







MetaGPT配置教程(使用智谱AI的GLM-4)
零、为什么要学MetaGPT
- 因为
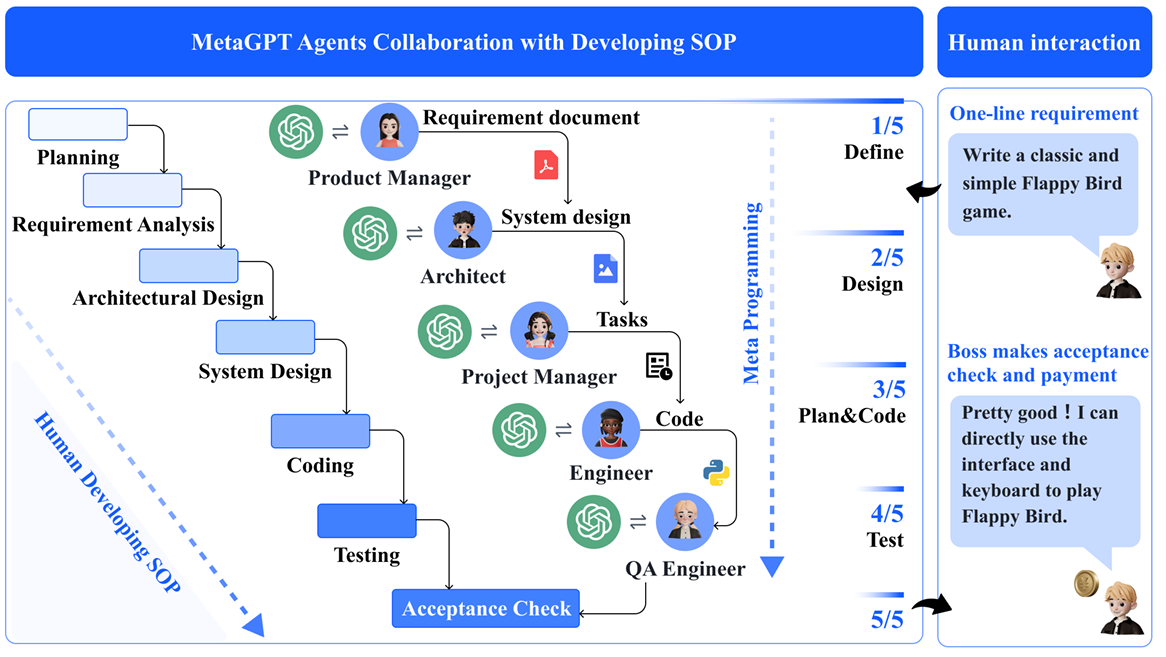
MetaGPT是 LLM Agent领域第一高分论文,全网Star数最高的多智能体框架。ICLR 2024 Oral 🙌
ICLR 2024录用结果公布:MetaGPT 的论文 《MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework》将被展示为Oral(口头报告)。这一荣誉仅占全部提交论文中的1.2%,并且位列LLM-based Agent 关键字第一!
- 因为可以当
帕鲁LLM老板:输入一句话的老板需求,输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等。
- 因为报名了Datawhale的组队学习。(正解)
说了再多也得从环境配置开始…
一、配置环境
创建一个新的conda环境并激活它:
conda create -n for_meta python==3.11
conda activate for_meta
检查Python版本以确保它大于3.9:
python --version
二、克隆代码仓库
然后,从GitHub上克隆MetaGPT的最新代码仓库:
git clone https://github.com/geekan/MetaGPT.git
cd MetaGPT
然后,使用pip安装仓库中的代码:
pip install -e .
但是现在的MetaGPT更新飞快,兴许以后的版本就不同了。所以先确定下现在的版本。
pip show metagpt # Version: 0.7.2
三、设置智谱AI配置
安装之后,可以新建一个项目目录来检索默认的配置文件地址。
from metagpt.const import DEFAULT_WORKSPACE_ROOT, METAGPT_ROOT, OPTIONS
default_yaml_file = METAGPT_ROOT / "config/config.yaml"
print(METAGPT_ROOT / "config/config.yaml")
我们输出的是在MetaGPT的源码目录中config/config2.yaml文件,我们在此设置智谱AI的配置。
修改为以下内容:
llm:
api_type: 'zhipuai'
api_key: 'Your api key....'
model: 'glm-4'
确保将api_key替换为您的智谱AI API密钥。
新注册有百万token,具体可以从这里智谱AI开放平台查看。
(要是有邀请码,邀请别人送token就好了…)
四、 示例demo(狼羊对决)
实际上就是角色扮演
from metagpt.team import Team
from metagpt.roles import Role
from metagpt.environment import Environment
from metagpt.actions import Action
import asyncio
action1 = Action(
name="喜羊羊说", instruction="批驳别人想法,表明你的创新发明并带有情感,不要重复。")
action2 = Action(
name="灰太狼说", instruction="批驳别人想法,表明你的创新发明并带有情感,不要重复。")
honglong = Role(name="喜羊羊", profile="羊村发明家",
goal="赢得青青草原最强发明产品", actions=[action1], watch=[action2])
bob = Role(name="灰太狼", profile="狼堡发明家",
goal="赢得青青草原最强发明产品", actions=[action2], watch=[action1])
env = Environment(desc="最强发明评选大赛")
team = Team(investment=10.0, env=env, roles=[honglong, bob])
asyncio.run(team.run(
idea="主题:实用性与美观性。每条消息不超过4句话。", send_to="喜羊羊", n_round=5))
# 这里设置的n_round=5是指两个人一共对话的次数是5个回合。
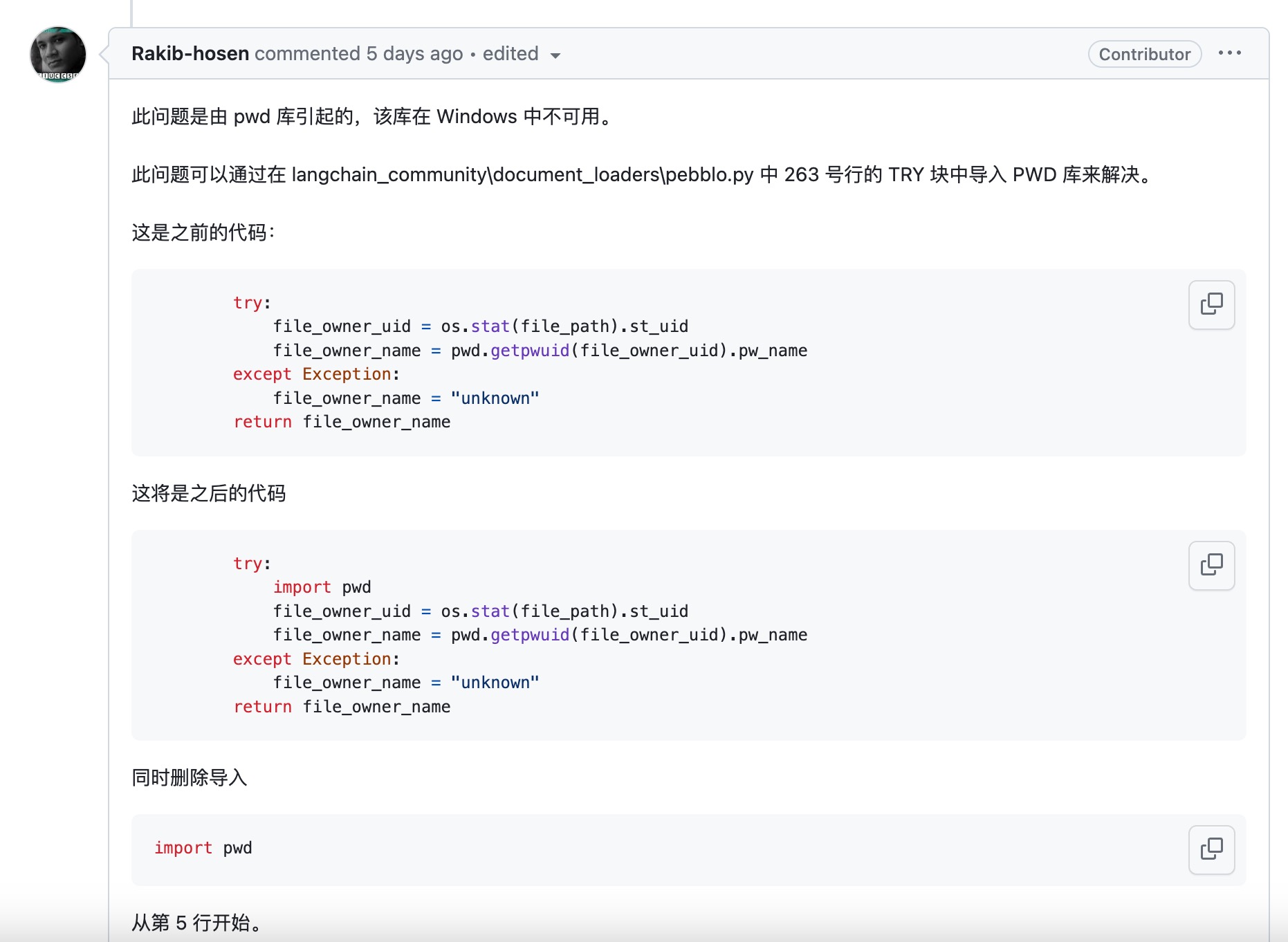
Tip:如果你遇到ModuleNotFoundError: No module named 'pwd'的错误,请将import pwd移动到使用它的位置。借鉴群里的图。
至此,我们就可以直接运行代码,得到如下输出结果。
一共对话5次,中途发生了一点点的网络问题,不过问题不大,依旧能继续执行下去。
















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











