






文章目录
前言
原论文地址:Spiking-YOLO: Spiking Neural Network for Energy-Efficient Object Detection
Spikingjelly官方文档:Spikingjelly官方文档
Spikingjelly源码链接:Spikingjelly-GitHub
一、Spiking-YOLO
Introduction
在本研究中,使用DNN到SNN的转换方法来探讨深度SNN中一个更先进的机器学习问题,即目标检测。目标检测被认为是更具挑战性的,因为它涉及到识别多个重叠对象和计算边界框的精确坐标。因此,在预测神经网络的输出值(即回归问题)时,它需要很高的数值精度,而不像在图像分类中那样选择一个概率最高的类(即argmax函数)。在深入分析的基础上,提出了将目标检测应用于深度SNN时存在的几个问题:a)传统归一化方法效率低下;b)SNN域中缺少一种有效的leaky-ReLU实现方法。
为了克服这些问题,我们提出了两种新的方法:逐通道归一化和阈值不平衡的符号神经元。因此,提出了一个基于脉冲的目标检测模型,称为Spiking-YOLO。作为SNNs中目标检测的第一步,我们实现了基于Tiny YOLO的Spiking-YOLO。
这是第一个用于目标检测的深度SNN,在非平凡数据集PASCAL VOC和MS-COCO上获得了与DNN相当的结果。
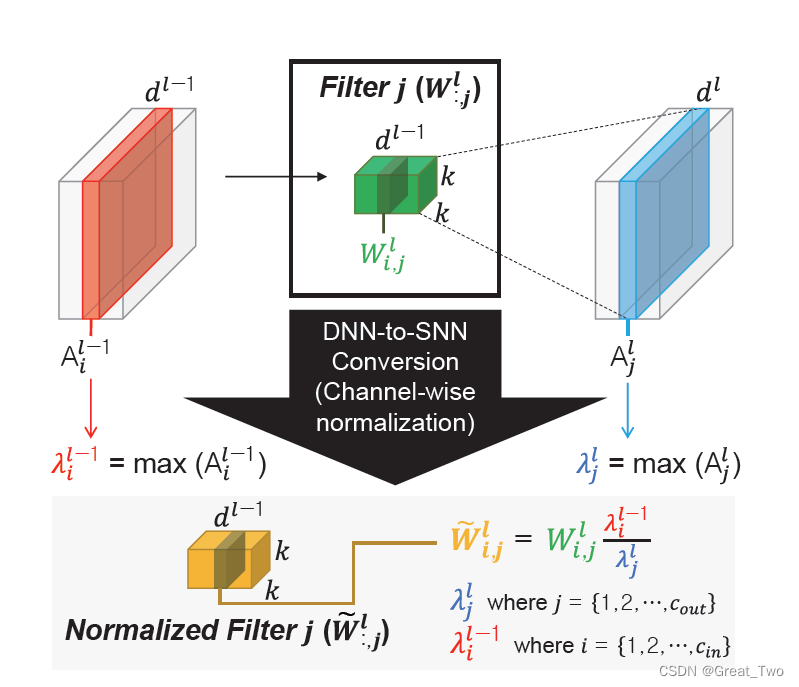
ANN-to-SNN转化细节
- 对Tiny YOLO进行转化,即YOLOv1-tiny,并非YOLOv3-tiny或YOLOv5-tiny
- 使用逐通道归一化取代逐层归一化
- 使用99.9%分位点值进行归一化,而非最大值归一化
- 使用阈值不平衡的符号神经元(IBT)取代IFNode,能够对Leaky-ReLu进行转化
- 使用BatchNorm参数吸收的方法对BatchNorm层进行转化
- 使用Spike Maxpool对Maxpool层进行转化
- 解码时分别使用Vmem解码和Spike count解码两种方式
二、Spikingjelly
1. Spikingjelly中ANN-to-SNN的理论基础
①逐层归一化
对于第l层的参数模块,假定得到了其输入张量Al-1和输出张量Al,其输入张量的最大值为λl-1=max(Al-1),输出张量的最大值为λl=max(Al),则归一化后的权重为
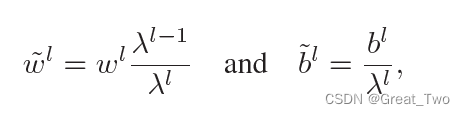
②使用99.9%分位点值
ANN每层输出的分布虽然服从某个特定分布,但是数据中常常会存在较大的离群值,这会导致整体神经元发放率降低。 为了解决这一问题,在进行逐层归一化时,Spikingjelly将缩放因子从张量的最大值调整为张量的p分位点。文献中推荐的分位点值为99.9%
③IFNode替代ReLu激活
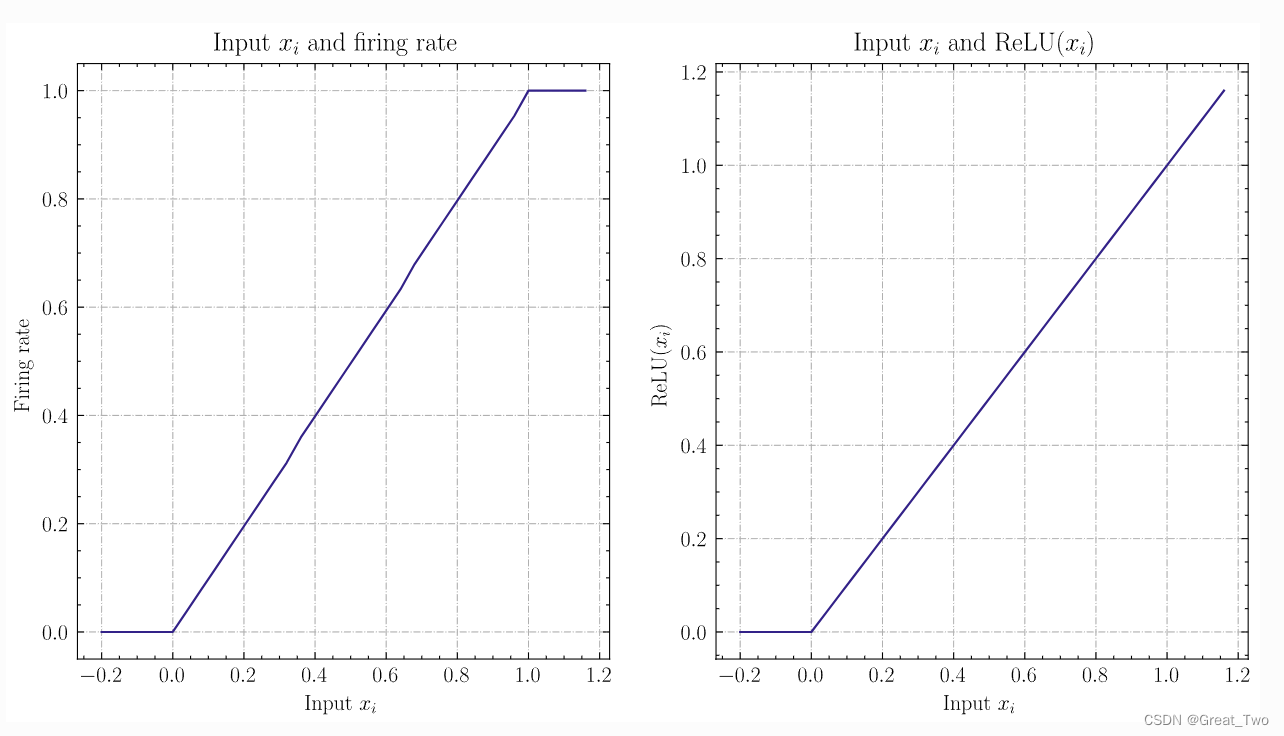
在Spikingjelly所提供的IF神经元脉冲发放频率和输入实验结果中,可以发现IF神经元和ReLu的曲线几乎一致。但需要注意的是,脉冲频率不可能高于1,因此IF神经元无法拟合ANN中ReLU的输入大于1的情况(这也是需要进行归一化的原因)
④BatchNorm参数吸收
假定BatchNorm的参数为 γ (Batchnorm.weight),β (Batchnorm.bias),μ (Batchnorm.running_mean),σ(Batchnorm.running_var)。参数模块(例如Linear)具有W和b,BatchNorm参数吸收就是将BatchNorm的参数通过运算转移到参数模块的W和b中,使得数据输入新模块的输出和有BatchNorm时相同。对此,新模型的W’和b’公式表示为:
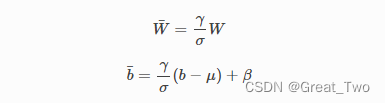
⑤对AvgPool和MaxPool的转化
对于ANN中的平均池化,Spikingjelly将其转化为空间下采样。由于IF神经元可以等效ReLU激活函数。空间下采样后增加IF神经元与否对结果的影响极小。对于ANN中的最大池化,目前没有非常理想的方案。目前的最佳方案为使用基于动量累计脉冲的门控函数控制脉冲通道 1 。此处Spikingjelly依然推荐使用AvgPool2d。
注:上述文字和图片均选自Spikingjelly的官方文档教程。
由上述材料我们可以推知:
- 若要实现Spiking-YOLO中的ANN-to-SNN转化方法,需要对逐层归一化和IFNode神经元进行修改
- 针对99.9%分位点值和BatchNorm参数吸收,Spikingjelly中已有相关的函数实现,无需自定义或修改
- 针对Spiking-YOLO中的 “使用Spike Maxpool对Maxpool层进行转化”,鉴于自身能力有限,博主使用的是Spikingjelly推荐的AvgPool2d,而非Spike Maxpool。
- 针对Spiking-YOLO中的Vmem解码和Spike count解码,鉴于自身能力有限,博主目前使用的是Spike count解码
2.导入Spikingjelly
import spikingjelly
#使用Spikingjelly内置的ann2snn转化方法
from spikingjelly.activation_based import ann2snn
3.进行ANN-to-SNN转化
#使用MNIST数据集仅为方便演示调用Spikingjelly的ANN-to-SNN转化方法
#初始参数设定
batch_size = 100
T = 50 #时间步
#训练集
train_data_dataset = torchvision.datasets.MNIST(
root=dataset_dir,
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
train_data_loader = torch.utils.data.DataLoader(
dataset=train_data_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=False)
#实例化模型
model = mnist_cnn.CNN().to(device)
#导入模型参数
model.load_state_dict(torch.load('SJ-mnist-cnn_model-sample.pth'))
#计算ANN在测试集上的准确率
acc = val(model, device, test_data_loader)
print('ANN Validating Accuracy: %.4f' % (acc))
#将ANN转化为SNN
#这里在逐层归一化时,使用的是最大值进行缩放
#如要使用99.9%分位点进行缩放,只需将 mode='max'改为 mode='99.9%'
model_converter = ann2snn.Converter(mode='max', dataloader=train_data_loader)
snn_model = model_converter(model)
print('Simulating...')
#计算SNN在测试集上的准确率
#这里的T为时间步,一般来说,T越大精度越高,但所需的时间也更长
mode_max_accs = val(snn_model, device, test_data_loader, T=T)
print('SNN accuracy (simulation %d time-steps): %.4f' % (T, mode_max_accs[-1]))
三、基于Spikingjelly实现Spiking-YOLO
1.深入剖析Spikingjelly的转化机制
Spikingjelly使用VoltageScaler类实现缩放功能,具体实现如下:
class VoltageScaler(nn.Module):
def __init__(self, scale=1.0):
"""
:param scale: 缩放值
:type scale: float
``VoltageScaler`` 用于SNN推理中缩放电流。
"""
super().__init__()
self.register_buffer('scale', torch.tensor(scale))
def forward(self, x):
return x * self.scale #逐层归一化
def extra_repr(self): #打印snn网络结构时调用
return '%f' % self.scale.item()
Spikingjelly使用VoltageHook类,在forward()中计算每一层的缩放因子scale,但不对输入张量做任何处理,输入张量的归一化是在VoltageScaler类中实现,具体实现如下:
class VoltageHook(nn.Module):
def __init__(self, scale=1.0, momentum=0.1, mode='Max'):
"""
:param scale: 缩放初始值
:type scale: float
:param momentum: 动量值
:type momentum: float
:param mode: 模式。输入“Max”表示记录ANN激活最大值,“99.9%”表示记录ANN激活的99.9%分位点,输入0-1的float型浮点数表示记录激活最大值的对应倍数。
:type mode: str, float
``VoltageHook`` 被置于ReLU后,用于在ANN推理中确定激活的范围。
"""
super().__init__()
self.register_buffer('scale', torch.tensor(scale))
self.mode = mode
self.num_batches_tracked = 0
self.momentum = momentum
def forward(self, x):
"""
:param x: 输入张量
:type x: torch.Tensor
:return: 原输入张量
:rtype: torch.Tensor
不对输入张量做任何处理,只是抓取ReLU的激活值
"""
err_msg = 'You have used a non-defined VoltageScale Method.'
if isinstance(self.mode, str):
if self.mode[-1] == '%': #使用99.9%分位点进行缩放
try:
s_t = torch.tensor(np.percentile(x.detach().cpu(), float(self.mode[:-1])))
except ValueError:
raise NotImplementedError(err_msg)
elif self.mode.lower() in ['max']: #使用最大值进行缩放
s_t = x.max().detach()
else:
raise NotImplementedError(err_msg)
#其余缩放方式博主在这里进行了删除,如有需要,可自行了解
if self.num_batches_tracked == 0:
self.scale = s_t
else:
self.scale = (1 - self.momentum) * self.scale + self.momentum * s_t
self.num_batches_tracked += x.shape[0]
return x
Spikingjelly使用repalce_by_ifnode()完成ReLu到IFNode的转化,同时调用VoltageScaler类实现对输入和输出张量的归一化:
#本段代码只截取了repalce_by_ifnode()的一部分,仅为方便理解Spikingjelly中的ReLu->IFNode的转化以及归一化操作
#对于每一层,如果使用的是ReLU激活函数
if type(fx_model.get_submodule(node.args[0].target)) is nn.ReLU:
m0 = VoltageScaler(1.0 / s) # 输入张量除以缩放因子,完成归一化
m1 = neuron.IFNode(v_threshold=1., v_reset=None) # 将ReLu替换为IFNode神经元
m2 = VoltageScaler(s) # 输出张量乘以缩放因子,以获得归一化前的原始激活值
2.基于Spikingjelly实现逐通道归一化
对于逐通道归一化,原论文的算法流程如下:

在Spikingjelly中实现的是逐层归一化,每一层的缩放因子scale是一个1*1的张量;而在逐通道归一化中,每一个通道都有一个缩放因子,因此每一层共有channels *1 个缩放因子。
博主这里分三步实现逐通道归一化,算法流程如下:
- 对于每一层,首先计算每个通道的缩放因子channel_scale,即一个大小为1*1的张量
- 然后再将该层所有通道的缩放因子channel_scale合并为一个大小为channels*1的张量channel_scales。
- 借助pytorch的广播机制,只需再将channel_scales重塑成一个大小为(1,channels,1,1)的4维张量scale,输入张量x便可以和scale在通道维度(dim=1)进行运算,以此实现逐通道归一化。
由于Spikingjelly是在VoltageHook类中计算每一层的缩放因子scale,所以实现逐通道归一化只需重写VoltageHook类即可:
class VoltageHook(nn.Module):
def __init__(self, scale=1.0, momentum=0.1, mode='Max'):
"""
:param scale: 缩放初始值
:type scale: float
:param momentum: 动量值
:type momentum: float
:param mode: 模式。输入“Max”表示记录ANN激活最大值,“99.9%”表示记录ANN激活的99.9%分位点,输入0-1的float型浮点数表示记录激活最大值的对应倍数。
:type mode: str, float
``VoltageHook`` 被置于ReLU后,用于在ANN推理中确定激活的范围。
"""
super().__init__()
self.register_buffer('scale', torch.tensor(scale))
self.mode = mode
self.num_batches_tracked = 0
self.momentum = momentum
def forward(self, x):
"""
:param x: 输入张量
:type x: torch.Tensor
:return: 原输入张量
:rtype: torch.Tensor
不对输入张量做任何处理,只是抓取ReLU的激活值
"""
err_msg = 'You have used a non-defined VoltageScale Method.'
if isinstance(self.mode, str):
if self.mode[-1] == '%':# 99.9%分位点进行缩放
try:
#逐层归一化:
#s_t = torch.tensor(np.percentile(x.detach().cpu(), float(self.mode[:-1])))
#逐通道归一化:
channels = x.size(1)
channel_scales = torch.empty(1, channels, 1, 1) # scale为[1,C,1,1]的四维张量
channel_scales = [torch.tensor([torch.percentile(abs_x[:, channel, :, :], percentile_value) for channel in range(channels)]
)
for channel in range(channels): #计算输入张量x中每个channel的99.9%分位值
#注:这里必须先取输入张量x的绝对值,因为原先Spikingjlly中默认是将ReLu转化为IFNode,不存在负激活值的情况,需将激活值缩放到[0,1];
#注:AAAI中是将Leaky-ReLu转化为IBM(带符号的神经元),存在大量负激活的情况,需将激活值缩放到[-1,1],所以需要对输入张量x先取绝对值后再计算
channel_scale = torch.tensor(np.percentile(torch.abs(x[:, channel, :, :].detach().cpu()), float(self.mode[:-1])))
channel_scales[0, channel, 0, 0] = channel_scale
s_t = channel_scales.view(1, channels, 1, 1)
#s_t为[1,C,1,1]的4维张量
except ValueError:
raise NotImplementedError(err_msg)
elif self.mode.lower() in ['max']:# 最大值进行缩放
#逐层归一化:
#s_t = x.max().detach()
#逐通道归一化:
#注:同样需要先对输入张量x取绝对值再计算
s_t = torch.max(torch.max(torch.max(torch.abs(x.detach()), dim=-1).values, dim=-1).values, dim=0).values.unsqueeze(
0).unsqueeze(-1).unsqueeze(-1)
#s_t为[1,C,1,1]的四维张量
else:
raise NotImplementedError(err_msg)
if self.num_batches_tracked == 0:
self.scale = s_t
else:
self.scale = (1 - self.momentum) * self.scale + self.momentum * s_t
self.num_batches_tracked += x.shape[0]
return x
3.基于Spikingjelly实现阈值不平衡的符号神经元
原论文中对阈值不平衡的符号神经元(IBT)的定义如下:
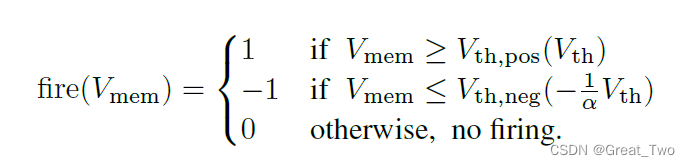
原论文提出阈值不平衡的符号神经元(IBT),在负值区域使用临界电压,不仅可以传递正负激活值,保持离散型,还可以高效和准确地仿照leaky-ReLu的leakage项
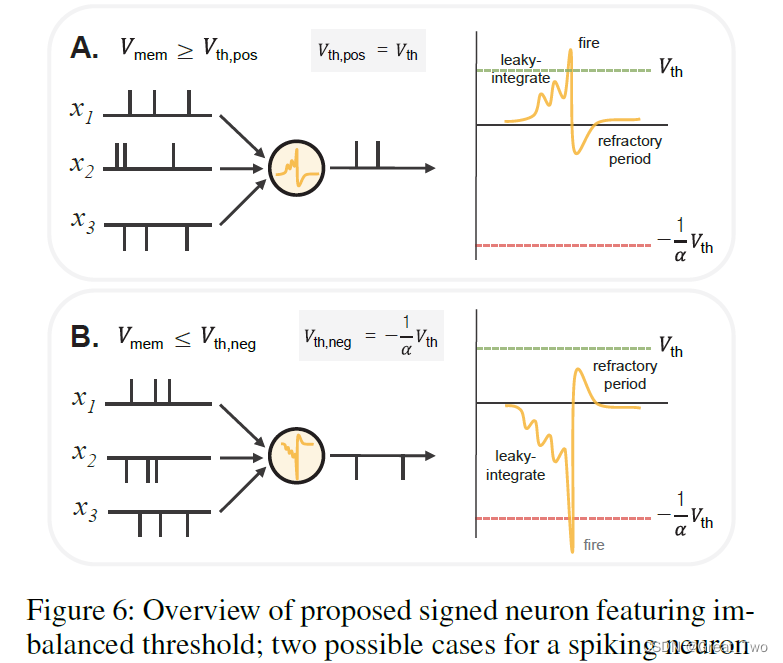
如图6所示,假设Vth,pos = 1V,在α = 0.1时,Vth,neg = -10V,膜电压需要多积累10倍来发射负脉冲,类似于Leaky-ReLu。
若在Spikingjelly中实现阈值不平衡的符号神经元(IBT),只需仿照IFNode自定义IBM神经元即可
注:Spikingjelly提供了s和m两种步进模式,同时也定义了hard_reset和soft_reset两种膜电位重置方法,自定义时需对上述情况分别进行重写,博主这里只展示了s步进+hard_reset和s步进+soft_reset两种:
class IBT(BaseNode):
def __init__(self, v_threshold: float = 1., v_reset: float = 0.,
surrogate_function: Callable = surrogate.Sigmoid(), detach_reset: bool = False, step_mode='s',
backend='torch', store_v_seq: bool = False):
"""
:param v_threshold: 神经元的阈值电压
:type v_threshold: float
:param v_reset: 神经元的重置电压。如果不为 ``None``,当神经元释放脉冲后,电压会被重置为 ``v_reset``;
如果设置为 ``None``,当神经元释放脉冲后,电压会被减去 ``v_threshold``
:type v_reset: float
:param surrogate_function: 反向传播时用来计算脉冲函数梯度的替代函数
:type surrogate_function: Callable
:param detach_reset: 是否将reset过程的计算图分离
:type detach_reset: bool
:param step_mode: 步进模式,可以为 `'s'` (单步) 或 `'m'` (多步)
:type step_mode: str
:param backend: 使用那种后端。不同的 ``step_mode`` 可能会带有不同的后端。可以通过打印 ``self.supported_backends`` 查看当前
使用的步进模式支持的后端。在支持的情况下,使用 ``'cupy'`` 后端是速度最快的
:type backend: str
:param store_v_seq: 在使用 ``step_mode = 'm'`` 时,给与 ``shape = [T, N, *]`` 的输入后,是否保存中间过程的 ``shape = [T, N, *]``
的各个时间步的电压值 ``self.v_seq`` 。设置为 ``False`` 时计算完成后只保留最后一个时刻的电压,即 ``shape = [N, *]`` 的 ``self.v`` 。
通常设置成 ``False`` ,可以节省内存
:type store_v_seq: bool
Integrate-and-Fire 神经元模型,可以看作理想积分器,无输入时电压保持恒定,不会像LIF神经元那样衰减。其阈下神经动力学方程为:
"""
super().__init__(v_threshold, v_reset, surrogate_function, detach_reset, step_mode, backend, store_v_seq)
@property
def supported_backends(self):
if self.step_mode == 's':
return ('torch', 'cupy')
elif self.step_mode == 'm':
return ('torch', 'cupy')
else:
raise ValueError(self.step_mode)
def neuronal_charge(self, x: torch.Tensor):
self.v = self.v + x
@staticmethod
@torch.jit.script
def jit_eval_single_step_forward_hard_reset(x: torch.Tensor, v: torch.Tensor, v_threshold: float, v_reset: float):
v = v + x
#IFNode
#spike = (v >= v_threshold).to(x)
#v = v_reset * spike + (1. - spike) * v
#IBT
spike_p = (v >= v_threshold).to(x) # spike_p为正脉冲,产生0或1
spike_n = -1. * (v <= -10.0 * v_threshold).to(x)# spike_n为负脉冲,产生0或-1,这里假定α=0.1
spike = spike_p + spike_n # 最终产生的脉冲spike等于正负脉冲之和,这个数学公式可以自行推导
v = v_reset * spike + (1. - torch.abs(spike)) * v
return spike, v
@staticmethod
@torch.jit.script
def jit_eval_single_step_forward_soft_reset(x: torch.Tensor, v: torch.Tensor, v_threshold: float):
v = v + x
#IFNode
#spike = (v >= v_threshold).to(x)
#v = v - spike * v_threshold
#IBT
spike_p = (v >= v_threshold).to(x) # spike_p为正脉冲,产生0或1
spike_n = -1.*(v <= -10.0 * v_threshold).to(x) # spike_n为负脉冲,产生0或-1,这里假定α=0.1
spike = spike_p + spike_n # 最终产生的脉冲spike等于正负脉冲之和,这个数学公式可以自行推导
v = v - spike_p * v_threshold - spike_n * v_threshold * 10.0 #此数学公式可自行推导
return spike, v
4.在replace_by_ifnode()中进行整合
在实现逐通道归一化和阈值不平衡的符号神经元(IBT)后,只需在replace_by_ifnode函数中对上述两种方法进行整合即可:
@staticmethod
def replace_by_ifnode(fx_model: torch.fx.GraphModule) -> torch.fx.GraphModule:
hook_cnt = -1
for node in fx_model.graph.nodes:
if node.op != 'call_module':
continue
if type(fx_model.get_submodule(node.target)) is VoltageHook:
if type(fx_model.get_submodule(node.args[0].target)) is nn.LeakyReLU:
hook_cnt += 1
hook_node = node
relu_node = node.args[0]
if len(relu_node.args) != 1:
raise NotImplementedError('The number of relu_node.args should be 1.')
#原先实现的是逐层归一化,scale仅为1维张量,故可以进行.item()的操作
#s = fx_model.get_submodule(node.target).scale.item()
#在逐通道归一化中,scale为[1,C,1,1]的4维张量,不能进行.item()的操作
s = fx_model.get_submodule(node.target).scale
target0 = 'snn tailor.' + str(hook_cnt) + '.0' # voltage_scaler
target1 = 'snn tailor.' + str(hook_cnt) + '.1' # IF_node
target2 = 'snn tailor.' + str(hook_cnt) + '.2' # voltage_scaler
m0 = VoltageScaler(1.0 / s)
#使用自定义的阈值不平衡的符号神经元(IBT),v_reset=None即使用soft_reset
m1 = neuron.IBT(v_threshold=1., v_reset=None)
m2 = VoltageScaler(s)
node0 = Converter._add_module_and_node(fx_model, target0, hook_node, m0,
relu_node.args)
node1 = Converter._add_module_and_node(fx_model, target1, node0, m1
, (node0,))
node2 = Converter._add_module_and_node(fx_model, target2, node1, m2, args=(node1,))
relu_node.replace_all_uses_with(node2)
node2.args = (node1,)
fx_model.graph.erase_node(hook_node)
fx_model.graph.erase_node(relu_node)
fx_model.delete_all_unused_submodules()
fx_model.graph.lint()
fx_model.recompile()
return fx_model
5.对训练好的Tiny YOLO进行ANN-to-SNN转换
model_converter = ann2snn.Converter(mode='99.9%', dataloader=train_data_loader) # 原论文使用99.9%分位值进行逐通道归一化
snn_model = model_converter(yolo_model) # yolo_model是以训练好的模型
总结
谢谢各位的浏览,如有不足欢迎下方留言评论。

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









