









1、正则表达式在文本编辑中用处大,其基本规则有:
匹配操作符
\ 转义字符
. 匹配任意单个字符
[1249a],[^12],[a-k] 字符序列单字符占位
^ 行首
$ 行尾
\<,\>:\<abc 单词首尾边界
| 连接操作符
(,) 选择操作符
\n 反向引用
重复操作符:
? 匹配0到1次。
* 匹配0到多次。
+ 匹配1到多次。
{n} 匹配n次。
{n,} 匹配n到多次。
{n,m} 匹配n到m次。
与扩展正则表达式的区别:grep basic
?, +, {, |, (, and )
匹配任意字符
.*
2-1、实例操作:
有以下文本例子
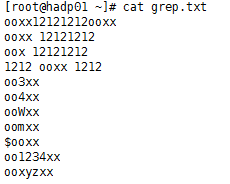
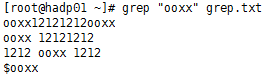
①、找出含有ooxx的行:
grep “ooxx” grep.txt
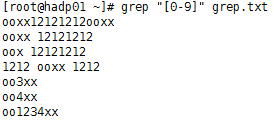
②、找出包含数字的行:
grep “[0-9]” grep.txt
③、找出包含3或者4的行
grep “[34]” grep.txt

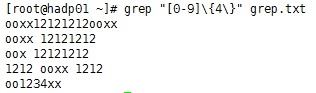
④、找出包好4个数字的行:
grep “[0-9]{4}” grep.txt或者grep -E “[0-9]{4}” grep.txt
⑤、找出包含ooxx单词的行
grep “<ooxx>” grep.txt

⑥、只包含4位数字的行
grep “[ ^0-9][0-9]{4}[ ^0-9]” grep.txt

2-2实例操作
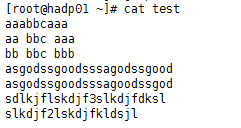
①、grep “a” test
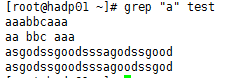
②、grep “a{3}” test

③、grep “<aaa” test,查找以aaa开头的
④、grep “<aaa>” test

⑤、 grep “b” test

⑥、grep “b{2,3}” test
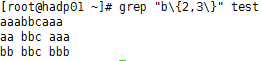
⑦、 grep “god” test
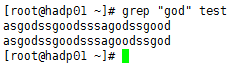
⑧、 grep “godgood” test
无输出
⑨、grep “god*good” test
无输出
⑩、grep “god.good" test

⑪、grep "god.good.god.good" test
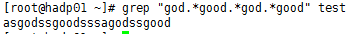
⑫、grep "god.good+" test
无输出
⑬、grep "(god.good)+" test
无输出
⑭、grep “(god).good.\1” test

⑮、grep "(god).(good).\1.\2" test
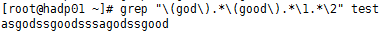
⑯、grep "(god).(good).\2.\1” test
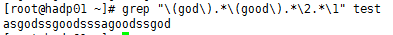
2、文本操作符
cut:显示切割的行数据
f:选择显示的列
s:不显示没有分隔符的行
d:自定义分隔符,下例子中-d自定义分隔符空格
例如:cut -d’ ’ -f1 gerp.txt
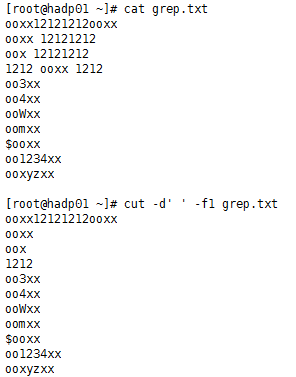
查看passwd下的第一列用户名数据


sort:排序文件的行
n:按数值排序
r:倒序
t:自定义分隔符
k:选择排序列
u:合并相同行
f:忽略大小写















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









