







今日任务:
- 单特征可视化:连续变量箱线图(核密度直方图)、离散特征直方图
- 特征和标签关系可视化
- 箱线图美化与直方图
对于数据可视化操作一般分为三种,即单特征分布可视化、特征与标签关系可视化和特征与特征关系可视化。
选择信贷数据集进行处理,读取数据:
import pandas as pd
data = pd.read_csv(r"D:\机器学习\Python训练营代码【2025.7.30版本】\data.csv")
data.tail()单特征分布可视化
找到连续特征
在day 5中学习了寻找离散特征的方法,同理可以得到寻找连续特征的代码。这样的代码看上去简单直观,非常适合初学者。
#连续特征的寻找
continuous_features = [] #创建空列表
for column in data.columns: #遍历
if data[column].dtype != 'object': #判断
continuous_features.append(column) #添加
continuous_features此外,还有一种直接调用函数的方法完成特征的筛选,即select_dtypes()根据数据类型选择列:
- include:指定要包含的数据类型,include=['object']
- exclude:指定要排除的数据类型
- 由于返回的是指定的列,故而获取列名时采用了columns属性
data.select_dtypes(include=['float64','int64']).columns.tolist()Matplotlib库
在数据可视化的操作中,常用的库为matplotlib和seaborn。在绘制图得过程中需要确定图的类型、坐标轴、数据的传入、标签及标题等。
根据数据类型和分析目标选择合适的图表类型,常见的绘图类型有:
- 数值变量分布分析:直方图(histogram)、核密度估计图(kde plot)、箱线图(boxplot)、小提琴图(violinplot)
- 关系分析:散点图(scatterplot)、回归图(regplot)、热力图(heatmap)
- 分类数据比较:柱状图(barplot)、计数图(countplot)、饼图(pie)
- 时间序列分析:折线图(lineplot)
绘制图表时的一般步骤为:(1)导入库(2)(设置画布),确定图表类型,传入数据(3)添加元素:label、title等(4)修改可选参数,美化图表。此外在绘图过程中应注意,中文字体显示不全以及负号显示问题,需在绘图前使用plt.rcParams设置好。
#中文字体显示
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False下面是选择了两种特征分别绘制了图表的例子:
(1)箱线图
适用于数值变量与分类变量,对于一定量数据包含一类含有多个特征的定类数据如一个班的各科(定类)成绩(定量)。可用来查看分布、离群值、比较不同类别等。
- data:绘图数据包含的dataframe,当使用x, y参数指定列名时必选
- x、y:x轴(分类变量,object或category),y轴(数值变量,int或float)
- hue:用于分组的分类变量,可绘制分组箱线图
- orient(v、h)、color、palette、width等
import matplotlib.pyplot as plt
import seaborn as sns
#连续特征描述
plt.figure(figsize=(6,4)) #设置画布大小
sns.boxplot(data=data,y='Annual Income',x='Home Ownership') #绘图
plt.title('Annual Income & Home Ownership')
plt.show()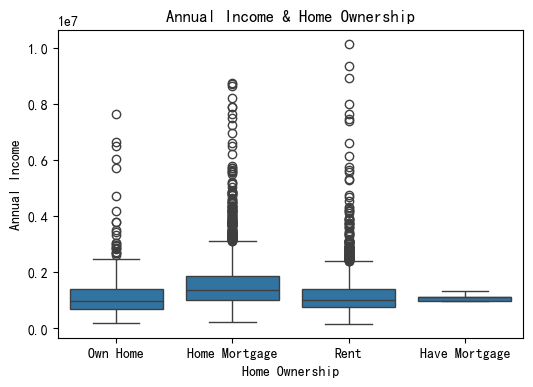
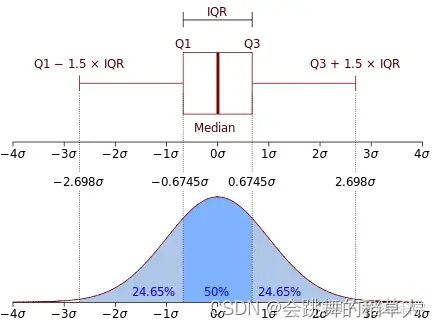
对于箱线图的解读,要关注以下几点,具体解读分析参考:一文读懂箱线图
- 箱体: 显示数据的四分位数范围(IQR)
- 中线: 中位数(50%分位数)
- 须线: 通常为1.5倍IQR范围内的数据
- 离群点: 超出须线范围的数据点,以圆点展示
- 箱体高度: 反映数据的集中程度(Q3-Q1,50%的数据)
(2)直方图
适用于单个数值变量的分布,可查看数据分布形态、异常值、偏度。
- data:绘图数据包含的dataframe,当使用x, y参数指定列名时必选
- x、y:指定要绘制直方图的变量
- hue:用于分组的分类变量
- bins:控制直方图的柱子数量(int)或边界(序列),默认'auto'
- kde:是否显示核密度估计曲线,默认False
#离散特征描述
plt.figure(figsize=(6,4))
sns.histplot(data=data,y='Years in current job',color='coral')
#plt.xticks(rotation=45)
plt.tight_layout() #自动调整子图参数,提供足够的空间
plt.title('Years in current job of histgram')
plt.show()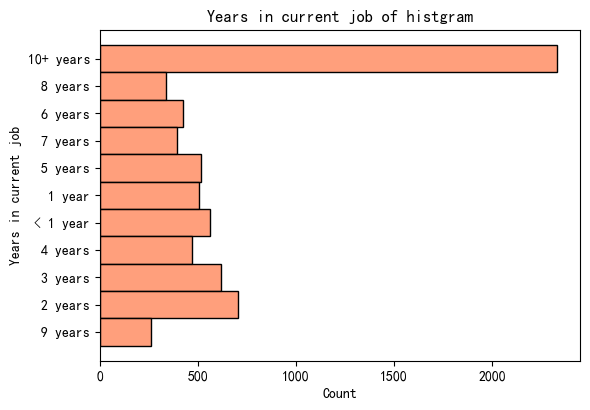
绘制特征和标签的关系
在信贷数据集中,标签为‘Credit Default’,即是否违约,包含两种情况。下面为离散标签与连续特征、离散标签与离散特征绘图示例。
离散标签与连续特征
箱线图
查看数据分布情况及异常值。选择一连续变量与标签绘制分组箱线图,结果如下:
plt.figure(figsize=(6,4))
sns.boxplot(data=data,y='Monthly Debt',x='Credit Default',hue='Term')
plt.title('Monthly Debt & Credit Default')
plt.show()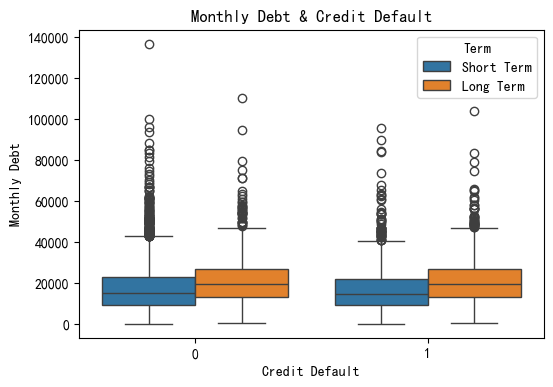
小提琴图
相较于箱线图,小提琴图可展示出数据分布的轮廓情况,包括分布轮廓和分布区域。
plt.figure(figsize=(6,4))
sns.violinplot(data=data,y='Current Credit Balance',x='Credit Default')
plt.title('Current Credit Balance & Credit Default')
plt.show()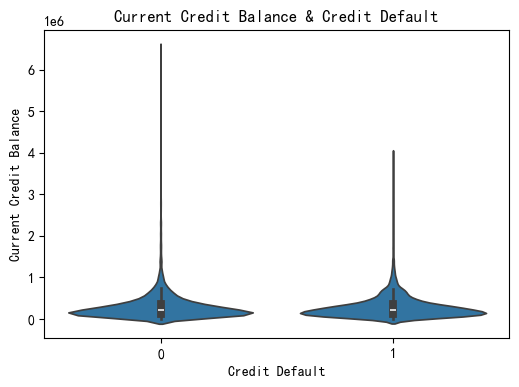
直方图+kde
具体频数+平滑形状。直方图本质是离散的,即使用于连续变量也是用离散的bins来近似。而使用kde可以提供连续视图,实现连续地描述分布。
plt.figure(figsize=(6,4))
sns.histplot(data=data,x='Monthly Debt',hue='Credit Default',kde=True,element="step")
plt.tight_layout()
plt.title('Monthly Debt & Credit Default')
plt.show()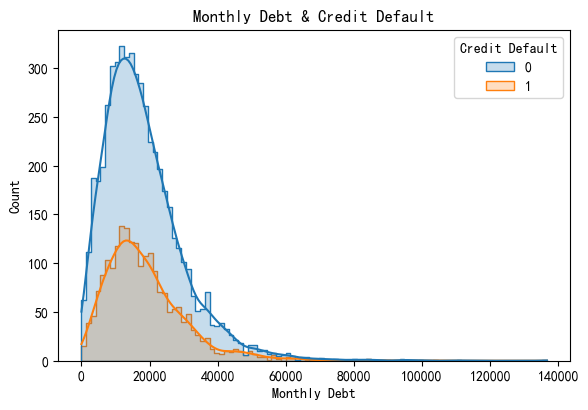
离散标签与离散特征
数值变量有的是连续变量,但有的是离散变量(数量有限)。比如,在信贷数据集中,‘Annual Income’为连续变量,而'Number of Open Accounts'为离散变量。
计数图(countplot)
适用分类变量,可查看各类别的频数分布。
- data:绘图数据包含的dataframe,当使用x, y参数指定列名时必选
- x、y:指定要计数的分类变量
- hue:用于进一步分组的第二个分类变量
plt.figure(figsize=(6,4))
sns.countplot(data=data,x='Number of Open Accounts')
plt.xticks(rotation=45)
#plt.title('Current Credit Balance & Credit Default')
plt.show()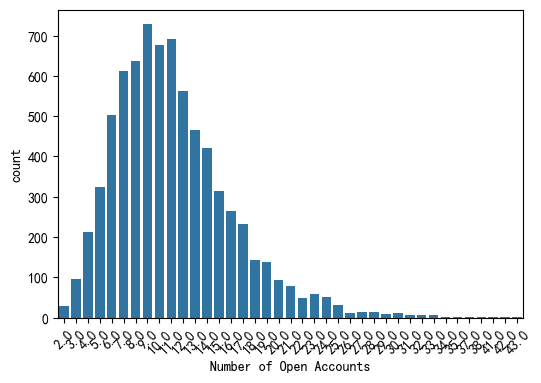
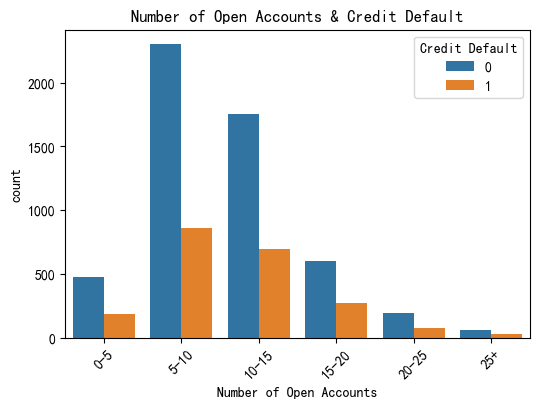
分箱
类别太多时,图表看上去会比较散。由于是数值型,采用分组的方法减少类别。此处使用 pandas 的 cut() 函数将连续的数值变量分箱(离散化)为分类变量,pd.cut():
- 分箱的原始列
- 定义分箱边界bins:分箱上界,float('inf')正无穷大
- 分箱标签labels:标签数比分箱数少一个
#分箱
data['Number of Open Accounts'] = pd.cut(data['Number of Open Accounts'], #分箱原始列
bins=[0,5,10,15,20,25,float('inf')], #分箱边界
labels=['0-5','5-10','10-15','15-20','20-25','25+'])
#画图
plt.figure(figsize=(6,4))
sns.countplot(data=data,x='Number of Open Accounts',hue='Credit Default')
plt.xticks(rotation=45)
plt.title('Number of Open Accounts & Credit Default')
plt.show()
进行数据可视化的初步分析,主要为了得到数据的分布、变量间的关系,根据目的选择合适的图表进行展现。如果为了提高美观度,查阅函数的相关参数进行调整即可。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









