






Aximof| 编辑
科普博文| 分类
AI 时代的数据变革
向量数据库在构建基于大语言模型的行业智能应用中扮演着重要角色。大模型虽然能回答一般性问题,但在垂直领域服务中,其知识深度、准确度和时效性有限。为了解决这一问题,企业可以利用向量数据库结合大模型和自有知识资产,构建垂直领域的智能服务。向量数据库存储和处理向量数据,提供高效的相似度搜索和检索功能。通过向量嵌入,将企业知识库文档和数据转化为向量表示,并与大模型进行交互,实现专有、私域的垂直的行业智能化应用。
- 80% 的数据为非结构化数据
- 非结构化数据+LLM(人工智能算法)
何为向量数据库?
在明白向量数据库之前,首先理解传统的关系型数据库;
关系型数据库
关系型数据库是一种以表格形式存储数据的数据库,它使用结构化查询语言(SQL)来管理和查询数据。关系型数据库的数据以行和列的形式组织,每个表格代表一个实体或关系,而每一行则代表该实体的一个实例,每一列则代表该实体的一个属性。
举个例子,一个关系型数据库可以包含一个名为“顾客”的表格,其中包含顾客的ID、姓名、地址和电话号码等属性。另外一个名为“订单”的表格可以包含订单的ID、日期、顾客ID等属性。这两个表格可以通过顾客ID建立关联,从而实现顾客和订单之间的关系。
关系型数据库的优点包括数据结构清晰、数据一致性好、支持复杂的查询和事务处理等。然而,它也有一些局限性,比如不太适合存储非结构化数据和处理大规模数据等。
向量数据库
向量;在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。两个向量的距离或者相似性可以通过欧式距离、余弦距离等得到,这就是向量数据库运行的基本数学原理。
向量数据就是根据事物的各项特征进行向量化而来;例如我们想要在数据世界区别梅西和C罗,就可以从具体的特征出发比如身高、发色、鼻梁高低、眼睛大小、声音响度高低等等方面,赋予他们向量,就能发现两个人的区别。
而这种向量当赋予全球80多亿人时就会发现,每个人都不尽相同,而且给予向量的特征角度越多,那么数据就会越准确。这从数学理论方面建立了每个人的模型,利用这个模型,我们就能在二进制世界中建立另一个现实世界,这样我们就可以将一本小说、一首音乐、一段视频、一张照片数据化,这就是向量数据。
向量数据库是一种新兴的数据库类型,它以向量(或向量化数据)作为基本的数据存储单元,适用于存储和处理大规模的高维度数据。向量数据库通常用于机器学习、数据挖掘、推荐系统等领域,因为它们能够高效地处理复杂的数据查询和分析。
举个实际的例子,假设一个电商平台的向量数据库中存储了用户的购买历史、浏览行为、喜好标签等信息。当用户浏览某个商品时,系统可以通过向量数据库快速找到与该用户具有相似购买历史和喜好标签的其他用户,从而向该用户推荐相关商品。
向量数据库的优点包括高效的相似性查询、支持高维度数据、适用于大规模数据等。
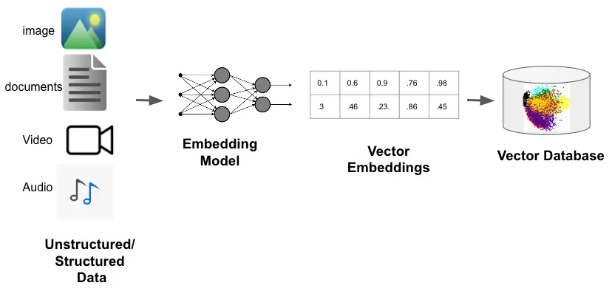
数据结构化向量化过程
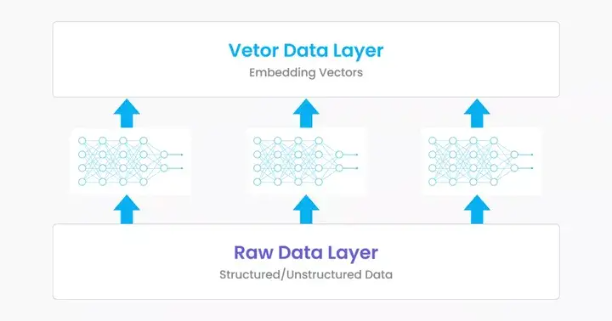
神经网络+Embedding ; 两层:原始数据层 & 向量层;
通过神经网络(Embedding模型),可以有效地将非结构化数据中的信息编码成向量
向量数据据的性质
- Embedding 向量是一种抽象的数据类型,针对抽象的数据类型可以构建统一的代数系统,从而避免非结构化数据丰富的形态所带来的复杂性;
- Embedding 向量的物理表示是一种稠密的浮点数向量,这有助于利用现代处理器的 SIMD 能力提升数据分析速度,降低平均算力成本;
- Embedding 向量这种信息编码形式,通常比原始的非结构化数据要小得多,占用存储空间更低,并能提供更高的信息传输效率。
- Embedding 向量也有与其对应的算子系统,最常用的算子是语义近似匹配。
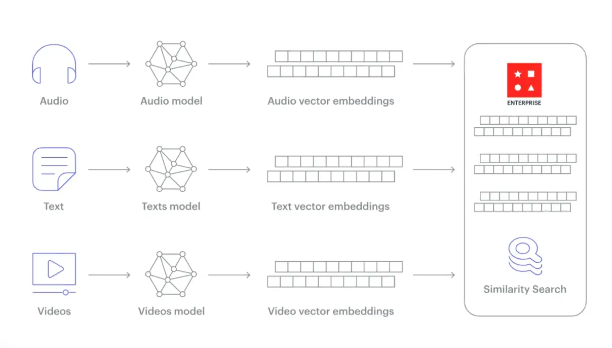
下图给出了一个跨模态语义近似匹配的例子。需要注意的是,图中给出的是匹配的结果。在具体运算过程中,文字和图片都会被映射到同一个 Embedding Space,在这个空间内进行向量化的语义近似分析;

语义上的加法操作:

向量数据库的主要特性
首先解决的是向量存储、检索和分析的问题;其次,作为一个数据库,需要提供标准的访问接口和数据插入查询删除更新的能力。
除此之外:
- 高效支持向量算子
- 向量索引能力
- 相比传统数据库基于 B 树、LSM 树等结构索引,高维向量索引往往计算量更大,属于计算密集型场景。在索引算法层面,多采用聚类、图等技术。运算层面,以矩阵运算、向量为主。因此,充分挖掘现代处理器的向量加速能力,对于降低向量数据库的算力成本至关重要。
- 跨部署环境的一致使用体验
- 支持混合查询
- 云原生
向量数据库的应用场景
推荐系统;电商、病毒代码检测、数据去重、生物特征验证、化学分子式分析、金融、保险等。
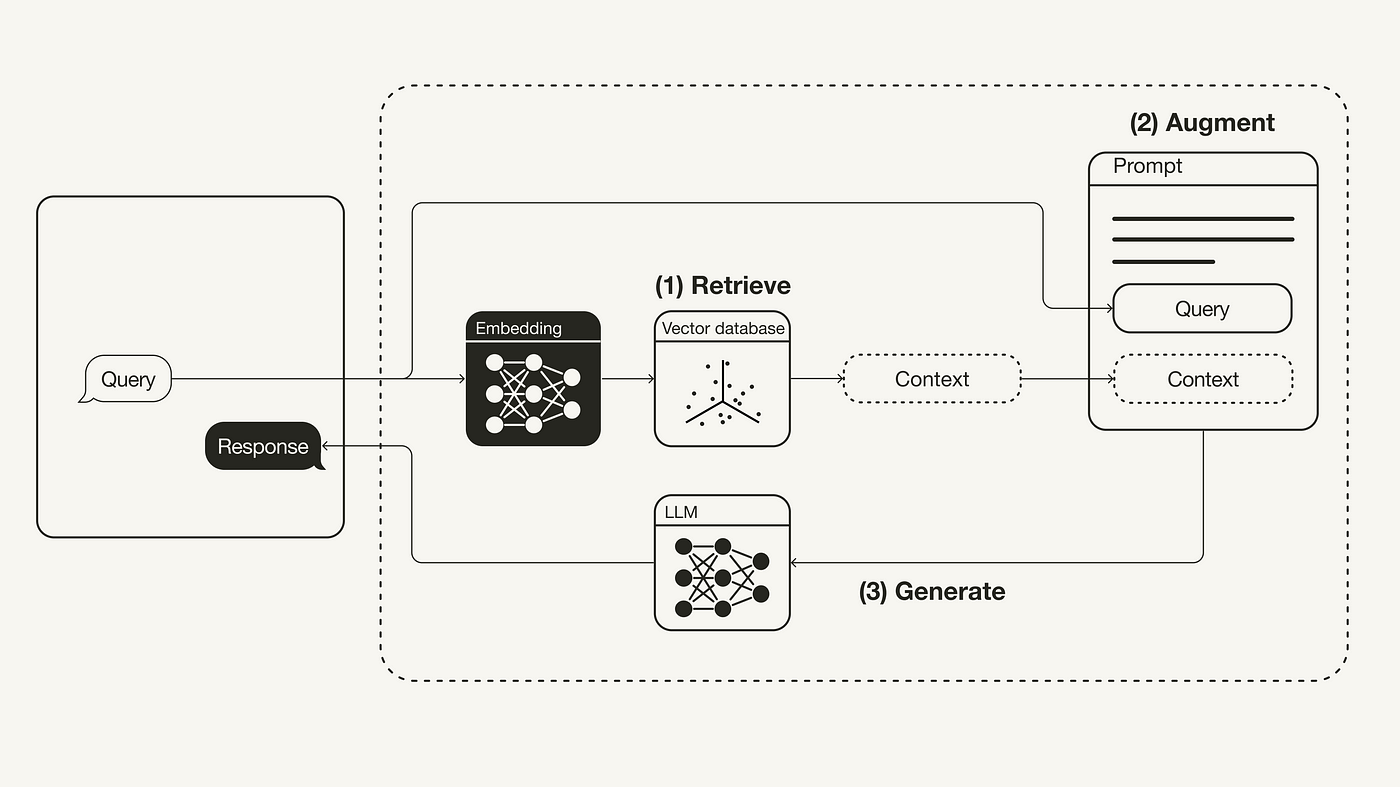
更重要的是,因为向量数据库让大模型(LLM)有了"记忆"的功能。在今年3月23日,OpenAI 在其发布的 chatgpt-retrieval-plugin项目中推荐使用一个向量数据库,在写 ChatGPT 插件时为其添加“长期记忆”能力。之后对于向量数据库项目的关注度都从那个时间节点开始再次起飞了。而且在现在最火热的大模型应用**检索增强生成(RAG,Retrieval Augmented Generation)**中发挥了重要的作用。

本文由mdnice多平台发布















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









