







论文题目:Researchand Implementation of a Multi-label Learning Algorithm for Chinese TextClassification
作者:Xun Wang, Huan Liu, Zeqing Yang, Jiahong Chu, Lan Yao, ZhiBin Zhao,Bill Zuo
摘要:挖掘京东商城的商品数据,学习并获得在线商城里消费者的反馈。定义三种类型的分类问题并分析它们之间的联系。在构造的数据集上应用单标签二分类器(是或不是属于这个类),最后将全部单标签分类器整合到一起得到一个多标签分类器。
正文:
Ⅰ.简介
文本分类问题分为二分类和多分类。多分类问题分为单标签多分类和多标签分类。多标签分类近年来被发现应用广泛。本文研究的中文多标签学习算法,目标是从用户评论中挖掘出产品属性。使用CHI平方指标来选择文本特征和计算特征权重。论文结构主要有:1.分析二分类、单标签多分类、多标签分类的内在联系,将多标签分类转化为多个单标签多分类分类器的组合。2.使用两种算法:POCA(位置排序)、WOCA(权重排序)来构造单标签多分类器的巡检及,避免标签组合爆炸的问题。3.收集京东商城上洗衣粉的用户评论数据。先提取洗衣粉产品的属性,收集标签集合后,将标签集合后,将标签赋给每个评论。
Ⅱ. 近期研究进展
多标签分类有两种方式:1. 转化为一系列单标签多分类问题。2. 算法转化,将传统算法转化为可直接解决多标签分类问题的算法。第一种方法的代表:BinaryRevelance(BR)。Classifier Chain(CC)基于BR,克服了忽略标签之间联系的问题。第2中方法的关键是将数据适应传统算法。代表包括:ML-KNN,Rank-SVM,BP-MLL等。ML-KNN是KNN针对多标签分类的一个变体,对K个样本使用信息增益评估,然后使用最大后验概率决定测试集表情。Rank-SVM调整核函数,将排序问题转化为多标签分类问题。BP-MLL修改了反向传播算法来适应多标签数据,主要提升在于引进了一种新的误差计算公式。很多多标签分类学习算法在大规模数据上表现不佳,本文提出一种新的基于SVM的算法。
Ⅲ. 问题描述
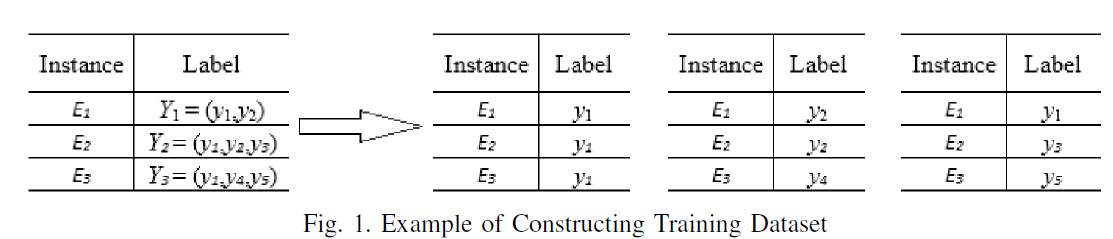
把多标签分类问题转化单标签多分类问题,先做好训练集的转化。单标签多分类问题可以看作多个二分类问题的结合,即该样本是不是属于该类(是或不是)。多标签分类问题可以看作多个单标签多分类问题的结合。本文采用转化方法,即将多标签分类问题转化为多个单标签多分类问题的结合。
Ⅳ. 基于SVM的中文文本多标签分类问题
文本分类方法可以分为三种:词匹配、知识工程方法、统计学习方法。本文采用第三种。本文使用MMSEG算法进行中文文本分割,使用卡方检验方法提取文本特征向量以及计算文本特征权重。提出两种方法来将原始的多标签数据集衍生为单标签多分类数据集以训练基于SVM的二分类器,最后将所有单标签多分类器整合成一个多标签分类器。单标签多分类器中采用one-vs-one的结对分类方法。
构造多标签分类训练集的两种方法:POCA(Positionin-
OrderConstruction Algorithm)和WOCA(Weight-in-
OrderConstruction Algorithm)。POCA认为标签在标签集中有它们的排序,跟它在原始评论中的语义重要性一致。POCA基于评论中的信息按照它们的重要性来传达的假设。如果一个样本的标签数K’跟训练集中的标签数K一样,那么这个样本将被拆分成K个依次放入K个新的构造出来的训练集中,无需重复如果一个样本的标签数K’小于训练集中的标签数K,那么在放入K‘个新训练集中,需要根据原始评论中标签位置的排序来进行对样本进行重复补充。WOCA认为出现需要进行样本重复补充时,应该根据标签的权重来决定,即各个标签在总的评论样本中出现的频率,频率越大的标签优先补充。
Ⅴ. 实验评估
收集京东商城上关于洗衣产品(洗衣液、洗衣粉、洗衣皂)的12275条真实用户评论,半人为标识标签,向领域专家征询意见,构建一个标签集。评估标准不考虑标签排序问题,故使用以下几种评估方法:Subset accuracy, Hamming
loss, Macro-averaging,Micro-averaging。
Subset accuracy,判断样本预测值与实际值标签完全一样的比例。与ML-KNN,ML-NB相比,POCA和WOCA在训练集占全部数据比例较小时,表现优异。
Hamming loss,用于调查样本和标签的错误分类,值越小越好。
















 3727
3727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











