







 文章介绍了如何通过模块编译选择必要的OpenCV组件,以及利用编译选项限制导出符号来优化动态库的大小。首先按需编译各个模块,去掉不必要的第三方库依赖,然后修改默认的导出宏,仅导出实际使用的函数,如类`Mat`,以进一步减小库的体积。
文章介绍了如何通过模块编译选择必要的OpenCV组件,以及利用编译选项限制导出符号来优化动态库的大小。首先按需编译各个模块,去掉不必要的第三方库依赖,然后修改默认的导出宏,仅导出实际使用的函数,如类`Mat`,以进一步减小库的体积。
摘要:本文描述了如何对opencv进行裁剪已达到最小化,不限于使用模块编译,去除第三方库依赖,改变编译选项,限制导出符号等。
关键字:opencv、导出符号
opencv库大小优化的文章网络上很少,大部分都是针对opencv的模块进行选择编译进行最小化,当然这也是最简单有效的方式。我这里介绍限制opencv导出符号来优化库大小的一种方式。
首先简单介绍下既然是最小化库大小那肯定是最小化动态库,因为静态库链接器会自动分析需要哪些符号将对应的符号导出不存在需要进行分析的必要。
1 按照模块编译
第一步是按照模块编译opencv,尽可能去掉你不需要的一些模块。一般来说core是必须的,不然使用opencv的意义在哪儿。比如下面的imgcodesc,stitching,core等这些模块你得清楚你需要哪些不需要哪些,如果不清楚可以看官方文档。另外这里这么多选项该选哪个不该选哪个很难确定,最简单粗暴的办法就是一个一个试:不断将编译出的库应用到你得程序中直到没有编译错误为止(因此这一步建议编译优化的选项选择编译速度最快的方式),同时需要注意有些选项虽然对编译无影响但是会影响opencv的运行速度比如指令集优化、SSE优化之类的。

同时能够去掉一些不需要依赖的一些第三方库比如有jpeg,tiff,webp等,可以根据自己的需求进行调整。
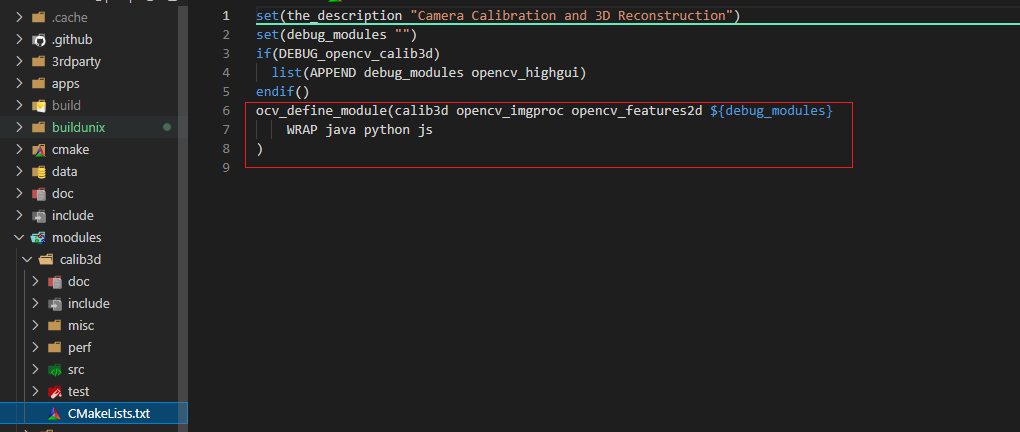
另外需要注意的是opencv中的模块有些是相互依赖的,可以在opencv源码目录下的modules目录中找到对应的模块的文件夹中的CMakeLists.txt文件寻找ocv_define_module,其中就列举出了依赖的模块。比如示例中calib3d模块就依赖于opencv_imgproc opencv_features2d两个模块,也就是说如果要编译calib3d模块这两个模块也要带上。
经过这一步一般opencv的库已经能够减小的比较小了。
还可以根据不同平台的区别调整编译参数来更进一步降低动态库的大小比如-ffunction等。
2 限制导出符号
静态库不会使目标库的体积过分大是因为静态库是残酷目标产物链接的,即生成对应目标产物时就已经直到哪些代码是无用的了,就可以丢弃。而动态库需要用户自己定义需要导出的符号才能限制大小,否则全符号导出目标产物体积是很大的。Msvc和gcc可以使用下面的修饰来限制导出符号。
__declspec(dllexport)
__attribute__ ((visibility ("default")))
__attribute__ ((visibility ("hidden")))
同时clang和gcc可以用--export-dynamic-symbol指定期望导出的符号,一般用于C,因为C的函数name-mangling是清楚的,而C++的要复杂一些。
基于以上我们可以修改opencv的默认导出函数来降低库大小,首先将opencv默认的导出宏重写,并新定义一个宏。
#ifndef CV_EXPORTS
# if (defined _WIN32 || defined WINCE || defined __CYGWIN__) && defined(CVAPI_EXPORTS)
# define CV_EXPORTS
# define CV_USER_DEFINE_EXPORTS __declspec(dllexport)
# elif defined __GNUC__ && __GNUC__ >= 4 && (defined(CVAPI_EXPORTS) || defined(__APPLE__))
# define CV_USER_DEFINE_EXPORTS __attribute__ ((visibility ("default")))
# define CV_EXPORTS __attribute__ ((visibility ("hidden")))
# endif
#endif
这样所有的符号默认都不导出,然后只需要将自定义的导出宏替换到期望导出的符号即可。比如我这边只期望导出Mat:
class CV_USER_DEFINE_EXPORTS Mat
{
public:
此时编译出的大小为2Mb:

更进一步,Mat的函数我并不是所有都是用那么就限制对应符号即可,此时仅仅留了一个库,可以看出进一步减少的空间比较小了:

然后就是根据你的使用场景来选择导出的符号裁剪库大小。然后我们简单看下目前库的内容,发现其中代码占大头,导出的符号仅仅剩一个了,如果需要继续优化可能就是要在代码上进行裁剪了:
ordinal hint RVA name
1 0 000B7710 ??0Mat@cv@@QEAA@XZ = ??0Mat@cv@@QEAA@XZ (public: __cdecl cv::Mat::Mat(void))
Summary
8000 .data
11000 .pdata
8B000 .rdata
2000 .reloc
1000 .rsrc
185000 .text
4000 _RDATA

















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









