}_{q(\mathbf{z})}[\mathbf{u}(\mathbf{z})]
−∇lng(η)=Eq(z)[u(z)]则有
E
q
(
z
)
[
u
(
z
)
]
=
E
p
(
z
)
[
u
(
z
)
]
\mathbb{E}_{q(\mathbf{z})}[\mathbf{u}(\mathbf{z})]=\mathbb{E}_{p(\mathbf{z})}[\mathbf{u}(\mathbf{z})]
Eq(z)[u(z)]=Ep(z)[u(z)]我们看到,最优解仅仅对应于将充分统计量的期望进⾏匹配。因此,例如,如果
q
(
z
)
q(\mathbf{z})
q(z)是⼀个⾼斯分布
N
(
z
∣
μ
,
Σ
)
\mathcal{N}(\mathbf{z} | \boldsymbol{\mu}, \mathbf{\Sigma})
N(z∣μ,Σ),那么我们通过令
q
(
z
)
q(\mathbf{z})
q(z)的均值
μ
\boldsymbol{\mu}
μ等于分布
p
(
z
)
p(\mathbf{z})
p(z)的均值并且令协⽅差
Σ
\mathbf{\Sigma}
Σ等于p(z)的协⽅差,即可最⼩化Kullback-Leibler散度。这有时被称为矩匹配(moment matching)。
下面考虑模型为
p
(
D
,
θ
)
=
∏
i
f
i
(
θ
)
p(\mathcal{D}, \boldsymbol{\theta})=\prod_{i} f_{i}(\boldsymbol{\theta})
p(D,θ)=i∏fi(θ)我们往往需要后验分布
p
(
θ
∣
D
)
p(\boldsymbol{\theta} | \mathcal{D})
p(θ∣D),则
p
(
θ
∣
D
)
=
1
p
(
D
)
∏
i
f
i
(
θ
)
p(\boldsymbol{\theta} | \mathcal{D})=\frac{1}{p(\mathcal{D})} \prod_{i} f_{i}(\boldsymbol{\theta})
p(θ∣D)=p(D)1i∏fi(θ)其中model evidence为
p
(
D
)
=
∫
∏
i
f
i
(
θ
)
d
θ
p(\mathcal{D})=\int \prod_{i} f_{i}(\boldsymbol{\theta}) \mathrm{d} \boldsymbol{\theta}
p(D)=∫i∏fi(θ)dθ但往往这是不可处理的,因此得考虑近似。期望传播基于后验概率分布的近似,这个近似也由⼀组因⼦的乘积给出,即
q
(
θ
)
=
1
Z
∏
i
f
~
i
(
θ
)
q(\boldsymbol{\theta})=\frac{1}{Z} \prod_{i} \widetilde{f}_{i}(\boldsymbol{\theta})
q(θ)=Z1i∏f
i(θ)其中每个因子
f
~
i
(
θ
)
\widetilde{f}_{i}(\boldsymbol{\theta})
f
i(θ)近似真实后验
f
i
(
θ
)
f_{i}(\boldsymbol{\theta})
fi(θ),我们对
f
~
i
(
θ
)
\widetilde{f}_{i}(\boldsymbol{\theta})
f
i(θ)加入一定的限制,我们假设它们为指数族分布,这样一来,
q
(
θ
)
q(\boldsymbol \theta)
q(θ)也是一个指数族分布。
理想情况下,我们想通过最小化KL散度求得变分近似。
K
L
(
p
∥
q
)
=
K
L
(
1
p
(
D
)
∏
i
f
i
(
θ
)
∥
1
Z
∏
i
f
~
i
(
θ
)
)
\mathrm{KL}(p \| q)=\mathrm{KL}\left(\frac{1}{p(\mathcal{D})} \prod_{i} f_{i}(\boldsymbol{\theta}) \| \frac{1}{Z} \prod_{i} \widetilde{f}_{i}(\boldsymbol{\theta})\right)
KL(p∥q)=KL(p(D)1i∏fi(θ)∥Z1i∏f
i(θ))注意与变分推断中使⽤的KL散度相⽐,这个KL的散度恰好相反。通常这个最⼩化是⽆法进⾏的,因为KL散度涉及到关于真实概率分布求平均。作为一个初略的近似,我们最小化
f
i
(
θ
)
f_{i}(\boldsymbol{\theta})
fi(θ)和
f
~
i
(
θ
)
\widetilde{f}_{i}(\boldsymbol{\theta})
f
i(θ)的KL,这个问题容易得多,并且具有算法⽆需迭代的优点。然⽽,由于每个因⼦被各⾃独⽴地进⾏近似,因此因⼦的乘积的近似效果可能很差。
期望传播通过在所有剩余因⼦的环境中对每个因⼦进⾏优化,从⽽取得了⼀个效果好得多的近似。⾸先,这种⽅法初始化因⼦
f
~
i
(
θ
)
\widetilde{f}_{i}(\boldsymbol{\theta})
f
i(θ),然后在因⼦之间进⾏循环,每次优化⼀个因⼦。这种⽅法的思想类似于之前讨论的变分贝叶斯框架的因⼦更近过程。假设我们希望优化因⼦
f
~
j
(
θ
)
\widetilde{f}_{j}(\boldsymbol{\theta})
f
j(θ)。⾸先,我们将这个因⼦从乘积中移除,得到
∏
i
≠
j
f
~
i
(
θ
)
\prod_{i \neq j} \widetilde{f}_{i}(\boldsymbol{\theta})
∏i̸=jf
i(θ)。从概念上讲,我们要确定因⼦
f
~
j
(
θ
)
\tilde{f}_{j}(\boldsymbol{\theta})
f~j(θ)的⼀个修正形式,使得乘积
q
new
(
θ
)
∝
f
~
j
(
θ
)
∏
i
≠
j
f
~
i
(
θ
)
q^{\text { new }}(\boldsymbol{\theta}) \propto \widetilde{f}_{j}(\boldsymbol{\theta}) \prod_{i \neq j} \widetilde{f}_{i}(\boldsymbol{\theta})
q new (θ)∝f
j(θ)i̸=j∏f
i(θ)尽可能接近
f
j
(
θ
)
∏
i
≠
j
f
~
i
(
θ
)
f_{j}(\boldsymbol{\theta}) \prod_{i \neq j} \widetilde{f}_{i}(\boldsymbol{\theta})
fj(θ)i̸=j∏f
i(θ)其中我们保持所有
i
≠
j
i \neq j
i̸=j的因⼦
f
~
i
(
θ
)
\widetilde{f}_{i}(\boldsymbol{\theta})
f
i(θ)固定。这保证了近似在由剩余的因⼦定义的后验概率较⾼的区域最精确。首先定义
q
\
j
(
θ
)
=
q
(
θ
)
f
~
j
(
θ
)
q^{\backslash j}(\boldsymbol{\theta})=\frac{q(\boldsymbol{\theta})}{\widetilde{f}_{j}(\boldsymbol{\theta})}
q\j(θ)=f
j(θ)q(θ)则
1
Z
j
f
j
(
θ
)
q
\
j
(
θ
)
\frac{1}{Z_{j}} f_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta})
Zj1fj(θ)q\j(θ)其中
Z
j
=
∫
f
j
(
θ
)
q
\
j
(
θ
)
d
θ
Z_{j}=\int f_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta}) \mathrm{d} \boldsymbol{\theta}
Zj=∫fj(θ)q\j(θ)dθ然后优化
K
L
(
f
j
(
θ
)
q
\
j
(
θ
)
Z
j
∥
q
n
e
w
(
θ
)
)
\mathrm{KL}\left(\frac{f_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta})}{Z_{j}} \| q^{\mathrm{new}}(\boldsymbol{\theta})\right)
KL(Zjfj(θ)q\j(θ)∥qnew(θ))由于
q
new
(
θ
)
q^{\text { new }}(\boldsymbol{\theta})
q new (θ)为一个指数族分布,那么很容易求解上式,利用之前的结果
E
q
(
z
)
[
u
(
z
)
]
=
E
p
(
z
)
[
u
(
z
)
]
\mathbb{E}_{q(\mathbf{z})}[\mathbf{u}(\mathbf{z})]=\mathbb{E}_{p(\mathbf{z})}[\mathbf{u}(\mathbf{z})]
Eq(z)[u(z)]=Ep(z)[u(z)]设置为充分统计量的期望即可。我们会假设这是⼀个可以计算的操作。例如,假如
q
(
θ
)
q(\boldsymbol{\theta})
q(θ)为高斯分布
N
(
θ
∣
μ
,
Σ
)
\mathcal{N}(\boldsymbol{\theta} | \boldsymbol{\mu}, \boldsymbol{\Sigma})
N(θ∣μ,Σ),那么可以设置均值为
f
j
(
θ
)
q
\
j
(
θ
)
Z
j
\frac{f_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta})}{Z_{j}}
Zjfj(θ)q\j(θ)的均值,方差为
f
j
(
θ
)
q
\
j
(
θ
)
Z
j
\frac{f_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta})}{Z_{j}}
Zjfj(θ)q\j(θ)的方差。得到了
q
n
e
w
(
θ
)
q^{\mathrm{new}}(\boldsymbol{\theta})
qnew(θ)了,则可以得到需要更新的
j
j
j
f
~
j
(
θ
)
=
K
q
n
e
w
(
θ
)
q
\
j
(
θ
)
\widetilde{f}_{j}(\boldsymbol{\theta})=K \frac{q^{\mathrm{new}}(\boldsymbol{\theta})}{q^{\backslash j}(\boldsymbol{\theta})}
f
j(θ)=Kq\j(θ)qnew(θ)其中
K
=
∫
f
~
j
(
θ
)
q
\
j
(
θ
)
d
θ
K=\int \widetilde{f}_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta}) \mathrm{d} \boldsymbol{\theta}
K=∫f
j(θ)q\j(θ)dθ
K
K
K的值可以通过匹配零阶矩的⽅式得到
∫
f
~
j
(
θ
)
q
\
j
(
θ
)
d
θ
=
∫
f
j
(
θ
)
q
\
j
(
θ
)
d
θ
\int \widetilde{f}_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta}) \mathrm{d} \boldsymbol{\theta}=\int f_{j}(\boldsymbol{\theta}) q^{\backslash j}(\boldsymbol{\theta}) \mathrm{d} \boldsymbol{\theta}
∫f
j(θ)q\j(θ)dθ=∫fj(θ)q\j(θ)dθ则
K
=
Z
j
K=Z_{j}
K=Zj
具体流程如下



10.7.1 Example: The clutter problem
我们的目标是从观测数据集中推断出多元高斯的均值
θ
\boldsymbol \theta
θ,其中数据中有背景噪声。
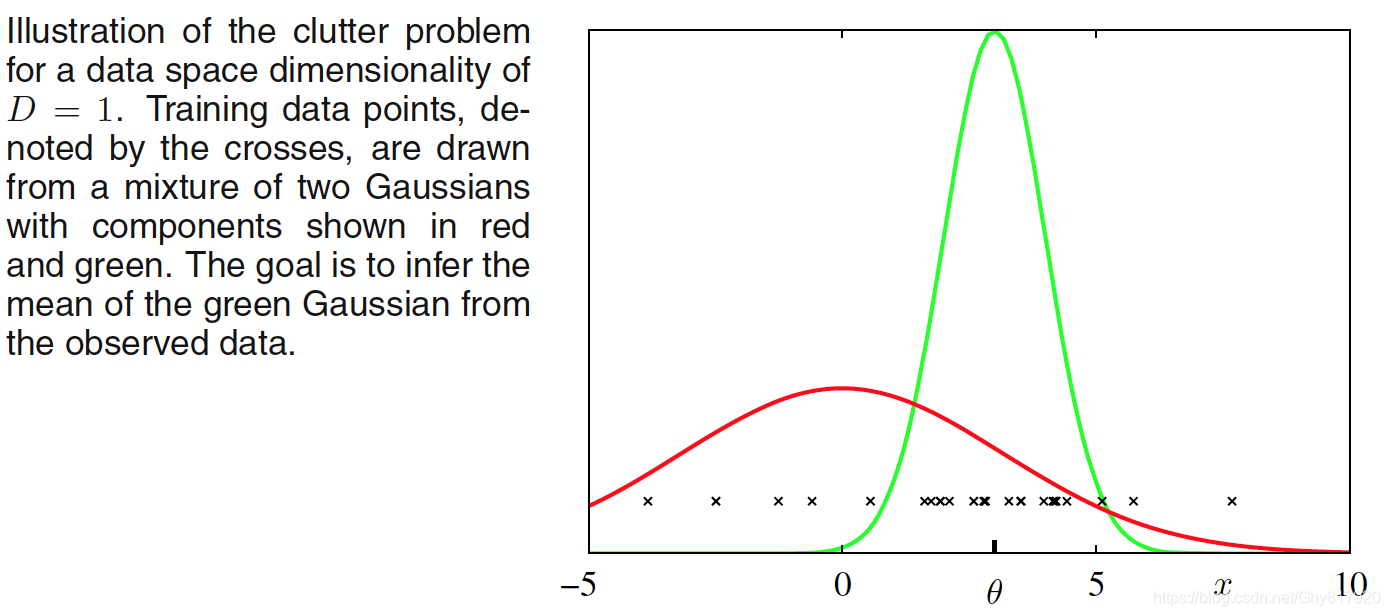
建模为GMM
p
(
x
∣
θ
)
=
(
1
−
w
)
N
(
x
∣
θ
,
I
)
+
w
N
(
x
∣
0
,
a
I
)
p(\mathbf{x} | \boldsymbol{\theta})=(1-w) \mathcal{N}(\mathbf{x} | \boldsymbol{\theta}, \mathbf{I})+w \mathcal{N}(\mathbf{x} | \mathbf{0}, a \mathbf{I})
p(x∣θ)=(1−w)N(x∣θ,I)+wN(x∣0,aI)其中
w
w
w为一个已经的。设高斯先验
p
(
θ
)
=
N
(
θ
∣
0
,
b
I
)
p(\boldsymbol{\theta})=\mathcal{N}(\boldsymbol{\theta} | \mathbf{0}, b \mathbf{I})
p(θ)=N(θ∣0,bI)其中
a
=
10
,
b
=
100
a=10, b=100
a=10,b=100 and
w
=
0.5
w=0.5
w=0.5,则联合分布为
p
(
D
,
θ
)
=
p
(
θ
)
∏
n
=
1
N
p
(
x
n
∣
θ
)
p(\mathcal{D}, \boldsymbol{\theta})=p(\boldsymbol{\theta}) \prod_{n=1}^{N} p\left(\mathbf{x}_{n} | \boldsymbol{\theta}\right)
p(D,θ)=p(θ)n=1∏Np(xn∣θ)因此后验概率分布由
2
N
2^N
2N个⾼斯分布混合⽽成。从⽽精确解决这个问题的计算代价会随着数据集的规模指数增长,因此对于⼤的
N
N
N值,精确求解是不可⾏的。为了运用EP算法,有
f
0
(
θ
)
=
p
(
θ
)
f_{0}(\boldsymbol{\theta})=p(\boldsymbol{\theta})
f0(θ)=p(θ),
f
n
(
θ
)
=
p
(
x
n
∣
θ
)
f_{n}(\boldsymbol{\theta})=p\left(\mathbf{x}_{n} | \boldsymbol{\theta}\right)
fn(θ)=p(xn∣θ),接下来我们要选择一个指数族分布作为近似分布,为了简单起见,我们选择高斯
q
(
θ
)
=
N
(
θ
∣
m
,
v
I
)
q(\boldsymbol{\theta})=\mathcal{N}(\boldsymbol{\theta} | \mathbf{m}, v \mathbf{I})
q(θ)=N(θ∣m,vI)则可分解为指数二次函数,注意以下并不是一个高斯分布,只是形式上是
f
~
n
(
θ
)
=
s
n
N
(
θ
∣
m
n
,
v
n
I
)
\widetilde{f}_{n}(\boldsymbol{\theta})=s_{n} \mathcal{N}\left(\boldsymbol{\theta} | \mathbf{m}_{n}, v_{n} \mathbf{I}\right)
f
n(θ)=snN(θ∣mn,vnI)其中
n
=
1
,
…
,
N
n=1, \ldots, N
n=1,…,N,我们设置
f
~
0
(
θ
)
\widetilde{f}_{0}(\boldsymbol{\theta})
f
0(θ) equal to the prior
p
(
θ
)
p(\boldsymbol{\theta})
p(θ)。
f
~
n
(
θ
)
,
\widetilde{f}_{n}(\boldsymbol{\theta}),
f
n(θ), for
n
=
1
,
…
,
N
n=1, \ldots, N
n=1,…,N可以被初始化为1,则对应
s
n
=
(
2
π
v
n
)
D
/
2
,
v
n
→
∞
s_{n}=\left(2 \pi v_{n}\right)^{D / 2}, v_{n} \rightarrow \infty
sn=(2πvn)D/2,vn→∞和
m
n
=
0
\mathbf{m}_{n}=\mathbf{0}
mn=0,其中
D
D
D为维度。则此时
q
(
θ
)
q(\boldsymbol{\theta})
q(θ)为先验。这样就能开始迭代了,首先从
q
(
θ
)
q(\boldsymbol \theta)
q(θ)除去
f
~
n
(
θ
)
\widetilde{f}_{n}(\boldsymbol{\theta})
f
n(θ)得到
q
\
n
(
θ
)
q^{\backslash n}(\boldsymbol{\theta})
q\n(θ),其中均值和逆方差为
m
\
n
=
m
+
v
\
n
v
n
−
1
(
m
−
m
n
)
(
v
\
n
)
−
1
=
v
−
1
−
v
n
−
1
\begin{aligned} \mathbf{m}^{\backslash n} &=\mathbf{m}+v^{\backslash n} v_{n}^{-1}\left(\mathbf{m}-\mathbf{m}_{n}\right) \\\left(v^{\backslash n}\right)^{-1} &=v^{-1}-v_{n}^{-1} \end{aligned}
m\n(v\n)−1=m+v\nvn−1(m−mn)=v−1−vn−1之后计算归一化参数
Z
n
=
(
1
−
w
)
N
(
x
n
∣
m
\
n
,
(
v
\
n
+
1
)
I
)
+
w
N
(
x
n
∣
0
,
a
I
)
Z_{n}=(1-w) \mathcal{N}\left(\mathbf{x}_{n} | \mathbf{m}^{\backslash n},\left(v^{\backslash n}+1\right) \mathbf{I}\right)+w \mathcal{N}\left(\mathbf{x}_{n} | \mathbf{0}, a \mathbf{I}\right)
Zn=(1−w)N(xn∣m\n,(v\n+1)I)+wN(xn∣0,aI)然后利用
q
\
n
(
θ
)
f
n
(
θ
)
q^{\backslash n}(\boldsymbol{\theta}) f_{n}(\boldsymbol{\theta})
q\n(θ)fn(θ)的均值和方差得到
q
new
(
θ
)
q^{\text { new }}(\boldsymbol{\theta})
q new (θ)的均值和方差
m
=
m
\
n
+
ρ
n
v
\
n
v
\
n
+
1
(
x
n
−
m
\
n
)
v
=
v
\
n
−
ρ
n
(
v
\
n
)
2
v
\
n
+
1
+
ρ
n
(
1
−
ρ
n
)
(
v
\
n
)
2
∥
x
n
−
m
\
n
∥
2
D
(
v
\
n
+
1
)
2
\begin{aligned} \mathbf{m} &=\mathbf{m}^{\backslash n}+\rho_{n} \frac{v^{\backslash n}}{v^{\backslash n}+1}\left(\mathbf{x}_{n}-\mathbf{m}^{\backslash n}\right) \\ v &=v^{\backslash n}-\rho_{n} \frac{\left(v^{\backslash n}\right)^{2}}{v^{\backslash n}+1}+\rho_{n}\left(1-\rho_{n}\right) \frac{\left(v^{\backslash n}\right)^{2}\left\|\mathbf{x}_{n}-\mathbf{m}^{\backslash n}\right\|^{2}}{D\left(v^{\backslash n}+1\right)^{2}} \end{aligned}
mv=m\n+ρnv\n+1v\n(xn−m\n)=v\n−ρnv\n+1(v\n)2+ρn(1−ρn)D(v\n+1)2(v\n)2∥∥xn−m\n∥∥2其中
ρ
n
=
1
−
w
Z
n
N
(
x
n
∣
0
,
a
I
)
\rho_{n}=1-\frac{w}{Z_{n}} \mathcal{N}\left(\mathbf{x}_{n} | \mathbf{0}, a \mathbf{I}\right)
ρn=1−ZnwN(xn∣0,aI)它可以简单地表⽰为点
x
n
\mathbf x_n
xn不在聚类中的概率。接下来就是计算更新后的
f
~
n
(
θ
)
\tilde{f}_{n}(\theta)
f~n(θ),其参数为
v
n
−
1
=
(
v
new
)
−
1
−
(
v
\
n
)
−
1
m
n
=
m
\
n
+
(
v
n
+
v
\
n
)
(
v
\
n
)
−
1
(
m
new
−
m
\
n
)
s
n
=
Z
n
(
2
π
v
n
)
D
/
2
N
(
m
n
∣
m
\
n
,
(
v
n
+
v
\
n
)
I
)
\begin{aligned} v_{n}^{-1} &=\left(v^{\text { new }}\right)^{-1}-\left(v^{\backslash n}\right)^{-1} \\ \mathbf{m}_{n} &=\mathbf{m}^{\backslash n}+\left(v_{n}+v^{\backslash n}\right)\left(v^{\backslash n}\right)^{-1}\left(\mathbf{m}^{\text { new }}-\mathbf{m}^{\backslash n}\right) \\ s_{n} &=\frac{Z_{n}}{\left(2 \pi v_{n}\right)^{D / 2} \mathcal{N}\left(\mathbf{m}_{n} | \mathbf{m}^{\backslash n},\left(v_{n}+v^{\backslash n}\right) \mathbf{I}\right)} \end{aligned}
vn−1mnsn=(v new )−1−(v\n)−1=m\n+(vn+v\n)(v\n)−1(m new −m\n)=(2πvn)D/2N(mn∣m\n,(vn+v\n)I)Zn优化过程不断重复,直到满⾜⼀个合适的终⽌准则,例如在对所有因⼦进⾏的⼀次优化迭代中,参数值的最⼤改变量⼩于⼀个阈值。利用此可得model evidence的近似
p
(
D
)
≃
(
2
π
v
new
)
D
/
2
exp
(
B
/
2
)
∏
n
=
1
N
{
s
n
(
2
π
v
n
)
−
D
/
2
}
p(\mathcal{D}) \simeq\left(2 \pi v^{\text { new }}\right)^{D / 2} \exp (B / 2) \prod_{n=1}^{N}\left\{s_{n}\left(2 \pi v_{n}\right)^{-D / 2}\right\}
p(D)≃(2πv new )D/2exp(B/2)n=1∏N{sn(2πvn)−D/2}其中
B
=
(
m
new
)
T
m
new
v
−
∑
n
=
1
N
m
n
T
m
n
v
n
B=\frac{\left(\mathbf{m}^{\text { new }}\right)^{\mathrm{T}} \mathbf{m}^{\text { new }}}{v}-\sum_{n=1}^{N} \frac{\mathbf{m}_{n}^{\mathrm{T}} \mathbf{m}_{n}}{v_{n}}
B=v(m new )Tm new −n=1∑NvnmnTmn注意,因⼦近似可以有⽆穷⼤的或者负数的“⽅差”参数
v
n
v_{n}
vn。这仅仅对应于曲线向上弯曲⽽不是向下弯曲的情形,并且只要所有的近似后验概率
q
(
θ
)
q(\boldsymbol{\theta})
q(θ)有正的⽅差,这种情形就未必有问题。平均场变分
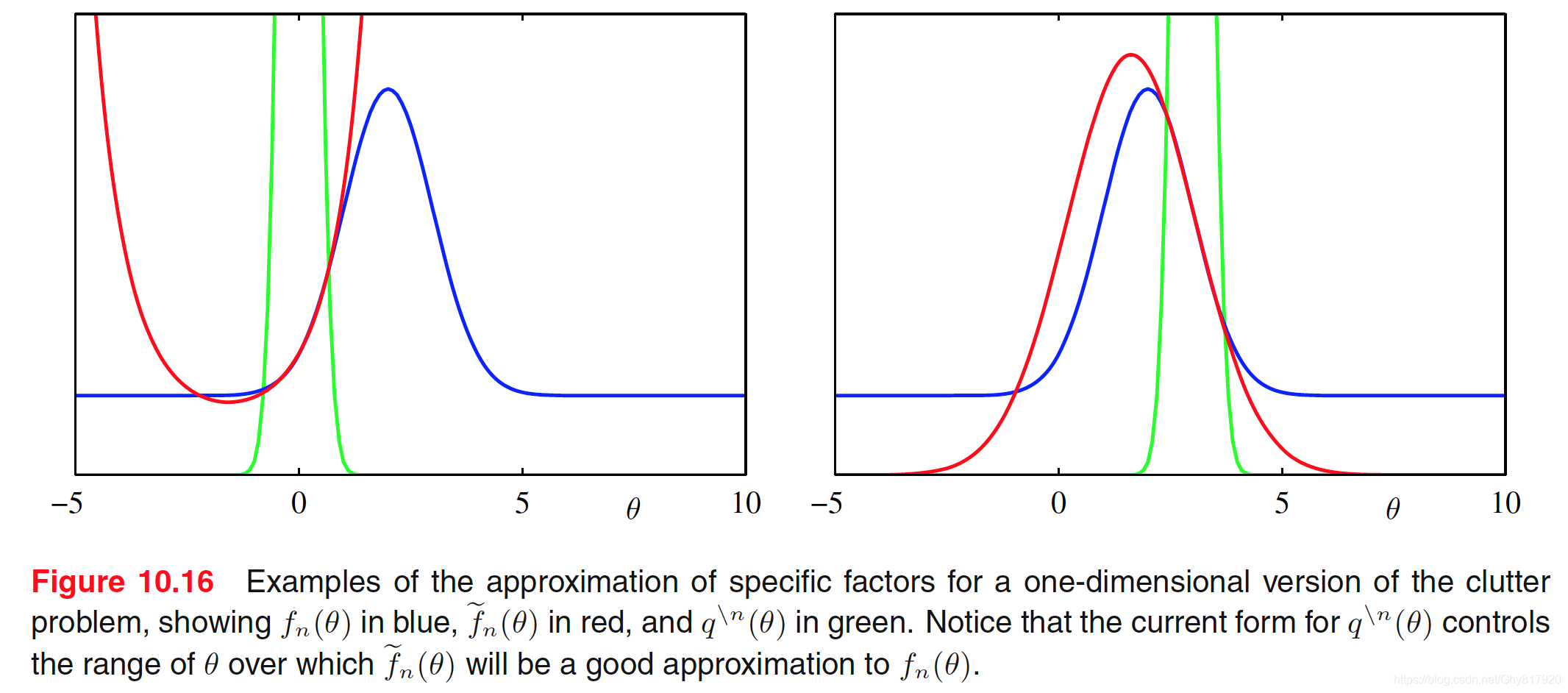
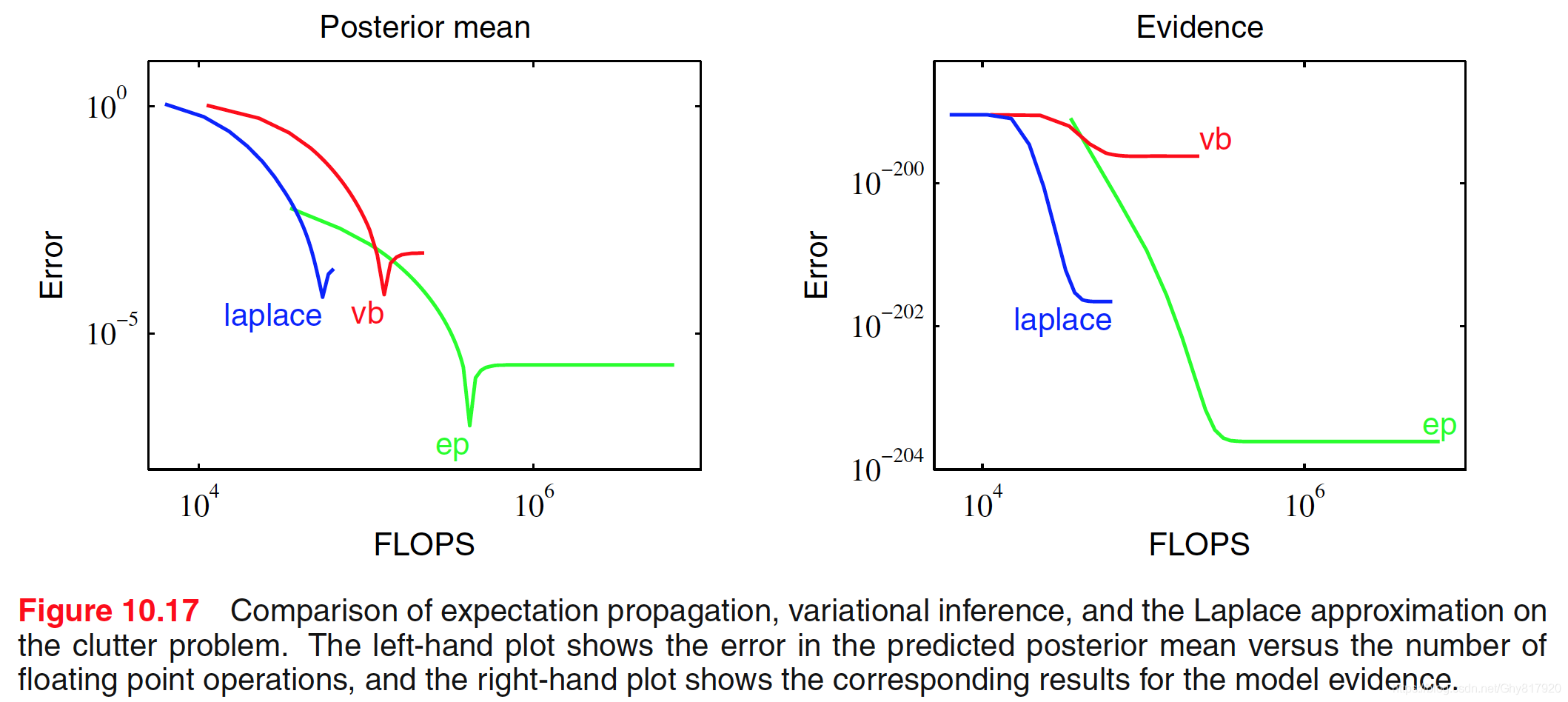
10.7.2 Expectation propagation on graphs
⽬前为⽌在我们对于EP的⼀般的讨论中,我们让概率分布
p
(
θ
)
p(\boldsymbol{\theta})
p(θ)中的所有因⼦
f
i
(
θ
)
f_{i}(\boldsymbol{\theta})
fi(θ)是
θ
\boldsymbol \theta
θ的全部分量的函数,类似地,对于近似分布
q
(
θ
)
q(\boldsymbol{\theta})
q(θ)的近似因⼦
f
~
(
θ
)
\widetilde{f}(\boldsymbol{\theta})
f
(θ)的情形也相同。我们现在考虑下⾯的情形:因⼦只依赖于变量的⼀个⼦集。这种限制可以很⽅便地使⽤第8章讨论的概率图模型的框架来表⽰。这⾥,我们使⽤因⼦图表⽰,因为它同时包含了有向图和⽆向图。
之前对于分解后的
q
q
q,在优化
K
L
(
p
∥
q
)
\mathrm{KL}(p \| q)
KL(p∥q)时,最优的
q
q
q就是
p
p
p的边缘分布。考虑以下的因子图
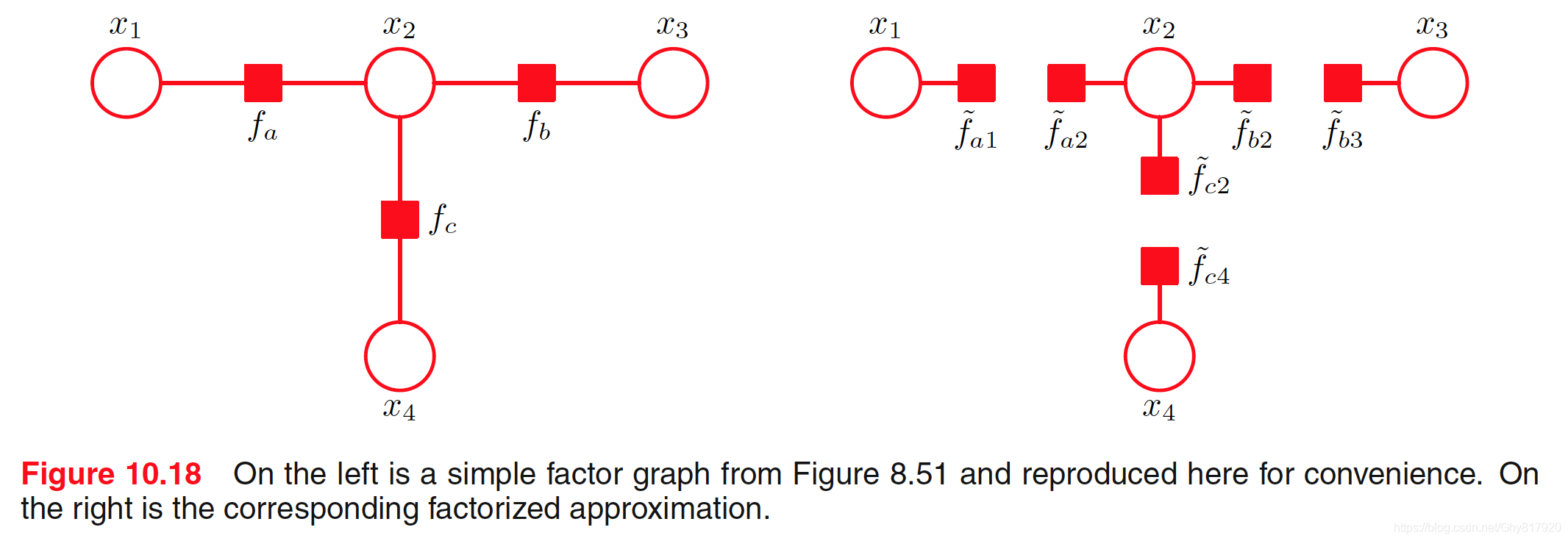
p
(
x
)
=
f
a
(
x
1
,
x
2
)
f
b
(
x
2
,
x
3
)
f
c
(
x
2
,
x
4
)
p(\mathbf{x})=f_{a}\left(x_{1}, x_{2}\right) f_{b}\left(x_{2}, x_{3}\right) f_{c}\left(x_{2}, x_{4}\right)
p(x)=fa(x1,x2)fb(x2,x3)fc(x2,x4)目标是近似
q
(
x
)
∝
f
~
a
(
x
1
,
x
2
)
f
~
b
(
x
2
,
x
3
)
f
~
c
(
x
2
,
x
4
)
q(\mathbf{x}) \propto \widetilde{f}_{a}\left(x_{1}, x_{2}\right) \widetilde{f}_{b}\left(x_{2}, x_{3}\right) \widetilde{f}_{c}\left(x_{2}, x_{4}\right)
q(x)∝f
a(x1,x2)f
b(x2,x3)f
c(x2,x4)现在,假设我们将注意⼒集中于近似分布上,其中因⼦本⾝可以关于各个变量进⾏分解,即
q
(
x
)
∝
f
~
a
1
(
x
1
)
f
~
a
2
(
x
2
)
f
~
b
2
(
x
2
)
f
~
b
3
(
x
3
)
f
~
c
2
(
x
2
)
f
~
c
4
(
x
4
)
q(\mathbf{x}) \propto \widetilde{f}_{a 1}\left(x_{1}\right) \widetilde{f}_{a 2}\left(x_{2}\right) \widetilde{f}_{b 2}\left(x_{2}\right) \widetilde{f}_{b 3}\left(x_{3}\right) \widetilde{f}_{c 2}\left(x_{2}\right) \widetilde{f}_{c 4}\left(x_{4}\right)
q(x)∝f
a1(x1)f
a2(x2)f
b2(x2)f
b3(x3)f
c2(x2)f
c4(x4)以上为一个完全分解的分布。现在我们使用EP算法。假设我们已经初始化了所有的因⼦,并且我们选择优化因⼦
f
~
b
(
x
2
,
x
3
)
=
f
~
b
2
(
x
2
)
f
~
b
3
(
x
3
)
\widetilde{f}_{b}\left(x_{2}, x_{3}\right)=\widetilde{f}_{b 2}\left(x_{2}\right) \widetilde{f}_{b 3}\left(x_{3}\right)
f
b(x2,x3)=f
b2(x2)f
b3(x3)。⾸先,我们将这个因⼦从近似分布中移除,
得到
q
\
b
(
x
)
=
f
~
a
1
(
x
1
)
f
~
a
2
(
x
2
)
f
~
c
2
(
x
2
)
f
~
c
4
(
x
4
)
q^{\backslash b}(\mathbf{x})=\widetilde{f}_{a 1}\left(x_{1}\right) \widetilde{f}_{a 2}\left(x_{2}\right) \widetilde{f}_{c 2}\left(x_{2}\right) \widetilde{f}_{c 4}\left(x_{4}\right)
q\b(x)=f
a1(x1)f
a2(x2)f
c2(x2)f
c4(x4)之后乘上精确的因子
f
b
(
x
2
,
x
3
)
f_{b}\left(x_{2}, x_{3}\right)
fb(x2,x3),则
p
^
(
x
)
=
q
\
b
(
x
)
f
b
(
x
2
,
x
3
)
=
f
~
a
1
(
x
1
)
f
~
a
2
(
x
2
)
f
~
c
2
(
x
2
)
f
~
c
4
(
x
4
)
f
b
(
x
2
,
x
3
)
\widehat{p}(\mathbf{x})=q^{\backslash b}(\mathbf{x}) f_{b}\left(x_{2}, x_{3}\right)=\widetilde{f}_{a 1}\left(x_{1}\right) \widetilde{f}_{a 2}\left(x_{2}\right) \widetilde{f}_{c 2}\left(x_{2}\right) \widetilde{f}_{c 4}\left(x_{4}\right) f_{b}\left(x_{2}, x_{3}\right)
p
(x)=q\b(x)fb(x2,x3)=f
a1(x1)f
a2(x2)f
c2(x2)f
c4(x4)fb(x2,x3)然后通过
K
L
(
p
^
∥
q
new
)
\mathrm{KL}\left(\widehat{p} \| q^{\text { new }}\right)
KL(p
∥q new )优化
q
new
(
x
)
q^{\text { new }}(\mathbf{x})
q new (x),之前说过最优的就是边缘分布,这四个边缘分布为
p
^
(
x
1
)
∝
f
~
a
1
(
x
1
)
p
^
(
x
2
)
∝
f
~
a
2
(
x
2
)
f
~
c
2
(
x
2
)
∑
x
3
f
b
(
x
2
,
x
3
)
p
^
(
x
3
)
∝
∑
x
2
{
f
b
(
x
2
,
x
3
)
f
~
a
2
(
x
2
)
f
~
c
2
(
x
2
)
}
p
^
(
x
4
)
∝
f
~
c
4
(
x
4
)
\begin{array}{ll}{\widehat{p}\left(x_{1}\right)} & {\propto \widetilde{f}_{a 1}\left(x_{1}\right)} \\ {\widehat{p}\left(x_{2}\right)} & {\propto \widetilde{f}_{a 2}\left(x_{2}\right) \widetilde{f}_{c 2}\left(x_{2}\right) \sum_{x_{3}} f_{b}\left(x_{2}, x_{3}\right)} \\ {\widehat{p}\left(x_{3}\right)} & {\propto \sum_{x_{2}}\left\{f_{b}\left(x_{2}, x_{3}\right) \widetilde{f}_{a 2}\left(x_{2}\right) \widetilde{f}_{c 2}\left(x_{2}\right)\right\}} \\ {\widehat{p}\left(x_{4}\right)} & {\propto \tilde{f}_{c 4}\left(x_{4}\right)}\end{array}
p
(x1)p
(x2)p
(x3)p
(x4)∝f
a1(x1)∝f
a2(x2)f
c2(x2)∑x3fb(x2,x3)∝∑x2{fb(x2,x3)f
a2(x2)f
c2(x2)}∝f~c4(x4)从而
q
new
(
x
)
q^{\text { new }}(\mathbf{x})
q new (x)将以上四个相乘得到。为了得到
f
~
b
(
x
2
,
x
3
)
=
f
~
b
2
(
x
2
)
f
~
b
3
(
x
3
)
\widetilde{f}_{b}\left(x_{2}, x_{3}\right)=\widetilde{f}_{b 2}\left(x_{2}\right) \widetilde{f}_{b 3}\left(x_{3}\right)
f
b(x2,x3)=f
b2(x2)f
b3(x3)的更新,首先
divide
q
n
e
w
(
x
)
\operatorname{divide} q^{\mathrm{new}}(\mathbf{x})
divideqnew(x) by
q
\
b
(
x
)
q^{\backslash b}(\mathbf{x})
q\b(x),则
f
~
b
2
(
x
2
)
∝
∑
x
3
f
b
(
x
2
,
x
3
)
f
~
b
3
(
x
3
)
∝
∑
x
2
{
f
b
(
x
2
,
x
3
)
f
~
a
2
(
x
2
)
f
~
c
2
(
x
2
)
}
\begin{array}{ll}{\widetilde{f}_{b 2}\left(x_{2}\right)} & {\propto \sum_{x_{3}} f_{b}\left(x_{2}, x_{3}\right)} \\ {\widetilde{f}_{b 3}\left(x_{3}\right)} & {\propto \sum_{x_{2}}\left\{f_{b}\left(x_{2}, x_{3}\right) \widetilde{f}_{a 2}\left(x_{2}\right) \widetilde{f}_{c 2}\left(x_{2}\right)\right\}}\end{array}
f
b2(x2)f
b3(x3)∝∑x3fb(x2,x3)∝∑x2{fb(x2,x3)f
a2(x2)f
c2(x2)}这些与使⽤置信传播得到的信息完全相同,其中从变量结点到因⼦结点的信息已经被整合到从因⼦结点到变量结点的信息当中。以上分别是
f
~
b
2
(
x
2
)
\widetilde{f}_{b 2}\left(x_{2}\right)
f
b2(x2)对应
μ
f
b
→
x
2
(
x
2
)
\mu_{f_{b} \rightarrow x_{2}}\left(x_{2}\right)
μfb→x2(x2),
f
~
b
3
(
x
3
)
\tilde{f}_{b 3}\left(x_{3}\right)
f~b3(x3)对应
μ
f
b
→
x
3
(
x
3
)
\mu_{f_{b} \rightarrow x_{3}}\left(x_{3}\right)
μfb→x3(x3)这个结果与标准的置信传播稍微有些不同,因为信息同时向两个⽅向传递。我们可以很容易地修改EP步骤,给出加和-乘积算法的标准形式。如果我们每次只优化⼀项,那么我们可以选择我们所希望进⾏的优化的顺序。特别地,对于⼀个树结构的图,我们可以遵循两遍更新的框架,对应于标准的置信传播⽅法,它会产⽣对变量和因⼦的边缘概率分布的精确的推断。这种情况下,近似因⼦的初始化不再重要。
现在,让我们考虑⼀个⼀般的因⼦图,它对应于下⾯的概率分布
p
(
θ
)
=
∏
i
f
i
(
θ
i
)
p(\boldsymbol{\theta})=\prod_{i} f_{i}\left(\boldsymbol{\theta}_{i}\right)
p(θ)=i∏fi(θi)其中
θ
i
\boldsymbol{\theta}_{i}
θi代表与因子
f
i
f_{i}
fi相关的变量子集合。考虑使用一个全分解的分布近似
q
(
θ
)
∝
∏
i
∏
k
f
~
i
k
(
θ
k
)
q(\boldsymbol{\theta}) \propto \prod_{i} \prod_{k} \widetilde{f}_{i k}\left(\theta_{k}\right)
q(θ)∝i∏k∏f
ik(θk)
θ
k
\theta_{k}
θk代表一个变量,考虑优化
f
~
j
l
(
θ
l
)
\widetilde{f}_{j l}\left(\theta_{l}\right)
f
jl(θl),则从
q
(
θ
)
q(\boldsymbol{\theta})
q(θ)除去
f
~
j
(
θ
j
)
\widetilde{f}_{j}\left(\boldsymbol{\theta}_{j}\right)
f
j(θj),则
q
\
j
(
θ
)
∝
∏
i
≠
j
∏
k
f
~
i
k
(
θ
k
)
q^{\backslash j}(\boldsymbol{\theta}) \propto \prod_{i \neq j} \prod_{k} \widetilde{f}_{i k}\left(\theta_{k}\right)
q\j(θ)∝i̸=j∏k∏f
ik(θk)乘上精确因子
f
j
(
θ
j
)
f_{j}\left(\boldsymbol{\theta}_{j}\right)
fj(θj),则
q
\
j
(
θ
)
f
j
(
θ
j
)
q^{\backslash j}(\boldsymbol{\theta}) f_{j}\left(\boldsymbol{\theta}_{j}\right)
q\j(θ)fj(θj)的在
f
~
j
l
(
θ
l
)
\widetilde{f}_{j l}\left(\theta_{l}\right)
f
jl(θl)上的边缘分布。则
f
~
j
l
(
θ
l
)
∝
∑
θ
m
≠
l
∈
θ
j
f
j
(
θ
j
)
∏
k
≠
j
∏
m
≠
l
f
~
k
m
(
θ
m
)
q
\
j
(
θ
)
\widetilde{f}_{j l}\left(\theta_{l}\right) \propto \frac{\sum_{\theta_{m \neq l} \in \boldsymbol{\theta}_{j}} f_{j}\left(\boldsymbol{\theta}_{j}\right) \prod_{k \neq j} \prod_{m \neq l} \widetilde{f}_{k m}\left(\theta_{m}\right)}{q^{\backslash j}(\boldsymbol{\theta})}
f
jl(θl)∝q\j(θ)∑θm̸=l∈θjfj(θj)∏k̸=j∏m̸=lf
km(θm)

















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









