







对目标网站进行分析
- 数据隐藏在网页的哪一部分
- 爬虫怎么和网站进行交互
几种分析方式
查看网页源代码(右键即可查看)
- 标题、URL等信息
右键+检查
查看
Elements
- 浏览器真正的源码(已经加载过一部分的JS)
- 定位网页界面上的位置
Network
- (类似抓包)显示网页加载时间、加载了哪些东西
- 通常要点上Disabled cache——防止从本机上下载数据

- 点击Name中的目标网站,再点击Headers可以查看网页请求方法
- 还需注意Cookies和User-Agent(下拉,Headers里面都有)
有些网站爬虫失败就是因为没有带User-Agent,可以自己设置一个User-Agent伪装爬虫
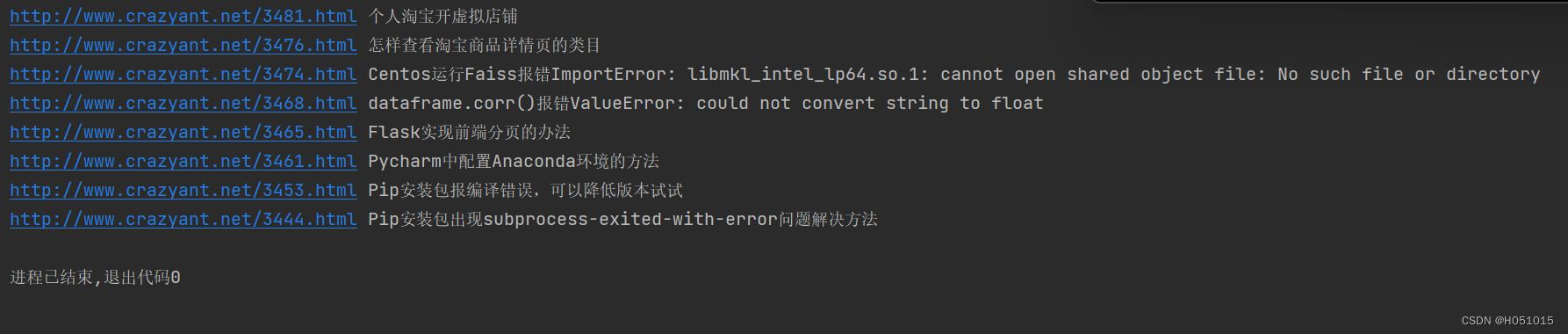
实例——提取页面中所有的标题、链接和文本
import requests
from bs4 import BeautifulSoup
url ="http://www.crazyant.net"
r= requests.get(url)
if r.status_code != 200:
raise Exception()
html_doc = r.text
soup=BeautifulSoup(html_doc,"html.parser")
# 只取出标签为h2的URL
h2_nodes = soup.find_all("h2",class_="entry-title")
for h2_node in h2_nodes:
link = h2_node.find("a")
print(link["href"],link.get_text())运行结果
两个知识点
#知识点1
import requests
#在访问网站时在Network中查看到的数据
cookies = {
"captchaKey" : "14a54079a1",
"captchaExpire":"1548852352"
}
r=requests.get(
"http://url",
cookies=cookies
)
#知识点2
#re即正则表达式
import re
url1 = "http://www.crazyant.net/123.html"
url2 = "http://www.crazyant.net/123.html#comments"
url3 = "http://www.baidu.com"
# d代表数字,d+代表很多个数字 所以下式将url1表示出来了
# ^和$保证了pattern只和url1匹配不和url2匹配
# re具体语法解析可以上网查阅
pattern = r'^http://www.crazyant.net/\d+.html$'
print(re.match(pattern, url1)) # ok
print(re.match(pattern,url2)) # None
print(re.match(pattern,url3)) # None实战1——爬取博客网站全部文章列表
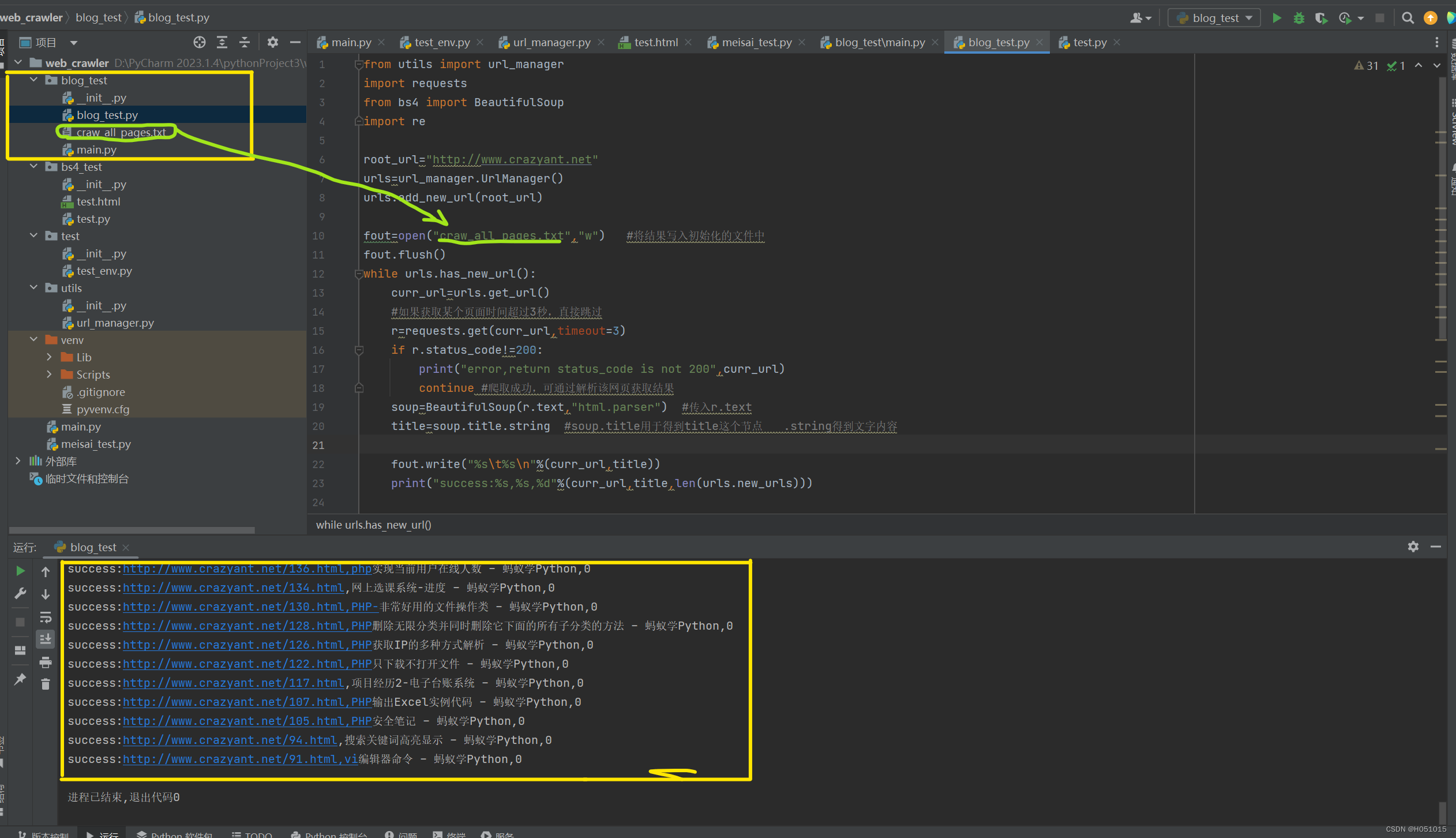
因为是爬取整个页面的URL,需要先将新的或者所有URL添加到URL管理器中,再进行爬取
from utils import url_manager
import requests
from bs4 import BeautifulSoup
import re
root_url="http://www.crazyant.net"
urls=url_manager.UrlManager()
urls.add_new_url(root_url)
fout=open("craw_all_pages.txt","w") #将结果写入初始化的文件中
fout.flush()
while urls.has_new_url():
curr_url=urls.get_url()
#如果获取某个页面时间超过3秒,直接跳过
r=requests.get(curr_url,timeout=3)
if r.status_code!=200:
print("error,return status_code is not 200",curr_url)
continue #爬取成功,可通过解析该网页获取结果
soup=BeautifulSoup(r.text,"html.parser") #传入r.text
title=soup.title.string #soup.title用于得到title这个节点 .string得到文字内容
fout.write("%s\t%s\n"%(curr_url,title))
print("success:%s,%s,%d"%(curr_url,title,len(urls.new_urls)))
links=soup.find_all("a")
for link in links:
#有些URL需要cookies,可能爬取不到href,所以判断href是否为None
href=link.get("href")
if href is None:
continue
pattern = r'^http://www.crazyant.net/\d+.html$'
if re.match(pattern,href):
urls.add_new_url(href)
fout.close() #关闭文件运行结果(文件中包含所有爬取到的链接与文字)
实战2——爬取豆瓣高分电影并存入excel
爬取十个页面的数据
并且爬取每一个的电影信息和排名(用Elements查看对应标签位置)

实战3——爬取西安天气数据
from utils import url_manager
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
# 通过抓包找到你需要的信息之后
# 检查 里面 标头 请求URL 中?前的内容
url = "http://tianqi.2345.com/Pc/GetHistory"
# 检查 里面 负载 的内容直接复制转为以下形式即可
headers = {
"User_Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"
}
def craw_table(year, month):
"""提供年份和月份爬取数据"""
params = {
"areaInfo[areaId]": 57036,
"areaInfo[areaType]": 2,
"date[year]": year,
"date[month]": month
}
# get是因为 标头 请求方式 为GET
resp = requests.get(url, headers=headers, params=params)
# print(resp.status_code) #为200则返回成功
# print(resp.text) #得到网页,data中即为真正的数据
data = resp.json()["data"] # json本身类似于字典,然后我只取其中data部分的内容 其实没懂为什么是json
# print(data) #展示内容 表格用pandas提取,内容可用bs4
df = pd.read_html(data)[0] # 解析网页中所有的表格 df即data frame
return df
"""测试代码是否成功"""
# df=craw_table(2024,1)
# print(df.head()) #输出表格的前几行
# 出现问题 ImportError: lxml not found, please install it 安装lxml库即可
df_list = []
for year in range(2011, 2024):
for month in range(1, 13):
print("爬取:", year, month) # 监督进程,方便查找错误
df = craw_table(year, month)
df_list.append(df)
pd.concat(df_list).to_excel("西安天气数据.xlsx", index=False) # 保存数据
P.S.作者时间实在是不够了,而且发现后面的爬取代码确实更难以简单理解,所以目前爬虫就到这里结束力,打完比赛作者还会继续学,大家可以先看着这篇简单的,辛苦啦!















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









