









一个神经概率语言模型
- 论文 | A Neural Probabilistic Language Model
- 链接 | http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
- 作者 | Warren S. McCulloch , Walter Pitts
摘要
统计语言模型的目标是学习一种语言的单词序列的联合概率函数。本质难点是维数灾难:测试集中的单词序列很可能跟训练集中见过的单词序列都不同。传统但非常成功的基于n-gram的方法通过将出现在训练集的很短的重叠的序列联系起来从而得到泛化。本文提出一种词的分布式表示来克服维数灾难,该方法允许每一个训练语句给模型提供关于语义相邻句子的指数级别数量的信息。这个模型同时学习(1)每个词的分布式表示和(2)词序列的概率函数。能得到泛化是因为一个从未见过的单词序列,如果它是由与它相似的词(在某种意义上有着附近的表示、组成已经见过的句子的词)的话,那么它会获得较高的概率。在合理的时间内训练如此大的模型(参数以百万计)本身就是一个挑战。我们报告基于神经网络的概率模型的实验,体现在两个文本语料库,该方法显著改进了最先进的n-gram模型,且该方法允许利用较长的上下文优势。
1.介绍
构造语言模型和其他学习问题困难的一个根本问题是维数灾难。当一个人想对很多离散随机变量(比如句子中的单词)建立联合分布模型时,这个问题尤其明显,因为将会产生很多自由参数。当对连续变量进行建模时,我们更容易得到泛化(如光滑的类的函数像多层神经网络或高斯混合模型),因为要学习的函数可以被期望拥有一些局部的平滑性。对于离散空间来说,泛化结构不够明显:每个离散随机变量的变化都可能对要顾及的函数产生极大的影响,且当每个离散变量取值范围很大时,大多数观察到的对象在汉明距离上几乎是无穷远的。
一个统计语言模型可以表示为给定前面的词,后面一个词出现的条件概率:
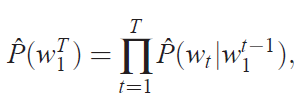
其中,Wt表示第t个词。
在建立统计语言模型时,一个可以考虑的降低模型困难的方法是利用单词顺序,考虑词序列中更靠近的词更加具有依赖性。因此,n-gram模型建立了一个给定前n-1个词,第n个词的条件概率表示:
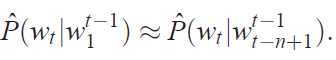
我们只考虑在训练集中出现的连续词的组合,或者出现足够频繁的词。当在语料中未见过的n个词的新组合出现时,将发生什么?我们不想为它们分配为0的概率,因为这样的组合确实有可能发生。一个简单的解决办法是使用更小的上下文,即使用tri-gram或者平滑后的tri-gram。本质上来说,一个新的词序列是通过“粘合”非常短的重叠的在训练语料中出现频繁的字片段组成。获得下一个片段的概率的规则是隐式的回退或者打折后的n-gram算法。研究者使用典型的n=3的tri-gram,并且获得了世界领先水平的结果。显然的是直接出现在词前面的序列携带的信息要比仅仅之前的一小段序列携带的信息多。我们在本论文中提出的方法至少在两个特点上面显著的提高了上面的问题。第一点,上面的方法没有考虑超过1或2个词的上下文;第二点,上面的方法没有考虑词与词之间的相似性。例如,在语料库中已经观测到了序列“The cat is walking in the bedroom”,可以帮助我们生成序列“A dog was running in a room”,因为“dog”和“cat”有相似的语义和语法角色。
解决这两个问题的思想的实现,使用的是同享参数的多层神经网络。这篇论文的另一个贡献是介绍了对大量数据训练如此大的神经网络的高效方法。最后,一个重要的贡献是说明了训练如此大规模的模型是昂贵但是值得的。
1.1 使用分布式表示解决维数灾难
简单讲,本方法可概括为3个步骤:
1. 为词汇表中的每个词分配一个分布式的词特征向量
2. 为词序列中出现的词以词特征向量形式表示联合概率函数
3. 同时学习词特征向量和联合概率函数的参数
词特征向量代表词的不同方面:每个词关联向量空间的一个点。特征的数量远小于词表的大小。概率函数被表达成给定前面的词后面一个词的条件概率的乘积(例如,在实验中,使用多层神经网络,给定前面的词预测下一个词)。这个函数有一些参数,可以通过迭代的方式调整这些参数来最大化训练数据的对数似然函数或者正则标准化。这些词特征向量被学习的当,但是它们可以使用先验的语义特征知识来初始化。
为什么这样有效?在前面的例子中,如果我们知道 “ dog”和“cat”扮演相似的角色(语义的或者句法的),类似的对于(the,a),(bedroom,room),(is,was),(running,walking),我们自然地可以由
The cat is walking in the bedroom
生成
A dog was running in a room
或者
The cat is runing in a room
A dog is walking in a bedroom
The dog was walking in the room
…
在本模型中,会得到泛化是因为“相似”的词被期望拥有相似的特征向量,以及因为概率函数是一个这些特征值的平滑函数,在特征中小的改变将在概率中产生小的变化。因此,上述这些句子的其中一个在语料库中的出现,将增加不仅是这个句子的概率,还有句子空间中“邻居”的组合出现的概率(由特征向量的序列表示)。
1.2与前面工作的关系
使用神经网络对高维离散分布建模已经被发现可以有效的学习其联合概率。在这个模型中,联合概率被分解为条件概率的乘积
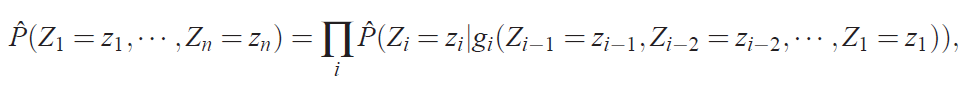
其中,g(x)是被左到右结构神经网络表示的函数。第i个输出块gi计算表达给定之前Z,Zi的条件概率的参数。
2.一个神经模型
训练集是一个词序列w1,…,wT,其中wt∈V,词表V是一个大但是有限的集合。模型的目标是学要到一个好的函数来估计条件概率:
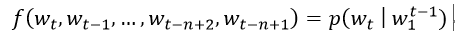
其中,必须满足的两个约束是:
我们把函数 分解为两个部分:
1. 一个映射C,从词表中的任意元素i到实向量C(i)∈Rm。它代表关联词表中词的分布特征向量。在实践中,C被表示成一个|V|×m的自由参数矩阵。
2. 词上的概率函数,用C表达:一个函数g,从输入序列的词的上下文特征向量,(C(wt-n+1),…,C(wt-1)),到词表中下一个词i的条件概率分布。g的输出是一个向量,向量的第i个元素估计概率
整个模型示意图,如下图
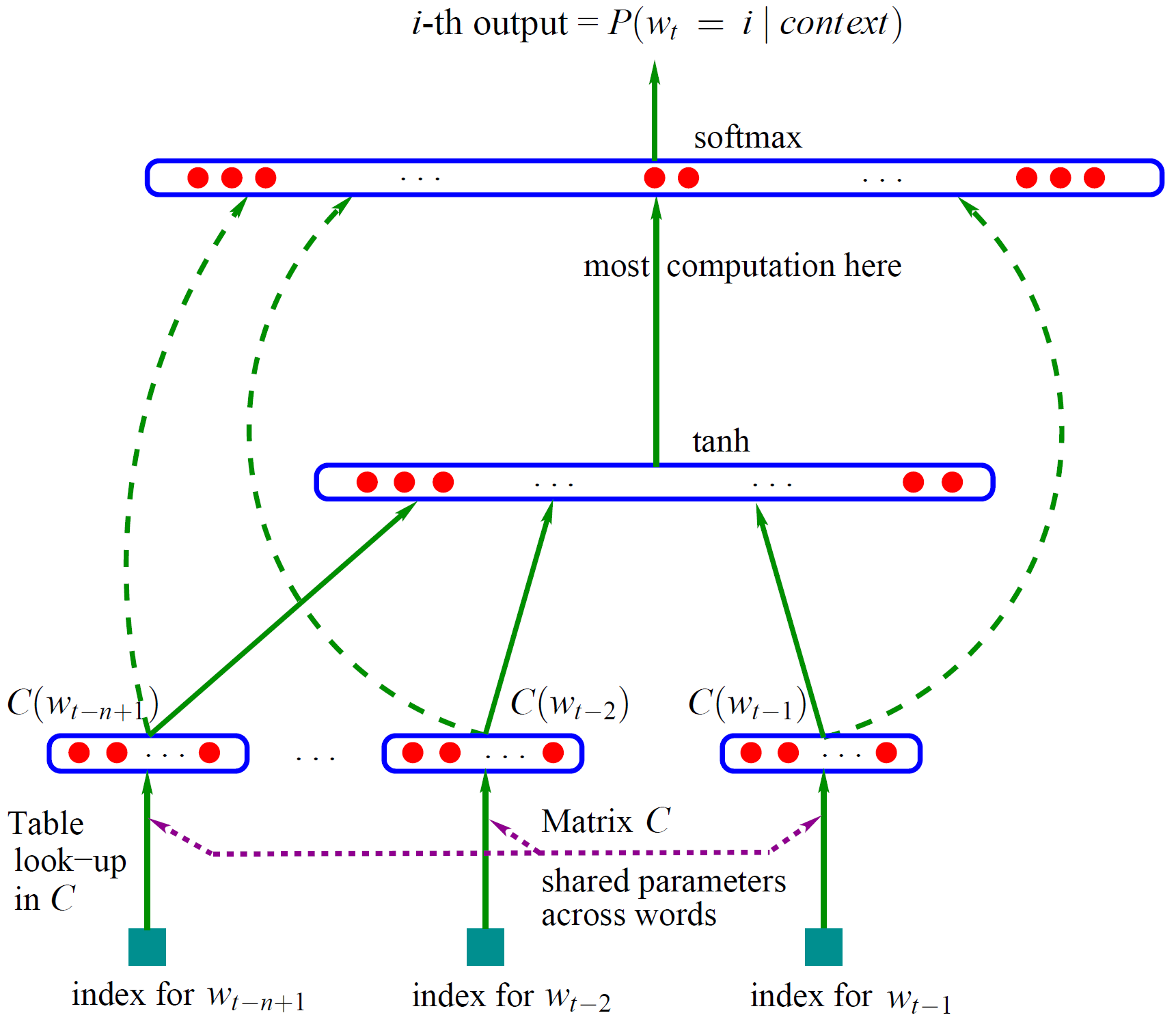
图1 神经网络语言模型结构图
函数f是这两个映射C和g的组合。这两个映射都关联一些参数。映射C的参数就是特征向量本身,被表示成一个|V|×m的矩阵C,C的第i行是词i的特征向量。函数g可以被一个前馈神经网络或者卷积神经网络实现或者其他的参数化函数实现。
训练目标是寻找θ使得训练数据的对数似然函数最大化:
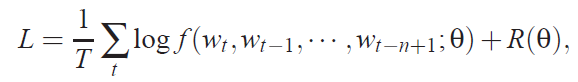
网络的第一层(输入层)是将 C(wt−n+1),…,C(wt−2),C(wt−1) 这n−1个向量首尾相接拼起来,形成一个 (n−1)m 维的向量,下面记为 x。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用 d+Hx 计算得到。d 是一个偏置项。在此之后,使用 tanh 作为激活函数。
网络的第三层(输出层)一共有 |V| 个节点,每个节点 yi 表示下一个词为 i 的未归一化 log 概率。最后使用 softmax 激活函数将输出值 y 归一化成概率。最终,y的计算公式为:
式子中的 U(一个 |V|×h 的矩阵)是隐藏层到输出层的参数,整个模型的多数计算集中在 U 和隐藏层的矩阵乘法中。
式子中还有一个矩阵 W(|V|×(n−1)m),这个矩阵包含了从输入层到输出层的直连边。直连边就是从输入层直接到输出层的一个线性变换,好像也是神经网络中的一种常用技巧(没有仔细考察过)。如果不需要直连边的话,将 W 置为 0 就可以了。在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。
模型训练过程如下:


具体推导过程参考:
CSDN博客:Feedforward Neural Network Language Model(NNLM)原理及数学推导考


















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











