







在使用Pytorch进行单机多GPU并行时,往往有两种方式,一种是基于DataParallel,另一种是基于DistributedDataParallel。前者太简单了,且速度不如后者,所以不作过多讨论。咱们在使用DistributedDataParallel时,其中有个参数broadcast_buffers,官方给出的解释就是
broadcast_buffers (bool): flag that enables syncing (broadcasting) buffers of
the module at beginning of the forward function.
(default: ``True``)
也就是说,每次进行forward时,都会对模型中buffers进行统一。因此作了以下小实验验证下这件事!
import os
import argparse
import torch as th
import torch.multiprocessing as mp
import torch.distributed as dist
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2'
class Mod(th.nn.Module):
def __init__(self):
super().__init__()
self.lin = th.nn.Conv2d(3, 5, 3, padding=1)
self.bn = th.nn.BatchNorm2d(5)
def forward(self, z):
print('forward_before\t{}'.format(self.bn.running_mean))
t = self.lin(z)
return (self.bn(t)).sum()
def main_worker(rank, world_size, seed=0):
world_size = world_size
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12345'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
mod = Mod().cuda(rank)
# process_group = th.distributed.new_group(list(range(world_size)))
# mod = th.nn.SyncBatchNorm.convert_sync_batchnorm(mod, process_group)
optim = th.optim.Adam(mod.parameters(), lr=1e-3)
mod = th.nn.parallel.DistributedDataParallel(mod,
device_ids=[rank], output_device=rank, broadcast_buffers=True)
if rank % 2 == 0:
z1 = th.zeros(7, 3, 5, 5).cuda(rank)
else:
z1 = th.ones(7, 3, 5, 5).cuda(rank)
out = mod(z1)
# if rank == 1:
print('forward_after\t{}'.format(mod.module.bn.running_mean))
# mod(z2) # <<---- The presence of this unused call causes an inplace error in backward() below if dec is a DDP module.
loss = (out**2).mean()
optim.zero_grad()
loss.backward()
optim.step()
print('backward_after\t{}'.format(mod.module.bn.running_mean))
out = mod(z1)
print(mod.module.bn.running_mean)
if __name__ == "__main__":
mp.spawn(main_worker, nprocs=2, args=(2, 0))
当broadcast_buffers=True时,运行结果为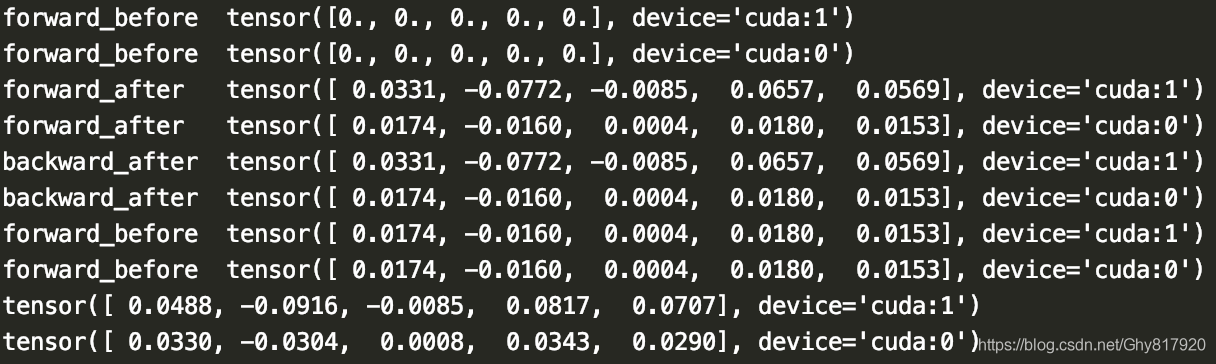
可以发现,在第一次运行forward后,BN中的runing mean会统计各自GPU上的batch统计量,因此得到的结果不同;当进行backward时也不会造成这个buffer的不同。再进行第二次forward之前时,cuda1上的runing mean则会与cuda0上的一致!
当broadcast_buffers=False时,运行结果为
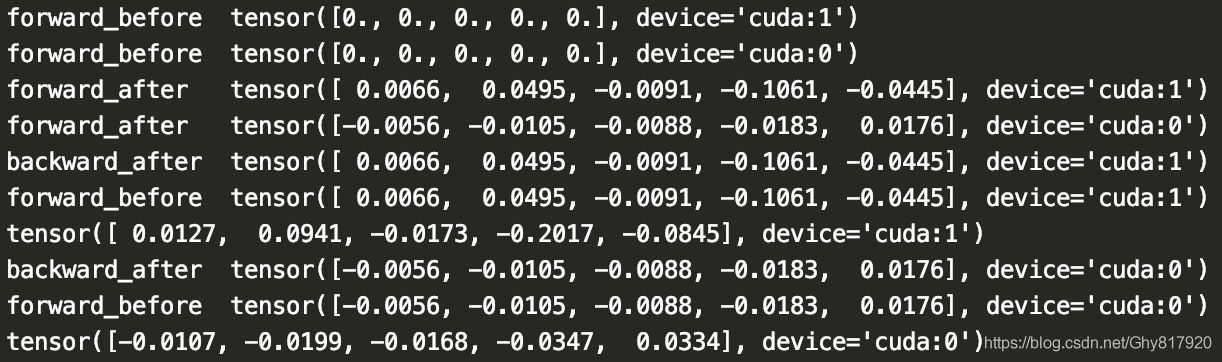
这时,就不会一致了。这种情况下,就跟DataParallel下的BN实现一模一样了!所以我们能不能说当broadcast_buffers=True时,就能达到所谓的同步BN的效果呢??????答案是否定的,同步BN的意思是runing mean是统计所有的分布上GPUs上的batch的统计量,而这个仅仅在每次保持其他GPU上的统计量与GPU0上的一致。所以怎么实现同步BN呢?Pytorch已经实现了!利用
process_group = th.distributed.new_group(list(range(world_size))) mod = th.nn.SyncBatchNorm.convert_sync_batchnorm(mod, process_group)
把上面的程序注释删除即可, 最终运行效果如下!
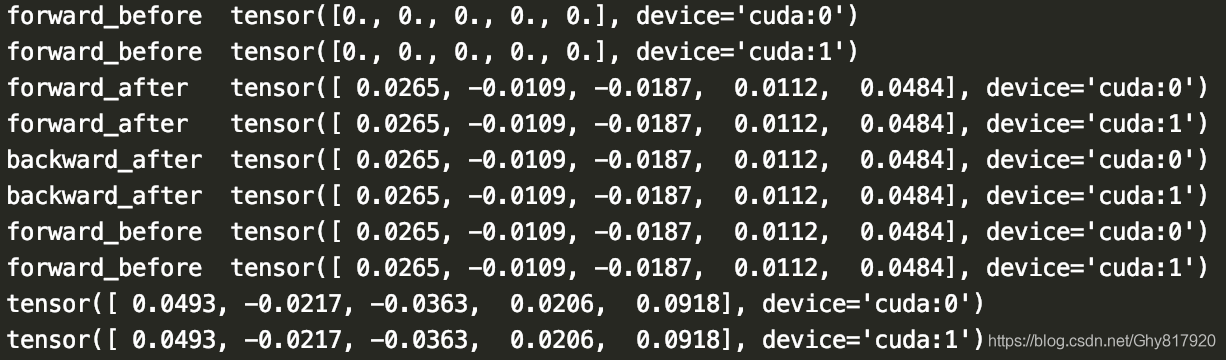
可以发现达到了同步BN效果!需要强调的是,Pytorch的同步BN只能适用于2d形式下,1d不支持!!!!!















 3508
3508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









