









集成学习(ensemble learning)通过构建并结合多个学习期来完成学习任务,有时也被称为多分类器系统(multi-classifier system)。
集成学习的一般结构:先产生一组“个体学习器”,再用某种策略将他们结合起来。

如何产生“好而不同”的个体学习器,是集成学习研究的核心。 好,即要求学习器要有一定的“准确性”;不同,即要求学习器要有“多样性”,不同学习器之间具有差异,最好是独立的。
根据个体学习器是否是同一种类型,集成可分为:
- 同质的(homogeneous):个体学习器是同种类型;
- 异质的(heterogenous):个体学习器是不同类型的。
根据个体学习器的生成方式,目前的集成学习方法大致分为两类:
- 个体学习器之间存在强依赖关系、必须串行生成的序列化方法(代表:Boosting);
- 个体学习器之间不存在强依赖关系、可同时生成的并行化方法(代表:Bagging)。
Bagging(袋装)
Bagging全称为Bootstrap aggregating。
Bagging是一种并行式集成学习方法:
1.利用 bootstrap(即有放回采样)方法从整体数据集中采取
T
T
T个含
m
m
m个训练样本的采样集;
2. 基于每个采样集学习出一个模型,
T
T
T个采样集得到
T
T
T个模型(同种模型);
3. 将
T
T
T个模型的输出集成得到最终预测结果,具体地:分类问题采用
T
T
T个模型预测投票的方式,回归问题采用
T
T
T个模型预测平均的方式。
对于Bagging需要注意的是,每次训练集可以取全部的特征进行训练,也可以随机选取部分特征训练。
对含有 m m m个样本的数据集 D D D进行自助采样法得到数据集 D ′ D' D′,样本在 m m m次( D ′ D' D′中也含 m m m个样本点)采样中始终不被采到的概率是 ( 1 − 1 m ) m (1-\frac{1}{m})^m (1−m1)m,取极限得到:
lim m → ∞ ( 1 − 1 m ) m = 1 e ≈ 0.368 \lim_{m\rightarrow\infty}(1-\frac{1}{m})^m=\frac{1}{e}\approx 0.368 m→∞lim(1−m1)m=e1≈0.368 可粗略的估计,通过自助采样,初始数据集 D D D中约有36.8%的样本未出现在数据集 D ′ D' D′中。
Bagging方法如何体现“好而不同”?
- 不同:每个模型的训练数据集不同,这样获得的模型具有较大差异;
- 好:如果采样出的每个子集都完全不同,则每个模型只用到了小部分训练数据,不足以进行有效学习。有放回抽样获得的采样集是相互有交叠的,保证差异的同时也提供足够了数据量。
自助法(bootstrap)是一种有放回的抽样方法,目的为了得到统计量的分布以及置信区间。具体步骤如下:
- 采用重抽样方法(有放回抽样)从原始样本中抽取一定数量的样本;
- 根据抽出的样本计算想要得到的统计量T;
- 重复上述N次(一般大于1000),得到N个统计量T;
- 根据这N个统计量,即可计算出统计量的置信区间.
Boosting(提升)
Boosting是一族可将弱学习器提升为强学习器的算法。这族算法的工作机制类似:
- 从初始训练集训练出一个基学习器;
- 根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注;
- 基于调整后的样本的分布来训练下一个基学习器;
- 重复进行上述步骤,直至基学习器数目达到实现指定的值 T T T,最终将这 T T T个基学习器进行加权结合。
Stacking(堆叠)
聚合多个分类或回归模型(可以分阶段来做)
Stacking是通过一个元分类器或者元回归器来整合多个分类模型或回归模型的集成学习技术。基础模型利用整个训练集做训练,元模型将基础模型的输出作为特征进行训练。基础模型通常包含不同的学习算法,因此stacking通常是异质集成。算法伪代码如下:

Stacking框架是堆叠使用基础分类器的预测作为对二级模型的训练的输入,然而,我们不能简单地在全部训练数据上训练基本模型,产生预测,输出用于第二层的训练。如果我们在训练集上训练,然后在训练集上预测,就会造成过拟合。为了避免过拟合,我们需要对每个基学习器使用K-fold,将K个模型对验证集的预测结果拼起来,作为下一层学习器的一个输入特征。
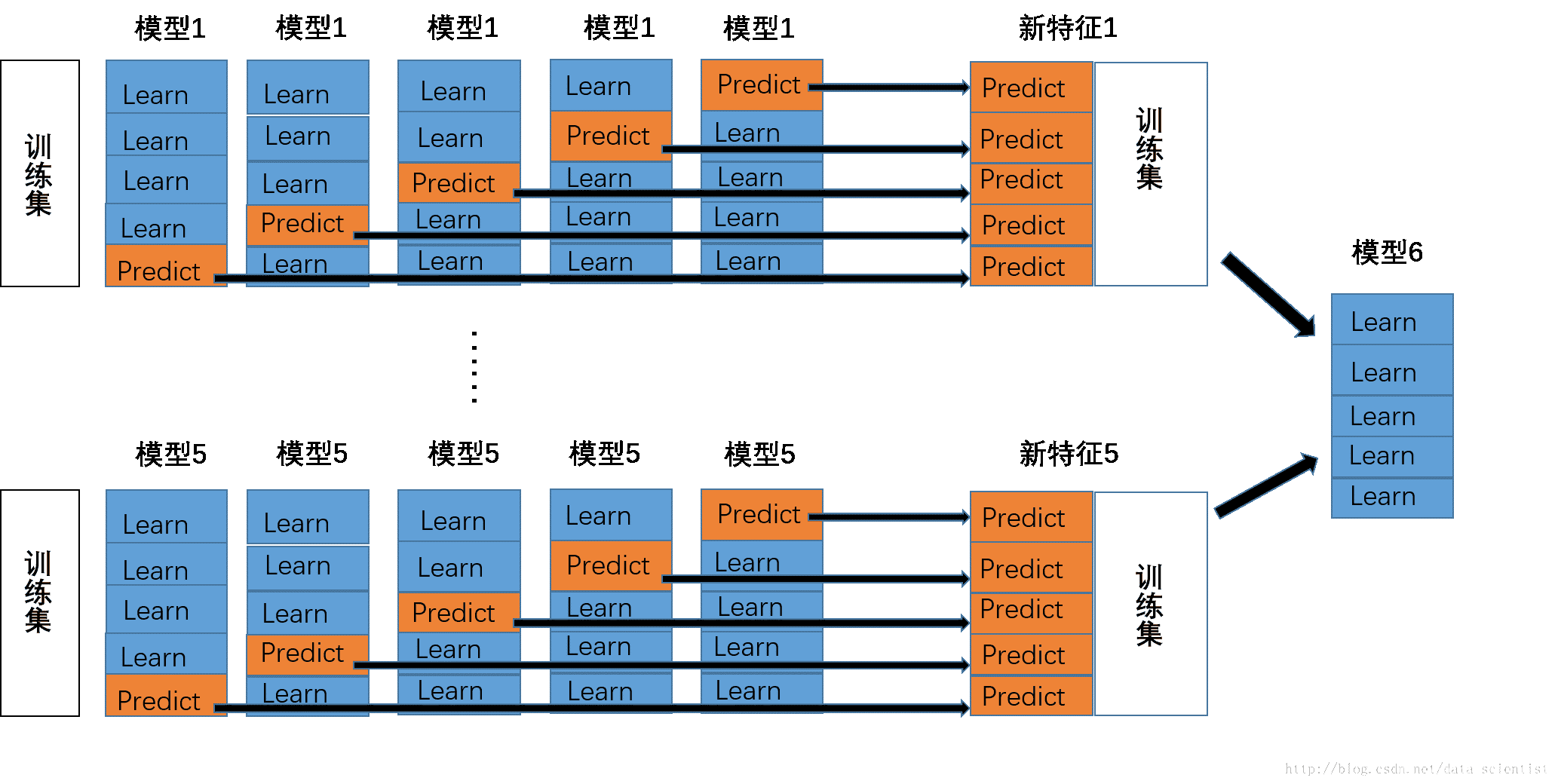
1、首先我们将训练集分为五份。
2、对于每一个基模型来说,我们用其中的四份来训练,然后对未用来的训练的一份训练集和测试集进行预测。然后改变所选的用来训练的训练集和用来验证的训练集,重复此步骤,直到获得完整的训练集的预测结果。
3、对五个模型,分别进行步骤2,我们将获得5个模型,以及五个模型分别通过交叉验证获得的训练集预测结果。即P1、P2、P3、P4、P5。
4、用五个模型分别对测试集进行预测,得到测试集的预测结果:T1、T2、T3、T4、T5。
5、将P15、T15作为下一层的训练集和测试集。在图中分别作为了模型6的训练集和测试集。
#异质集成学习的实现
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import KFold
import numpy as np
# The algorithms we want to ensemble.
# We're using the more linear predictors for the logistic regression, and everything with the gradient boosting classifier.
#boosting和逻辑回归两种方法
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), ["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize", "Title",]],
[LogisticRegression(random_state=1,solver='liblinear'), ["Pclass", "Sex", "Fare", "FamilySize", "Title", "Age", "Embarked"]]
]
kf = KFold(n_splits=3, shuffle=True,random_state=1)
predictions = []
test_index=[]
for train, test in kf.split(titanic):
train_target = titanic["Survived"].iloc[train]
full_test_predictions = []
# Make predictions for each algorithm on each fold
for alg, predictors in algorithms:
# Fit the algorithm on the training data.
alg.fit(titanic[predictors].iloc[train,:], train_target)
# Select and predict on the test fold.
# The .astype(float) is necessary to convert the dataframe to all floats and avoid an sklearn error.
test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1]
full_test_predictions.append(test_predictions)
# Use a simple ensembling scheme -- just average the predictions to get the final classification.
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
# Any value over .5 is assumed to be a 1 prediction, and below .5 is a 0 prediction.
test_predictions[test_predictions <= .5] = 0
test_predictions[test_predictions > .5] = 1
predictions.append(test_predictions)
test_index.append(test)
# Put all the predictions together into one array.
predictions = np.concatenate(predictions, axis=0)
test_index= np.concatenate(test_index, axis=0)
# Compute accuracy by comparing to the training data.
accuracy = len(predictions[predictions ==titanic.loc[test_index,"Survived"]]) / len(predictions)
print(accuracy)
Bagging,Boosting主要区别

- 样本选择上:Bagging采用的是Bootstrap随机有放回抽样;而Boosting每一轮的训练集是不变的,改变的只是每一个样本的权重。
- 样本权重:Bagging使用的是均匀取样,每个样本权重相等;Boosting根据错误率调整样本权重,错误率越大的样本权重越大。
- 预测函数:Bagging所有的预测函数的权重相等;Boosting中误差越小的预测函数其权重越大。
- 并行计算:Bagging各个预测函数可以并行生成;Boosting各个预测函数必须按顺序迭代生成。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
模型融合方法学习总结
【机器学习】模型融合方法概述
模型融合—Stacking调参总结
[机器学习]集成学习–bagging、boosting、stacking
Ensemble learning 概述
Bagging和Boosting概念及区别

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









