






深度学习发展
前言
以下内容均为个人观点,如有错误,可以与我联系,我会尽快改正。
以时间为线索来看深度学习的发展
要说深度学习就首先要先讲一下什么是人工智能:
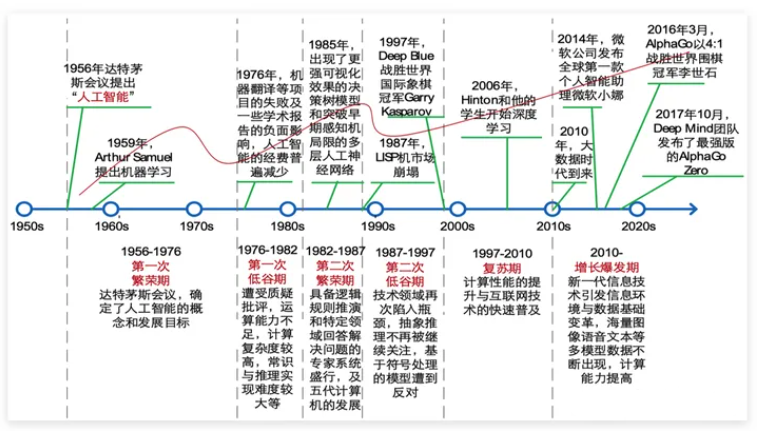
人工智能掀起过三次浪潮
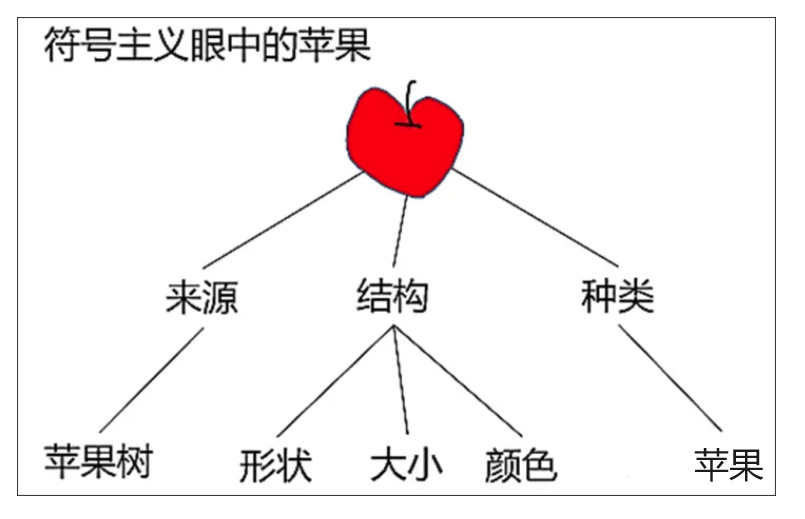
2000年以前 - 符号主义
其中2000年以前以符号主义为主,2000年后随着计算机技术的发展,连接主义开始兴起。
符号主义(逻辑主义、心理学派、计算机学派)基本思想:
人类的认知过程是各种符号进行推理运算的过程。
人是一个物理符号系统,计算机也是一个物理符号系统,因此,能用计算机来模拟人的智能行为。
知识表示、知识推理、知识运用是人工智能的核心。符号主义认为知识和概念可以用符号表示,认知就是符号处理过程,推理就是采用启发式知识及启发式搜索对问题求解的过程。
2000年 - 连接主义兴起
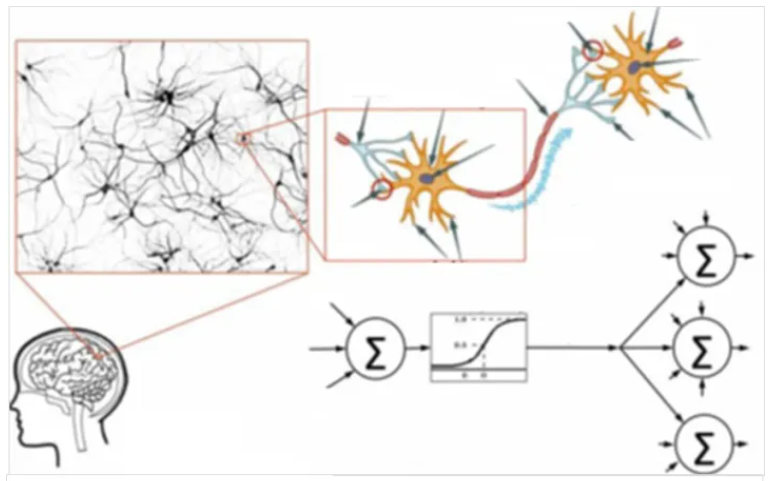
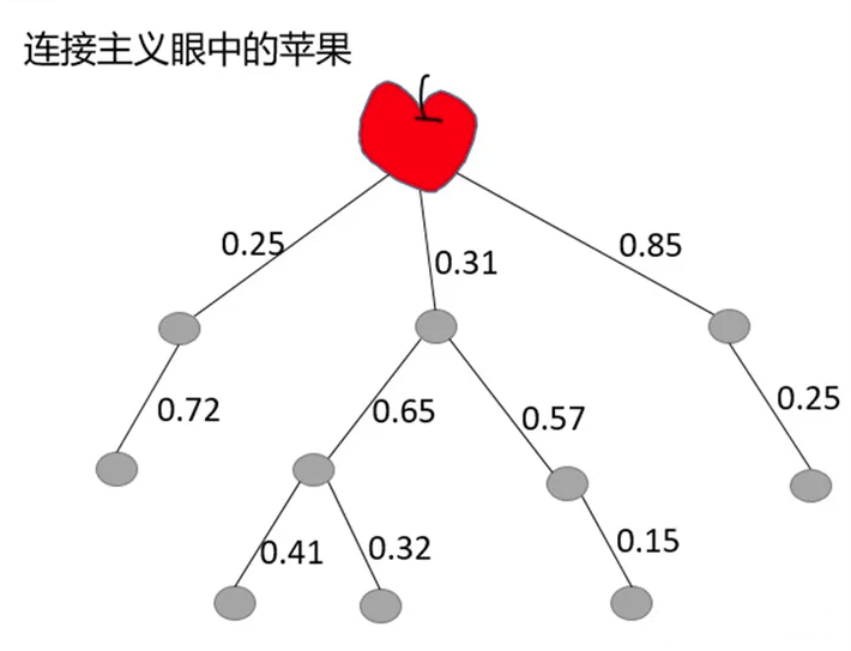
连接主义
连接主义源于仿生学,特别是人脑模型的研究。
对于连接主义的基本思想:
思维的基本是神经元,而不是符号处理过程。
人脑不同于电脑,并提出连接主义的电脑工作模式,用于取代符号操作的电脑工作模式。
连接主义中,一个概念用一组数字,向量,矩阵或张量表示。概念由整个网络的特定激活模式表示。每个节点没有特定的意义,但是每个节点都参与整个概念的表示。
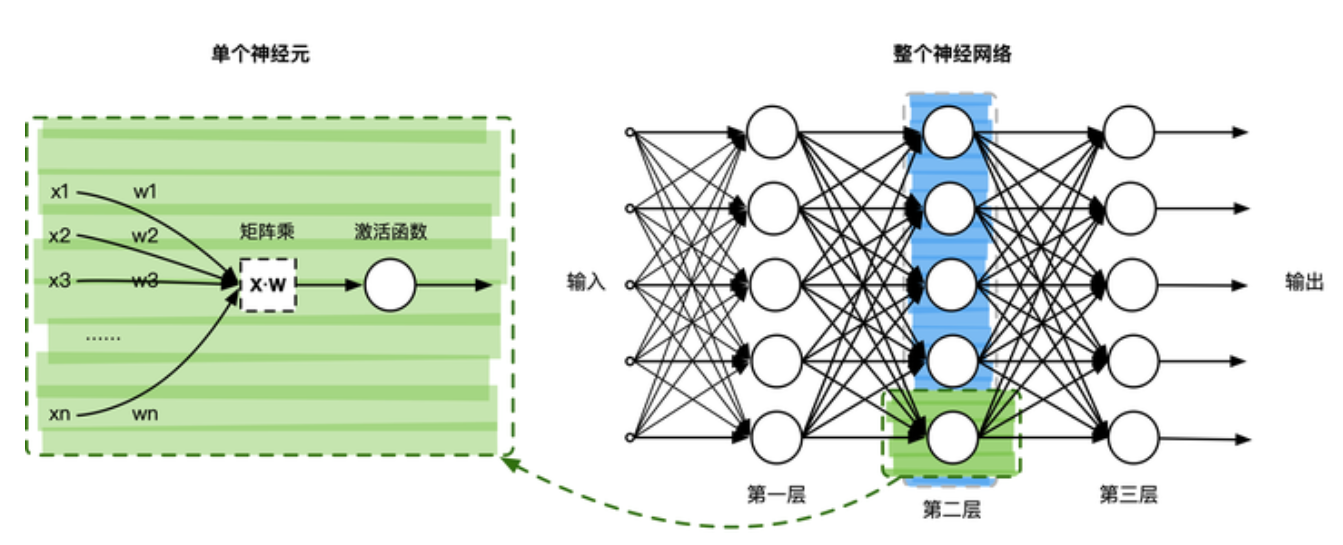
现在业界比较通用对神经网络概念的解释是:
1)从通用概念的角度上来看的话,神经网络是在模拟人脑的工作机制,神经元与神经突触之间的连接产生不同的信号传递,每个神经元都记录着信号的特征。
以一个三层的MLP网络举例,一个神经网络由多个神经元结构组成,每一层的神经元都拥有多个输入和输出,一层可以由多个神经元组成。例如第2层神经网络的神经元输出是第3层神经元的输入,输入的数据通过神经元上的激活函数(非线性函数如tanh、sigmod等),来控制输出的数值。数学上简单理解,单个神经元其实就是一个X·W的矩阵乘,然后加一个激活函数fun(X·W),通过复合函数进行组合神经元,变成一个神经网络的层。
特征图经过网络前向传播通过权重参数计算输出结果;反向传播通过导数链式法则计算损失函数对各参数的梯度,并根据梯度进行参数的更新
- 卷积层
提起神经网络就一定要讲卷积层,卷积层是主干网络的基础部件之一,负责提取数据中的特征。与全连接层相比卷积层可以保持输入数据的形状不变。当输入数据是图像时,卷积层会以3 维数据的形式接收输入数据,而全连接层需要将数据展平成二维才能输入。而且卷积层的参数量较小。
因此,在 CNN 中,可以正确理解图像等具有形状的数据。
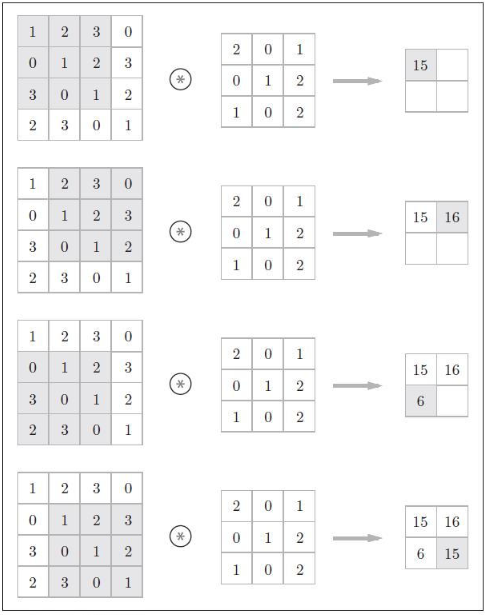
卷积层(Convolution Layer)的主要作用是对输入的数据进行特征提取,而完成该功能的是卷积层中的卷积核(Filter)。
我们可以将卷积核看作一个指定窗口大小的扫描器,扫描器通过一次又一次地扫描输入的数据,来提取数据中的特征。如果我们输入的是图像数据,那么在通过卷积核的处理后,就可以识别出图像中的重要特征了。
这是一张5x5的图像数据,对数据进行卷积,定义卷积为三通道输入(in_channels),二通道输出(out_channels),步幅2(stride),边缘填充1(padding)
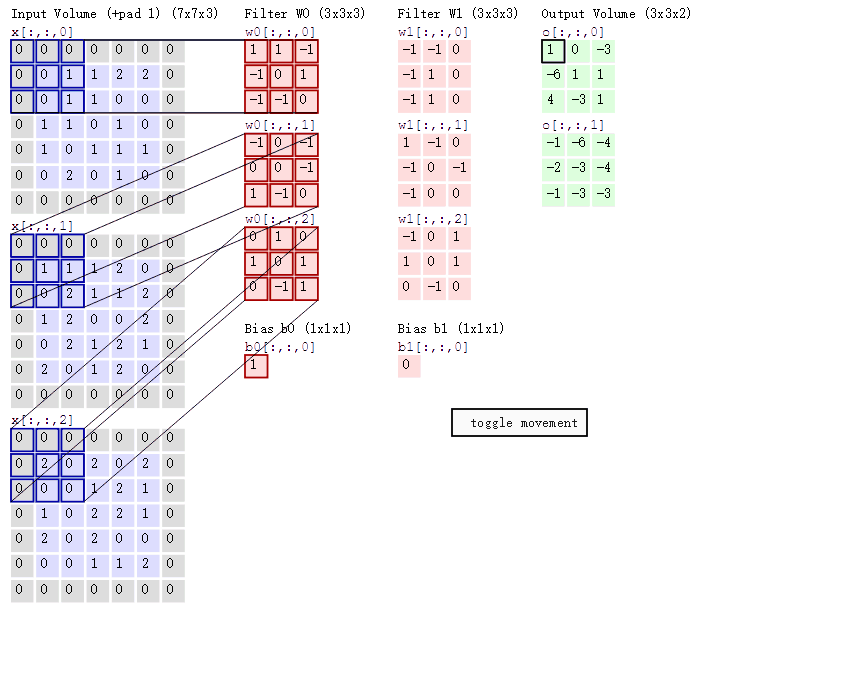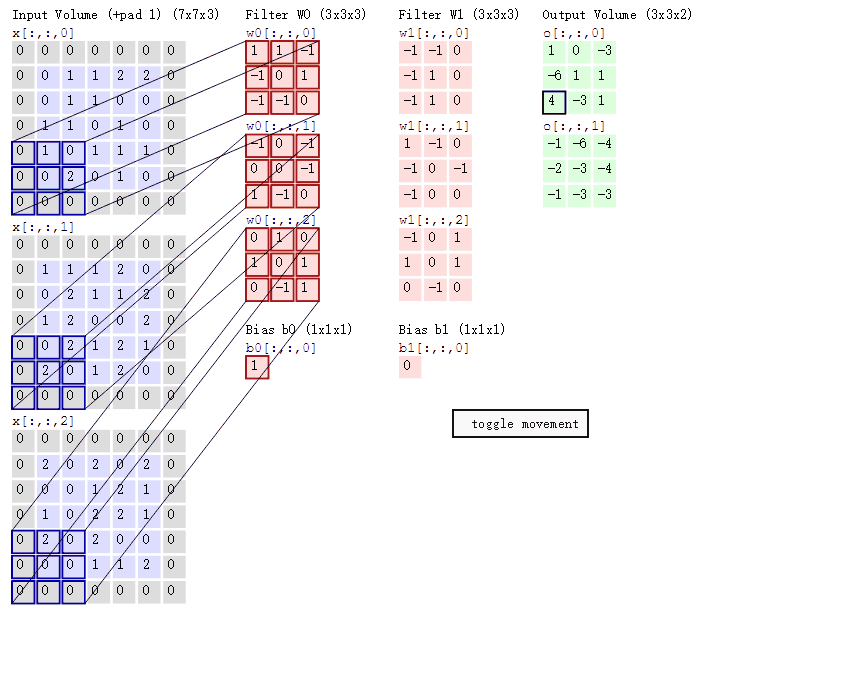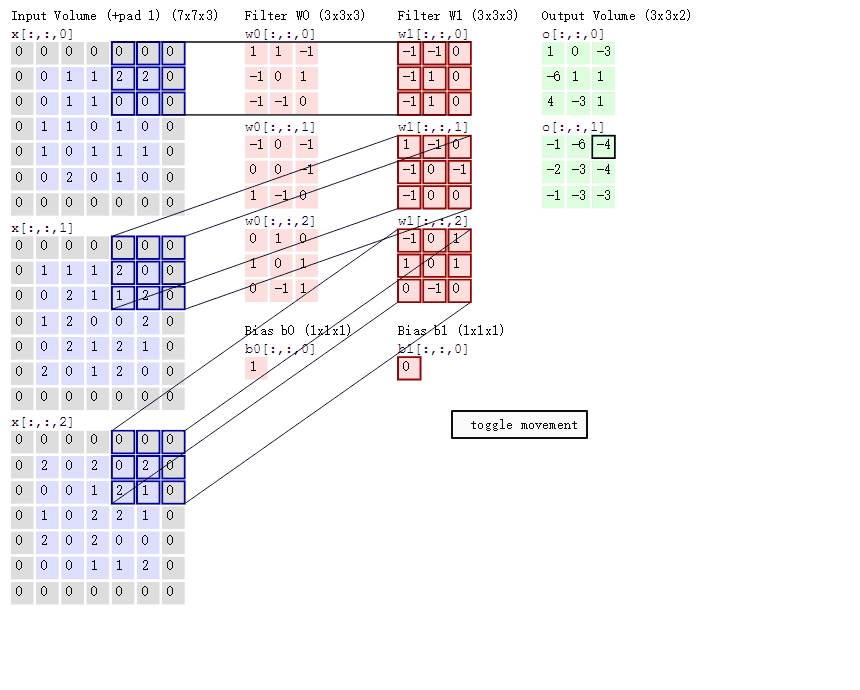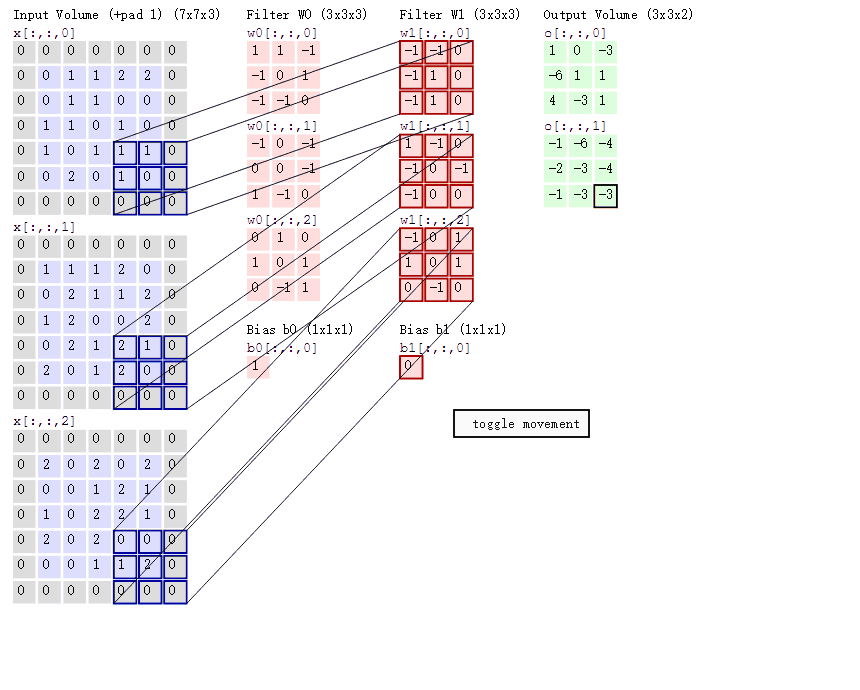
下面代码用卷积层对图像进行边缘检测
这里使用了三种不同的算子(卷积核)对图像进行边缘检测操作
- ker = [[1, 0, -1],
[1, 0, -1],
[1, 0, -1]] - ker2 = [[1, 0, -1], # Sobel滤波器
[2, 0, -2],
[1, 0, -1]] - ker3 = [[3, 0, -3], # Scharr滤波器
[10, 0, -10],
[3, 0, -3]]
# 导入所需库
from PIL import Image
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch import nn
# 打开并转换图像为灰度模式
image = Image.open('Beautiful.jpg')
image = image.convert("L")
image_np = np.array(image)
# 获取图像的高度和宽度
h, w = image_np.shape
# 将图像转换为PyTorch张量
image_tensor = torch.from_numpy(image_np.reshape(1, 1, h, w)).float()
# 定义卷积核的大小
kersize = 3
# 创建一个卷积核,初始化为-1的矩阵
# ker = torch.ones(kersize, kersize, dtype=torch.float32) * -1
# ker[2, 2] = 24
# ker = torch.tensor([[1, 0, -1],
# [1, 0, -1],
# [1, 0, -1]], dtype=torch.float)
# ker = torch.tensor([[1, 0, -1], # Sobel滤波器
# [2, 0, -2],
# [1, 0, -1]], dtype=torch.float)
ker = torch.tensor([[3, 0, -3], # Scharr滤波器
[10, 0, -10],
[3, 0, -3]], dtype=torch.float)
print(ker)
# 创建卷积层并将卷积核赋值给卷积层的权重
conv2d = torch.nn.Conv2d(1, 1, (kersize, kersize), bias=False)
ker = ker.reshape((1, 1, kersize, kersize))
conv2d.weight.data = ker
# 对图像进行卷积操作
image_out = conv2d(image_tensor)
image_out = image_out.data.squeeze()
# 显示卷积后的图像
plt.axis('off')
plt.imshow(image_out, cmap=plt.cm.gray)
plt.show()
原始图像长这样:

这里对图像做垂直边缘检测,结果如下:

这里对图像做水平边缘检测(对算子进行转置就可以了),结果如下:

2012年 AlexNet:手动学习 -> 自动学习
AlexNet是深度学习第一个发展节点,在AlexNet网络问世之前,大量的学者在进行图像分类、分割、识别等工作时,主要是通过对图像进行手工特征提取或是特征+机器学习的方法。但是,这种手工准确提取特征是非常难的事情,而且即便使用机器学习的方法,整个算法的鲁棒性依然存在较大的问题。因此,一直都有一种讨论:特征是不是也是可以进行学习的?如果是可以学习的,那么特征的表示是不是也存在层级问题(例如第一层为线或是点特征,第二层为线与点组成的初步特征,第三层为局部特征)?从这一思想出发,特征可学习且自动组合并给出结果,这是典型的“end-to-end”,而特征学习与自由组合就是深度学习的黑盒子部分。
AlexNet网络结构相对简单,使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层,具体如下所示。
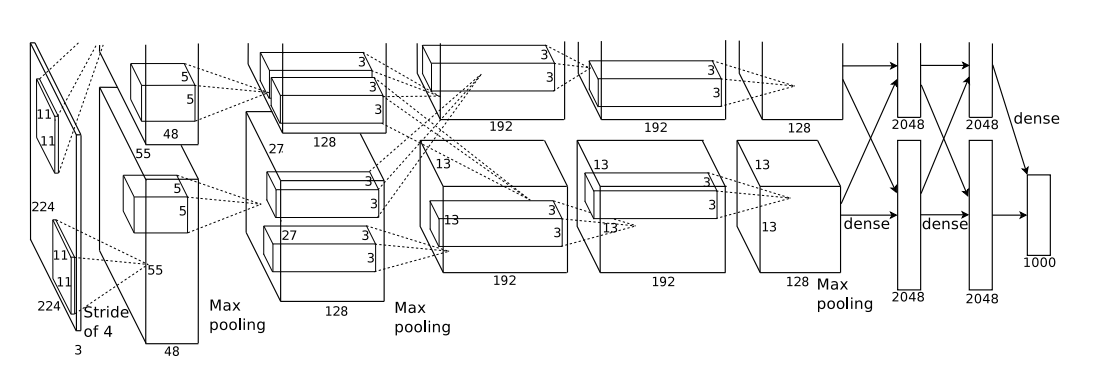
文章下载地址
https://proceedings.neurips.cc/paper_files/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
2015 Resnet:更大更深
AlexNet是2012年ImageNet竞赛的冠军模型。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg(19层),GoogLeNet(22层)。人们发现更大更深的模型往往效果很好,但是在设计模型的时候科学家们发现了问题,如果模型设计的过深或者激活函数不合理就会导致梯度在反向传播的过程中出现弥散或者过大出现梯度消失,梯度爆炸的现象。
为了解决这些问题何凯明团队在2015年ImageNet竞赛中提出了ResNet模型(残差网络)取得了当年的冠军,将模型深度提高到了152层。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。在模型块中加入了Batch Normalization(批规范化层),其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题 。
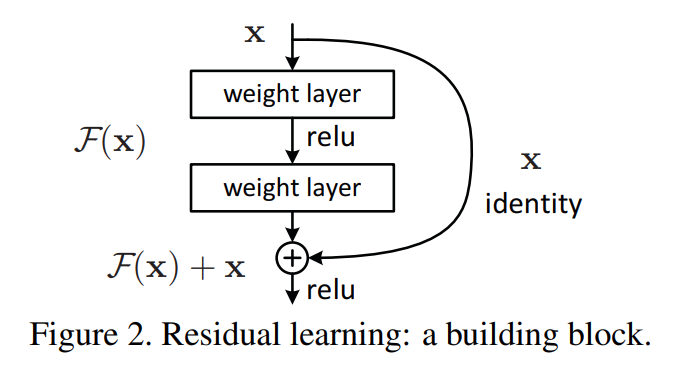
这是一个残差块的基本结构,他和普通的顺序型连接的区别就是将网络块的输入直接连接到了输出处,使他的输入传播到网络的深层也不会消失,这个小改进使用到了恒等映射的思想。
恒等映射
恒等映射亦称恒等函数,对任何元素,象于原象相同的映射。对于映射函数f(x),若它的定义域A和值域B相等,并对所有的a ∈ A均有f ( a ) = af(a)=a时,则称f(x)为恒等映射。
多增加的网络层全部为恒等映射时,可以认为不会产生性能损失。
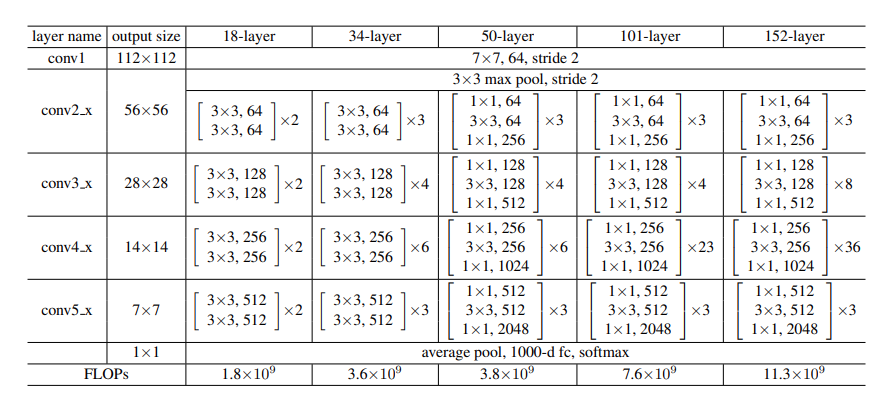
作者设计了多个版本:ResNet-50,ResNet-101,ResNet-152. 随着深度增加,因为解决了退化问题,性能不断提升。作者最后在Cifar-10上尝试了1202层的网络,结果在训练误差上与一个较浅的110层的相近,但是测试误差要比110层大1.5%。作者认为是采用了太深的网络,发生了过拟合。
这个网络的残差结构,几乎应用到了后面的所有主干网络中。真正意义上的使深度学习变得深度
文章下载地址
https://arxiv.org/abs/1512.03385v1
2020 vision transformer:二分天下
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究,从此深度学习视觉方向由卷积网络和Transformer网络二分天下。
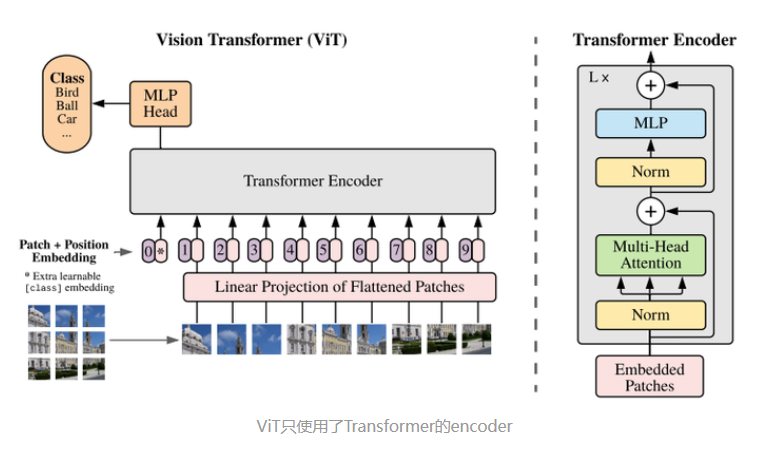
transformer最初是应用在自然语言处理中的,vision transformer的原理就是将输入图像分成一个个小碎片,将碎片看作是句子中的单词(patch),对碎片进行位置编码再传入主干网络
ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果
文章下载地址
https://arxiv.org/abs/2010.11929v2
神经网络的两大结构
神经网络的两大结构:循环结构LSTM
一个处理图像的神经网络,通常他的输入数据尺寸为(N x C x h x w), N代表了他一次性处理n个数据,神经网络默认这n个数据间是没有关系的,但当我们处理有时间顺序或前后顺序的数据时之前的网络就不好用了,学者们就设计出了具有循环结构的网络LSTM(长短期记忆递归神经网络):
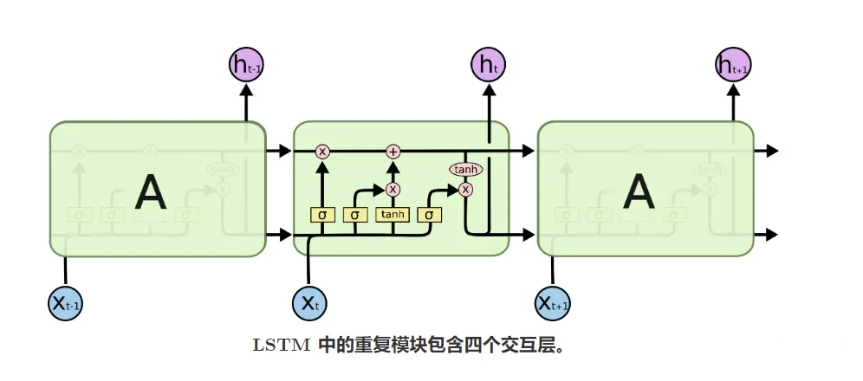
在上图中,每一个红色圆形代表对向量做出的操作(pointwise operation, 对位操作),而黄色的矩形代表一个神经网络的网络块,上面的字符代表神经网络所使用的激活函数
- LSTM的关键:单元状态
LSTM能够从RNN中脱颖而出的关键就在于上图中从单元中贯穿而过的线 ——神经元的隐藏态(单元状态),我们可以将神经元的隐藏态简单的理解成递归神经网络对于输入数据的“记忆”,用
表示神经元在 时刻过后的“记忆”,这个向量涵盖了在时刻前神经网络对于所有输入信息的“概括总结” - LSTM_1 遗忘门:
对于上一时刻LSTM中的单元状态来说,一些“信息”可能会随着时间的流逝而“过时”。为了不让过多记忆影响神经网络对现在输入的处理,我们应该选择性遗忘一些在之前单元状态中的分量——这个工作就交给了“遗忘门” - LSTM_2 & 3 记忆门
记忆门是用来控制是否将在
时刻(现在)的数据并入单元状态中的控制单位。首先,用tanh函数层将现在的向量中的有效信息提取出来,然后使用(图上tanh函数层左侧)的sigmoid函数来控制这些记忆要放“多少”进入单元状态。这两者结合起来就可以做到:
每一次输入一个新的输入,LSTM会先根据新的输入和上一时刻的输出决定遗忘掉之前的哪些记忆——输入和上一步的输出会整合为一个单独的向量,然后通过sigmoid神经层,最后点对点的乘在单元状态上。因为sigmoid 函数会将任意输入压缩到
的区间上,我们可以非常直觉的得出这个门的工作原理 —— 如果整合后的向量某个分量在通过sigmoid层后变为0,那么显然单元状态在对位相乘后对应的分量也会变成0,换句话说,“遗忘”了这个分量上的信息;如果某个分量通过sigmoid层后为1,单元状态会“保持完整记忆”。不同的sigmoid输出会带来不同信息的记忆与遗忘。通过这种方式,LSTM可以长期记忆重要信息,并且记忆可以随着输入进行动态调整
- LSTM_4 输出门
输出门,顾名思义,就是LSTM单元用于计算当前时刻的输出值的神经层。输出层会先将当前输入值与上一时刻输出值整合后的向量(也就是公式中的
)用sigmoid函数提取其中的信息,接着,会将当前的单元状态通过tanh函数压缩映射到区间(-1, 1)中*
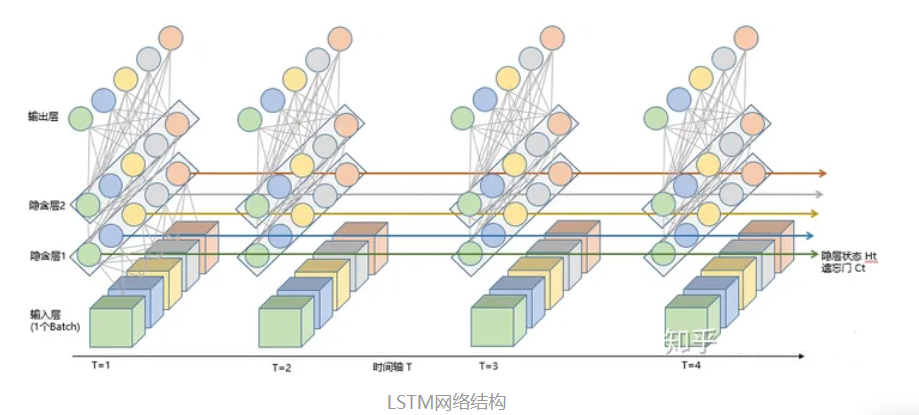
上面的图表示包含2个隐含层的LSTM网络,在T=1时刻看,它是一个普通的BP网络,在T=2时刻看也是一个普通的BP网络,只是沿时间轴展开后,T=1训练的隐含层信息H,C会被传递到下一个时刻T=2,如下图所示。上图中向右的五个常常的箭头,所的也是隐含层状态在时间轴上的传递。
神经网络的两大结构:顺序结构
顺序结构的神经网络主要由三部分构成:backbone, neck, head,下面以deeplabv3网络举例:
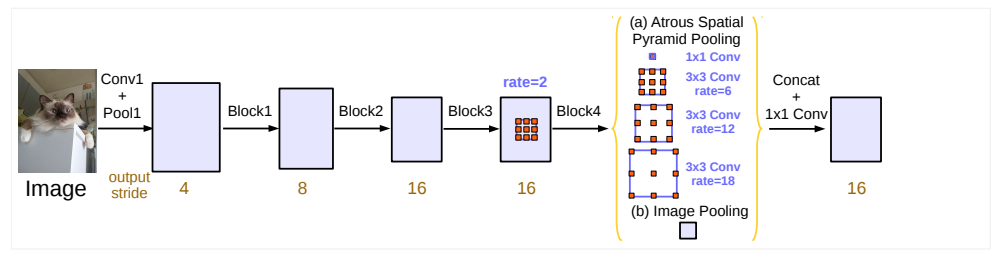
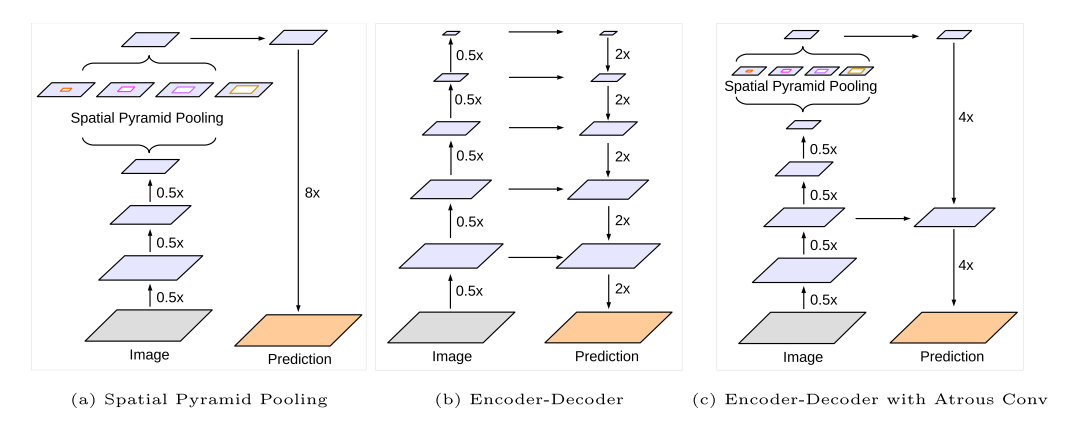
文章下载地址
https://openaccess.thecvf.com/content_ECCV_2018/papers/Liang-Chieh_Chen_Encoder-Decoder_with_Atrous_ECCV_2018_paper.pdf
Backbone, 译作骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等;
Head,译作检测头,主要用于预测结果,根据任务不同head的形式也不同,分类任务可能就只是个全连接层,目标检测任务就是多个全连接层或卷积层组成的(因为要输出的内容多且复杂,目标坐标角度种类置信度等),语言分割任务就是由多个卷积层与反卷积层组成(或者说是膨胀层,反卷积层用来将特征图恢复原始大小)
在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层,通常称为Neck。
简而言之,基于深度学习的目标检测模型的结构是这样的:输入->主干->脖子->头->输出。
主干网络提取特征,脖子负责将特征重组,将特征处理成更容易检测的状态,然后头部计算预测输出。
总结
在本文中,我们回顾了深度学习的发展历程,从2000年以前的符号主义到2020年的Vision Transformer。这一演进过程展示了深度学习在人工智能领域的巨大进步,如2012年的AlexNet和2015年的ResNet等重要里程碑。
深度学习不仅改变了我们对计算机视觉和自然语言处理等问题的解决方式,还在图像识别领域取得了显著的成就。以图像分类为例,深度卷积神经网络(CNN)如AlexNet、ResNet和Inception等模型已经在图像分类任务中取得了巨大成功。这些模型能够识别图像中的对象、动物、物体等,不仅在学术界获得了很高的准确性,还在实际应用中用于图像搜索、自动标注、智能相册等领域。
此外,深度学习还在物体检测方面有着卓越的表现,模型如Faster R-CNN、YOLO和SSD能够实时识别图像中的多个不同类别的物体,并提供它们的准确位置信息。这些技术在自动驾驶、安防监控、工业质检等领域有广泛的应用,提高了系统的智能性和效率。


深度学习已经改变了世界,未来将继续如此。我们鼓励读者深入研究和探索这一令人兴奋的领域,因为它在图像识别以及其他领域中仍然有着广阔的潜力。深度学习不仅是一种技术,更是一种推动科学进步的力量,我们期待看到它在未来的发展中取得更多突破和创新。
MMSegmentation框架
最后结尾这里再推荐大家一个神经网络的框架MMSegmentation
https://github.com/open-mmlab/mmsegmentation
- 主要特性
- 统一的基准平台
我们将各种各样的语义分割算法集成到了一个统一的工具箱,进行基准测试。 - 模块化设计
MMSegmentation 将分割框架解耦成不同的模块组件,通过组合不同的模块组件,用户可以便捷地构建自定义的分割模型。 - 丰富的即插即用的算法和模型
MMSegmentation 支持了众多主流的和最新的检测算法,例如 PSPNet,DeepLabV3,PSANet,DeepLabV3+ 等. - 速度快
训练速度比其他语义分割代码库更快或者相当。
OpenMMLab还有很多其他好用的工具箱,具体如下

深度学习是什么,能干什么
深度?学习?
为什么叫深度,怎么深的,是谁做的,因为什么
网络是如何加深的,块状结构
梯度收敛下山图
机器怎么学习,学习了什么,这种学习方式存在什么问题,有什么解决办法
分类与回归
过拟合泛化,大量数据
信息如何输入,学习,储存,输出
深度学习的起源;
起源 人脑
神经元 ->神经网络
发展 resnet
两大领域的基本块儿有什么区别
几个任务;每一种任务的经典模型
卷积神经网络是什么,为什么要用到。
自己构建一个卷积核
用边缘检测举个例子,来解释卷积层是如何起作用的
网络编码-解码结构,反卷积
每个任务是怎么使用的分类与回归
火出圈啦🔥大批人才涌入
人工智能兴起 阿尔法狗(强化学习)
异军突起:transformer
巅峰
现在的网络是如何发展的,改进在哪
网络块儿不同的层
层串联,并联

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









