






 本文深入探讨了Google的Zircon微内核中的调度器工作原理,包括基于时间片的调度算法、线程抢占机制及上下文切换过程。此外,还详细介绍了线程优先级管理和CPU分配迁移策略。
本文深入探讨了Google的Zircon微内核中的调度器工作原理,包括基于时间片的调度算法、线程抢占机制及上下文切换过程。此外,还详细介绍了线程优先级管理和CPU分配迁移策略。
目录
概述
Ziron是Google新推出的microkernel 替换传统的Linux kernel作为Fuchsia OS的kernel运行
本文旨在分析Ziron 调度器(Scheduler)的基本工作方式,在通用操作系统中调度器的主要职责是以公平的方式确保所有线程取得运行时间,使得线程之间共享有限的处理器时间资源。 Zircon的调度器基于LK’s scheduler,它支持线程抢占,是一个realtime OS的调度器。
代码下载: https://fuchsia.googlesource.com/zircon
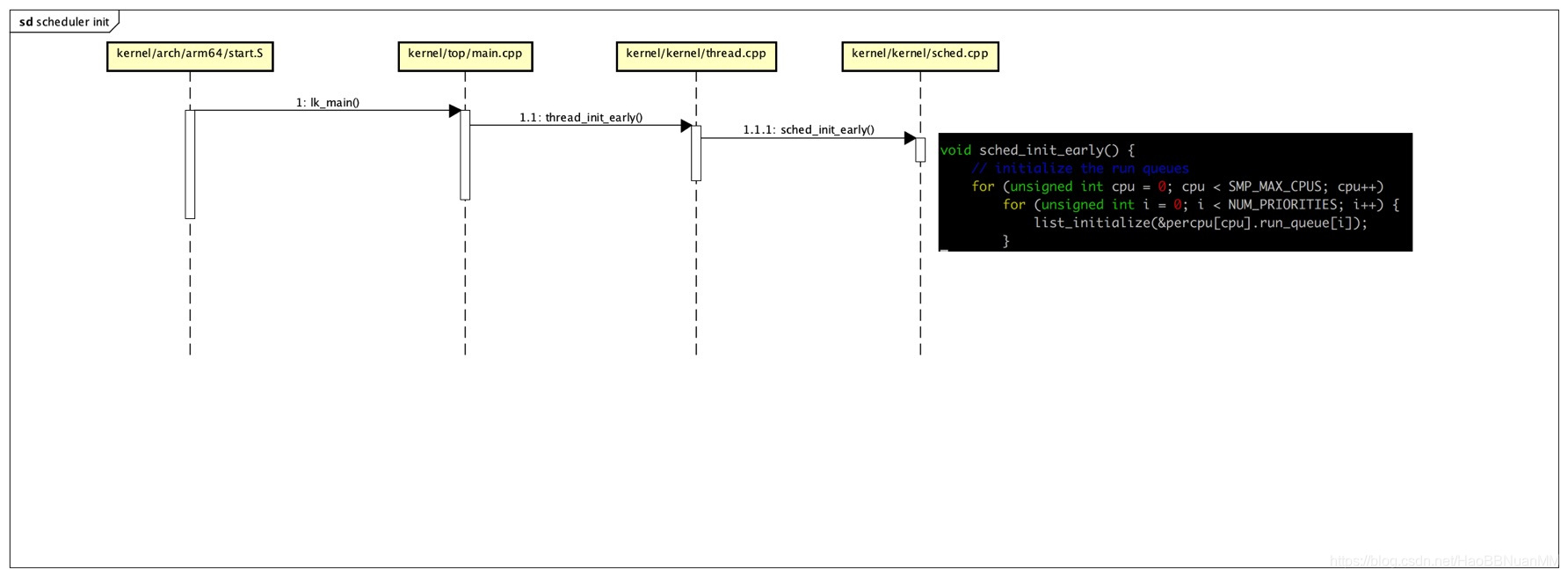
Scheduler 工作方式
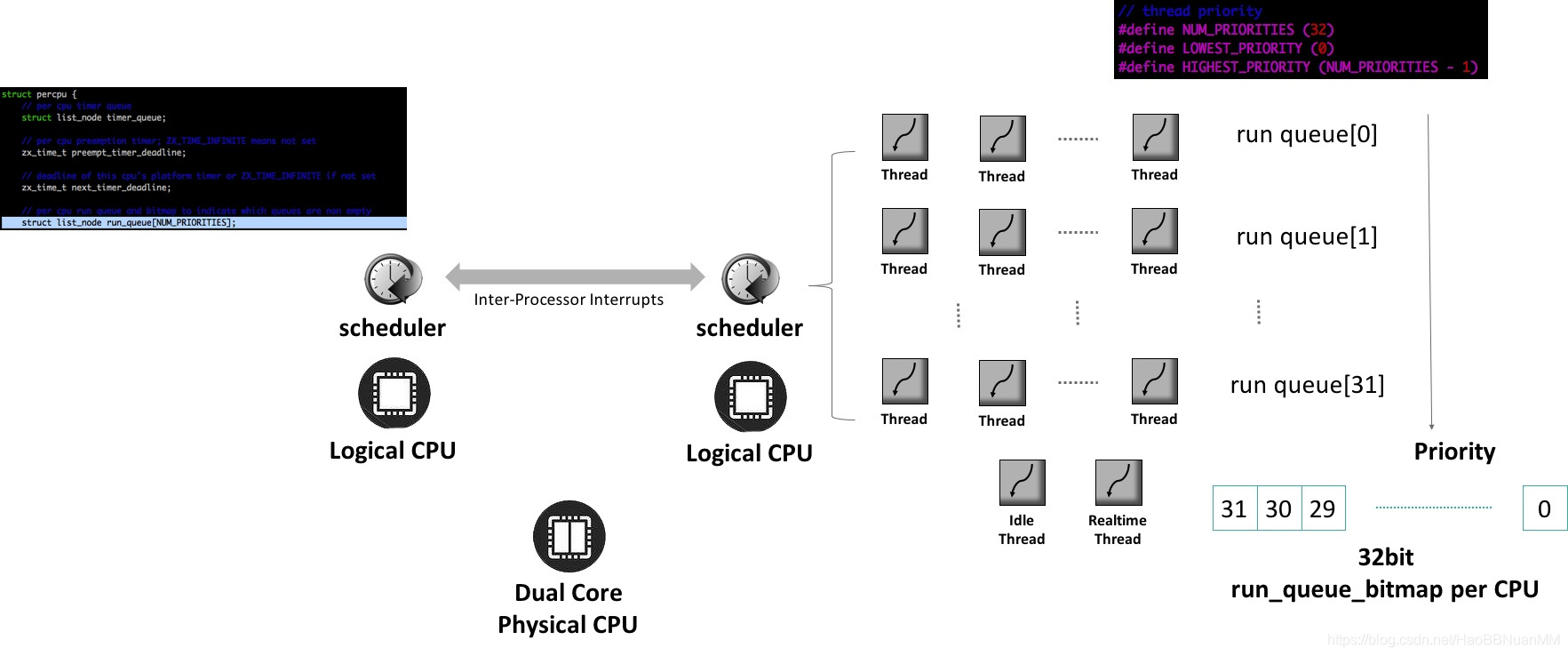
- 物理CPU组成逻辑CPU
- 逻辑CPU上运行scheduler (scheduler之间通过IPI (Inter-Processor Interrupts)通信)
- 每个逻辑CPU有32个run queue,queue[31]为最高优先级queue,每个queue的head为最高优先级thread
- 每个逻辑CPU有32bit的run_queue_bitmap 标记run queue是否有等待调度的thread, 可以在O(1)时间内计算出最高优先级的run queue#
// using the per cpu run queue bitmap, find the highest populated queue
static uint highest_run_queue(const struct percpu* c) TA_REQ(thread_lock) {
return HIGHEST_PRIORITY - __builtin_clz(c->run_queue_bitmap) -
(sizeof(c->run_queue_bitmap) * CHAR_BIT - NUM_PRIORITIES);
}
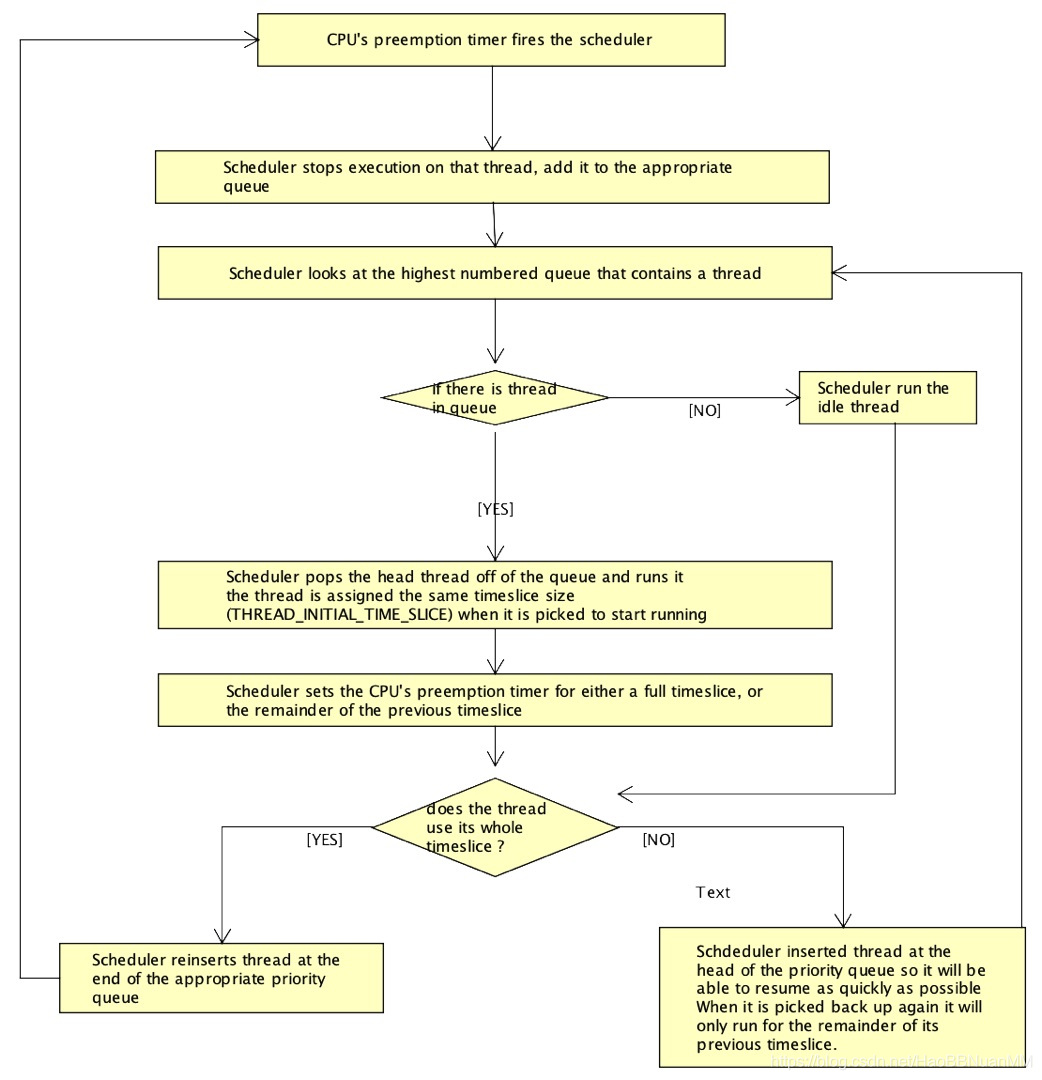
- 基于时间片的scheduler
- Real-time threads (marked with THREAD_FLAG_REAL_TIME) 允许不被抢占的允许,但它们在被block或者主动放弃cpu的时候可以再次发生调度
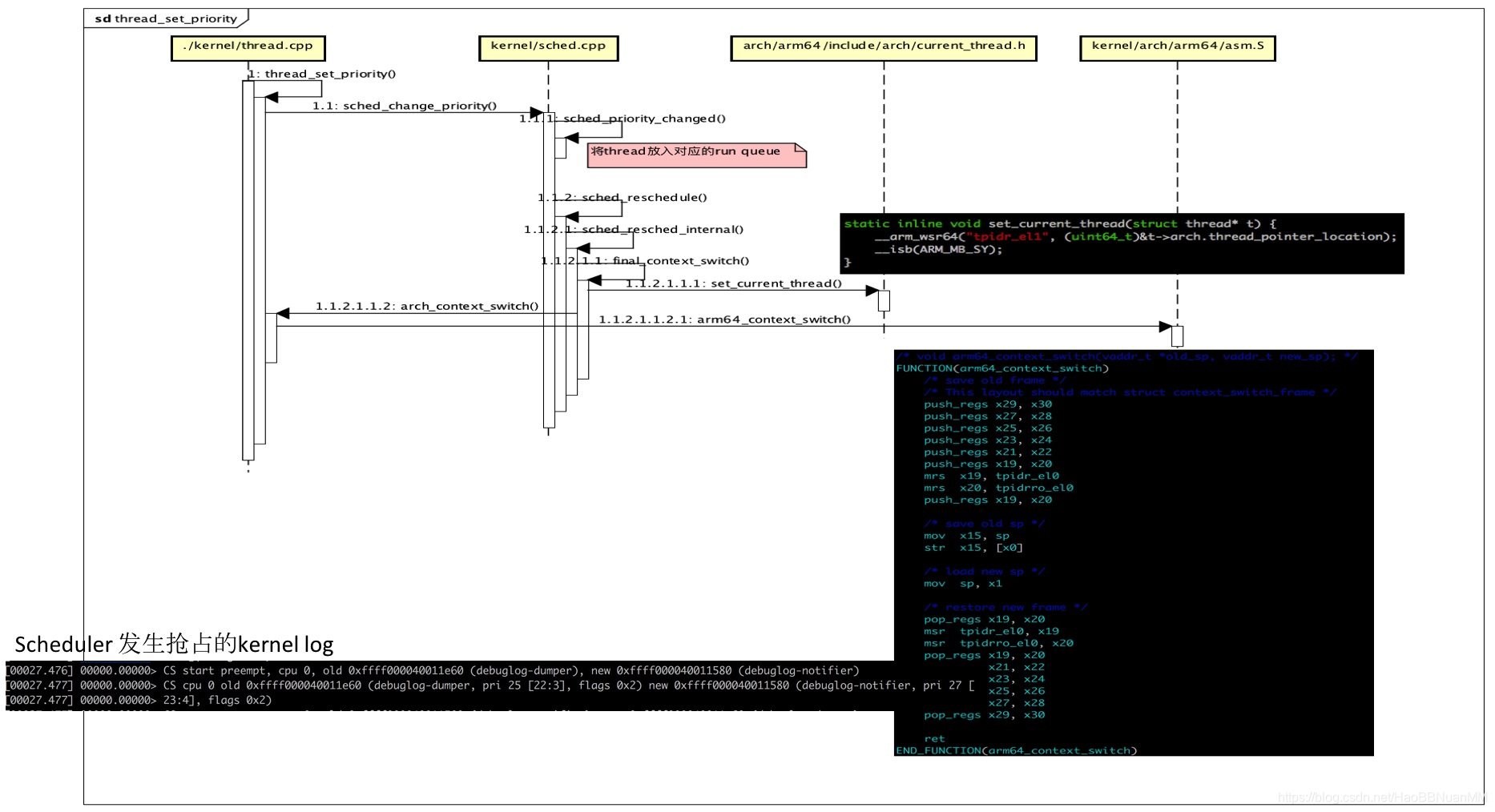

thread effective priority 决定thread会被加入哪个run queue :
// compute the effective priority of a thread
static void compute_effec_priority(thread_t* t) {
int ep = t->base_priority + t->priority_boost;
if (t->inherited_priority > ep) {
ep = t->inherited_priority;
}
DEBUG_ASSERT(ep >= LOWEST_PRIORITY && ep <= HIGHEST_PRIORITY);
t->effec_priority = ep;
}- Thread Effective Priority = inherited priority/base priority + boost
- base priority ∈∈ [0, 31]
- inherited priority inherited from its parent thread
- Boost ∈∈ [-MAX_PRIORITY_ADJ, MAX_PRIORITY_ADJ], 取值由以下因素确定
When a thread is unblocked, after waiting on a shared resource or sleeping, it is given a one point boost.
When a thread yields (volunteers to give up control), or volunteers to reschedule, its boost is decremented by one but is capped at 0 (won’t go negative).
When a thread is preempted and has used up its entire timeslice, its boost is decremented by one but is able to go negative.
If the thread is in control of a shared resource and it is blocking another thread of a higher priority then it is given a temporary boost up to that thread’s priority to allow it to finish quickly and allow the higher priority thread to resume
CPU Assignment and Migration
- Threads are able to request which CPUs on which they wish to run using a 32 bit CPU affinity mask
Ex: (001)2 is CPU 1, (100)2 is CPU 3, and (101)2 is either CPU 1 or CPU 3.
- When selecting a CPU for a thread the scheduler will choose, in order:
- The CPU doing the selection, if it is idle and in the affinity mask.
- The CPU the thread last ran on, if it is idle and in the affinity mask.
- Any idle CPU in the affinity mask.
- The CPU the thread last ran on, if it is active and in the affinity mask.
- The CPU doing the selection, if it is the only one in the affinity mask or all cpus in the mask are not active.
- Any active CPU in the affinity mask.

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









