







人工智能包含机器学习和深度学习,深度学习是实现人工智能的一个工具或者技术手段。深度学习热度趋势可以看出它真的很热门


1.深度学习的起源和发展
“深度学习(Deep Learning)”是2006年由多伦多大学(University of Toronto)的Geoffrey Hinton教授与他的同事们提出的,他也因此被称为“深度学习之父”。深度学习与人工神经网络(Artificial Neural Network,ANN)关系密切,因此深度学习的起源可以追溯到更早的时间。
分为三个阶段。第一阶段(1943-1969),第二阶段(1980-1989),第三阶段(2006- 如今)

1.1 第一阶段(1943-1969)
1943年:Warren McCulloch和Walter Pitts提出了MP神经元模型,模拟人类神经元
1957年:Frank Rosenblatt提出由两层神经元组成的感知机 (Perceptron)
1960年:Bernard Widrow和Ted Hoff提出了ADLINE神经网络
1969年:Marvin Minsky和Seymour Papert指出感知器只能做简单的线性分类任务,无法解决异或操作(XOR)这种简单分类问题,导致人工神经网络的研究陷入低谷
1.2 第二阶段(1980-1989)
1982年:John Hopfield提出了Hopfield神经网络,有连续型和离散 型两种类型,分别用于优化计算和联想记忆。
1984年:Kunihiko Fukushima(福岛邦彦)提出了模拟生物视觉传导通路的神经认知机,被认为是卷积神经网络的原始模型。
1986年:David Rumelhart、Geoffrey Hinton和Ronald Williams重新独立提出了误差反向传播算法(Error Back Propagation, BP),并指出多层感知机可以解决异或操作(XOR)这样的线性不可分问题。
1986年与1990年,分别出现了Jordan Network与Elman Network两种循环神经网络(Recurrent Neural Networks,RNN)。
1995年:Corinna Cortes和Vladimir Vapnik提出了支持向量机 (Support Vector Machine,SVM),除了其简单的训练方法与优越的性能超过了人工神经网络之外,其良好的可解释性,公式推导的优美,使得人工神经网络(黑盒子,解释性困难)研究再次进入低谷期。
1997年:Jurgen Schmidhuber和Sepp Hochreiter提出了长短期记忆网络(Long-Short Term Memory,LSTM),极大地提高了循环神经网络的效率和实用性。
1998年:Yann LeCun提出了称作LeNet-5的卷积神经网络(Convolutional Neural Networks ,CNN),率先将人工神经网络 应用于图像识别任务。
1.3 第三阶段(2006-现在)

2006年:Geoffrey Hinton和他的同事们提出了一种称作深度信念网络(Deep Belief Networks,DBN)的多层网络并进行了有效的训练,同时提出了一种通过多层神经网络进行数据降维的方法,正式提出了深度学习的概念。
2012年:Alex Krizhevsky在CNN中引入ReLU激活函数,在图像识别基准测试中获得压倒性优势,深度学习在2012年之后在业界引起了巨大的反响。
2012年:Frank Seide等人使用深度神经网络进行语音识别, 相比于传统的GMM和HMM,识别错误率下降了20%-30%, 取得了突破性的进展。
2012年:Alex Krizhevsky等人提出了AlexNet,它引入了ReLU激活函 数 ,并使用GPU加速 。 在著名的 ImageNet图像识别大赛中,AlexNet使得图像识别错误率从 26%下降到了15%,并夺得2012年的冠军。在随后几年的ImageNet图像识别大赛中,又出现了一些经典的卷积神经网络,如VGGNet、GoogleNet、ResNet、SENet等,图像识别错误率继续下降。
2014年起:R-CNN、Fast R-CNN、Faster R-CNN等一系列 目标检测模型的提出,极大地提升了目标检测的精度,但是它们一般要经过特征提取、分类/回归两个阶段才能完成, 模型训练效率较低
2014年:生成对抗网络(GAN)由当时还在蒙特利尔大学读博士的Ian J. Goodfellow提出,由于它无需标注大量的数据即可进行训练,在学术界迅速掀起了研究热潮。GAN在图像生成、 图像转换、图像迁移、图像修复等领域都有很好的应用。
2016年:YOLO目标检测模型被提出,由于它是一个端到端的模型,大大提高了模型训练与推理效率,但模型的精度不如R-CNN系列高,之后YOLO的后续版本陆续被推出, 目前已经到了第八版
2017年:SENet的图像识别错误率已经下降到了2.25%,由 于错误率已经到了极限,这也导致ImageNet图像识别大赛从2018年开始不再举办。
在自然语言处理领域,LSTM、门限循环单元(Gated Recurrent Unit,GRU)等循环神经网络在语言模型、机器翻译等任务上也取得了很大的进展
特别是随着Transformer的出现,使BERT、GPT等预训练大模型进入人们的视野,这些大模型在自然语言处理领 域多个任务上都超越了已有方法
2022年以来:ChatGPT、GPT4.0的相继问世更是使得大型 通用语言模型达到了前所未有的高度,被誉为信息技术领 域里程碑式的突破
2023年:百度公司在国内也率先推出了大型通用语言模型文心一言,之后清华大学、复旦大学、华为公司、阿里公司、科大讯飞也都发布了自己的大模型,开启了大型中文语言模型的新时代。
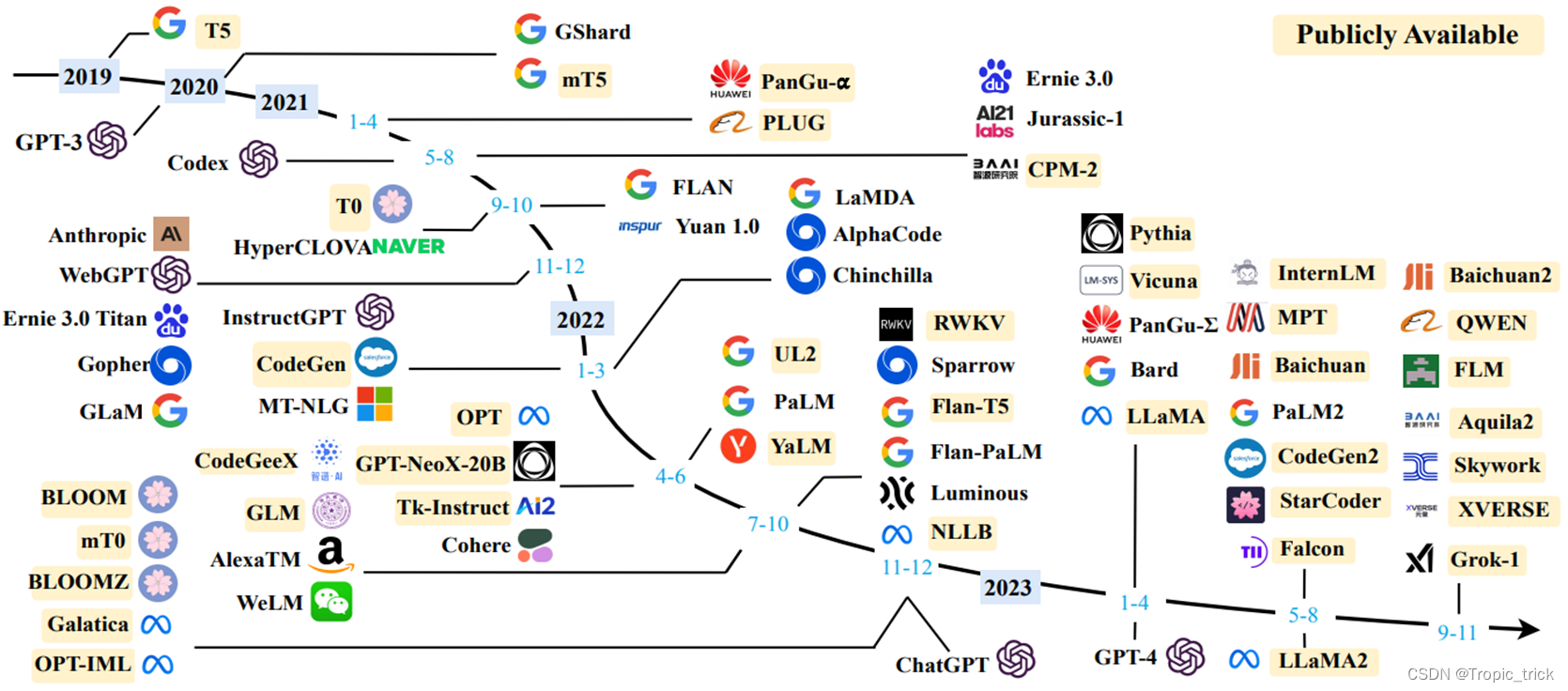
Zhao, Wayne Xin, et al. "A survey of large language models." arXiv preprint arXiv:2303.18223 (2023).
当前,深度学习仍然是人工智能领域关注度最高的主题之 一 ,研究如火如荼,应用五花八门
在研究方面:基于AI的内容生成、多模态数据分析、深度 强化学习等工作正在火热进行
在应用方面:深度学习已经在安防、医疗、金融、智能制 造、无人驾驶等多个领域取得了显著的成果
2.深度学习与机器学习、AI的关系

2.1 人工智能基本概念
人工智能定义:
最早在1956年的美国达特茅斯会议( Dartmouth Conference)上提出,当时会议的主题是“用机器来模仿人类学习以及其它方面的智能” 。因此,1956年被认为是人工智能的元年。 一般认为,人工智能是研究、开发用于模拟、延伸和扩展人的智能 的理论、方法、技术及应用系统的一门新兴学科。
“人工智能,是利用数字计算机或者数字计算机控制的机器模拟、延伸 和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理 论、方法、技术及应用系统。”---- 全国信息安全标准化技术委员会

分类:
强人工智能:认为有可能制造出真正能推理和解决问题的智能机器, 这样的机器被认为是有自主意识的
弱人工智能:认为不可能制造出能真正进行推理和解决问题的智能机器,这些机器只不过看起来像是智能的,但是并不真正拥有智能,也不会有自主意识
超级人工智能:机器的智能彻底超过了人类,你觉得什么时候到来?会有赛博朋克2077里的那般景象吗?
马斯克说过:碳基生物是硅基生物的垫脚石。

2.2 机器学习基本概念
机器学习定义:
让计算机具有像人一样的学习和思考能力的技术的总称。具体来说 是从已知数据中获得规律,并利用规律对未知数据进行预测的技术。一个简单的例子,利用机器学习算法对往年的天气预报数据进行学 习,就能够预测未来的天气预报数据。
机器学习分类:
1.监督学习(跟学师评):有老师(环境)的情况下,学生(计算 机)从老师(环境)那里获得对错指示、最终答案的学习方法。包 含线性回归、多项式回归、决策树和随机森林等回归算法,以及 KNN、逻辑回归、贝叶斯和支持向量机等分类算法。
2.无监督学习(自学标评):没有老师(环境)的情况下,学生(计 算机)自学的过程,一般使用一些既定标准进行评价,或无评价。 包含K-Means聚类、主成分分析、关联分析和密度估计等算法。
3.弱监督学习:仅有少量环境提示(教师反馈)或者少量数据(试题 )标签(答案)的情况下,机器(学生)不断进行学习的方法。包 含强化学习、半监督学习和多示例学习等算法

3.深度学习的基本概念与典型算法
深度学习是指通过构建多层神经网络结构来学习数据的特征,以便 于进行数据分类、回归与生成。深度学习与浅层学习相比,神经网络结构的层数更多(一般大于或等于4层),通过多层神经网络结构可以学习得到更丰富的数据特征。
浅层前馈神经网络和深度前馈神经网络:

有监督学习的浅层学习算法:决策树、支持向量机、感知机和Boosting等。
无监督学习的浅层学习算法:自编码器、受限玻尔兹曼机、 高斯混合模型和稀疏自编码器等
有监督学习的深度学习算法:深度前馈神经网络、卷积神经网络、循环神经网络、Transformer、胶囊网络和深度森林等。
无监督学习的深度学习算法:深度自编码器、生成对抗网络、深度玻尔兹曼机和深度信念网络等。

4.深度学习的主要应用
4.1 图像处理领域主要应用
图像分类(物体识别):整幅图像的分类或识别
物体检测:检测图像中物体的位置进而识别物体
图像分割:对图像中的特定物体按边缘进行分割
图像回归:预测图像中物体组成部分的坐标

4.2 计算机视觉领域主要应用
人脸识别:首先通过目标检测提取人的正脸,然后通过人脸识别人 员身份。
行人重识别:检测视频序列中的行人,并识别特定人员的身份。
目标跟踪:在连续的视频帧中定位某一行人或者其他运动目标。
动作识别:识别视频中人体的动作/行为
产品缺陷检测:检测工业产品存在的缺陷
4.3 语音识别领域主要应用
语音识别:将语音识别为文字
声纹识别:识别是哪个人的声音
语音合成:根据文字合成特定人的语音
4.4 自然语言处理领域主要应用
语言模型:根据之前词预测下一个单词。
情感分析:分析文本体现的情感(正负向、正负中或多态度类型)。
神经机器翻译:基于统计语言模型的多语种互译。
神经自动摘要:根据文本自动生成摘要。
机器阅读理解:通过阅读文本回答问题、完成选择题或完型填空。
自然语言推理:根据一句话(前提)推理出另一句话(结论)。
4.5 综合应用(多模态)
图像描述:根据图像给出图像的描述句子
可视问答:根据图像或视频回答问题
图像生成:根据文本描述生成图像
视频生成:根据故事自动生成视频















 29
29











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









