







一、DPCM编解码原理
预测编码指根据某一模型利用旧的样本值对新样本值进行预测,然后将样本的实际值与其预测值相减得到误差值,对于这一误差值进行编码。如果模型足够好且样本序列在时间上相关性较强,那么误差信号的幅度将远远小于原始信号,从而得到较大的数据压缩结果。
预测编码方法分线性预测和非线性预测编码方法。线性预测编码方法也称差值脉冲编码调制法,简称DPCM。
二、DPCM编解码过程如下图:
编码器(Encoder)中Q是量化器,P是预测器。输入信号Xn是某一像素点的实际灰度值,Pn是对该像素点的预测值,dn 是预测误差,^(dn)是量化预测误差,^(Xn)=量化预测误差^(dn)+预测灰度值Pn,得到当前像素点的重建值,作为下一个像素点的预测值。需要注意,预测器的输入是已经解码以后的样本,因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,DPCM编码器中内嵌了一个解码器。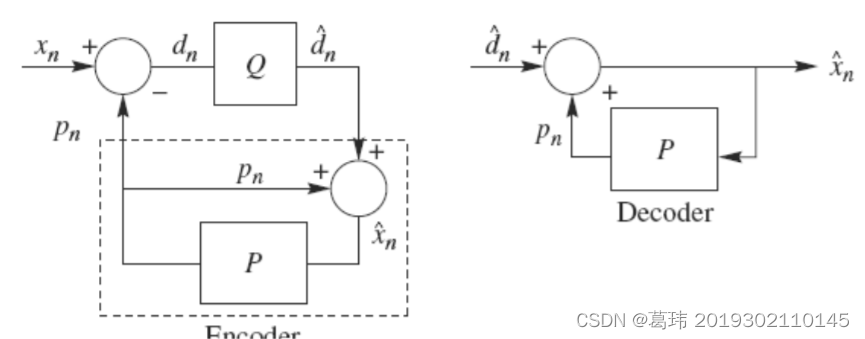
三、实验过程
实验图像(从左往右分别为8bit、4bit、2bit量化后的图像)

对比8bit、4bit、2bit、1bit量化的重建图像,可以看到,8bit图像还原最好,4bit有些许失真,2bit重建图像基本失真,而1bit的重建图像完全失真。这说明量化比特数越大,PSNR越大,重建图像质量也越好。
重建图像概率分布(从上到下分别为8bit、4bit、2bit)
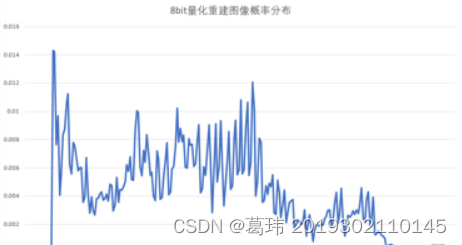
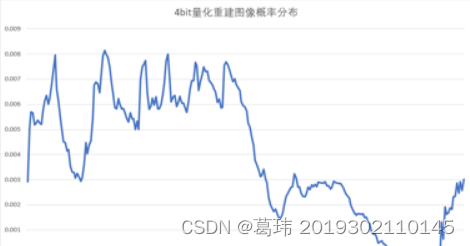
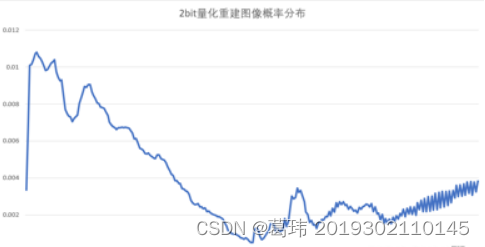
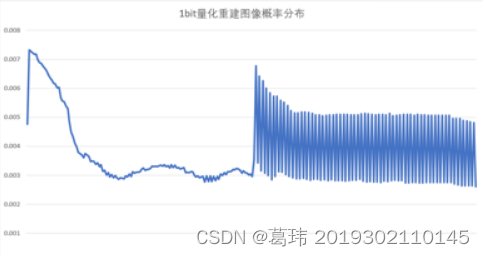
1bit量化图像和概率分布较为特殊(随着量化比特数的减小,重建图像的质量大大降低,图像失真明显。当只用1bit量化时,重建图像已完全分辨不出其原图像。),如下

四、 过程代码:
#include <iostream>
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#include<math.h>
#include<std
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









