









THOUGHT PROPAGATION: AN ANALOGICAL APPROACH TO COMPLEX REASONING WITH LARGE LANGUAGE MODELS
前言
一篇来自中科院自动化所和耶鲁大学的文章,将prompt方法又卷到一个新的高度,文章提出的思维传播已经从一种方法上升到思想的境界,在任何需要使用LLM进行复杂推理任务的场景都能够大放异彩,是一篇特别fancy的文章。
| Paper | https://arxiv.org/pdf/2310.03965.pdf |
|---|---|
| Code | 无 |
| From | arXiv |
ABSTRACT
随着prompt技术的发展,大模型在推理任务上取得显著成功。然而现有的prompt方法无法重用解决相似问题的思路,并且在推理过程中会累积错误。为了解决这个问题,作者提出了思维传播(TP),它可以利用相似问题的解决方案来增强LLMs的复杂推理能力。具体来说,FP首先提示LLMs提出一系列和输入问题相关的类似问题并解决,接着TP重用类似问题的答案直接产生新的解决方案。TP兼容现有的prompt方法,即插即用,在三项具有挑战的任务的实验表明,TP在最短路径推理、创意写作、智能体任务完成方面有着显著的提升。
1 INTRODUCTION
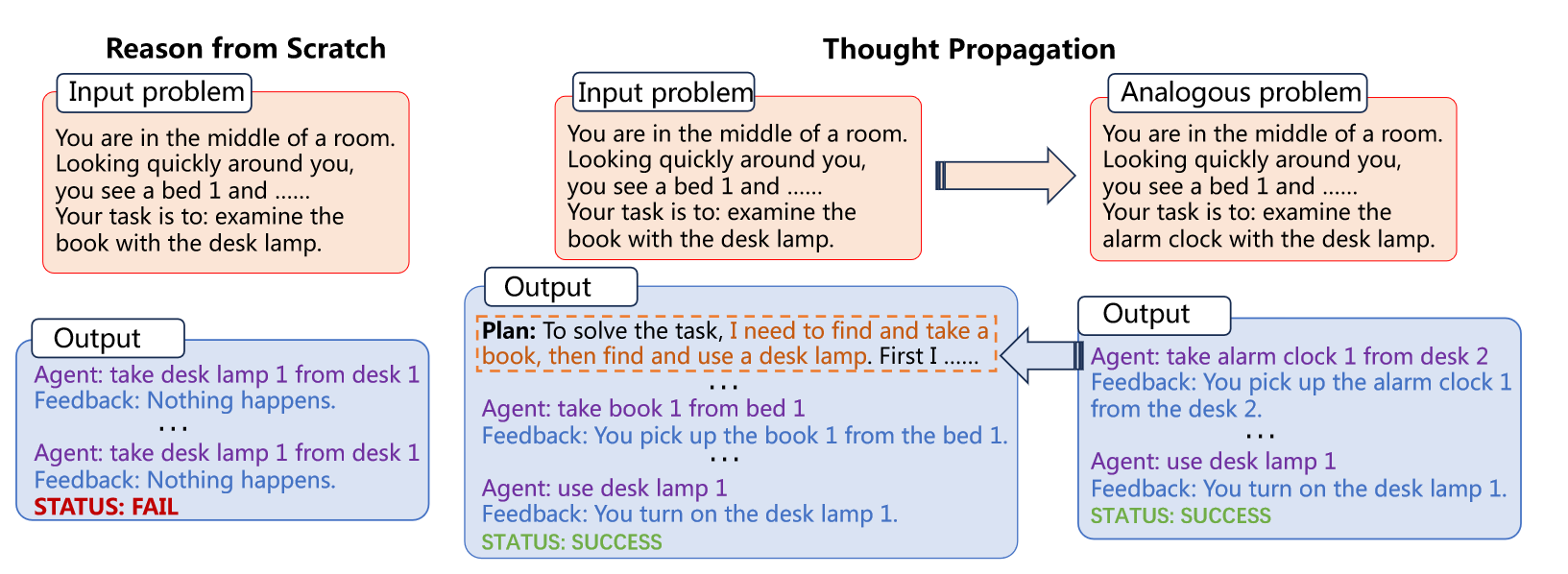
越来越大规模的LLMs利用最新的prompt技术在逻辑、算数和常识推理问题上取得显著的提升。早期工作只是通过小样本输入输出进行简单的推理,最近的方法将复杂的推理过程分解为中间推理步骤。虽然这些方法都在努力提升LLMs的复杂推理能力,但是却有着两点问题:
- 从头开始的推理无法重用解决类似问题的见解。
- 当面临多步骤推理时,从头开始推理对中间阶段错误很敏感。
但是人类具有类比推理的能力,这个类比强调了实体关系以A之于B就像C之于D的形式。基于这些类比的知识,人类就像站在巨人的肩膀上一样。而LLMs目前正缺少利用问题之间的类比提升推理性能的探索。因此本文作者改进传统的推理思路,提出思维传播框架,用于修正现有的从头开始推理的方法,增强LLMs的复杂推理能力。对于一个给定的问题,TP首先提示LLMs生成一系列和原始问题类似的问题,接着采用CoT的方式解决类比的问题。聚合模块进一步聚合这些类似问题的解决方案,具体来说,第一步重用类别问题的解决方案生成输入问题的新解决方案,第二步将输入问题和类比问题进行比较,并根据类似问题的结果制定高级计划。最后,LLMs执行这些计划,以在解决输入问题时纠正其中间推理步骤。TP与现有Prompt方法兼容,即插即用,减少了特定任务工程中的密集劳动。
作者在三个任务上测试了所提出的方法,包括最短路径推理、创意写作和LLM智能体计划。这些任务需要搜索图结构数据,开放式写作和长期实验规划,这对LLM带来了挑战。而TP可以泛化到不同的推理任务上,并具有优越的性能。
2 RELATED WORK
2.1 Graph Neural Network
图神经网络通过聚合邻域节点信息获得当前节点的embedding。最近的工作将参数化GNN和LLM结合起来,用于图相关的任务,例如图可解释性、分类和问答。不同的是,本文工作的目的是无需微调就能够提升LLM的推理能力。
2.2 Analogical Reasoning
类比推理已经在视觉推理、自然语言推理、知识图谱推理中应用,这些方法用于训练神经网络执行实体之间的关系推理。最近也有工作利用知识图谱帮助LLMs进行类比生成和推理,但是它们需要借助外部知识库来存储实体关系进行类比推理,这对于一般任务来说成本高昂。因此,针对一般任务的LLM复杂推理的通用类比方法处于缺失。
2.3 Prompt-based Large Language Model Reasoning
大语言模型基于提示的方法在许多任务中都取得了成功,早先的方法在输入问题上附上成对的问题及其解决方案,最近的方法将复杂的推理过程分解为中间推理步骤。但是这些方法都无法重用解决类似问题的见解。此外,这些方法还受到中间步骤累计错误的困扰。
2.4 LLM as Autonomous Agents
LLM智能体可以和工具、其它语言模型或者人类进行交互自动做出决策并制定计划通过反馈解决任务。当部署在长期实验决策和规划场景时,LLM需要经过多轮的行动和规划,由于LLM会产生幻觉,因此智能体会累计错误,导致任务无法完成。但是本文的TP方法可以总结完成类似任务的经验并提高任务的完成度。
2.5 More Discussion with Retrieval-augmented LLMs
基于检索增强的LLM可以减少幻觉,提高LLM的输出质量。对于输入问题,检索增强的LLM首先查询具有十亿级token的外部数据库,获得语料库的子集构建答案。相比下,本文提出的方法不需要从外部数据库获取知识,而是聚合解决类似问题的知识提示推理过程。
3 PRELIMINARIES
将推理和解决方案表示为
p
∈
P
\mathbf{p} \in \mathcal{P}
p∈P和
s
∈
S
\mathbf{s} \in \mathcal{S}
s∈S,
P
\mathcal{P}
P和
S
\mathcal{S}
S分别表示推理和解决方案的空间。LLM表示为
f
θ
f_{\theta}
fθ。
IO Prompting
IO Prompting使用任务描述和few-shot输入输出对的demonstration辅助LLMs推理解决问题
s
=
f
θ
(
p
)
\mathbf{s} = f_{\theta}(\mathbf{p})
s=fθ(p),如上图(a)所示,推理路径只有一步,但是这不足以解决涉及多步推理的复杂问题。
Chain-of-Thought Prompting
CoT提示将问题的推理路径分解为多步从而让LLMs拥有复杂推理能力,如图(b)所示。CoT采用few-shot的prompt来提示LLM生成带有中间步骤的推理结果。该过程可以表示为:
z
i
=
f
θ
(
p
;
{
z
j
∣
j
<
i
}
)
\mathbf{z}_i = f_{\theta}(\mathbf{p};\{\mathbf{z}_j|j < i\})
zi=fθ(p;{zj∣j<i}),其中
z
i
\mathbf{z}_i
zi是中间推理步骤。
Tree-of-Thought Prompting
ToT提示将LLM推理制定成利用启发式方法(BFS或DFS)在解决空间中进行搜索,当到达第i步的子方案
z
i
\mathbf{z}_i
zi时,ToT让LLM提出子任务的候选,然后利用LLM评估最好的子方案,并选择它作为下一个子方案。重复上述过程得到ToT满意的解。
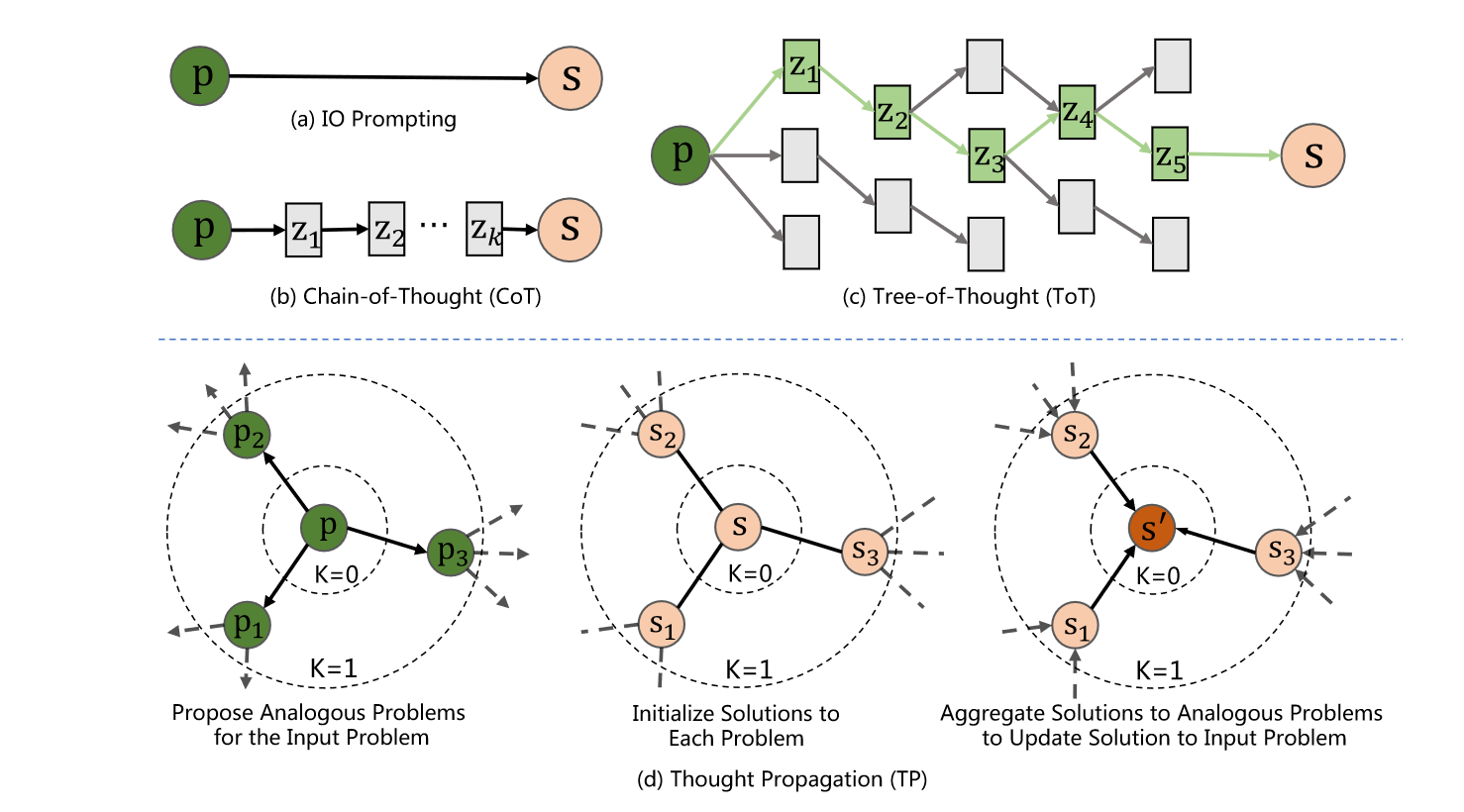
虽然上述的方法通过不同的prompt方式提升LLM的复杂推理能力,但是都是利用LLM从头开始推理,无法重用先验知识,并且会出现累积错误,因此它们在涉及优化和多步搜索的任务中表现不佳。如下图所示:

IO Prompting、CoT和ToT在寻找0到4的最短路径上都出现了错误,而这仅仅是很简单的图问题。
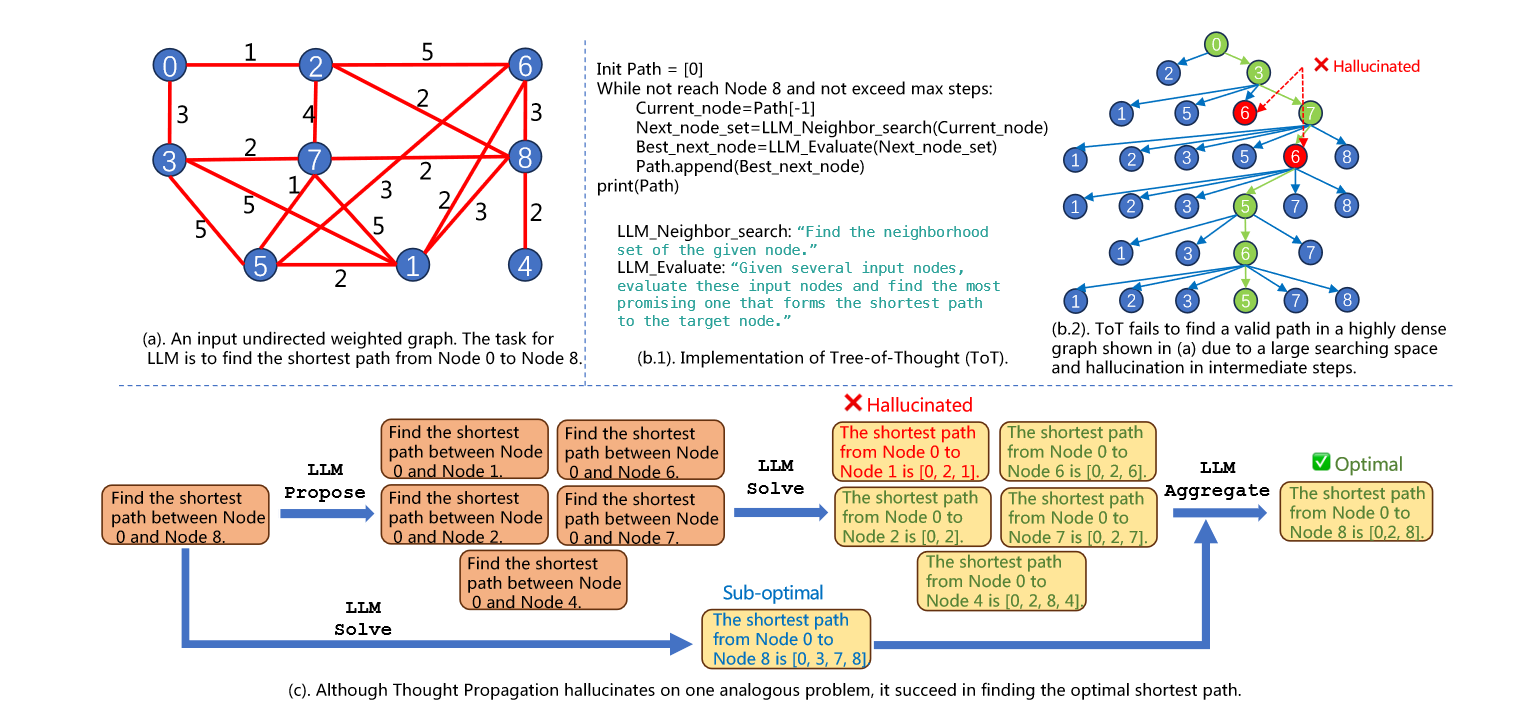
上图是TP和ToT在复杂最短路径任务上的示例,可以看到ToT由于幻觉出现了累积错误,而TP和多个类似任务进行了类比,这些类比任务是节点0到节点8相邻节点最短路径的任务。虽然类似任务中有出现幻觉的情况,但是大部分任务的解决步骤都是正确的,TP将类比方案和LLM solve进行聚合,最终得到了正确的结果。
4 METHODOLOGY
当人类遇到新问题的时候,通常会和具有相似特征的熟悉问题进行比较,这一过程称为类比推理。TP具有异曲同工之妙,它结合类似问题的解决方案,通过更新解决方案或者生成计划,从而无需借助外部知识库来解决问题。TP具有三个模块:LLM Propose、LLM Slove、LLM Aggregate。
LLM Propose
给定一个问题,LLM Propose会生成一组类似的问题。解决这些问题可以提供独特的见解帮助LLM解决输入的问题。类比问题主要从两个角度产生:
- 类似问题的解决方案可以启发生成输入问题的新的解决方案。
- 解决类比问题可以为输入问题生成高级的计划,帮助LLM纠错。
LLM Solve
该模块具有两个目的,一是生成原始的处理方案,二是解决类比问题。这些方案最终通过聚合帮助生成更好的答案。
LLM Aggregate
LLM Aggregate聚合了类似问题的解决方案,以增强对输入问题的解决。它利用类似问题的解决方案得到新的解决方案,同时提示LLM利用类似问题的解决方案导出高级计划来解决输入问题。
Multi-layer Implementation
如第三章开头图片(d)中所示,TP可以重复堆叠,利用K跳类似问题的解决方案来改进输入问题的解决方案。从这个角度出发,现有的IO、CoT、ToT方法都是TP中
K
=
0
K=0
K=0的特例。当
K
K
K的值设置为1时,TP可以从1跳聚合类似问题来改进输入问题的解决方案。在这种情况下,第i层的问题是第(i-1)层问题的类似问题,因此可以使用第i层的解决方案来细化第(i-1)层问题的解决方案。这种分层细化直达原始问题无法被细化为止。
General Setup and Recipe
TP即插即用,可以直接应用到现有的prompt方法上。本文实验中大部分任务都可以直接用IO提示或者CoT实现,但是涉及到自主规划和探索的复杂问题,需要TP这种协同思想和行为的方法,带来显著的性能提升。
Complexity Analysis
复杂性分析主要来自两个方面:
- 层数增加,复杂度呈指数级增加,因此作者将 K K K最多设置为2。
- 层数增加,5-shot的LLM Solve比0-shot的设置更昂贵。
5 EXPERIMENTS
实验部分在三个具有挑战的任务上进行,分别是最短路径推理,创意写作和LLM智能体计划,用于评估TP性能。最短路径推理采用作者构建的100个最短路径问题,创意写作数据集来自他人构建的100个写作任务,LLM智能体计划任务来自ALFWorld游戏实例化的134个环境,TP在这三个任务上都取得了最好的结果。
5.1 SHORTEST-PATH REASONING
最短路径推理任务是从带权无向图中找到从源节点到目标节点的最短路径。这是有挑战性的任务,因为:
- 图结构不遵循训练LLM的顺序语料。
- 这种离散优化问题需要在大空间中搜索。
| Baselines | IO,CoT,BaG,ToT |
|---|---|
| Settings | 0-shot,1-shot,5-shot |
| Models | PaLM2(Bison),GPT-3.5,GPT-4 |
Evalution Metrics
将图
G
i
G_i
Gi的最短路径表示为
L
i
∗
L_i^*
Li∗,LLM有效的输出路径为
L
i
L_i
Li。
N
N
N是图的总数。
N
o
p
t
i
m
a
l
N_{optimal}
Noptimal和
N
f
e
a
s
i
b
l
e
N_{feasible}
Nfeasible分别是LLM输出的最优路径和有效路径的数量。作者提出三个指标评估最短路径推理的性能。
O
p
t
i
m
a
l
R
a
t
e
(
O
R
)
=
N
o
p
t
i
m
a
l
/
N
\mathbf{Optimal\,\, Rate}(\mathbf{O R})=N_{optimal} / N
OptimalRate(OR)=Noptimal/N衡量LLM生成路径作为最优路径的百分比,越高越好。
F
e
a
s
i
b
R
a
t
e
(
F
R
)
=
N
f
e
a
s
i
b
l
e
/
N
\mathbf{Feasib\,\, Rate}(\mathbf{F R})=N_{feasible} / N
FeasibRate(FR)=Nfeasible/N衡量 LLM 生成的路径中有效路径的百分比。越高越好。
O
v
e
r
−
L
e
n
g
t
h
R
a
t
e
(
O
L
R
)
=
∑
i
=
1
N
f
e
a
s
i
b
l
e
(
L
i
−
L
i
∗
)
/
L
i
∗
\mathbf{Over-Length\,\, Rate}(\mathbf{OLR})=\sum^{N_{feasible}}_{i=1}(L_i-L_i^*)/L_i^*
Over−LengthRate(OLR)=∑i=1Nfeasible(Li−Li∗)/Li∗衡量 LLM 生成的有效路径相对于最佳路径的超长。越低越好。

结果如上表所示,TP通过生成最优且有效的最短路径,实现了比基线显著的性能增益。对于GPT-3.5和GPT-4,ToT的性能较差,作者发现ToT有时候会向后搜索,由于累积误差而找不到有效路径。CoT也是同样道理,性能甚至不如IO。
尽管大多数情况下1-shot比0-shot带来了显著的提升,但是5-shot设置下提升微乎其微。可以能有两点原因:
- 较长的prompt文本会包含冗余的信息。
- 5-shot由于过长有时候会出现输出中断。
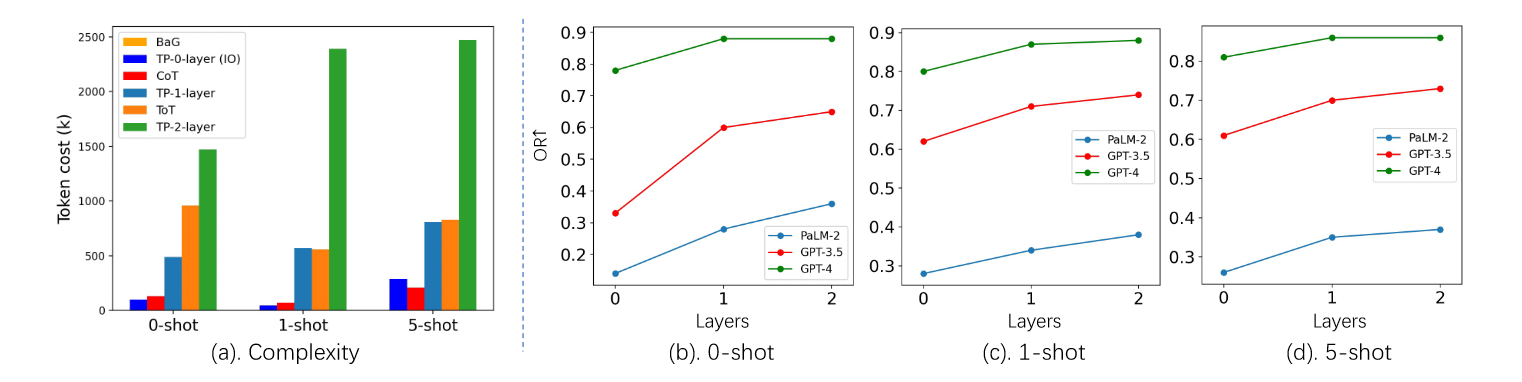
上图测试了TP在不同层数下的表现,可以看到1-layer TP已经取得了显著的性能提升。2-layer虽然达到了最优的性能,但是增益不显著,并且成本高昂。
5.2 CREATIVE WRITING
创意写作任务具体内容是给定四个随机的句子,目标是生成四段以该句子结尾的段落,这种任务需要高度的创造性思维和计划。作者采用GPT-4生成的连续评分和用户研究来评估生成的连续信息的创造性。
| Baselines | IO,CoT,ToT |
|---|---|
| Settings | 0-shot |
| Models | GPT-3.5,GPT-4 |
因为是零样本,LLM Propose使用简单的prompt来重新表述并生成四句输入:Rephrase the input sentences but do not change their meanings or orders.这样与baseline相比就有五个类似的问题,对于每个问题,LLM Solve使用CoT Prompting生成写作计划,从而编写四个段落。最后LLM Aggregate评估输出的所有计划,采用最有希望的计划来生成四个段落。
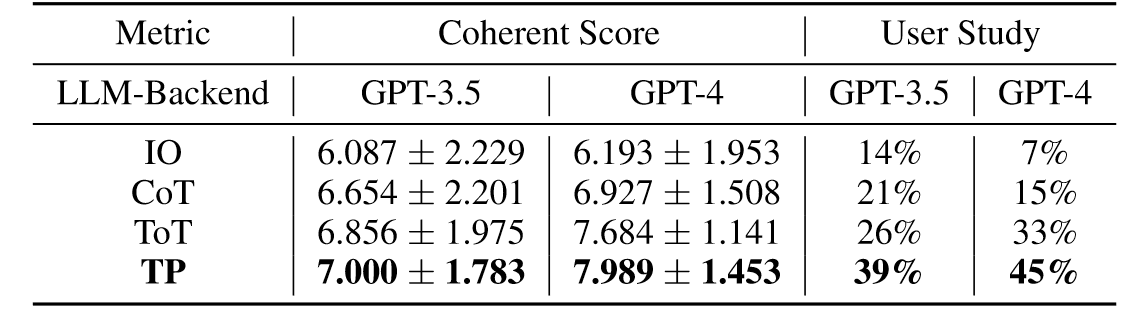
结果如上表所示,TP在两个backbone上的性能评分都是最高,并且获得了最高的用户偏好,并且由于模型能力的改进,所有方法在 GPT-4 上都取得了更好的性能。
5.3 LLM-AGENT PLANNING
LLM-Agents采用LLM作为与环境交互并自主制定计划和决策的核心组件。ALFWorld是一款基于文本的游戏平台,具有与ALFRED和TextWorld一致的各种交互式家居环境。它包含六种类型的任务和 134 个未见过的环境进行评估。
| Baselines | BULTER,ReAct,Act,Reflexion |
|---|---|
| Settings | 0-shot |
| Models | GPT-3 |
在该任务中,LLM Propose使用零样本prompt来评估原始任务与成功规划试验的其余任务之间的相似性得分。具有最高两个相似度得分的其余任务被视为两个类比问题。LLM Solve采用ReAct来实例化LLM-Agent的规划,LLM Aggregate采用零样本prompt,根据类比问题的成功实验以及原始问题的规划实验,制定两个计划来帮助完成原始问题。最后评估这两个计划输出更好的来指导LLM-Agent完成任务。在实验中,作者对于LLM Aggregate制定了两个策略:
- 自我评估。直接零样本评估两个计划,并输出最好的计划。
- 模拟。LLM-Agent 使用两个计划在任务环境中执行新的计划试验,并输出更好的一个。
此外,作者还添加了自我反思(SR)模块来反映LLM-Agent自身的故障。因此对于TP有了四个变种方法:
- TP-SR-SE:自我反思和自我评价的思想传播;
- TP-SE:自我评价的思想传播;
- TP-SR-SM:具有自我反思和模拟的思想传播;
- TP-SM:通过模拟进行思想传播。
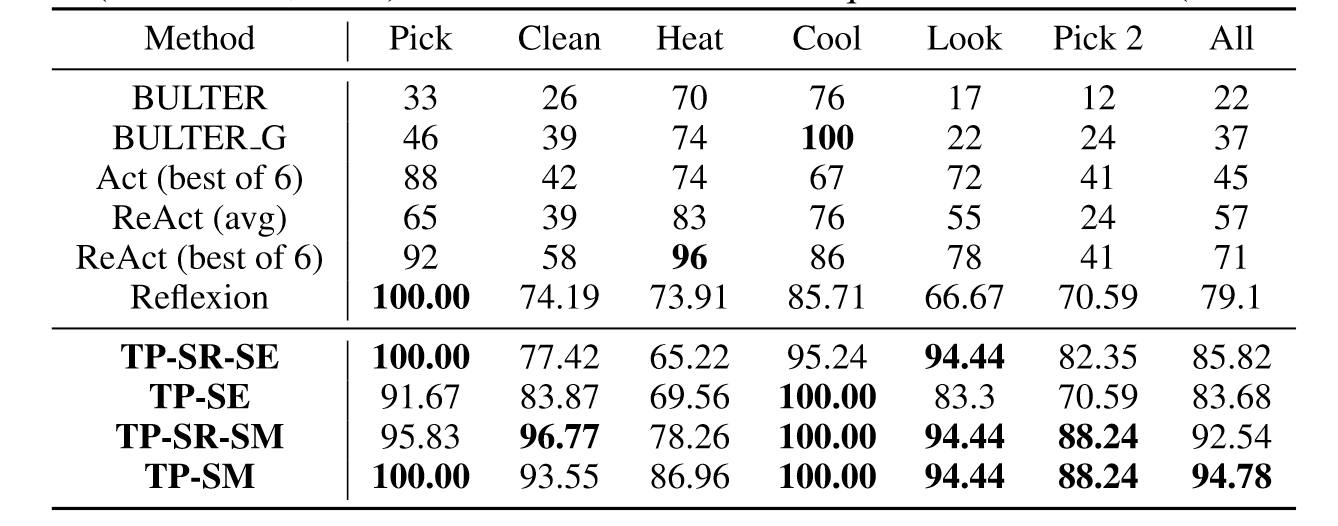
上表展现了在LLM-Agent规划问题上TP的良好性能,即使没有自我反思模块也能有巨大的性能提升。

上表表示,思维传播的不同变体模型通过迭代实现了一致性的性能改进,但是在其他任务如ReAct和Reflexion中都陷入了循环。
6 CONCLUSIONS
现有的LLM推理提示方法无法利用解决类似问题的见解,并且由于从头开始推理,会在多步骤推理中积累错误。为了解决这些问题,本文提出思想传播(TP),它探索类似的问题,以类比的方法产生完善的解决方案或知识密集型计划,以促进新问题的解决。 TP 与现有的提示方法兼容,显示出对最短路径规划、创意写作和LLM-Agent规划等各种任务即插即用泛化和增强的性能。未来的方向将进一步提高框架的性能和效率。
阅读总结
思维传播作为一种特殊的prompt形式,帮助LLM利用先前经验知识,从而避免累积错误的同时提升模型在复杂推理任务上的性能,其实思维传播的提出并不是偶然,由于大模型已经具有初步智能,人类已经主观上将其作为AI-Agent看待,因此在解决问题上的思路和真实场景下人类解决问题的思路相近,从IO到CoT再到ToT,人们一直在探索LLM用人类思考的方式解决问题的形式,而TP正是和人类通过历史经验学习复杂推理问题的方法具有异曲同工之妙,其能在复杂推理问题上成功也就理所当然了。
由于文章在10月初才挂到arxiv上,其附录内容并没有附上,因此其具体的实现细节还需要之后更新才能看到。总之,虽然TP在理解上很简单,但是它在通用性和实用性上都拉满了,它已经不只是一种方法,而是一种思想,在任何问题上都可以泛化,这是我认为TP最值得称赞的地方。
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











