






项目概述
本文将带你一步步实现一个基于PySpark Streaming的实时单词计数应用。这个应用能够监听网络端口,实时统计输入文本中的单词出现频率。
环境准备
首先,我们需要创建一个专门的工作目录
核心代码解析
我们的核心代码NetworkWordCount.py如下:
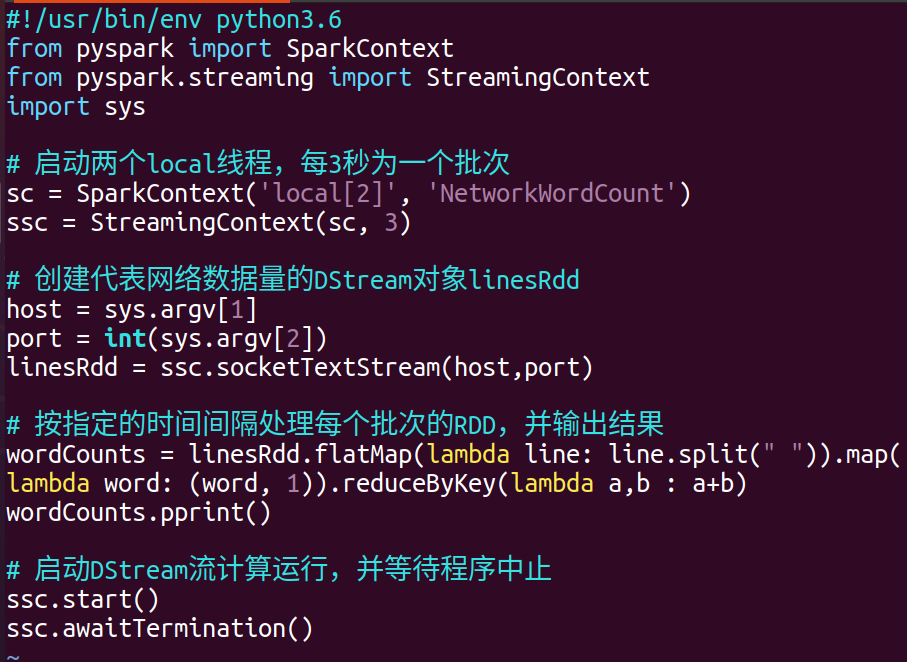
代码解析:
-
创建SparkContext,使用2个本地线程
-
创建StreamingContext,设置批处理间隔为3秒
-
通过socketTextStream创建DStream,监听指定主机和端口
-
对每行文本进行单词分割、映射和计数
-
使用pprint()打印结果
-
启动流计算并等待终止
运行应用
1. 启动Spark Streaming应用

2. 使用netcat发送数据
打开另一个终端,启动netcat服务器然后,输入一些测试文本: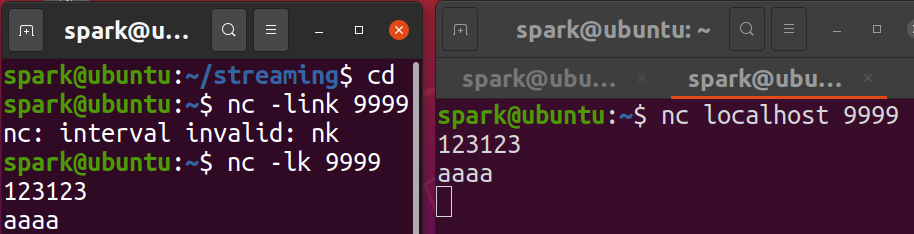
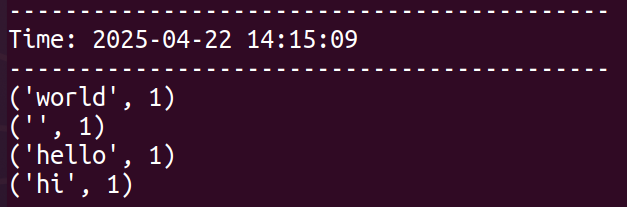
3. 查看结果
在Spark Streaming应用的输出中,你将看到类似以下结果:
常见问题解决
-
日志信息过多:可以通过
sc.setLogLevel("WARN")设置日志级别,只显示警告及以上级别的日志。 -
netcat命令错误:注意正确的命令是
nc -lk 9999,不是nc -link 9999。 -
端口占用:确保9999端口没有被其他应用占用。
总结
通过这个简单的示例,我们实现了:
-
使用PySpark Streaming处理实时数据流
-
通过socket接收实时文本数据
-
对文本进行单词计数
-
每3秒输出一次统计结果
这个基础框架可以扩展为更复杂的实时处理应用,如实时日志分析、实时推荐系统等。希望这篇教程对你入门Spark Streaming有所帮助!

















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









