







AI 时代学什么,怎么学 / 2024.9

生活中有许多难以确定的随机变量,比如明天雾霾的程度,或某公司的股票值,等等,都是不确定的随机变量。随机变量不是用固定的数值表达,而是用某个数值出现的概率来描述。正因为处处都有随机变量,所以处处都听见“概率”一词。
本文来自:《深度学习》[美] 伊恩·古德费洛 等
《从掷骰子到阿尔法狗》张天蓉

计算机科学的许多分支处理的实体大部分都是完全确定且必然的。程序员通常可以安全地假定CPU将完美地执行每条机器指令。虽然硬件错误确实会发生,但它们非常罕见,以至于大部分软件应用在设计时并不需要考虑这些因素的影响。鉴于许多计算机科学家和软件工程师在一个相对干净和确定的环境中工作,机器学习对于概率论的大量使用是很令人吃惊的。
这是因为机器学习通常必须处理不确定量,有时也可能需要处理随机(非确定性的)量。不确定性和随机性可能来自多个方面。至少从20世纪80年代开始,研究人员就对使用概率论来量化不确定性提出了令人信服的论据。这里给出的许多论据都是根据Pearl(1988)的工作总结或启发得到的。
几乎所有活动都需要一些在不确定性存在的情况下进行推理的能力。事实上,除了那些被定义为真的数学声明,我们很难认定某个命题是千真万确的或者确保某件事一定会发生。
不确定性有3种可能的来源:
(1)被建模系统内在的随机性。例如,大多数量子力学的解释,都将亚原子粒子的动力学描述为概率的。我们还可以创建一些假设具有随机动态的理论情境,例如一个假想的纸牌游戏,在这个游戏中,我们假设纸牌被真正混洗成了随机顺序。
(2)不完全观测。即使是确定的系统,当我们不能观测到所有驱动系统行为的变量时,该系统也会呈现随机性。例如,在Monty Hall问题中,一个游戏节目的参与者被要求在3个门之间选择,并且会赢得放置在选中门后的奖品。其中两扇门通向山羊,第3扇门通向一辆汽车。选手的每个选择所导致的结果是确定的,但是站在选手的角度,结果是不确定的。
(3)不完全建模。当我们使用一些必须舍弃某些观测信息的模型时,舍弃的信息会导致模型的预测出现不确定性。例如,假设我们制作了一个机器人,它可以准确地观察周围每一个对象的位置。在对这些对象将来的位置进行预测时,如果机器人采用的是离散化的空间,那么离散化的方法将使得机器人无法确定对象们的精确位置:因为每个对象都可能处于它被观测到的离散单元的任何一个角落。
在很多情况下,使用一些简单而不确定的规则要比复杂而确定的规则更为实用,即使真正的规则是确定的并且我们建模的系统可以足够精确地容纳复杂的规则。例如,“多数鸟儿都会飞”这个简单的规则描述起来很简单并且使用广泛,而正式的规则——“除了那些还没学会飞翔的幼鸟,因为生病或是受伤而失去了飞翔能力的鸟,包括食火鸟(cassowary)、鸵鸟(ostrich)、几维(kiwi,一种新西兰产的无翼鸟)等不会飞的鸟类⋯⋯以外,鸟儿会飞”,很难应用、维护和沟通,即使经过这么多的努力,这个规则还是很脆弱而且容易失效。
尽管我们的确需要一种用以对不确定性进行表示和推理的方法,但是概率论并不能明显地提供我们在人工智能领域需要的所有工具。
概率论最初的发展是为了分析事件发生的频率。我们可以很容易地看出概率论,对于像在扑克牌游戏中抽出一手特定的牌这种事件的研究中,是如何使用的。这类事件往往是可以重复的。当我们说一个结果发生的概率为 p,这意味着如果我们反复实验(例如,抽取一手牌)无限次,有p的比例可能会导致这样的结果。这种推理似乎并不立即适用于那些不可重复的命题。
如果一个医生诊断了病人,并说该病人患流感的概率为40%,这意味着非常不同的事情——我们既不能让病人有无穷多的副本,也没有任何理由去相信病人的不同副本在具有不同的潜在条件下表现出相同的症状。在医生诊断病人的例子中,我们用概率来表示一种信任度(degree of belief),其中1表示非常肯定病人患有流感,而 0表示非常肯定病人没有患流感。
前面那种概率直接与事件发生的频率相联系,被称为频率派概率(frequentist probability);而后者涉及确定性水平,被称为贝叶斯概率(Bayesian probability)。两种学派的核心区别在于对先验分布的认识。频率学派认为,假设是客观存在且不会改变的,即存在固定的先验分布,只是作为观察者的我们无从知晓,因而在计算具体事件的概率时,要先确定概率分布的类型和参数,然后以此为基础进行概率推演。相比之下,贝叶斯学派则认为,固定的先验分布是不存在的,参数本身是随机数。换言之,假设本身取决于观察结果,是不确定且可以修正的。数据的作用是对假设做出不断的修正,使观察者对概率的主观认识更加接近客观实际。
关于不确定性的常识推理,如果我们已经列出了若干条期望它具有的性质,那么满足这些性质的唯一一种方法就是将贝叶斯概率和频率派概率视为等同的。例如,如果我们要在扑克牌游戏中根据玩家手上的牌计算他能够获胜的概率,那么可以使用和医生情境完全相同的公式,即依据病人的某些症状计算他是否患病的概率。为什么一小组常识性假设蕴含了必须是相同的公理控制两种概率?更多的细节参见Ramsey(1926)。

概率可以被看作用于处理不确定性的逻辑扩展。逻辑提供了一套形式化的规则,可以在给定某些命题是真或假的假设下,判断另外一些命题是真的还是假的。概率论提供了一套形式化的规则,可以在给定一些命题的似然后,计算其他命题为真的似然。
目前,很多机器学习算法是以概率统计的理论为基础支撑推导出来的,比如代价函数的最小二乘形式、逻辑回归算法都基于对模型的最大似然估计。概率论中的高斯函数及中心极限定理等。深度学习还可能涉及概率论中的:随机变量、概率分布、边缘概率、条件概率及其链式法则、期望、方差和协方差、贝叶斯规则、连续型变量……等等。
概率论的诞生
公元17世纪的欧洲国家的贵族盛行赌博之风,赌博方式很简单:掷骰子或者抛硬币。不过,如此简单的赌具中却蕴藏着有趣的数学现象。比如说抛硬币,硬币有正反两面,抛出的硬币落下后的结果不确定,可能是正面,也可能是反面。结果的正反是随机的、难以预料的,却按照一定的概率出现,因而被称为“随机变量”。现在,我们把研究随机变量及其概率的数学理论称为“概率论”。
话说当年的法国有一位叫德·梅雷的贵族,在掷骰子游戏之余,也思考一点相关的数学问题。他苦思不得其解时,便向以聪明著称的帕斯卡请教。1654年,他向帕斯卡请教了一个亲身经历的“分赌注问题”。故事大概如此:梅雷和赌友各自出32枚金币,共64枚金币作为赌注。掷骰子为赌博方式,如果结果出现“6”,梅雷赢1分;如果结果出现“4”,对方赢1分;谁先得到10分,谁就赢得全部赌注。赌博进行了一段时间后,梅雷已得了8分,对方也得了7分。但这时,梅雷接到紧急命令,要立即陪国王接见外宾,于是只好中断赌博。那么,问题就来了,这64枚金币的赌注应该如何分配才合理呢?
这个问题实际上是在15、16世纪时就已经被提出过,称之为“点数分配问题”,意思就是说,在一场赌博半途中断的情况下,应该如何分配赌注?人们提出各种方案,但未曾得到大家都认为合理的答案。
就上面梅雷和赌友的例子来说。将赌注原数退回显然不合理,没有考虑赌博中断时的输赢情况,相当于白赌了一场。将全部赌注归于当时的赢家也不公平,比如当时梅雷比对方多得一分,但他还差2分才能赢,而对方差3分,如果继续赌下去的话,对方也有赢的可能性。
帕斯卡对这个问题十分感兴趣。直观而言,上面所述的两种方案显然不合理,赌博中断时的梅雷应该多得一些,但到底应该多得多少呢?也有人建议以当时两人比分的比例来计算:梅雷8分,对方7分,那么梅雷得全部赌注的8/15,对方得7/15。这种分法也有问题,比如说,如果甲乙双方只赌了一局就中断了,甲赢得1分,乙得0分。按照刚才的分法,甲拿走全部赌注,显然又是极不合理的分法。
帕斯卡从直觉意识到,中断赌博时赌注的分配比例,应该由当时的输赢状态与双方约定的最终判据的距离有关。比如说,梅雷已经得了8分,距离10分的判据差2分;赌友得了7分,还差3分到10分。因此,帕斯卡认为需要研究从中断赌博那个“点”开始,如果继续赌博的各种可能性。为了尽快地解决这个问题,帕斯卡以通信的方式与住在法国南部的费马讨论。费马不愧是研究纯数学的数论专家,很快列出了“梅雷问题”中赌博继续下去的各种结果。
梅雷原来的问题是掷骰子赌“6点”或“4点”的问题,但可以简化成抛硬币的问题:甲乙两人抛硬币,甲赌“正”,乙赌“反”,赢家得1分,各下赌注10元,先到达10分者获取所有赌注。如果赌博在“甲8分、乙7分”时中断,问应该如何分配这20元赌注。下图(a)显示了费马的分析过程:从赌博的中断点出发,还需要抛4次硬币来决定甲乙最后的输赢。这4次随机抛掷产生16种等概率的可能结果。因为“甲赢”需要结果中出现2次“正”,“乙赢”需要结果中出现3次“反”,所以在16种结果中,有11种是“甲赢”,5种是“乙赢”。换言之,如果赌博没有中断,而是从中断点的状态继续到底的话,可以算出甲赢的概率是11/16,乙赢的概率是5/16。赌博的中断使得双方按照这种比例失去了最后赢得全部赌注的机会,因此,按此比例来分配赌注应该是合理的方法。所以,根据费马的分析思路,甲方应该得20元×11/16=13.75元,乙方则得剩余的,或20元×5/16=6.25元。
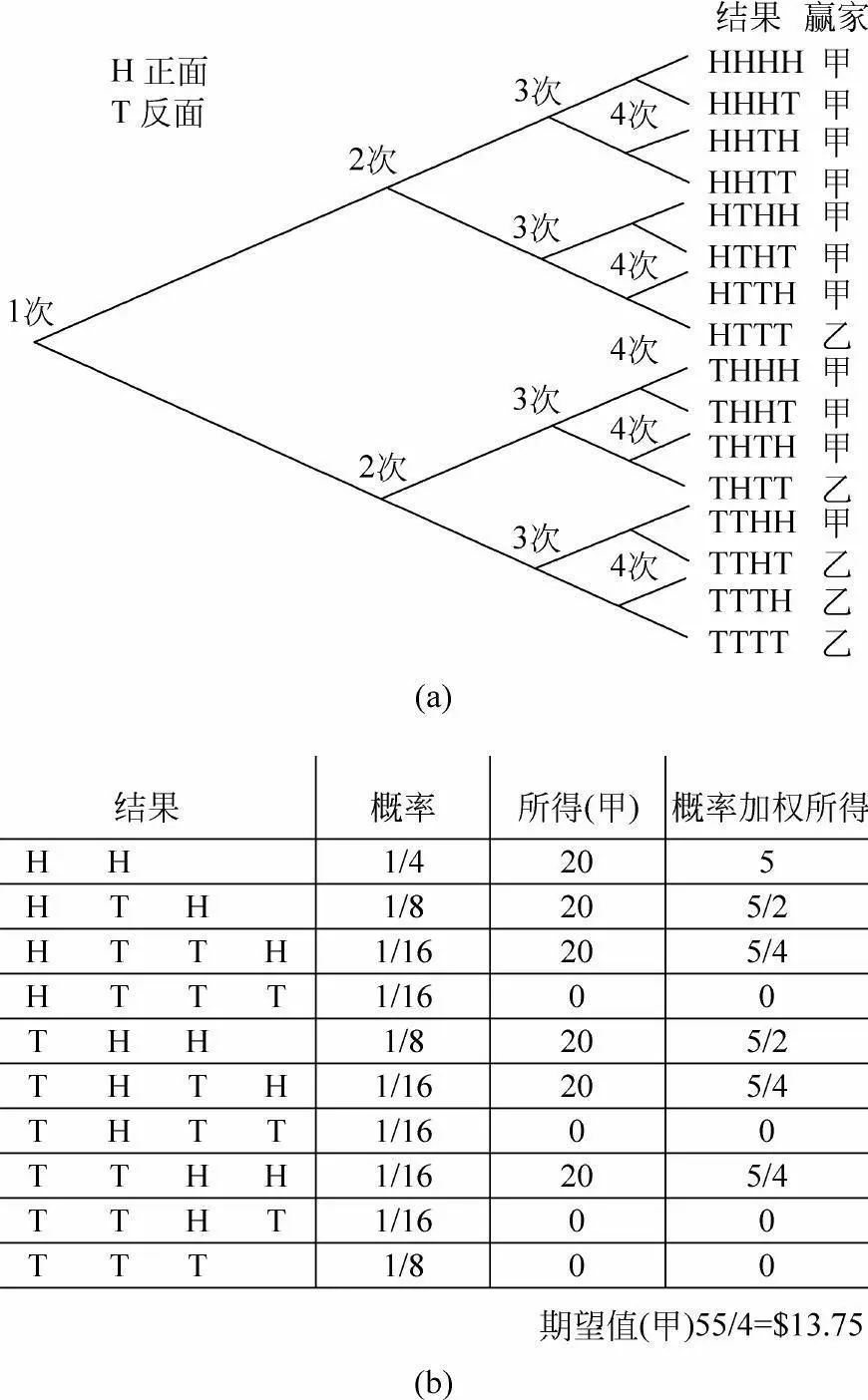
费马和帕斯卡对点数分配问题的思路
(a)费马列出所有结果计算分配比例;
(b)帕斯卡引入期望值的概念计算所得(甲)
帕斯卡十分赞赏费马思路的清晰,费马的计算也验证了帕斯卡自己得到的结论,虽然他用的是与费马完全不一样的方法。帕斯卡在解决这个问题的过程中提出了离散随机变量的“期望值”的概念。期望值是用概率加权后得到的平均值。上图(b)所示,帕斯卡计算出从甲方的观点,“期望”能得到的赌注分配为13.75元,与费马计算的结果一致。
“期望”是概率论中的重要概念,期望值是概率分布的重要特征之一,它常被用在与赌博相关的计算中。例如,美国赌场有一种轮盘赌。其轮盘上有38个数字,每一个数字被选中的概率都是1/38。顾客将赌注(比如1美元)押在其中一个数字上,如果押中了,顾客得到35倍的奖金(35美元),否则赌注就没了,即损失1美元。那么,如何计算顾客“赢”的期望值呢?
根据期望值的定义“概率加权求平均”进行计算,下图显示了计算结果:顾客赢钱的期望值是一个负数,约等于-0.0526美元。也就是说,对赌徒而言,平均起来每赌1美元就会输掉5美分,相当于赌场赢了5美分,所以赌场永远不会亏!
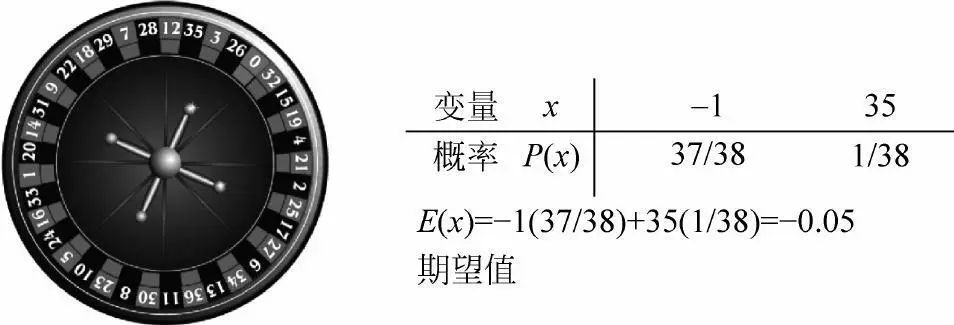
赌场轮盘对赌徒而言的期望值
从研究掷骰子开始,帕斯卡不仅仅引入了“期望”的概念,还发现了“帕斯卡三角形”(即中国古书中所记载的“杨辉三角形”),虽然杨辉的发现早于帕斯卡好几百年,但是帕斯卡将此三角形与概率、期望、二项式定理、组合公式等联系在一起,与费马一起为现代概率理论奠定了基础,对数学做出了不凡的贡献。1657年,荷兰科学家惠更斯在帕斯卡和费马工作的基础上,写成了《论赌博中的计算》一书,被认为是关于概率论的最早系统论著。不过,人们仍然将概率论的诞生日,定为帕斯卡和费马开始通信的那一天——1654年7月29日。
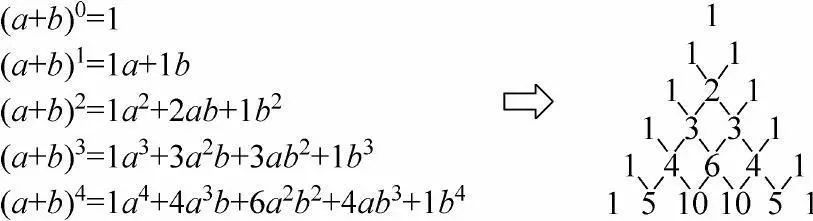
帕斯卡三角形(杨辉三角)
推荐阅读

《中国人工智能简史:从1979到1993》
作者:林军 岑峰 著
出版时间:2023.8
出版社:人民邮电出版社
作者团队深入采访了全国十余所主要高校、中科院多个研究所老中青三代人工智能研究者,重点介绍中国人工智能领域杰出的科学家,以及他们创造非凡成果的有趣故事。
本书梳理了自 1979 年至 1993 年中国人工智能领域初期十多年的发展历程,用轻松而真诚的笔触,讲述了为中国人工智能发展寻路的奠基者,并介绍了重要历史事件的来龙去脉,带领读者深入了解中国人工智能发展早期鲜为人知的历史。

[美] 斯图尔特·罗素(Stuart Russell)[美]彼得·诺维格(Peter Norvig) 著,
张博雅,陈坤,田超,顾卓尔,吴凡 ... 译,张志华 校
吴军、黄铁军作序推荐
揭示AI与chatgpt的奥秘,详解人工智能的发展与未来!
本书全面、深入地探讨了人工智能(AI)领域的理论和实践,以统一的风格将当今流行的人工智能思想和术语融合到引起广泛关注的应用中,真正做到理论和实践相结合。
本书可作为高等院校人工智能相关专业本科生、研究生教材,也是相关领域专业人员的一本参考书。

《概率导论(第2版·修订版)》
作者:[美] 迪米特里·伯特瑟卡斯,[美] 约翰·齐齐克利斯
译者:郑忠国 童行伟
从直观、自然的角度阐述概率;适合理工科学生入门,便于自学。
本书多年来在美国麻省理工学院、斯坦福大学、加州大学等名校被用作概率课程教材,经过课堂检验和众多师生的反馈得以不断完善,是一本在表述简洁和推理严密之间取得优美平衡的经典作品。

《普林斯顿概率论读本》
作者:[美] 史蒂文·J. 米勒(Steven J. Miller)
译者:李馨
普林斯顿读本三剑客之概率论,概率论教材,叙述深入浅出,提供课程视频和讲义,概率论学习图书。
对于学生来说,学习概率论及其众多应用、技术和方法似乎非常费力且令人生畏,而这正是本书的用武之地。这本通俗易懂的学习指南旨在用作概率论的独立教材或相关课程的补充材料,可帮助学生轻松地学习概率论知识并取得良好效果。
本书基于史蒂文·J. 米勒在布朗大学、曼荷莲学院和威廉姆斯学院教授的课程而作。米勒通过先修课程材料、各种难度的问题及证明对概率论这一数学领域进行了详细介绍。探索每个主题时,米勒首先引导学生运用直觉,然后才深入技术细节。本书涵盖的主题很广,并且对材料加以重复以强化知识。读完本书,学生不仅能掌握概率论,还能为将来学习其他课程打下基础。

《概率论沉思录》
作者:埃德温·汤普森·杰恩斯
译者:廖海仁
著名数学物理学家,圣路易斯华盛顿大学和斯坦福大学教授,统计力学和概率统计推断方面权谋埃德温·汤普森·杰恩斯,40年思想著作;
无数读者苦等15年的概率论神作,英文版豆瓣评分9.4高分;
概率论作为逻辑的延伸,是所有科学推断的基础。本书收集了概率统计的各种线索,将概率和统计推断融合在一起,用新的观点生动地描述了概率论在物理学、数学、经济学、化学和生物学等领域中的广泛应用,尤其是阐述了贝叶斯理论的丰富应用,弥补了传统概率论和统计学的不足,并揭开了众多悖论背后的玄机。
长按二维码—识别—关注

















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









