






最近正好在攻克AI用例生成的技术,所以恰好弄到了这个知识点,踩了个坑,觉得挺有意义,就特此记录一下~
**背景**:torch是python的一个训练AI模型的第三方库,挺好用的,但是参数都得是数字,也就是你的各种业务需求,都要先想办法转换成多角度画像的数字才能利用后续的什么均方差、随机梯度下降这种算法。当然,这并不难,任何事务都可以用纯数字来表示,比如我自己,性别:1(1表示男,2表示女),身高:174,年龄:33,日收入:900,爱好:1 (1代表游戏,2代表运动,3代表旅游) 等等.... ,这样一个人就可以用一大串数字组成的列表来代表:\[1,174,33,900,1\]
这里说一下为什么用日收入,因为少啊!你用年收入,六位数了都!这对于其他数据 才1-3位来说,属于一个噪声数据,会让整个模型很糟糕很难预测,所以准备数据一般都要平滑一点,这叫归一化或标准化处理。
**正文:**
然后,你比如想要的一个预测模型,预测目的比如是你在多少岁可以结婚?那么这个结婚年龄,就是模型的一个输出。当然,你可以继续预测更多内容,比如你什么时候暴富... ,所以结果可能就是这样的列表\[28,31\]
大家看一下,输入是\[1,174,33,900,1\] ,输出是\[28,31\] 。那么这就是一条数据,一个人的数据而已。如果你想使用这个模型真的去预测别人。那么你起码要有很多很多人的真实数据才能训练出来。
然后你去网上找了很多人的这个数据,然后所有输入都放在了一个大列表中,就会变成这样的一个二维列表
\[ \[1,174,33,900,1\] , \[2,164,21,100,3\] ,\[1,174,49,150,2\] ... \]
然后输出也给存放到一起变成一个大二维列表
\[ \[28,31\],\[25,42\],\[24,51\] ...\]
所以,接下来我们就简单的写一下这个模型:(当然前提是你要pip下载torch,然后直接复制到你本地运行就可以看到结果)
`import torch``import torch.nn as nn``import torch.optim as optim`
`class WQRF(nn.Module):` `def __init__(self, i_data_count, m_data_count, o_data_count):` `super().__init__()` `self.ItoM = nn.Linear(i_data_count, m_data_count)` `self.MtoO = nn.Linear(m_data_count, o_data_count)`
`def forward(self, in_data):` `im = torch.relu(self.ItoM(in_data))` `return self.MtoO(im)`
`def get_test_data():` `in_data = torch.tensor([[1, 174, 33, 900, 1], [2, 164, 21, 100, 3], [1, 174, 49, 150, 2]], dtype=torch.float32)` `out_data = torch.tensor([[28, 31], [25, 42], [24, 51]], dtype=torch.float32)` `return in_data, out_data`
`def make_AI():` `wqrf = WQRF(i_data_count=5, m_data_count=16, o_data_count=2)` `criterion = nn.MSELoss()` `optimizer = optim.SGD(wqrf.parameters(), lr=0.01)`
`# 获取整个数据集` `in_data, out_data = get_test_data()`
`# 由于in_data和out_data已经是整个数据集,因此下面的循环是全批量梯度下降` `for epoch in range(10000):` `optimizer.zero_grad()` `# 在这里,我们使用整个数据集in_data进行一次前向传播` `out_tmp = wqrf(in_data)` `# 计算整个数据集的损失` `loss = criterion(out_tmp, out_data)` `# 反向传播损失,计算梯度` `loss.backward()` `# 使用优化器更新模型参数` `optimizer.step()` `print(f'第{epoch}次训练, 当前损失值:{loss.item()}')`
这里,我print的是每次的损失值,损失值越小代表越精准。在实际使用中,一般会进行的循环要求损失值小于多少才会停止,而不是这样直接写死10000次。但有些时候因为数据选的不好,所以永远也降不到损失值以下,那就会设置一个最高循环次数比如10000来结束。
看看损失值在开始的时候还是很大的:
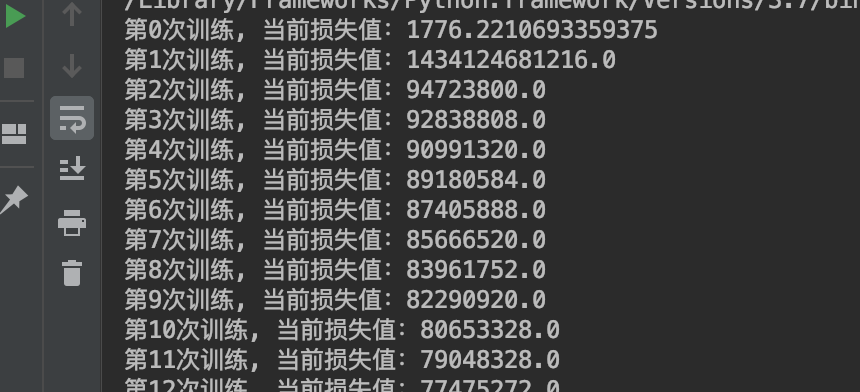
但是最后的时候不但稳定而且很小:
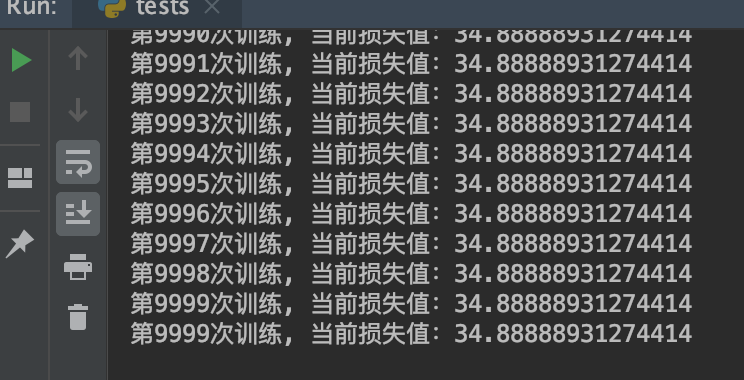
还有,给的数据越多,预测误差就越小,循环次数越多也越小,但是执行时间就会比较高,没办法。
在结束后,我们可以直接保存好这个模型,以便之后调用其来预测新人的结婚和暴富年龄等,这可是根据大数据来预测的,可不是网上那种随机结果的骗人小程序哦~ 大家可以部署后输入自己身边亲朋好友同学等人的基本信息,本地训练,然后预测自己的。毕竟大家都是一个地区和圈子内,结果应该比较准。
然后保存模型:(红圈代码,代码和之前训练的一起重新运行!才会保存!)
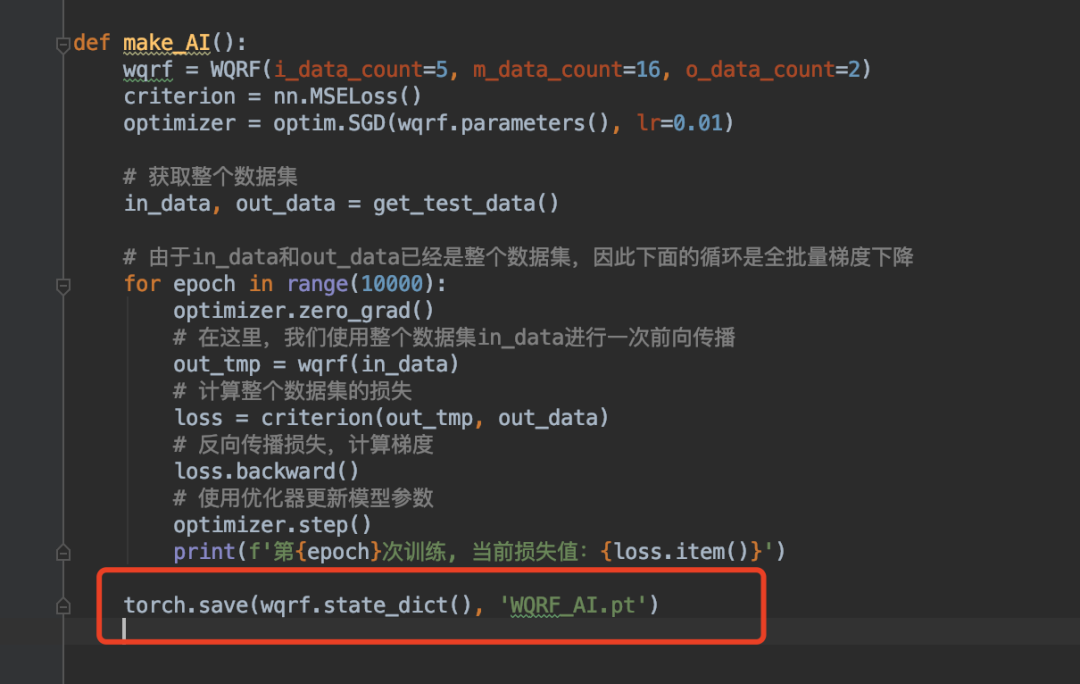
再次运行后,保存了这个模型文件:WQRF_AI.pt

这就是永久存储到你本地的模型了,之后要预测啥,直接调用就可以,很多同学喜欢网上下载一些AI的模型,大多也是.pt,就是这样生成的~ 以后就不用到处去网上搜还要下载了,这回当一个真正的极客,自己写模型!
然后就是使用:(你可以直接在当前文件继续写调用函数,只是再运行就别运行make_AI了,那是用来训练的。咱直接运行play_AI,这是直接用模型预测的!)
我们来假设有个女生:30岁,1米68,日收入1000,喜欢旅游。看看几岁结婚几岁暴富!
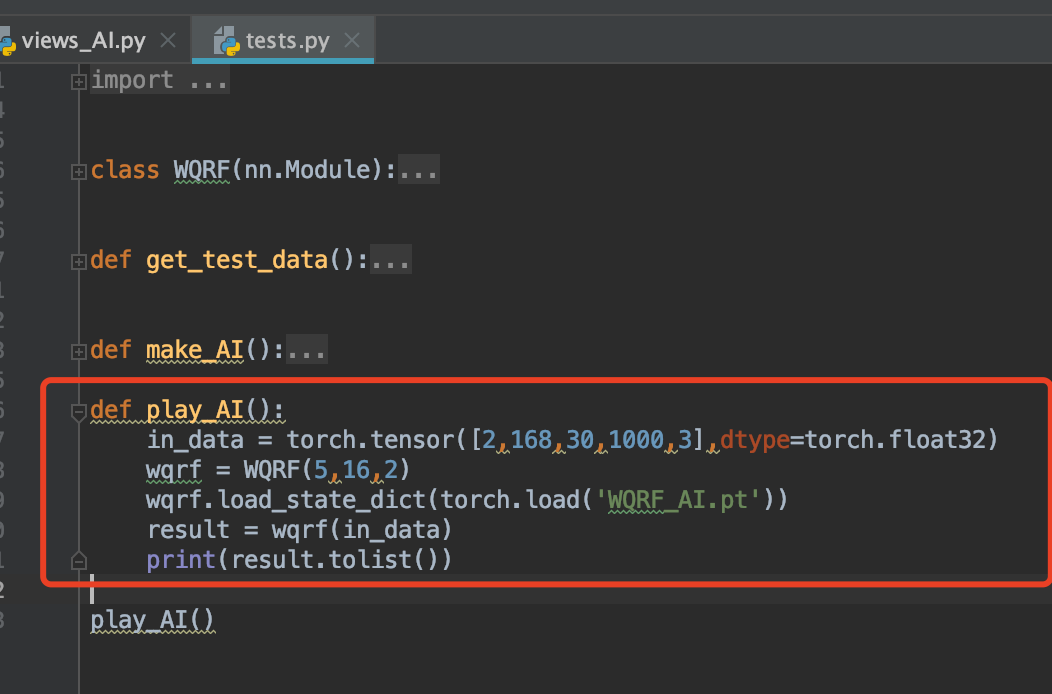
def play_AI():` `in_data = torch.tensor([2,168,30,1000,3],dtype=torch.float32)` `wqrf = WQRF(5,16,2)` `wqrf.load_state_dict(torch.load('WQRF_AI.pt'))` `result = wqrf(in_data)` `print(result.tolist())`
`play_AI()
好,然后我们看看预测的结果:

答案出来了!25岁结婚!41岁暴富!
注意,这个模型因为已经有上万次的训练,所以非常精准,无论再预测几次结果都不会变。但是一开始给的三个数据确实假的,所以这个结果也是假的。大家请用自己身边至少几十个人的数据来训练才会有借鉴意义哦~
这,就是一个很简单的模型的创建和使用了~
目前,我已经成功把AI技术应用到了测试领域的一些场景中。
【 测试排期预测】需要多少天,什么时候封板,会有多少bug,有多大风险等均可根据大数据预测。结果根据学员反馈几乎精准无比!
【简历优化】目前更多依靠GPT和算法的结合哦,但是因为训练数据不足,所以优化效果和我亲自优化差很多。
【用例生成】同时融合了 GPT + 用例生成算法 + 本地AI 来生成用例,能帮助使用者节省80%的用例编写时间哦~ 但并不能完全替代测试,请不要裁掉我们!
【脚本预测】对自动化脚本的各种指标进行静态预测,比如需要运行多久,误报率多高,能发现多少bug,什么时候适合执行等等。已经半成熟了,可以拿出来讲了!
【自动找BUG】一般来说,代码的bug直接交给GPT就可以,但是我这里说的是业务上的bug,并非语法或者代码层面的。要根据需求和开发者和产品经理等指标来找出最可能发生bug的操作行为,这个技术目前是我正在攻克了一半的,所以暂时没有加入到课程和公众号文章连载中哦~ 请大家耐心等待。
但是,上面给大家讲的只是最简单最简单的一个应用。下一节文章,我会给大家讲,在更复杂的更高维的场景中,这个AI模型的代码要怎么改!
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









