







 本文探讨了如何重新理解线性概念,并通过实际案例展示了线性与非线性数据建模的区别。通过引入多项式回归和分箱处理,解决非线性问题,加深了对模型适用性的理解。
本文探讨了如何重新理解线性概念,并通过实际案例展示了线性与非线性数据建模的区别。通过引入多项式回归和分箱处理,解决非线性问题,加深了对模型适用性的理解。
1 重塑我们心中的“线性”概念

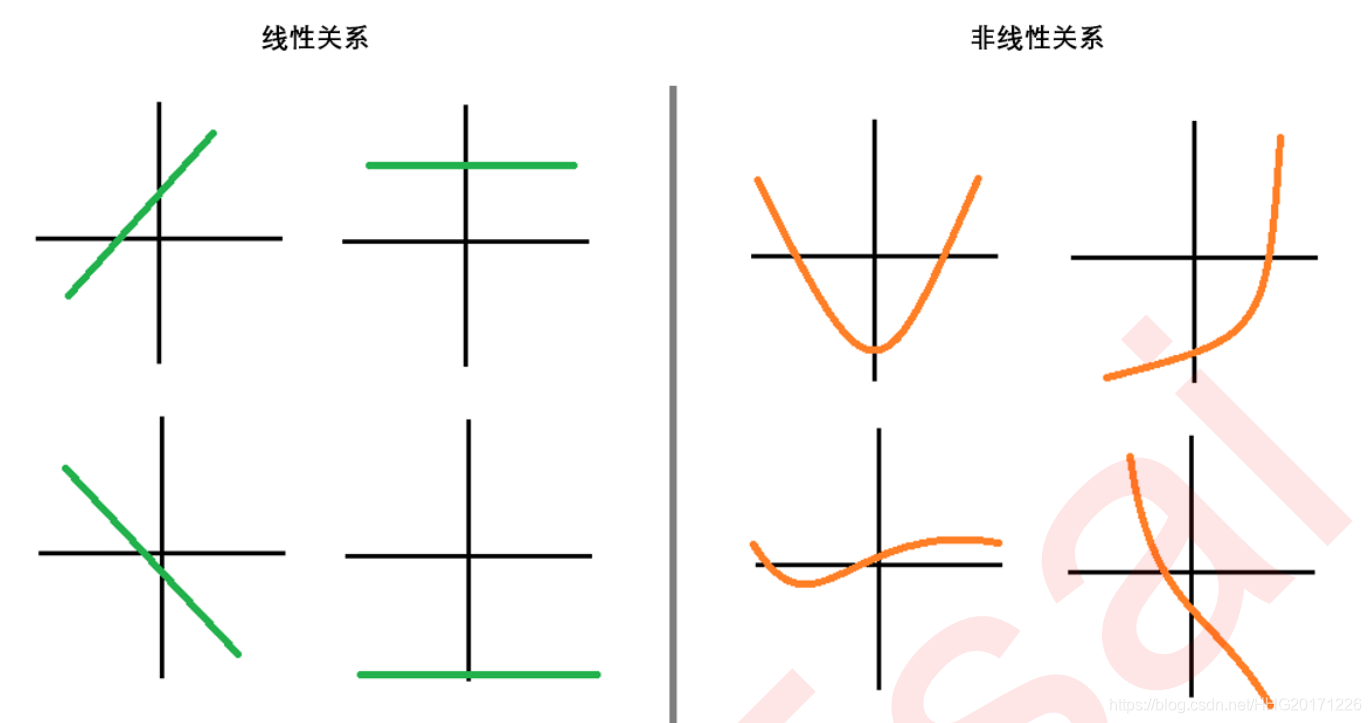
1.1 变量之间的线性关系

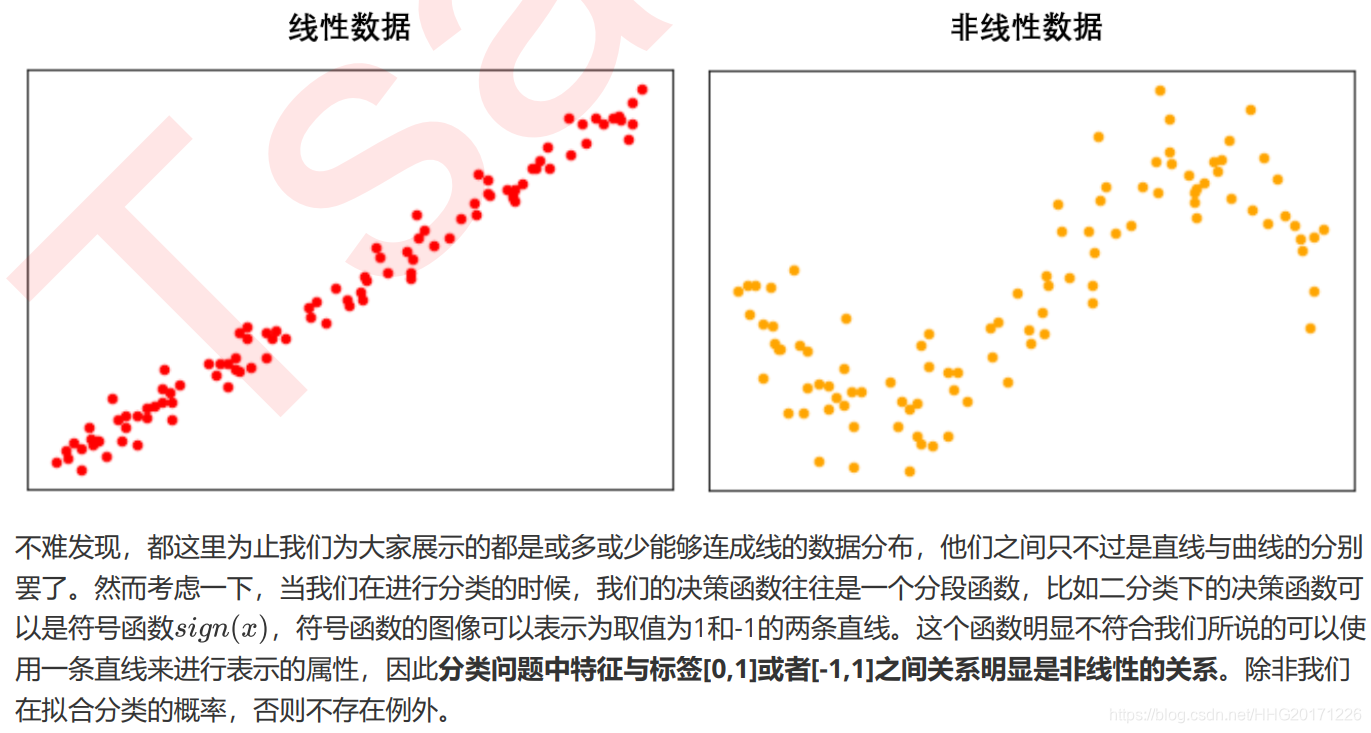
1.2 数据的线性与非线性

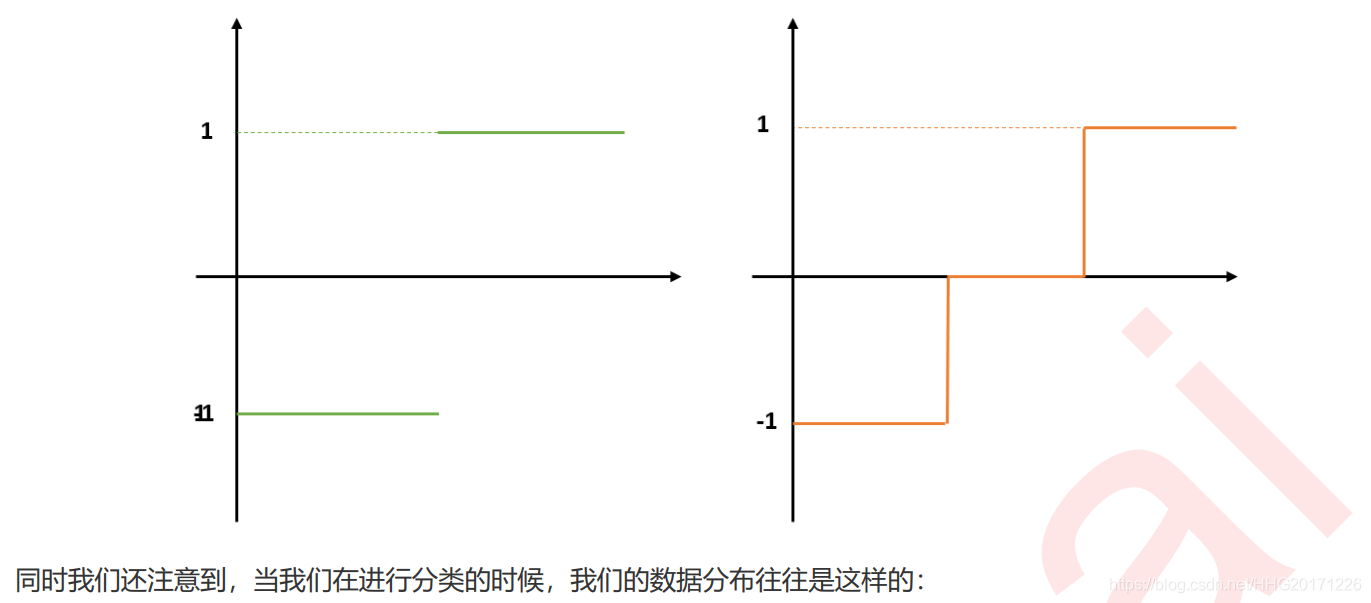

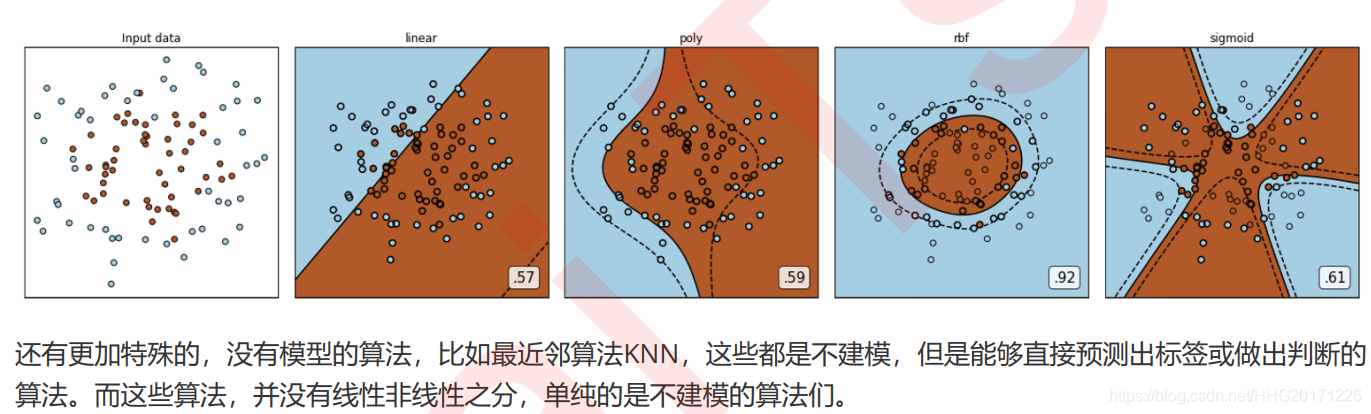
1.3 线性模型与非线性模型


1. 导入所需要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
2. 创建需要拟合的数据集
rnd = np.random.RandomState(42) #设置随机数种子
X = rnd.uniform(-3, 3, size=100) #random.uniform,从输入的任意两个整数中取出size个随机数
#生成y的思路:先使用NumPy中的函数生成一个sin函数图像,然后再人为添加噪音
y = np.sin(X) + rnd.normal(size=len(X)) / 3 #random.normal,生成size个服从正态分布的随机数
#使用散点图观察建立的数据集是什么样子
plt.scatter(X, y,marker='o',c='k',s=20)
plt.show()
#为后续建模做准备:sklearn只接受二维以上数组作为特征矩阵的输入
X.shape
X = X.reshape(-1, 1)
3. 使用原始数据进行建模
#使用原始数据进行建模
LinearR = LinearRegression().fit(X, y)
TreeR = DecisionTreeRegressor(random_state=0).fit(X, y)
#放置画布
fig, ax1 = plt.subplots(1)
#创建测试数据:一系列分布在横坐标上的点
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
plt.tight_layout()
plt.show()








2 使用分箱处理非线性问题

1. 导入所需要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
2. 创建需要拟合的数据集
rnd = np.random.RandomState(42) #设置随机数种子
X = rnd.uniform(-3, 3, size=100) #random.uniform,从输入的任意两个整数中取出size个随机数
#生成y的思路:先使用NumPy中的函数生成一个sin函数图像,然后再人为添加噪音
y = np.sin(X) + rnd.normal(size=len(X)) / 3 #random.normal,生成size个服从正态分布的随机数
#使用散点图观察建立的数据集是什么样子
plt.scatter(X, y,marker='o',c='k',s=20)
plt.show()
#为后续建模做准备:sklearn只接受二维以上数组作为特征矩阵的输入
X.shape
X = X.reshape(-1, 1)
3. 使用原始数据进行建模
#使用原始数据进行建模
LinearR = LinearRegression().fit(X, y)
TreeR = DecisionTreeRegressor(random_state=0).fit(X, y)
#放置画布
fig, ax1 = plt.subplots(1)
#创建测试数据:一系列分布在横坐标上的点
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
plt.tight_layout()
plt.show()
4. 分箱及分箱的相关问题
X_binned.shape #训练
#因此我们需要创建分箱后的测试集:按照已经建好的分箱模型将line分箱
line_binned = enc.transform(line)
line_binned.shape #分箱后的数据是无法进行绘图的
line_binned
LinearR_.predict(line_binned).shape
5. 使用分箱数据进行建模和绘图
#准备数据
enc = KBinsDiscretizer(n_bins=10,encode="onehot")
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)
#将两张图像绘制在一起,布置画布
fig, (ax1, ax2) = plt.subplots(ncols=2
, sharey=True #让两张图共享y轴上的刻度
, figsize=(10, 4))
#在图1中布置在原始数据上建模的结果
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
ax1.plot(X[:, 0], y, 'o', c='k')
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
#使用分箱数据进行建模
LinearR_ = LinearRegression().fit(X_binned, y)
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)
#进行预测,在图2中布置在分箱数据上进行预测的结果
ax2.plot(line #横坐标
, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果
, linewidth=2
, color='green'
, linestyle='-'
, label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
#绘制和箱宽一致的竖线
ax2.vlines(enc.bin_edges_[0] #x轴
, *plt.gca().get_ylim() #y轴的上限和下限
, linewidth=1
, alpha=.2)
#将原始数据分布放置在图像上
ax2.plot(X[:, 0], y, 'o', c='k')
#其他绘图设定
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()
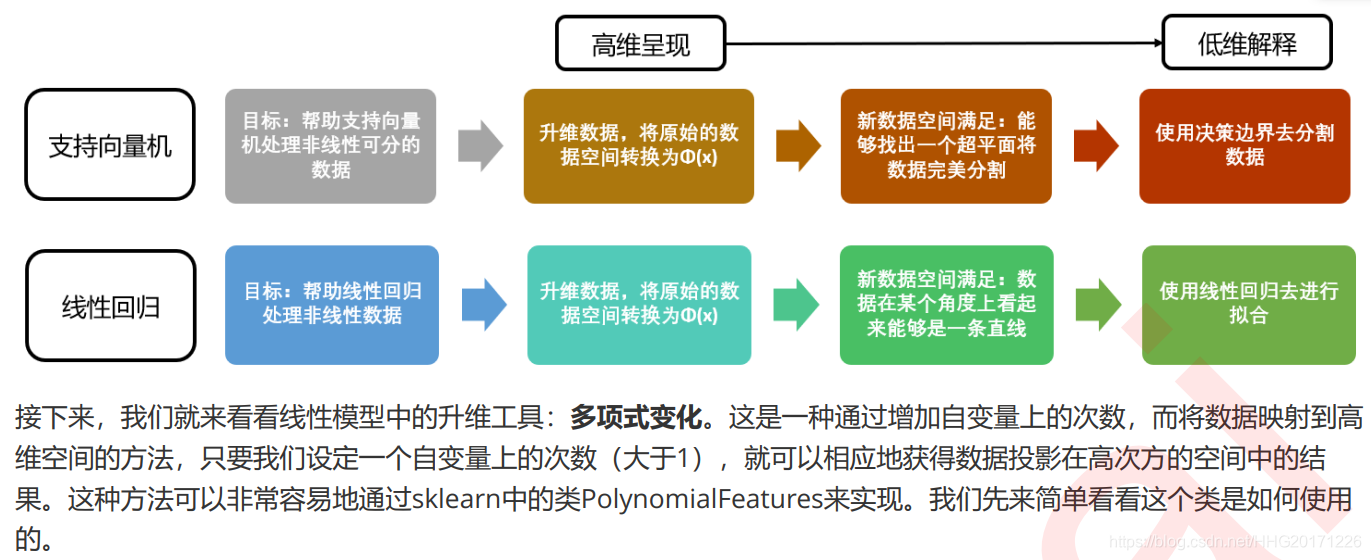
3 多项式回归PolynomialFeatures
3.1 多项式对数据做了什么

class sklearn.preprocessing.PolynomialFeatures (degree=2,
interaction_only=False,
include_bias=True)

from sklearn.preprocessing import PolynomialFeatures
import numpy as np
#如果原始数据是一维的
X = np.arange(1,4).reshape(-1,1)
X #
二次多项式,参数degree控制多项式的次方
poly = PolynomialFeatures(degree=2)
#接口transform直接调用
X_ = poly.fit_transform(X)
X_
X_.shape
#三次多项式
PolynomialFeatures(degree=3).fit_transform(X)



#三次多项式,不带与截距项相乘的x0
PolynomialFeatures(degree=3,include_bias=False).fit_transform(X)
#为什么我们会希望不生成与截距相乘的x0呢?
#对于多项式回归来说,我们已经为线性回归准备好了x0,但是线性回归并不知道
xxx = PolynomialFeatures(degree=3).fit_transform(X)
xxx.shape
rnd = np.random.RandomState(42) #设置随机数种子
y = rnd.randn(3)
y #
生成了多少个系数?
LinearRegression().fit(xxx,y).coef_
#查看截距
LinearRegression().fit(xxx,y).intercept_
#发现问题了吗?线性回归并没有把多项式生成的x0当作是截距项
#所以我们可以选择:关闭多项式回归中的include_bias
#也可以选择:关闭线性回归中的fit_intercept
#生成了多少个系数?
LinearRegression(fit_intercpet=False).fit(xxx,y).coef_
#查看截距
LinearRegression(fit_intercpet=False).fit(xxx,y).intercept_

X = np.arange(6).reshape(3, 2)
X #
尝试二次多项式
PolynomialFeatures(degree=2).fit_transform(X)


PolynomialFeatures(degree=2).fit_transform(X)
PolynomialFeatures(degree=2,interaction_only=True).fit_transform(X)
#对比之下,当interaction_only为True的时候,只生成交互项
从之前的许多次尝试中我们可以看出,随着多项式的次数逐渐变高,特征矩阵会被转化得越来越复杂。不仅是次数,当特征矩阵中的维度数(特征数)增加的时候,多项式同样会变得更加复杂:
#更高维度的原始特征矩阵
X = np.arange(9).reshape(3, 3)
X
PolynomialFeatures(degree=2).fit_transform(X)
PolynomialFeatures(degree=3).fit_transform(X)
X_ = PolynomialFeatures(degree=20).fit_transform(X)
X_.shape


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









